今天介绍一篇 Agentic RL 的小文章吧,来自 2602 Think Fast and Slow: Step-Level Cognitive Depth Adaptation for LLM Agents[1],我们在《LLM 的下一步:从“会答”到“会想”——Planning as Data 与思考范式重构 | 长琴[2]》中提过一嘴,不过当时关注的是它的认知结构(本文不再赘述)。这里重点看下它提出来的 COPO(认知感知策略优化)——用于通过置信度感知优势重加权来实现步骤级的权重分配。
出发点很简单,GRPO 对轨迹中的所有步骤统一分配优势,并不会区分每一步所采用的认知模式在当前上下文中是否合适。COPO 基于动作预测的置信度,实现了逐步(step-level)的信用分配。这里有个关键洞察:合适的认知模式应当能够促进模型做出高置信度且正确的动作选择。
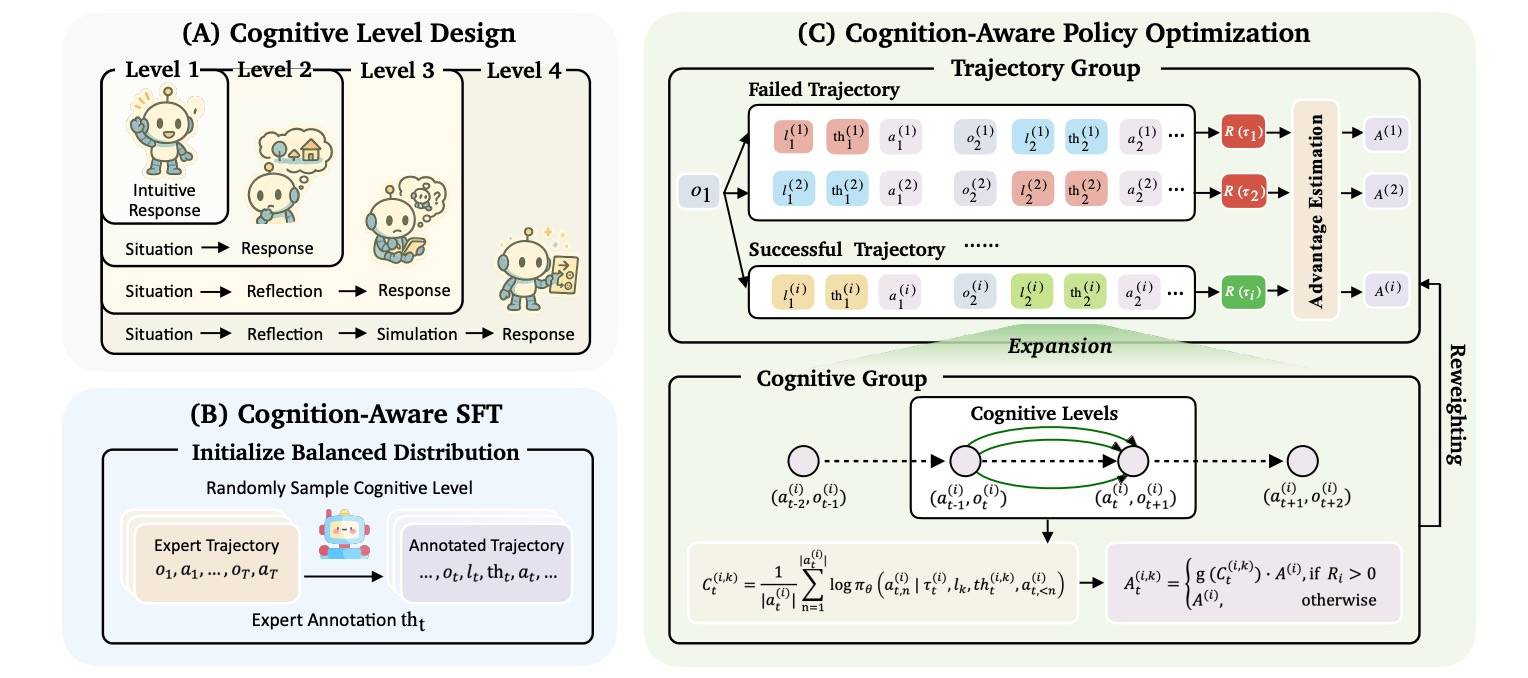
看图 C,Cognitive Group 会对每一步的 advantage 重新赋权。下面看看具体细节。
L1(本能反应)、L2(情境意识)、L3(经验整合)和L4(战略规划)。
认知组构建
这一步是针对成功的轨迹,在每一步构建 cognitive group(认知组),具体做法很简单:在保持 observation 和 action 固定的前提下,基于 4 个认知等级重新生成思考过程。对轨迹 i,有 group et(i,k)=[lk,thti,k,ati],lk 就是第 k 个 level(共 4 个)。
为了评估每种认知层级的适用性,考察模型在以不同思维过程为条件时,对动作预测的置信程度:
Ct(i,k)=at(i)1n=1∑at(i)logπθ(at,n(i)∣τt(i),lk,tht(i,k),at,<n(i))
at,ni 是 action ati 的第 n 个 token,τ 是轨迹,更高的置信度分数表明该思维过程与最终动作之间具有更强的一致性。
基于置信度的优势重加权
为了在每个组内比较不同的认知层级,对置信度分数进行归一化处理:
Cnorm ,t(i,k)=σt(i)Ct(i,k)−μt(i),
这个归一化是在 cognitive group e 层面做的。然后 softmax 到权重:
g(Ct(i,k))=∑j=14exp(m⋅Cnorm ,t(i,j))exp(m⋅Cnorm ,t(i,k)),
m 是温度。这些权重在不改变总优势值大小的前提下(g 的和为 1),将其在不同认知层级之间重新分配。
At(i,k)={g(Ct(i,k))⋅A(i),A(i), if Ri>0 otherwise
A 就是 GRPO 的标准形式。
注意,这里只针对成功的轨迹重加权,放大有助于产生高置信度动作预测的认知层级的优势,同时削弱不确定性较高的部分。对于失败的轨迹,则不会构建认知组,其优势仍然保持在轨迹层级。
COPO
综上所述,得到最终的优化目标:
JCoPO(θ)=Ex∼X,{τ(i)}i=1G∼πθold(⋅∣x)G1i∈I+∑e(i)1t=0∑Tk=1∑4n=1∑et(i,k)min(rt,n(i,k)A^t(i,k),rˉt,n(i,k)A^t(i,k))+i∈I−∑y(i)1t=0∑Tn=1∑yt(i)min(rt,n(i)A^(i),rˉt,n(i)A^(i))−βDKL[πθ∥πref],
其中,i∈I+ 就是成功的轨迹,失败的轨迹做法就是标准 GRPO,r=clip(r,1−ε,1+ε)。
效果表格就不贴了,看个收敛速度的小图(也包含成功率 SR):
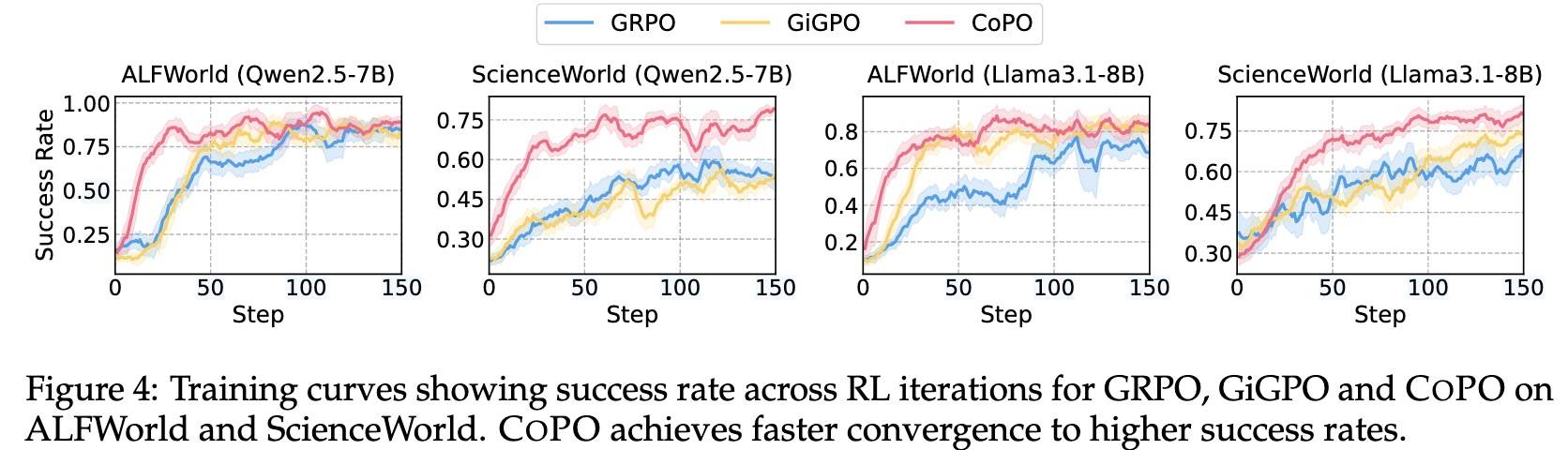
可以看到,提升还是非常明显的。
然后训练后不同 Level 的分布是这样的:
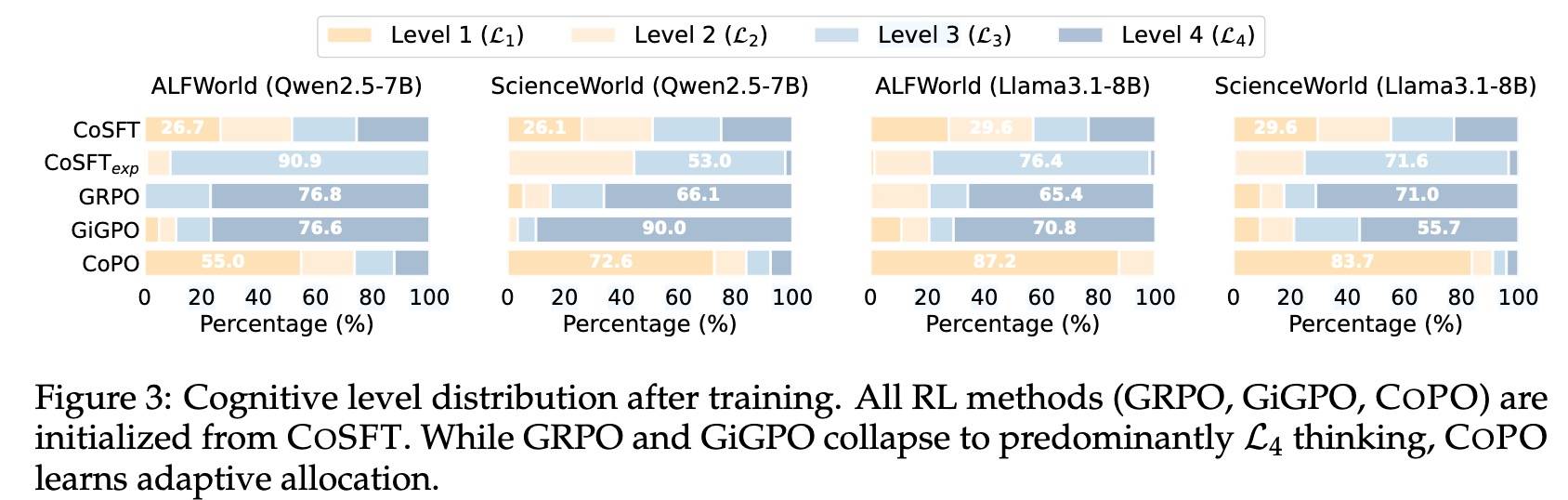
SFT 还是分布比较均衡的,RL 后和其他算法表现出明显的不同,GRPO 和 GiGPO 都倾向于 L4(更深层的思考通常与更高的最终奖励相关),COPO 则实现逐步的自适应思考——只在有益时才采用更深层的思考。
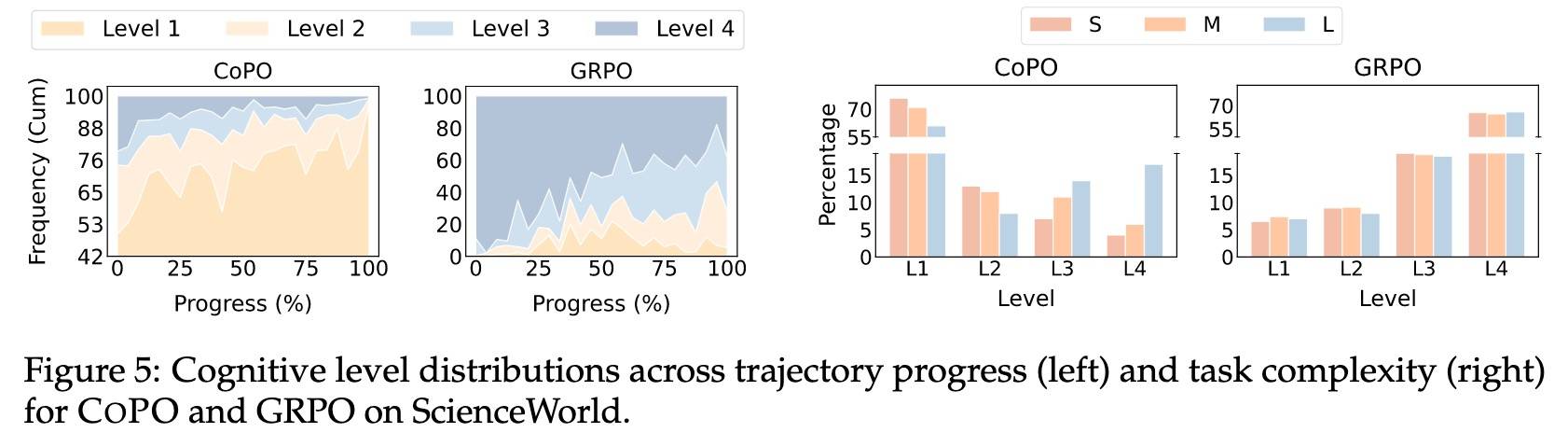
如上图左所示,L4 在初始化阶段达到峰值,此时复杂任务需要全局目标评估和长时规划,随后占比开始下降;L2 同样在初始阶段占主导,因为此时对环境的感知对于解析观测信息和评估可选动作至关重要,随后稳定;L1 一路上升,说明后期大多数步骤已经转化为无需深度思考的常规执行;L3 在各阶段相对均匀,只有在出现错误或需要借助过往经验进行决策时才会在特定上下文中出现。
L1(本能反应)、L2(情境意识)、L3(经验整合)和L4(战略规划)。
COPO 的这种结构化的分配在认知上是合理的:初始化阶段以战略规划为主,探索阶段依赖环境感知,随着流程逐渐明确,常规执行占比提升,而反思则在必要时出现。相比之下,GRPO 从始至终都被 L4 思维所主导(全程超过 50%),无论步骤复杂度如何都趋向于统一的深度推理。
上图右边则是算法对短(S)、中(M)和长(L)三类任务(轨迹越长越复杂)的感知情况,COPO 展现出明显的复杂度感知适应能力:能够随着任务复杂度的提升按比例增加认知投入。而 GRPO 在所有难度级别上都保持近乎均匀的分布。
小结
我们看到 COPO 的思想其实非常的直观,而且你看,其实它还是变着花样搞数据,而且目测,这种 ”花样“ 还会有更多。原因也很简单,对于后训练来说,数据一定是排在第一位的,具体来说——什么样的数据以什么样的方式给模型——就是后训练的核心了。
Reference
[1] 2602 Think Fast and Slow: Step-Level Cognitive Depth Adaptation for LLM Agents: https://arxiv.org/abs/2602.12662
[2] LLM 的下一步:从“会答”到“会想”——Planning as Data 与思考范式重构 | 长琴: https://yam.gift/2026/04/17/NLP/LLM-Training/2026-04-17-Think-Strategy/
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。