上次提到《当我20天的账单超过4000美元 | 长琴[1]》应该只是众多使用 AI Coding 场景中的一个缩影,本文还是以我自己为例,继续聊聊 AI Coding 以及 AI。
SIS:不硬clip,大部分token其实可转为on-policy
关于重要性采样系数,之前已经介绍过不少了,不过主要方案还是 clip,比如《GRPO“又一背锅侠”:Clip的各种拉扯 | 长琴[1]》中介绍的一系列文章,更进一步的优化是《GRPO优化在继续——CISPO和熵 | 长琴[2]》的 sg 和 特定 token mask,Minimax 后续模型也都用了自家的 CISPO,但是依然没有脱离 clip 和超参数设置。
Clip 有助于训练稳定,这没问题,但它最大的问题是会抑制来自高偏差策略样本的梯度,从而丢失有价值的学习信号。本文我们介绍的 SIS(Selective Importance Sampling)来自论文 Turning Off-Policy Tokens On-Policy: A Plug-in Approach for Improving LLM Alignment (arxiv:2607.04728)[3](文章图片、公式均来自此论文),在这个方向上再进一步。他们的出发点很简单——将那些 off-policy 的 token 转为 on-policy,自然就不需要 IS 了。具体怎么做的呢?他们将旧策略作为建议分布,执行 token 级别的拒绝测试:被接受的 token 自然就可以看作 on-policy 的,被拒绝的那就保持原来的 IS。
SIS 是即插即用的,仅修改重要性采样系数,而且它还有个正的外部性——提升训练的稳定性。关于稳定性我们在《GRPO“第一背锅侠”Token Level X:DAPO/DrGRPO与GSPO/GMPO的殊途同归 | 长琴[4]》提过,后面又专门写了两篇相关文章:《稳定压倒一切:MoE RL 训推不一致问题及解决策略 | 长琴[5]》、《MoE RL 训练不稳定性再思考:训推不一致,还是采样噪声? | 长琴[6]》,感兴趣的同学可以进一步阅读。
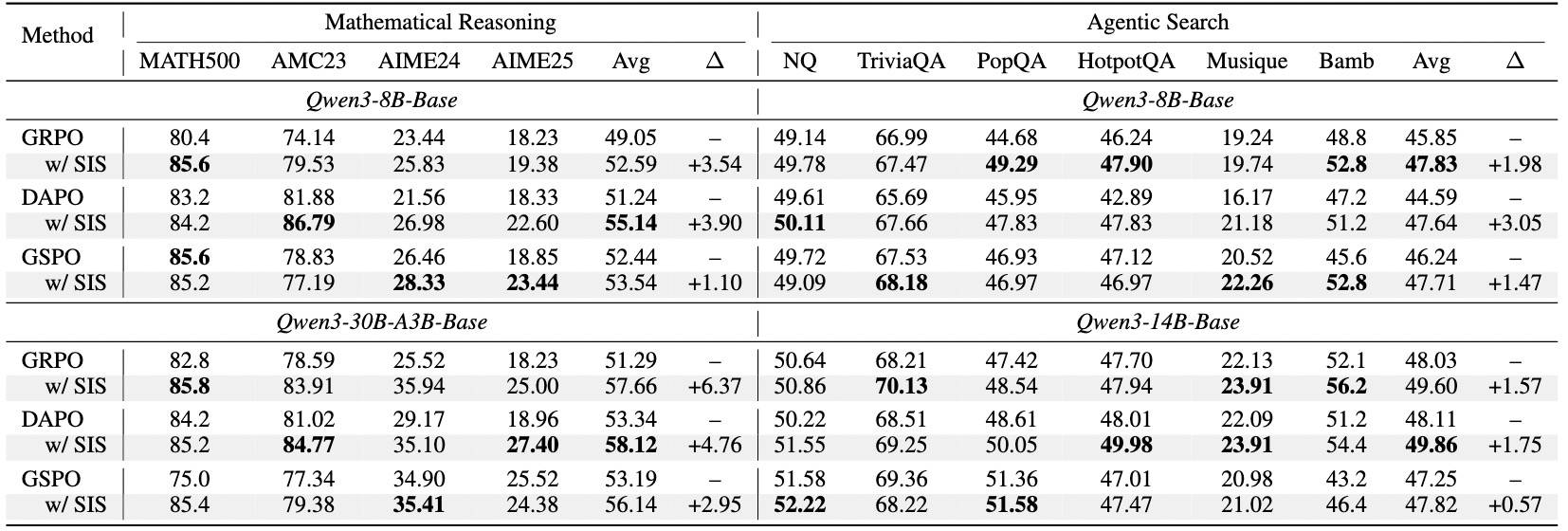
这里的问题或麻烦可能在于引入一个拒绝测试,不过论文给出了一个近似做法,使整个计算保持较低计算成本。效果和稳定性双全(见下表),值得一试。
从 SVM 到分布对齐:后训练方法的另一个统一视角
关于 Agentic RL 相关的我们之前已经介绍过几篇了:
- GiGPO:双层级优势函数驱动的Agent强化学习新范式 | 长琴[1]
- COPO:基于认知模式的 Step-Level Agentic RL 优化 | 长琴[2]
- GAGPO:如果把GiGPO拉回PPO+GAE | 长琴[3]
要说这类任务和普通任务的区别,可能最明显的就是「Step」这一步的处理了。和 LLM 不同,长程 agent 任务(尤其是机器人)经常会有物理意义上的多步,那是真正的 step,而不是多步推理那种多个 token。正是因为这种相对稳定的 step 特性,所以这种类似 “锚点” 的 step 就能给 RL 带来不一样的启示。今天我们就来介绍一个有意思的设计,它通过一个分类器把稀疏的结果奖励转为稠密的过程奖励。
为什么TRPO在LLM里不能用?——FiberPO的起点
我们在《TRPO深度拆解:为什么做后训练应该读懂TRPO | 长琴[1]》中详细挖了一下 TRPO,开头说到不得不上就是因为看到 FiberPO 了——非常 nice 的文章,又是个人非常喜欢的类型。FiberPO 比较长,本文是系列第一篇,主要介绍 vanishing theorem。
VLA Sim-Real 协同训练
一直对 EmbodiedAI 比较关注,大概是从 2103 A Survey of Embodied AI: From Simulators to Research Tasks[1] 开始,主要是一直对机器人感兴趣,看了《超能陆战队》后就总想自己也搞一个,再加上自己也是搞 AI 算法,关注到这个方向其实是比较自然的。后面陆续出来 RT-2: Vision-Language-Action Models[2]、SayCan: Grounding Language in Robotic Affordances[3]、2303 PaLM-E: An Embodied Multimodal Language Model[4] 等研究(都是 Google 的),不过再往后就基本没怎么关注了。工作忙起来了,事情也多起来了。
不过事情来到 2026 年就不一样了,记得我在 2025 年底跨年夜晚上发了一条朋友圈:“2025是RL、多模态、AI Coding年。2026继续,再补一个Embodied AI”,没几个月过去已经开始应验,现在半年过去简直要暴走。我自认为自己在这个方向还是比较浅薄的,所以准备补一补,多读几篇相关论文,本文就从《2602 Beyond Imitation: Reinforcement Learning-Based Sim-Real Co-Training for VLA Models[5]》开始吧。
当我20天的账单超过4000美元
最近一阵用 AI 更加频繁了,工作模式、学习模式出现了非常明显的计算机化——大脑=CPU,不停切换时间片,并发处理多线任务。工作上 3-5 个是常态,另外还有 2-3 个学习相关的,还有 1-2 个是其他项目。多管齐下,半个多月就快 3900 美元了——有点顶不住了。
然后最近 AI 非常疯狂啊,表现出超巨大的虹吸效应——所有 AI 相关的领域都在疯狂吸金,其他方向要么加入 AI,要么瑟瑟发抖。感觉 AI 对整个社会的冲击大于历史上任何一次的技术冲击。这件事情本身就非常恐怖,放几年前没有人会相信。
今天这个文章预计会比较散,因为也没有啥具体主题,但最近就是非常想写一点这方面的感受,顺便分享一些自己的心得感受。
你可能没那么懂 SFT:SFT 与 RL 的爱恨纠葛
背景
说起 SFT,可能只要是这一行的,哪怕刚入门都能说道几句,但当我们仔细深入分析后就会发现它没那么简单。就好像你知道自然音阶,也能在钢琴上找到 do re mi fa suo la xi,但弹不好一首曲子。
GAGPO:如果把GiGPO拉回PPO+GAE
今天介绍一篇 Agentic RL 相关的比较巧妙的论文:2605 GAGPO: Generalized Advantage Grouped Policy Optimization[1],如果用一句话简要概括,那就是:“用 GROUP 的方法计算 V”,效果不错,以至于当时看了第一反应是怀疑。不过仔细阅读全文后,发现确实很有意思,而且实验也比较全面。
它的出发点很简单——不要 Value 模型,怎么把后续结果有效地回传到每个中间步骤。本文提出的 GAGPO = Generalized Advantage Grouped Policy Optimization,它是一种无需 Critic 的 RL 算法,能够实现精确的、与步骤对齐的时序 credit assignment。
做法更加简单——从采样得到的 rollout 中构建一个非参数化的分组价值代理,然后通过 TD/GAE 把最终结果的监督信号沿时间维度传播到前面的每一步(注意是 Step,不是 Token)。
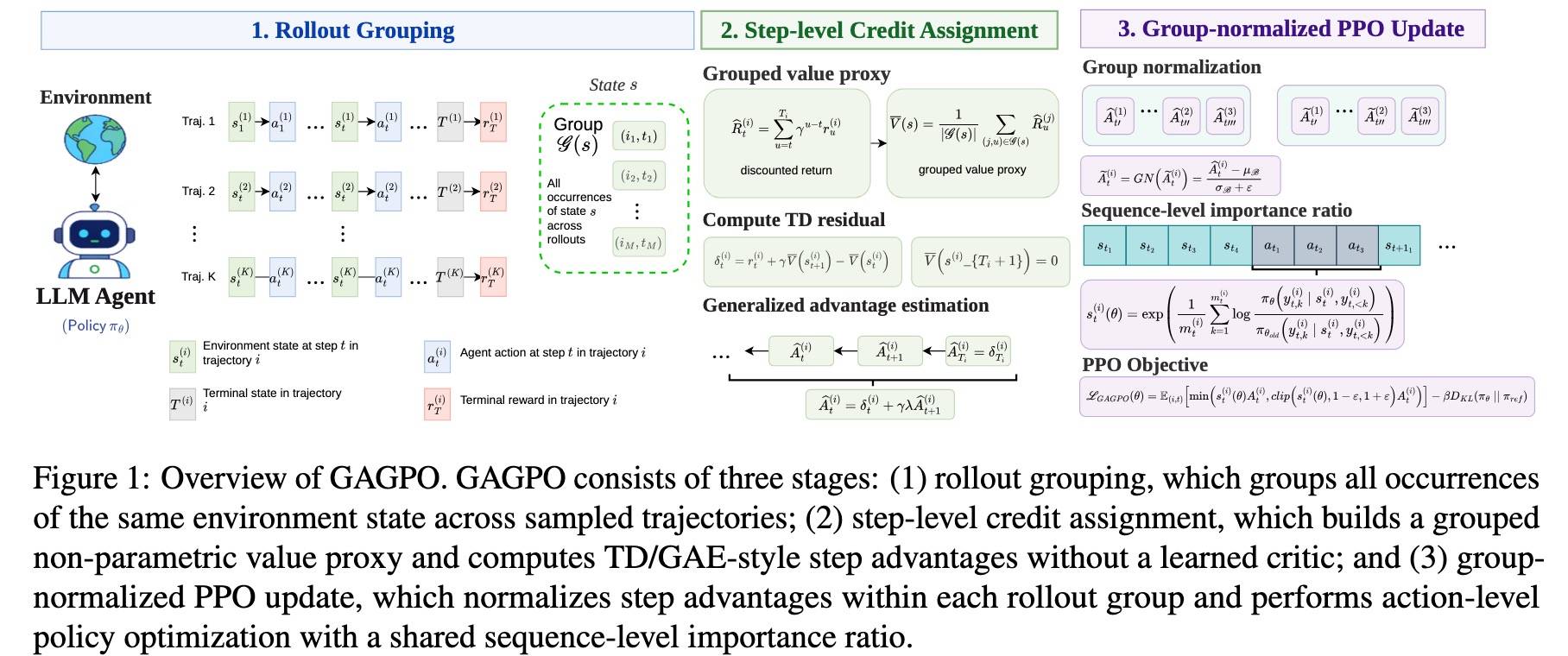
这里的关键就是第二步——用 GRPO GROUP 的方法计算 V,然后用 GAE 的方法计算每一步的 A(注意,每个 Step 的所有 Token 的 A 一样)。而这一步的关键是 Agentic 任务相对稳定的 State。
TRPO深度拆解:为什么做后训练应该读懂TRPO
TL;DR
TRPO 解决了强化学习中“策略更新步长难以确定”的痛点。它通过数学证明,将复杂的策略改进过程转化为一个带约束的局部优化问题。
- 核心思想:利用 KL 散度在“概率分布空间”而非“参数数值空间”衡量更新距离。
- 三大支柱:MM 保证单调提升、信任区域(Trust Region)确保更新稳定、共轭梯度(CG)实现高维参数的高效求解。
- 历史地位:它是 PPO 和 GRPO 的理论基石,定义了现代 RL 对齐算法的底层逻辑。
一直想仔细读一下 TRPO 的 paper[1],每次都拖延住,这次是真的不得不上了,趁热打铁,记录一下。顺便说一句,类似 TRPO 这种 paper 是我个人非常喜欢的一类文章,写的很好,非常推荐。
TRPO 这篇论文在现代强化学习中的地位不亚于 “Attention is all you need” 在 LLM 中的地位,后续大放异彩的 PPO、GRPO 其实都是在给 TRPO 的基础上“做减法”。
比如 PPO,TRPO 计算 Fisher 矩阵和共轭梯度实现极其复杂,PPO-Clip 直接用截断把新旧策略的比值强行限制在 之间。而 GRPO 更是把 TRPO 里的思想发挥到了极致,它依然保留了 KL 散度约束,但在去掉 Baseline 这步走的更远,直接通过分组得分来代替 Advantage 估算。
总的来说,只要符合以下三点的,基本都是 TRPO 这一脉的:
- 重要性采样:用旧数据训练新模型,必须修正分布偏差,分子分母的比例永远是核心。
- 信任区域 :步子不能太大,必须限制在一定范围内,否则策略直接崩溃。
- 优势函数:不考虑绝对得分,只看当前动作是否比平均水平更好。
红豆为什么会滚——从两岁女儿的玩耍说起
写在前面:我不是物理科班出身——本职是算法工程师。本文只是从一个工程师的好奇心出发,把一个家庭场景里随手冒出来的物理问题拿出来探讨一番。如果有不严谨的地方,欢迎指正。
前几天周末,女儿在床上玩红豆——家里那种煮粥用的小红豆,圆鼓鼓的椭球。
她两岁多,正是什么都想拿来玩的年纪,每次都让我抱着她去厨房的罐子里抓一点豆子玩儿。我也没办法,每次只能依着她,看着她把红豆放在有点褶皱的被子上滚来滚去,我问她:“小西瓜,你知不知道为什么豆子会滚来滚去,旁边的小方块不会这样滚来滚去呀?”
她自然是不理我的,不过我心里在想怎么回答这个问题,“因为它是圆的?”听起来好像有道理,其实是句废话——我仔细一想,这里面好像涉及到好几个物理问题,于是就趁此机会记录一下。