刚出了 DAPO:为GRPO的锦上加四点花 | Yam[1],字节Seed团队马上就送来新的 VAPO[2],同样的清晰、高质量。
VAPO,全称 Value-based Augmented Proximal Policy Optimization,没错了,这是基于价值的方法。本文指出了困扰基于价值方法的三个关键挑战:价值模型偏差、序列长度异质性以及奖励信号的稀疏性,并分别对其进行优化,最终在 AIME 2024 上比 DAPO 提升10个点,并且更加稳定,需要的训练步数更少。
背景
我们知道,GRPO(以及其变种)移除了critic,通过一组输出的最终奖励来计算 Advantage,方法更简单,但关键是有效果,所以至今依然是主流(简单很重要)。相反,训练一个可靠的价值模型不但复杂,有额外开销,而且也难训好,复杂任务中往往不稳定。本文的出发点是:如果可以解决训练价值模型的挑战,基于价值的方法具有更高的性能上限。理由如下:
- 价值模型能更精确地进行奖励归因,通过准确追踪每个动作对后续回报的影响,促进更细粒度的优化。这对于复杂的推理任务尤为关键,在这类任务中,个别步骤中的细微错误常常会导致灾难性失败,而在无价值模型下进行优化仍然面临挑战。
- 与价值无关方法中基于蒙特卡洛方法(即用完整轨迹中的累积回报来估计策略好坏的一种方式)估计的Advantage相比,价值模型可以为每个Token提供方差更低的价值估计,增强训练稳定性。
- 训练良好的价值模型具有内在泛化能力,能够更高效地利用在线探索过程中遇到的样本,显著提升RL上限。
有点类似PPO Reward Model和DPO的区别,只要能训好价值模型,理论上效果应该是更好的。不过想“训好”有挑战:
- 由于轨迹较长且以自举方式学习价值函数本身具有不稳定性,因此学习一个低偏差的价值模型并不容易。
- 同时处理短回答和长回答也是一项挑战,因为它们在优化过程中可能表现出对于偏差-方差权衡的非常不同的偏好。
- 来自验证器的奖励信号本就稀疏,而CoT模式的长度进一步加剧了这一问题,这种模式本质上需要更好的机制来平衡探索与利用。
本文的 VAPO 就是想方设法解决上述挑战,包括长度适应GAE,DAPO的 Clip-Higher、Token级别损失,VC-PPO[3]的Value-Pretraining和Decoupled-GAE,SIL[4]的self-imitation learning,以及GRPO等。它是第一个明显优于无价值模型方法的基于价值的 RL 框架。
在开始前,先把几个相关的损失函数列一下。首先是RLHF的PPO:
其中,R是使用Reward Model计算得到的Token级别的奖励,KL则保证策略模型不偏离ref模型太远,具体是用下面的式子表达的。
这和我们看到的另一种写法(比如R1相关:DPO数据选择与DPO等RL算法 | Yam[5]中的)是等价的。
然后是PPO:
其中:
表示当前策略和旧策略在同一个状态下选择动作的概率比,分子是当前策略在状态st下选择动作at的概率,分母类似。比值大于1,表示新策略更倾向于选这个动作;相反,说明新策略不再倾向选这个动作。
策略一般鼓励Advantage比较高的Action,Advantage通过GAE计算完成:
其中:
表示TD误差。R表示t步的奖励,V就是价值函数,γ是折扣因子(通常设置为接近1),λ是GAE的参数(通常设置为0.95)。
挑战
接下来我们展开说明三个挑战。
长序列价值模型偏移
在VC-PPO中,使用奖励模型初始化价值模型会引入明显的初始化偏差。这源于两个模型之间的客观不匹配。奖励模型是在Token <EOS>上进行评分,导致早期Token分数较低;相反,价值模型在给定policy下估计 <EOS> 前面所有Token的期望累积奖励,在早期训练阶段,鉴于 GAE 的反向计算,沿轨迹累积的每个时间步 t 都会有一个正偏差。
另外,GAE常用实践标准的λ = 0.95可能会加剧这个问题。在结束Token处的奖励信号 R(st, <EOS>) 会以 λ(T-t)R 的形式向后传播到第 t 个Token。当序列较长(T-t≫1)时,有效奖励信号会被削弱到几乎为0(比如 0.95100≈0.006)。因此,终止奖励(时间步T)对早期时间步 t 的影响几乎可以忽略不计。此时,价值函数的更新几乎完全依赖于自举(R部分几乎为0),导致依赖于高偏差的估计。而价值模型的要求就是稳定、方差小,否则GRPO就够了(基于蒙特卡洛,偏差小、方差大)。
关于GAE参数的讨论,可以参考R1相关:RL数据选择与Scaling | Yam[6],这里再稍微展开一下。考虑式(5),当 λ=0 时,At=δt,GAE 退化为单步 TD 误差(高偏差,低方差);当 λ=1 时,GAE 等价于蒙特卡洛(MC)回报(低偏差,高方差)。实际取0.95是一个折中考虑,在高方差和高偏差之间做平衡。
这里的关键问题就是最终时间步T的奖励 R(sT, <EOS>) 是模型唯一直接观测到的外部(稀疏)奖励。这里假设T+1为<EOS>。式(5)可以展开为:
其中:
除了最后一项,其他项没有R。因此,对时间步t,当T-t很大时(也就是T很长时前面的Token),最终奖励对Advantage的贡献几乎为0,Advantage几乎完全依赖未来的Value估计。此时,价值模型V(St)(通常拟合真实回报)的更新主要依赖V(St+1),即自举,而不是真实的外部奖励信号。意味着价值模型的更新依赖于自身的估计,如果初始值模型存在偏差(如因奖励模型初始化导致的正向偏差),这种偏差会通过自举不断累积,从而导致价值模型的估计越来越不可靠。
展开一下价值模型如何更新。价值函数的训练目标通常是拟合真实的回报Rt,这个回报是通过GAE间接算出来的。
它的Loss如下:
这里的Rt是目标回报,即认为某个状态St将来会得到多少奖励。式(9)来自Advantage的定义:
因为在Actor-Critic方法中没有Q网络,因此用式(9)这个估计值来表示未来总奖励,自然也就是价值函数的训练目标。
Q:动作价值函数;V:状态价值函数;Q-V=A。
将式(9)代入式(10)后,Loss变为:
它的本质就是让Advantage趋近于0,即当前状态的价值预测已经完美了,那它和真实回报之间的误差应该就是 0。也就是说,理想状态下,每一步价值预测都能知道最终结果是不是对的。
这里很自然有个问题,这只有最后一步有奖励,价值函数还能学习吗?当然可以了!因为未来的回报仍然是非零的,如刚刚所言,它就是要学习:当前这个状态,未来可能会达成的最终奖励。GAE 会通过TD 残差以及λ 的传导把这个终点奖励传回前面。这也是为什么会有本节前面提到的λ = 0.95导致的价值模型偏移问题。
举个例子,假设:
- 轨迹长度为 T = 5
- 奖励为:r0 = r1 = r2 = r3 = 0, r4 = 1
- 折扣因子γ=1,GAE 衰减因子λ=0.95
- 价值函数预测:暂定全部为 0(初始状态),实际是价值函数输出值
为了方便计算,把式(5)写成递推式:
计算过程如下:
- 计算δt。根据式(6),δ4 = 1+0-0 = 1,其他δ均为0
- 用GAE计算Advantage,根据式(13),从后往前递推。
- A4 = δ4 = 1
- A3 = δ3+γλA4 = 0 + 0.95×1 = 0.95
- A2 = 0.95×0.95 = 0.9025
- A1 = 0.95×0.9025 = 0.8574
- A0 = 0.95×0.8574 = 0.8145
- 根据式(9)计算Return。即为前一步的A
- 用式(10)计算Loss:1/2/5 × (A0^2 + … + A4^2) ≈ 4.1156/10 ≈ 0.4116
代码如下:
1 | import torch |
输出结果为:
1 | Advantages: tensor([0.8145, 0.8574, 0.9025, 0.9500, 1.0000]) |
实际在PPO中,计算损失的values是参与损失的,而用于得到returns的values则不参与损失(推理模式下计算得到)。
另外,批量计算GAE时需要Mask,即每条轨迹计算到哪里截止,可以参考这个项目[7]的实现。
训练时异构序列长度
在复杂推理任务中,模型的回复长度往往差异很大,这要求算法足够鲁棒,能处理非常简短到非常长的序列。此时,常用的固定 λ 参数的 GAE面临挑战。即便模型已经很好了,固定的 λ 也可能无法高效适配长度变化的序列。显著的问题就是:短序列高方差、长序列高偏差。因为GAE本质是方差和偏差的权衡,回复短时,估计结果更偏向于方差主导的一侧;回复长时,又因为引入自举而导致较高的偏差。GAE的递归特性依赖于未来状态,这种机制在长回复中会累积误差,加剧偏差问题。
稍微解释一下,短序列时,由于 λ 比较大,GAE 接近蒙特卡洛。举个例子,比如生成的回复只有一个Token:“好”,此时,GAE会直接用终止奖励计算优势,但短序列的奖励噪声可能很大(比如“好”和“坏”对应的奖励可能是1和0)。相反,长序列时,GAE 主要靠自举,如果 V 的估计不准,误差就会一直累积,结果就是模型无法学习长期依赖,早期Token的生成质量难以提升。
其根本原因就是 GAE 的指数衰减框架,它的本质其实是指数衰减求和。指数衰减的局限性就是:
- 短序列:权重集中在前几步,奖励信号未充分平滑→高方差。
- 长序列:权重分散,早期信号被过度衰减→高偏差。
这里很直观的思路就是使用动态 λ,也正是本文思路,我们后面再说。
验证任务奖励稀疏性
与传统(如RLHF)的奖励模式不同,复杂推理任务经常使用二元验证器(一般是规则)作为奖励模型,而非稠密信号(连续值)。这种奖励信号的稀疏性在长链推理中尤其严重,长序列不仅增加了计算时间,也降低了获得非零奖励的频率。
而在策略优化过程中,生成正确答案的样本可能极其稀少而宝贵。带来的问题就是探索-利用困境:一方面,模型需要保持较高的不确定性,从而输出多样化的回复,提升生成正确答案的可能性;另一方面,又必须高效利用通过艰难探索获得的正确样本,以提高学习效率。
稀疏奖励导致训练信号极度稀缺,而CoT则加剧了这种稀疏性,只有最终答案完全正确时才能获得奖励1,中间任何一步错误都会导致奖励为0。
模型为避免陷入局部最优(比如重复生成错误模式),就必须充分探索多样化推理路径,保持策略的高不确定性。而正确样本又过于珍贵,需要模型高效利用它们进行学习,利用不足会浪费正确样本的指导价值。
这里的根本原因就是二元奖励无法区分“接近正确”和“完全错误”的回复,反正只要答案是错的,那就0分,不管中间对了多少。这看起来就很不合理对吧,所以逐步验证的奖励设计还是有必要的,我自己之前在KK[8]数据集上对此进行过尝试,奖励有明显提升,如下图所示。
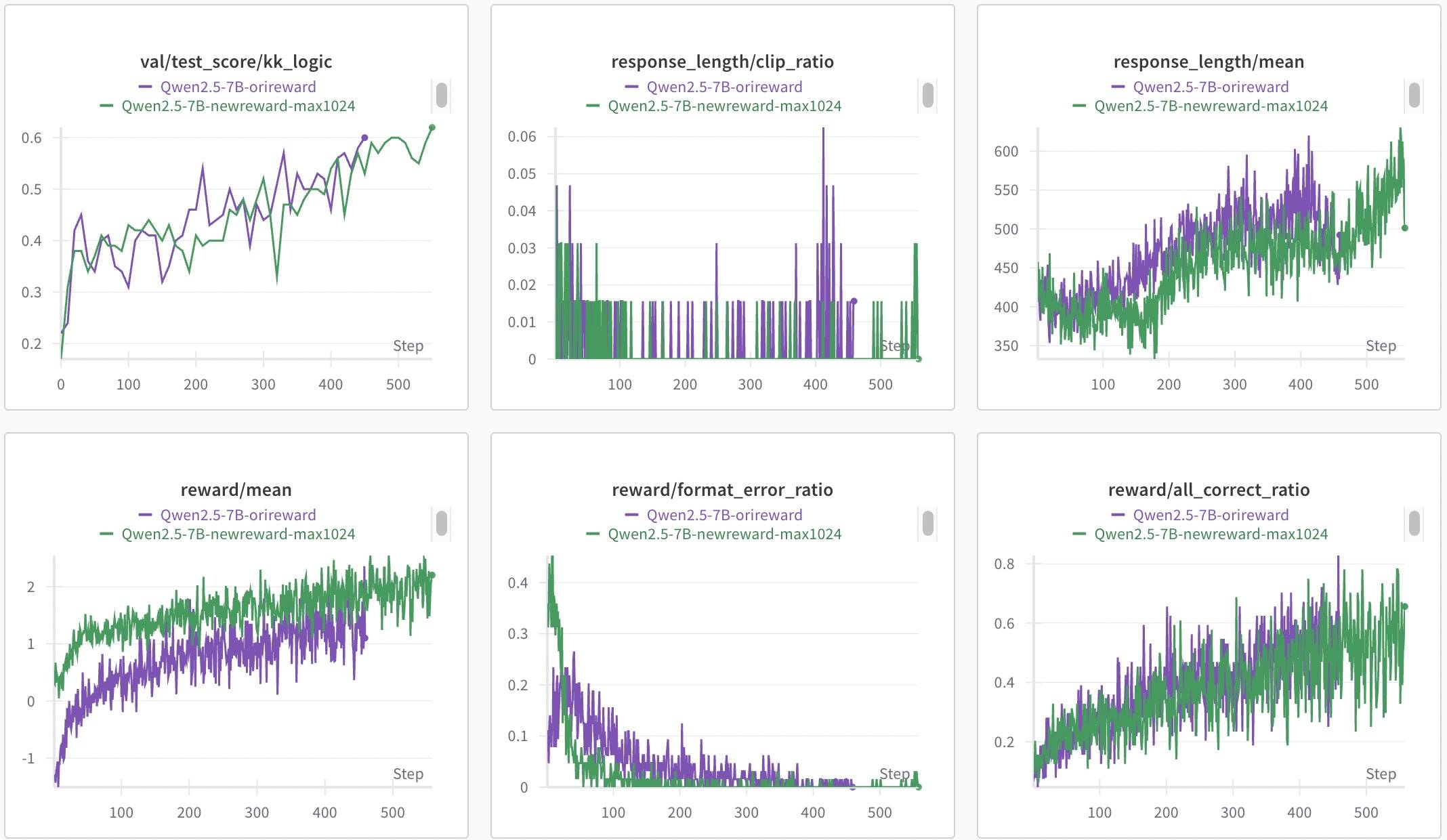
图中绿色曲线对应的就是新的奖励设计,我们看第二行第一幅图,整体有一个较明显的提升幅度。不过最终Acc(第一行第一幅图)相差不大,可能的原因猜测如下:
- Acc计算方式与Reward奖励方式不同:Acc按所有人都对得1分,否则0分计算;Reward按猜对1个人就给分,猜错扣分的逻辑。这个可能是直接原因。
- 训练数据集只选择了3个人:3个人还是比较少,任务难度也低。
- 奖励模式设计不合理:调整后的Reward奖励方式其实还是看结果的,而不是“逐步验证”,所以Reward的增加是必然的,但其实对最终结果(按Acc的逻辑)意义不大。这个可能是根本原因。
KK数据集:KK表示knights和knaves,骑士和恶棍。
题目示例:一座非常特殊的岛屿,岛上只有骑士和恶棍居住。骑士总是说真话,恶棍总是说谎。你遇到两个居民:佐伊和奥利弗。佐伊说:"奥利弗不是骑士。"奥利弗说:"只有佐伊是恶棍,奥利弗才是骑士。"那么谁是骑士,谁是恶棍?
需要判断两个角色的身份。答案是:“(1) Zoey 是个恶棍; (2) Oliver 是个骑士”。
这是2个人的子集,数据集包含从2个人到8个人的不同子集。上面的实验基于3个人这个子集。
方案
说完挑战,接下来看本文给出的方案。下面的方案是和前面的挑战一一对应的。
缓解长序列价值模型偏移
主要是两个策略:价值模型预训练(Value-Pretraining)和分解(或解耦)GAE(Decoupled-GAE),思路均借鉴自VC-PPO[3]。
Value-Pretraining
在 CoT 任务中直接应用 PPO 容易失败,常见的问题包括生成输出长度崩塌和性能下降。其根本原因在于:价值模型通常是从奖励模型初始化的,但两者的目标函数并不一致,存在不匹配的问题。这点我们在前面挑战时也提到过。本文的Value预训练步骤如下:
- 持续从固定策略(如 πsft)中采样生成响应,并使用蒙特卡洛回报更新价值模型。固定策略目的是确保生成的数据分布稳定,避免策略更新与价值训练相互干扰。
- 训练价值模型,直到关键指标(如 value loss 和 explained variance)达到足够低的水平。
- 保存训练好的价值模型的checkpoint,并在后续实验中加载该模型用于初始化。
这样做的目的是通过MC回报提供无偏奖励信号,避免自举导致的偏差累积(尤其在长序列中),为后续RL阶段提供一个高质量的价值函数初始化,减少训练不稳定。
Decoupled-GAE
即解耦了policy和value model的Advantage计算,对value模型,采用λ = 1.0,对policy模型,使用较小的 λ(如0.95)来加速收敛。
管理训练时异构序列长度
主要是两个策略:长度自适应GAE(Length-Adaptive GAE)和Token级别损失(Token-Level Policy Gradient Loss),后者我们已经在DAPO:为GRPO的锦上加四点花 | Yam[1]中介绍过了,没错,就是沿用了DAPO的设计。
Length-Adaptive GAE
policy的λ设置为0.95的问题在挑战部分已经说过,主要是长回复序列因为自举导致的偏差。长度自适应GAE就是根据序列长度动态调整 λ,在短序列和长序列之间更好地平衡偏差与方差,提升整体估计性能。为确保不同长度的序列中TD误差分布均匀,本文设计了λ系数的总和与输出长度L成正比:
其中 α 是控制整体偏差-方差权衡的超参数(论文取0.05)。于是有:
也就是说,长度越长,λ越大,缓解长序列信号衰减导致的偏差;长度越短,λ越小,减少蒙特卡洛回报的方差。
Token-Level Policy Gradient Loss
DAPO中专门讲过,这里不展开了。简单来说,原有的GRPO中,所有 Token 的损失首先在序列级别按Token进行平均,然后再在 batch 级别进行平均。这就导致来自较长序列的 Token 对最终损失值的贡献会相对较小。因此,如果模型在处理长序列时出现关键性问题(这一现象在强化学习训练的探索阶段尤为常见),由于这类问题在损失中的权重被削弱,可能导致训练过程不稳定,甚至发生崩溃。
处理验证任务的稀疏奖励
主要通过三个策略:Clip-Higher、Positive Example LM Loss和Group-Sampling,提高稀疏奖励场景下探索-利用权衡的效率。
Clip-Higher
也是DAPO的策略,简单来说,clip的上限会限制Policy的探索能力,它限制低概率Token的概率增长,从而限制了多样性。本文high值设为0.28,low值设为0.2,与DAPO一致。
Positive Example LM Loss
这个设计旨在提升强化学习训练过程中正样本的利用效率。在复杂推理任务的RL中,部分任务表现出极低的准确率,大多数训练样本都会生成错误答案。传统的策略优化方法主要通过压制错误样本的生成概率来进行更新,但这种基于试错机制的方式在RL中计算代价极高,效率较低。因此,当策略模型偶尔采样到正确答案时,如何最大化其利用价值就特别关键。
本文引入了一种模仿学习的方法:对于策略模型采样到的正确结果,额外加入负对数似然(Negative Log-Likelihood, NLL)损失,从而强化模型对正确示范的学习。
T 表示正确答案的集合。最终的Loss如下:
本文μ=0.1。
Group-Sampling
用于使用相同 prompt 采样具有区分性的正负样本。在固定计算预算的前提下,有两种主要的计算资源分配方式:
- 尽可能使用更多的 prompt,每个 prompt 仅采样一次。
- 减少每个 batch 中不同 prompt 的数量,将计算资源用于对相同 prompt 进行多次生成。
实验发现,后者性能略微更优。这归因于它引入了更丰富的对比信号,增强了策略模型的学习能力。
效果
最终效果如下:
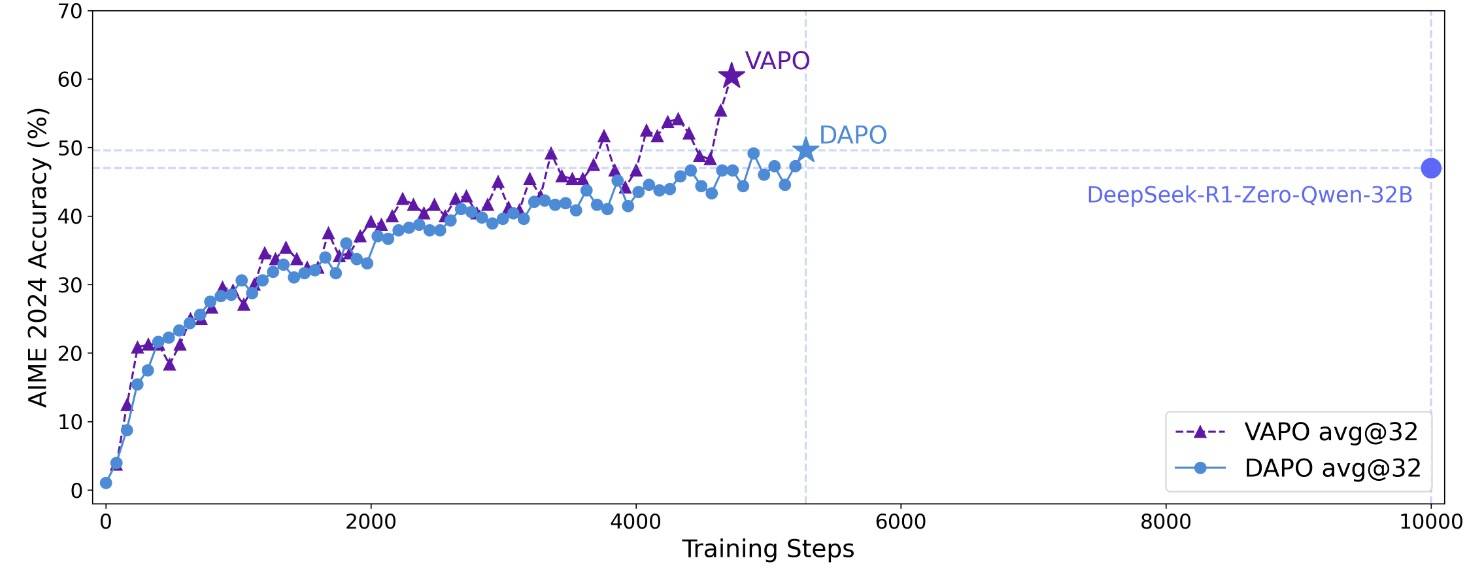
VAPO以更少的步骤取得比DAPO更好的性能。
各个优化点性能提升如下:
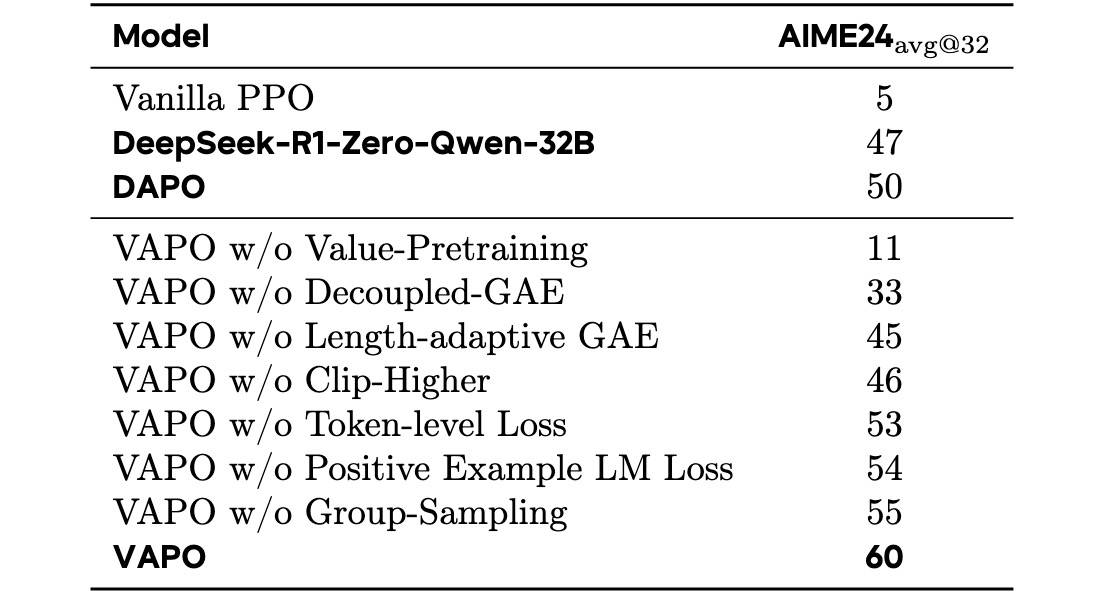
上表的顺序也就是VAPO各个优化点的贡献排序。显然,Value-Pretraining和GAE的优化占了相当的比例,重要性极高(VAPO的分数减去列出的分数就是贡献分)。
小结
本文从三个方面分析了基于Value的PPO算法在long-CoT、仅验证结果的推理任务中的挑战,并针对性地提出了对应的解决方案。对长序列价值模型偏移问题,使用Value-Pretraining和Decoupled-GAE;对训练时的异构长度问题,使用Length-Adaptive GAE和Token级别损失;对验证类任务奖励稀疏性问题,使用Clip-Higher、Positive Example LM Loss和Group-Sampling。这些优化中,Clip-Higher和Token-level Loss来自DAPO,Group-Sampling来自GRPO,剩余部分比较有意思的是针对GAE的优化,虽然看起来比较简单,但能发现这些问题并做出有效果的改进也是不容易的。总的来说,非常有价值,论文也一如既往的清晰、干净,值得一读。
References
[1] DAPO:为GRPO的锦上加四点花 | Yam: https://yam.gift/2025/03/19/NLP/LLM-Training/2025-03-19-LLM-PostTrain-DAPO/
[2] VAPO: https://arxiv.org/abs/2504.05118
[3] VC-PPO: https://arxiv.org/abs/2503.01491
[4] SIL: https://proceedings.mlr.press/v80/oh18b.html
[5] R1相关:DPO数据选择与DPO等RL算法 | Yam: https://yam.gift/2025/03/02/NLP/LLM-Training/2025-03-02-LLM-PostTrain-DPO-Data/
[6] R1相关:RL数据选择与Scaling | Yam: https://yam.gift/2025/02/27/NLP/LLM-Training/2025-02-27-LLM-PostTrain-PPO-Data/
[7] 这个项目: https://github.com/zplizzi/pytorch-ppo
[8] KK: https://github.com/AlphaPav/mem-kk-logic
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。