来自MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention[1]中的一个发现。其实R1-Zero后,关于GRPO的优化和研究已经有相当不少的文章了,光笔者自己都梳理过不少,如下。
- VAPO:基于价值方法的新突破 | Yam[2]
- 异曲同工之妙的DrGRPO——DAPO几乎同时出现的又一GRPO优化! | Yam[3]
- DAPO:为GRPO的锦上加四点花 | Yam[4]
- R1相关:RL数据选择与Scaling | Yam[5]
- R1相关:DPO数据选择与DPO等RL算法 | Yam[6]
- R1相关:R1-Zero的进一步理解和探索 | Yam[7]
没想到还能继续出新。
背景
首先回顾一下PPO:
其中:
是重要性采样权重,表示当前策略和旧策略在同一个状态下输出o的概率比,比值大于1,表示新策略更倾向于选输出该token;相反,说明新策略不再倾向选这个token。
这是带Clipping和KL惩罚的损失函数。PPO需要价值网络计算Advantage,不过GRPO去掉了价值模型,将Advantage定义为相对于组中其他响应的输出奖励。
Reward可以用规则来计算,也可以用一个Reward模型。
问题
在使用GRPO时,观察到其对性能产生负面影响,而且不能有效促进CoT推理行为出现。通过一系列试验后发现主要是由于PPO/GRPO损失函数中的不当裁剪操作导致的。
具体来说,与反思行为相关的token通常是推理路径中的“分叉点”,在Base模型中出现频率低,且被赋予较低的概率。这些token往往具备较高的r,因此在第一次on-policy更新后就会被裁剪掉,无法参与后续的off-policy梯度更新。然而,这些低概率的token往往对于稳定熵以及促进可扩展的强化学习至关重要。
尽管 DAPO 尝试通过提高裁剪上界来缓解这一问题,但本文发现这一方法在本文采用的设置中效果有限——每个生成批次包含 16 轮 off-policy 更新。其实关于这点,我们在DAPO:为GRPO的锦上加四点花 | Yam[4]也分析过,原话是:“论文中low被设置成0.2,high被设置成0.28。看起来好像也没增加多少;)”,因为这个high值的影响其实非常小。
还需要解释一下on-policy和off-policy,首先是结论:GRPO 算法整体属于 on-policy,但更新过程有 off-policy 的“成分”。
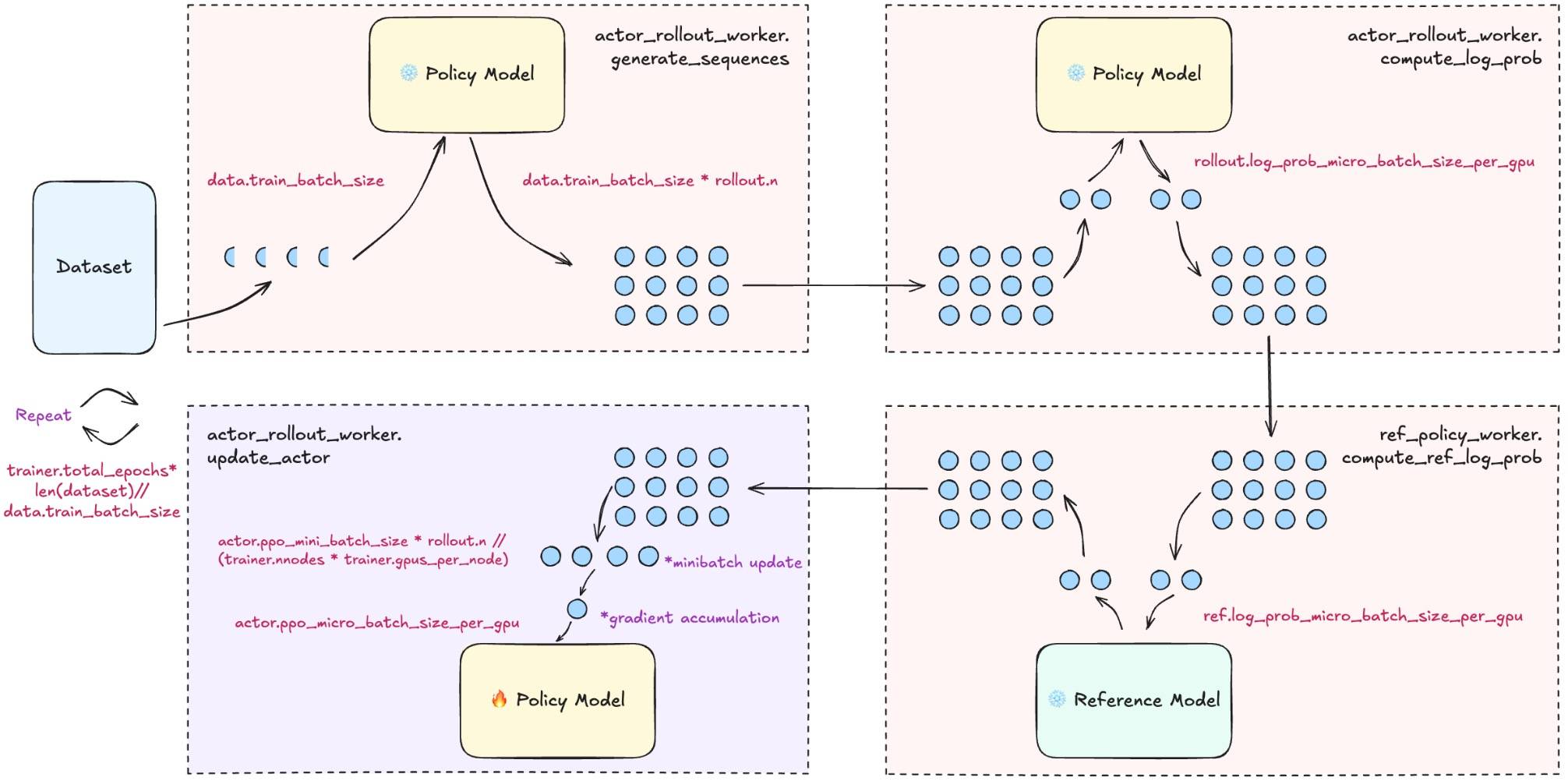
如图所示(图片来自verl仓库),
- 采样:on-policy rollout,每个输出都是根据当前policy生成的。
- 计算log_prob:用当前policy和ref policy计算log prob,然后计算r。
- 多轮actor更新:每一轮更新后policy会变,但数据依然是一开始采样的。新策略在学旧策略生成的数据,产生 off-policy 成分。
on-policy和off-policy关键区别是:
- on-policy:当前策略采样数据,用这批数据训练这版策略。
- off-policy:训练用的数据不是当前策略采样的,可能来自旧策略甚至别的策略。
CISPO
CISPO是Clipped IS-weight Policy Optimization的简称,它被设计为明确避免丢弃token,即使是那些对应较大更新的token,同时通过内在机制将熵控制在合理范围内,以确保探索过程的稳定性。
本文从REINFORCE出发,它的损失函数如下(标准 REINFORCE 不需要重要性系数,但 off-policy 或策略与采样分布不一致,则须引入重要性采样比率。关于 REINFORCE 可以移步《Reinforce++和它的KL Loss选择 | 长琴》):
sg表示停止梯度操作。对r进行clip:
其中,就是clip的IS weight:
此外,还采用了DAPO[8]提出动态采样和长度惩罚技术,另外也没有使用KL惩罚。
这里的核心是sg操作,让IS停止(不参与)梯度,这样就不会像PPO那样clip导致update被截断,进而导致token update被强行剪掉。CISPO只是将IS当做一种固定的reweighting因子,衡量采样分布和目标分布(新旧策略)之间的差异。
这也是个很有意思的发现,令人感慨——细节真多。
文中还提出一个通用公式,引入一个按 token的 mask,然后就可以通过超参数调优来控制是否以及在何种条件下应舍弃来自特定token的梯度。
注意,式(7)比式(5)就在后面多了一个M。
简单来说,就是让过分放大奖励和过分惩罚的token损失为0,完全不参与梯度更新(一定程度上等价于PPO带梯度的的clip)。其实PPO的clip动作看起来貌似就是类似的一个mask(把high和low值换成同一个ϵ)。
熵
还记得CISPO一开始的那句“同时通过内在机制将熵控制在合理范围内”吗?
说起熵,那是一个让人又爱又恨的东西,我们又不希望它太小——策略太稳定没探索了,也不希望它太大——策略太飘忽训练不稳定。其实这放在我们生活中也是一样,大多数情况下,我们既不希望生活一潭死水,但也不想每天心惊肉跳。你把“生活”换成“人生”其实也一样。
熵本质上是一种不确定性的度量,熵值太小,说明新的信息几乎不会对系统带来影响(信息量为0),系统趋于稳定;而熵值大,稍微一点信息就会对系统有影响,所以我们有最大熵原理。简单来说,在面临不确定性时,我们应该利用已知的信息让选择等可能性(不确定性最大)。关于熵,笔者之前也有不少文章提到过,感兴趣可以阅读附录1。
好吧,言归正传,这里其实是想顺带说说 Reasoning with Exploration: An Entropy Perspective[9] 这篇paper,本文发现:高熵区域与三类探索性推理行为存在正相关性:
- 决定或连接逻辑步骤的关键Token;
- 自我验证和修正等反思性行为;
- Base模型未充分探索的罕见行为。
说明熵可以作为识别语言模型中探索性推理行为的有用信号。于是,本文使用基于熵的项(经过裁剪并断开梯度的熵项)来增强优势函数。不过与传统的最大熵方法通过促进不确定性来鼓励探索不同,这里通过促进更长、更深的推理链来鼓励探索。
裁剪操作确保了熵项既不会主导优势项,也不会改变其符号,而梯度分离则保持了原始的优化方向。这一设计在保持策略梯度优化流的同时,增强了策略在不确定性下表现出的探索性推理行为。
此外,由于熵与策略置信度之间存在内在的张力关系(既要探索未知,又要利用已知;既要保持不确定性,又要有信心做出决策),随着置信度的提升,熵项会自然减弱——从而在训练早期鼓励探索,而在后期避免过度探索。
“熵与置信度之间的内在张力”意味着:模型在不确定时需要探索(熵高),而在确定后会自然减少探索(熵低)。这种动态变化使得基于熵的探索机制具有自我调节能力,不会一直被人为鼓励,从而避免了过拟合或奖励欺骗。
整体改动如下。
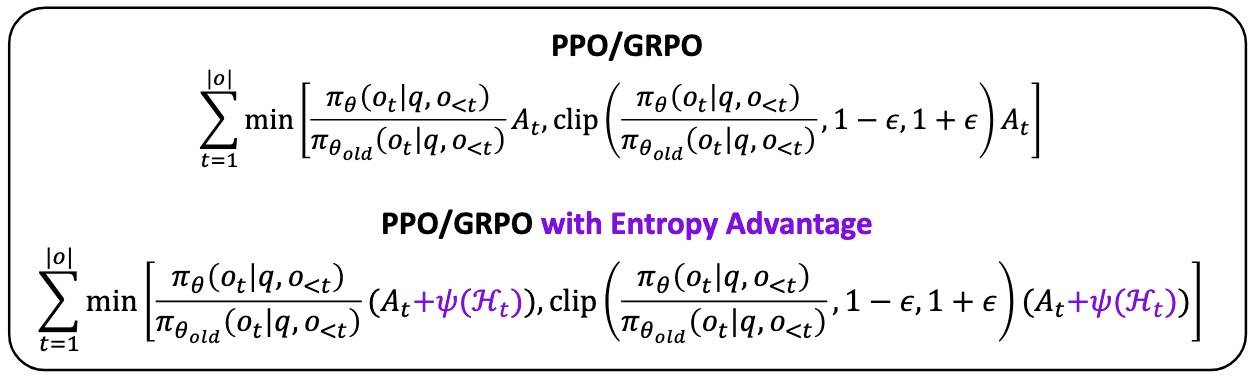
对于输出 o 中的每个Token ot,当前策略对词表 V 的熵为:
定义ψ(Ht)为:
其中,α 是缩放系数,κ 控制clip阈值。这个clip保证ψ(Ht)比阈值小,不会主导Advantage;另外,绝对值也确保了At<0时ψ(Ht)不会反转Advantage符号,从而保留原始优化方向。
更关键的是,熵项Ht detach掉了,因此它在梯度传播时仅作为一个固定的偏移量添加到原始Advantage上。这样做能够调整更新的幅度,但不会改变梯度的方向。这和CISPO的sg(IS)是类似的思想。
代码改动1行:
1 | # Compute advantages as in PPO or GRPO |
实证结果表明,当At>0时,更高的熵会导致对所选Token的更新更强,从而大幅提升其概率,使得输出分布更加集中。分布越集中,熵就越低,这反过来会降低 ψ(Ht) ,并削弱后续的更新强度。
和基于熵的正则项对比如下:

其中,A_shaped = At + ψ(Ht) 。
最终效果确实有少量提升。
小结
本文介绍了MinMax在MiniMax-M1中提出的CISPO,它的出发点是解决GRPO中的不当裁剪问题,尤其是与反思行为相关的token。出发点与DAPO的Clip-Higher类似,不过后者效果不明显,于是通过clip IS 后停止梯度,这样Token的update不会被截断,IS作为权重因子依然影响策略。
我们还介绍了关于熵的一篇paper,主要是观察到熵在探索方向的潜力,于是在Advantage上加了一个「经过裁剪并断开梯度的熵项」,调整了更新的幅度,但不改变梯度方向。
不知不觉,RL在LLM中的应用已经逐渐进入深水区了,我们在实际项目中也开始使用相关技术,确实取得了不错的效果。这个方向确实非常有意思,值得关注,笔者个人也一直比较感兴趣,之前有过一些思考(参阅这里[10]附录部分),感兴趣的读者可以关注hscspring/rl-llm-nlp: Reinforcement Learning in LLM and NLP.[11]
附录
附录1
笔者曾提到或讨论过熵的相关文章,有些内容可能很幼稚甚至不对,还望读者海涵。
- Reward Model建模 | Yam[12]
- DAPO:为GRPO的锦上加四点花 | Yam[4]
- 预训练:NTP和Scaling Law | Yam[13]
- 数据结构与算法:思考排序 | Yam[14]
- 信息熵与选择:由三门问题想到的 | Yam[15]
- NLP 与 AI | Yam[16]
- 人生随笔 | Yam[17]
- 中文分词系列一:思考分词 | Yam[18]
- 通过最优转移进行词表学习:VOLT | Yam[19]
- 自然语言计算机形式分析的理论与方法笔记(Ch02) | Yam[20]
- 自然语言计算机形式分析的理论与方法笔记(Ch16) | Yam[21]
- 剑指 Offer2(Python 版)解析(Ch2) | Yam[22]
- 西蒙《人工科学》读书笔记 | Yam[23]
References
[1] MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention: https://arxiv.org/abs/2506.13585
[2] VAPO:基于价值方法的新突破 | Yam: https://yam.gift/2025/04/19/NLP/LLM-Training/2025-04-19-VAPO/
[3] 异曲同工之妙的DrGRPO——DAPO几乎同时出现的又一GRPO优化! | Yam: https://yam.gift/2025/03/28/NLP/LLM-Training/2025-03-28-LLM-PostTrain-DrGRPO/
[4] DAPO:为GRPO的锦上加四点花 | Yam: https://yam.gift/2025/03/19/NLP/LLM-Training/2025-03-19-LLM-PostTrain-DAPO/
[5] R1相关:RL数据选择与Scaling | Yam: https://yam.gift/2025/02/27/NLP/LLM-Training/2025-02-27-LLM-PostTrain-PPO-Data/
[6] R1相关:DPO数据选择与DPO等RL算法 | Yam: https://yam.gift/2025/03/02/NLP/LLM-Training/2025-03-02-LLM-PostTrain-DPO-Data/
[7] R1相关:R1-Zero的进一步理解和探索 | Yam: https://yam.gift/2025/04/10/NLP/LLM-Training/2025-04-10-Think-More-about-R1-Zero/
[8] DAPO: https://yam.gift/2025/03/19/NLP/LLM-Training/2025-03-19-LLM-PostTrain-DAPO/
[9] Reasoning with Exploration: An Entropy Perspective: https://arxiv.org/abs/2506.14758
[10] 这里: https://yam.gift/2025/02/17/NLP/LLM-Training/2025-02-17-DeepSeek-R1/
[11] hscspring/rl-llm-nlp: Reinforcement Learning in LLM and NLP.: https://github.com/hscspring/rl-llm-nlp
[12] Reward Model建模 | Yam: https://yam.gift/2025/06/09/NLP/LLM-Training/2025-06-09-RM-Modeling/
[13] 预训练:NTP和Scaling Law | Yam: https://yam.gift/2025/02/28/NLP/LLM-Training/2025-02-28-LLM-Pretrain-NTP-and-ScaleLaw/
[14] 数据结构与算法:思考排序 | Yam: https://yam.gift/2018/12/31/DSA/Think-Ds-Algo/2018-12-31-Ch02-Thinking-Sort/
[15] 信息熵与选择:由三门问题想到的 | Yam: https://yam.gift/2019/06/19/Math/2019-06-19-Think-From-Three-Gates/
[16] NLP 与 AI | Yam: https://yam.gift/2018/07/22/NLP/2018-07-22-NLP-and-AI/
[17] 人生随笔 | Yam: https://yam.gift/2023/01/21/Diary/2023-01-21-Life/
[18] 中文分词系列一:思考分词 | Yam: https://yam.gift/2020/05/13/NLP/2020-05-13-Segmentation-Thinking/
[19] 通过最优转移进行词表学习:VOLT | Yam: https://yam.gift/2021/07/18/Paper/2021-07-18-VOLT/
[20] 自然语言计算机形式分析的理论与方法笔记(Ch02) | Yam: https://yam.gift/2018/10/11/NLP/NLPFA/2018-10-11-Ch02-Pioneers-in-Language-Computing/
[21] 自然语言计算机形式分析的理论与方法笔记(Ch16) | Yam: https://yam.gift/2019/04/04/NLP/NLPFA/2019-04-04-Ch16-Formal-Model-in-Statistical-Machine-Translation/
[22] 剑指 Offer2(Python 版)解析(Ch2) | Yam: https://yam.gift/2019/12/15/DSA/Coding-Review2/2019-12-15-CR2-Ch2/
[23] 西蒙《人工科学》读书笔记 | Yam: https://yam.gift/2018/09/30/AI/2018-09-30-The-Science-of-Artificial/
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。