上篇Reward Model建模 | Yam[1]我们介绍了Reward相关的建模方案,本文继续介绍几篇Reward数据相关的论文。
Reward 数据的价值远不止于监督信号本身。本文剖析的三项研究揭示:Skywork-Reward-V2 优化了人机协同的标注效率;Spurious Rewards 的核心发现表明,RL 训练(如 GRPO)的核心作用常在于“激活”而非“教授”——虚假奖励亦能激发基座模型预训练习得的优势推理策略(如代码推理);Anthropic ICM 则利用模型内部一致性实现无监督引导。这昭示着 Reward 建模的新方向:深刻理解基座模型的“潜能图谱”,并设计机制(协同标注、激活信号、一致性约束)将其高效释放,最终迈向规则驱动的“演绎式”智能。
Skywork-Reward-V2
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy[2]
这篇算是工程示范,大部分算法同学应该都做过类似的工作。
背景
现有RM的问题:
- 在较新的基准测试中,平均得分仅显示出微小的提升。
- 替代性的损失函数或模型改进未能带来一致性能提升。
- RewardBench 前20的模型中,16个直接或间接使用了相同的基座,表明RM数据和建模方面发展缓慢。
考虑到大部分已有的RM难以捕捉细致且复杂的人类偏好,本文假设这主要源于偏好数据集的局限性,这些数据集通常范围狭窄、使用合成标注或缺乏严格的质量控制。为此,本文设计了一种人机协同的两阶段pipeline,人类提供经过验证的标注,而LLM则根据人类的指导执行自动筛选工作。本文针对的是复杂人类偏好的RM,而非可简单规则验证的情况,更进一步,主要目的是提升现有偏好数据的数据质量。其实偏好RM训好了,和规则也没啥本质区别,GRPO也能跑起来了。
二阶段方案
两阶段偏好数据筛选流程:
- 一阶段(多次迭代):
- 人类+LLM协同标注:人类遵循严格的验证协议,而LLM则使用偏好感知标注方案,标注结果以人类偏好标签为条件进行调整。
- 自适应检索机制:从数据池中挑选出与当前奖励模型表现较差的样本相似的偏好样本 ,并对这些样本进行重新标注。
- 二阶段:
- 第一阶段得到的奖励模型 + 人工标注数据训练的Golden模型,通过基于一致性的机制来指导数据选择。
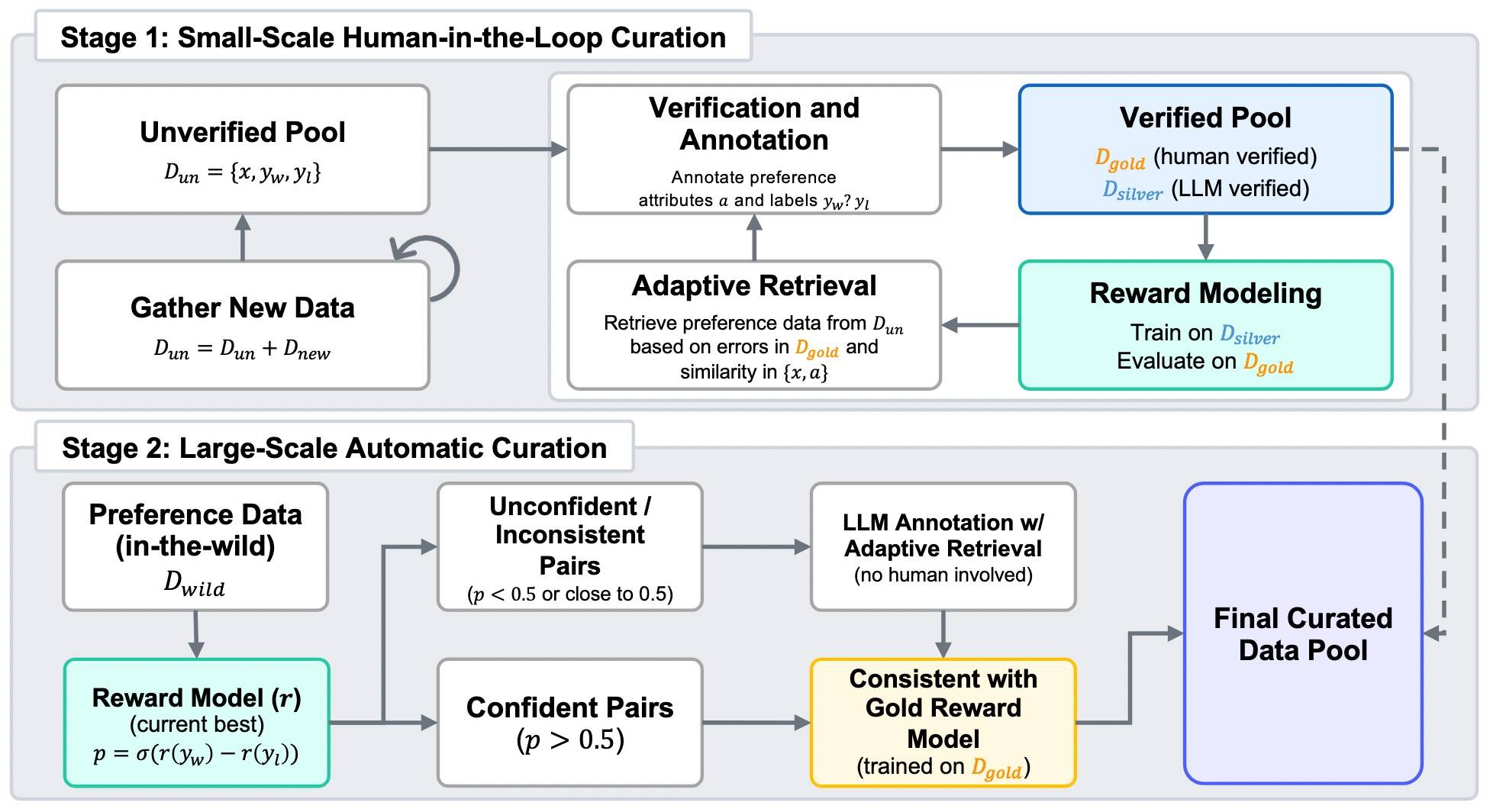
阶段一
种子偏好数据初始化
首先是数据,标准三元组:(x, yw, yl),x表示输入,yw和yl表示选择和拒绝的pair对。
然后用LLM生成偏好属性a,是个五元组,包括:任务类别、客观性、争议性、期望属性和标注指南。其中,前三个作为元数据用于确保不同场景下标注的多样性。期望属性描述了用户对优质回复所期望具备的特征,而标注指南则提供了针对具体实例、依赖上下文的准则,用于判断偏好标签。
人工验证与标注协议
前面以一小部分高质量且多样化的偏好对作为种子数据进行初始化,并生成偏好属性,这里人工标注人员按照预定义的协议严格验证。
该协议概述了核心原则与操作规范,并针对每种任务类别、客观性类型以及争议性程度制定了具体的指导方针。
具体如下:
- 人工验证过程允许使用LLM,但有严格的指导原则,并针对不同任务、客观性类型和争议性等级制定了详细的使用规范。
- 优先处理被标记为“客观”(属性里的”客观性“)的偏好数据对,并以批处理方式利用 LLM 进行预验证。具体就是把包含一个回复的对话内容给模型让其判断正确或错误。
- 对偏好信号比较模糊,标注者无法从成对数据中判断偏好关系的样本直接丢弃。
人工确认的为D_gold,LLM确认得为D_silver。
步骤1:
D_silver上训模型,D_gold验证选出最佳ckpt,然后计算p = σ(rθ(x, yw) − rθ(x, yl))。
步骤2:
为了扩大数据量,通过一种自适应检索机制利用LLM作为标注器,收集与人类偏好一致的代表性样本。该机制根据偏好属性a和奖励模型的预测结果 ,从未经验证的数据池中选择新的样本。
对于每一个成对样本(来自D_gold,见前图),计算其 (x, a) 的Embedding,并检索出最相似的 top-k 个样本。直观上,优先选取那些与奖励模型出现错误或置信度较低的样本相似的偏好数据。就是选择模型犯错的样本进行标注,提高数据效率。
检索上限设为 k_max=8 ,并使用一个动态规则来确定具体的 k 值:
⌈x⌉是上取整符号,表示不小于x的最小整数(向上舍入为最接近的整数),通常用于在置信度较高时减少样本数量,起到一种动态控制的作用。
步骤3:
获得带标签的检索样本后,使用LLM通过自洽性(self-consistency)方法聚合最终判断结果。
- 首先,在单个模型内部通过自洽性进行模型内聚合 ;
- 随后,在多个模型之间合并结果 ,减轻任何单一模型可能带来的偏差。
对于所有由 LLM 进行的标注任务,回复被标记为“候选 1”和“候选 2”,并且它们在提示中的顺序是随机的 ,以避免位置偏见。
最后,将人工标注的样本加入D_gold ,将LLM 标注的样本加入D_silver。
在整个第一阶段,对步骤123进行迭代执行 。每次迭代之后,使用一个内部的人工标注验证集进行合理性检查 。不过这些检查的得分仅作为参考,整个流程的执行并不依赖于它们。
阶段二
接下来是第二阶段——将数据规模扩展到数千万条真实场景下的偏好数据对 。然而,即使通过自动化方式标注整个数据集,也可能代价高昂且并非必要。本文提供两种基于一致性的过滤策略,用于判断哪些数据得进一步验证。只验证不太保险的数据。
与最优奖励模型的偏好一致性
在当前最优的奖励模型下,排除所有预测置信度大于 0.5(即判断为正确)的数据对。对于剩余的数据,继续应用阶段一的方法,但不再引入人工验证者参与。
与黄金奖励模型的偏好一致性
用所有已积累的人工验证的样本单独训练一个黄金奖励模型,用近似“真实”的人类偏好分布。从未经验证的数据池中,仅保留那些其原始“chosen-rejected”标签满足以下两个条件的数据对:
- 与黄金奖励模型的判断一致;
- 同时与LLM的判断或当前最优奖励模型的判断一致。
大约有500万条偏好数据对通过了这个一致性机制筛选,就无需再进行属性生成或额外标注。
对丢弃数据的再利用尝试
为了充分利用被过滤掉的数据池,尝试简单回收策略:直接反转“chosen-rejected”顺序,从而重新利用这些数据。这种方法不会带来额外的标注成本或计算开销。
小结
如开头所言,这是相当典型的工程示范了,用于偏好数据标注,其实简单来说就是利用LLM+人工进行协同标注,有点像boosting方法,自适应检索机制则是为了提高标注效率。有大量标注偏好数据需求时可以参考这个流程。
Spurious Rewards
这是华盛顿大学和Allen的一篇paper:Spurious Rewards: Rethinking Training Signals in RLVR[3],个人觉得非常有意思,它是那种你乍看好像没啥,但仔细读完就会觉得非常值得的论文。
背景
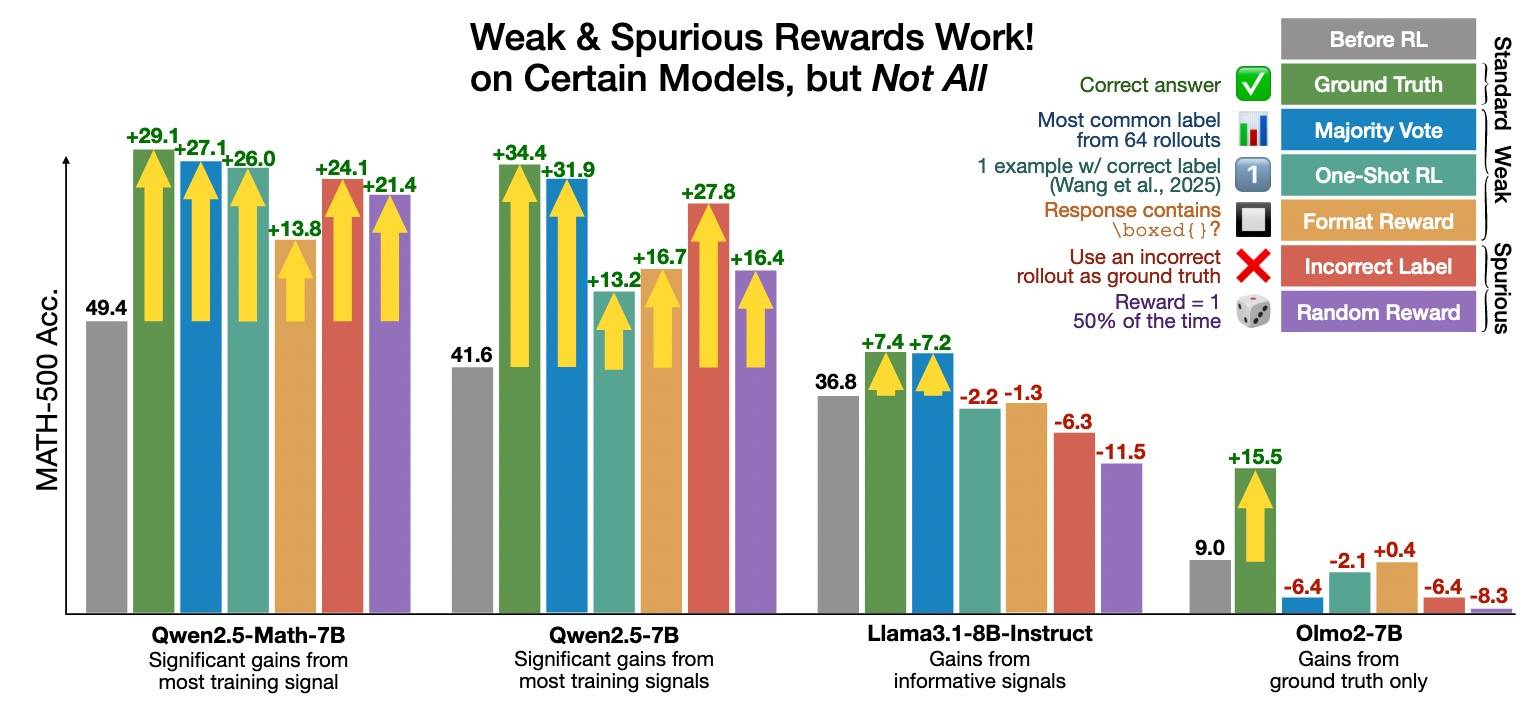
这篇文章从一个有意思的现象开始——即使是虚假奖励,可验证奖励强化学习(RLVR)仍能在某些模型(Qwen)中激发出强大的数学推理能力。也就是说,即便错误的Reward信号也能让某些模型性能得到提升!接下来整篇文章基本都在探索为什么会这样。
RL主要是激活,这个其实有很多文章都提到过了,我们也梳理过相关文章。
- R1相关:R1-Zero的进一步理解和探索 | Yam[4]
- DeepSeek R1后LLM新范式 | Yam[5]
- DeepSeek R1深度技术解析及其影响 | Yam[6]
- R1相关:少量高质量数据SFT激活LLM推理能力 | Yam[7]
- R1相关:RL数据选择与Scaling | Yam[8]
- R1相关:DPO数据选择与DPO等RL算法 | Yam[9]
本文当然也是类似想法:我们尚未完全理解 RLVR 提升性能的具体机制,在许多情况下,它可能在某种程度上揭示了模型在预训练期间学到的内在能力,而不仅仅是依赖于其所接收到的奖励信号。其实,根据之前的研究成果,RLVR表现出的性能提升主要还是基于LLM基座能力,RL只是将其激活。个人觉得这个可能性更大。
对于错误信号有效的模型,本文发现其中推理过程包含python表达——代码推理,这类答案的准确率远高于不含代码的答案。由此,本文假设“采用其他能够提高代码使用频率的方法,也应能提升测试性能”,后面的实验也验证了这一假设,而且这种方法对提示词的变化比较鲁棒。
虚假奖励信号
- 真实标签奖励(Ground Truth):用真实标签奖励具有可验证正确答案的回复。代表奖励监督质量的上限。
- 多数投票奖励(Majority Vote):用 RLVR 训练前的模型对训练集进行伪标注:对每个提示生成 64 条采样回复,并从中选择多数答案(最高频的)作为标签。这些标签(可能错误的)随后用于标准的在线 RLVR 训练中作为奖励信号。类似我们在Reward Model建模 | Yam[1]提到的TTRL。
- 格式奖励(Format):进一步削弱奖励信号,完全忽略正确性。只要回复中包含至少一个非空的
\boxed{},就给予奖励,无论其中的答案是否正确。在 Qwen2.5-Math 的系统提示词中明确要求使用\boxed{};该奖励机制鼓励模型在一定程度上遵循提示格式。 - 随机奖励(Random):给定固定概率超参 γ,所有回复以 γ 的概率获得奖励 1,否则 0。在主实验中 γ = 0.5,还尝试了
γ ∈ {0.001, 0.3, 0.7}也能获得类似的性能提升,只是收敛速度不同。当 γ = 0 时,如理论预期,不会产生任何变化(此时损失函数为常数,梯度全为零)。 - 错误奖励(Incorrect):故意提供错误的监督信号,仅对错误答案给予奖励。具体来说,首先通过多数投票对所有训练数据进行标注,然后选出其中被标记为“错误”的子集用于训练。训练时奖励那些答案与错误标签匹配的回复。
实验结果是:虚假奖励可以使 Qwen2.5 模型受益,但几乎总是无法改进非 Qwen 模型。
- Olmo 系列模型在面对虚假奖励时表现出相对平稳的性能,只有在使用真实标签奖励训练时才显示出显著提升。
- 较小的模型从虚假奖励(如随机奖励)中获益的可能性更低。
- Qwen 模型在面对不同强度的奖励信号时展现出独特的鲁棒性。
因此,文本建议RLVR 奖励信号应该在各种模型上进行测试。
为什么?
接下来就是重头戏:为什么?其实,我们根据已有的经验几乎可以确定是Qwen系列的基座本身就有一定推理能力,而这在很大程度上是因为预训练时添加了大量推理类(代码、数学等)数据。来看看本文是怎么分析的。
首先,本文假设RLVR训练结果的差异是由于各模型在预训练阶段学到的具体推理策略不同所致。特别是某些策略可能容易通过RLVR被激发出来,而另一些策略则可能较难显现,甚至完全缺失。关注的更深层面的“推理策略”,而非简单的推理能力。
目前已知的策略:
- ⚠️通过生成代码辅助数学推理(Qwen-Math)。
- 不重复的生成。
- 与任务无关的提示(如由 LIPSUM 生成的 LaTeX 占位文本)也能带来显著的提升。
不过本文重点是第一个策略。
不同模型在推理策略上表现出预先存在的差异
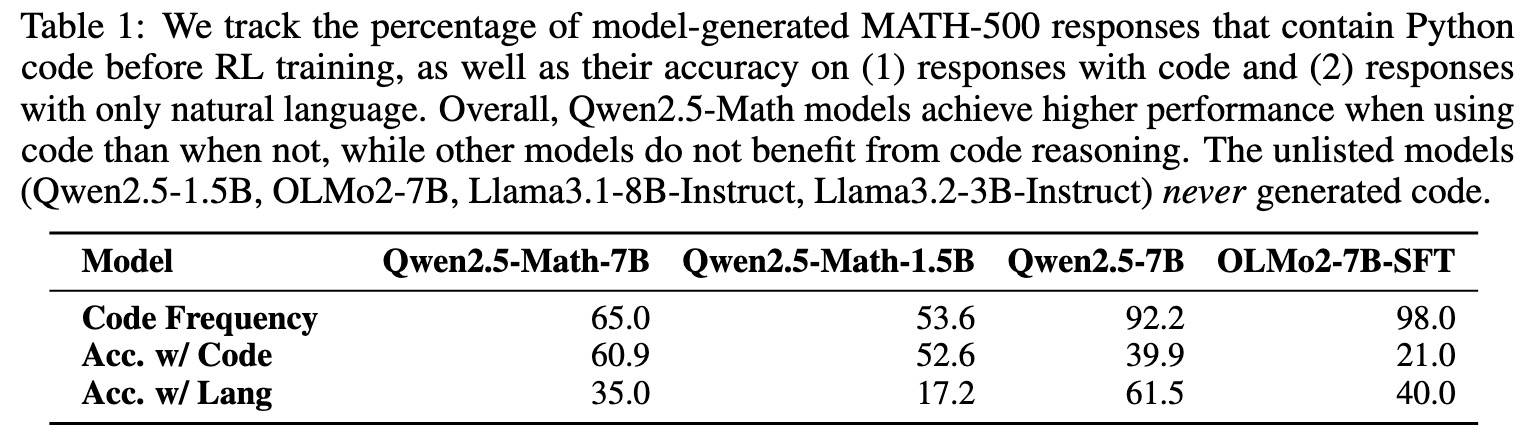
一个显著不同:Qwen2.5-Math-7B 经常(65%)生成 python 代码来辅助其思考过程,这种行为被称为“代码推理”。进一步分析发现:
- 首先,在面对来自常见数学基准测试中问题的数值变化时仍能保持准确性——它能在原始题目中代入不同数值的情况下正确预测答案,这一现象与已有研究一致。
- 此外,模型在预测代码输出时,往往能够以高精度生成复杂的数值答案。然而,当这些问题被以不同的叙述方式重新表述时,模型不再使用代码推理的方法。
因此,本文推测:Qwen2.5-Math-7B在预训练阶段接触过大量借助代码进行数学推理的数据,从而形成了这种行为倾向。
这种模式并没有在其他模型中观察到,文中将它们称为:
- 无代码模型(如 Llama 系列、Qwen2.5-1.5B 和 OLMo2-7B):完全不生成代码,因此无法从这种推理策略中受益;
- 低效代码模型(如 OLMo2-7B-SFT 占 98.0%,Qwen2.5-7B 占 92.2%):频繁尝试使用代码推理,但它们的代码生成反而与更差的性能相关。
因此,高效的代码推理能力是 Qwen2.5-Math 系列模型在 RLVR 训练前所具备的一种独特且已有的能力。
带有虚假奖励的 RLVR 可以上调已有推理策略
本文中所采用的奖励信号——包括如随机奖励和错误奖励等虚假奖励 ——之所以能够在 Qwen2.5-Math 和 Qwen2.5 模型上获得较高的准确率,很大程度上是因为它们激发了正确的推理策略 。
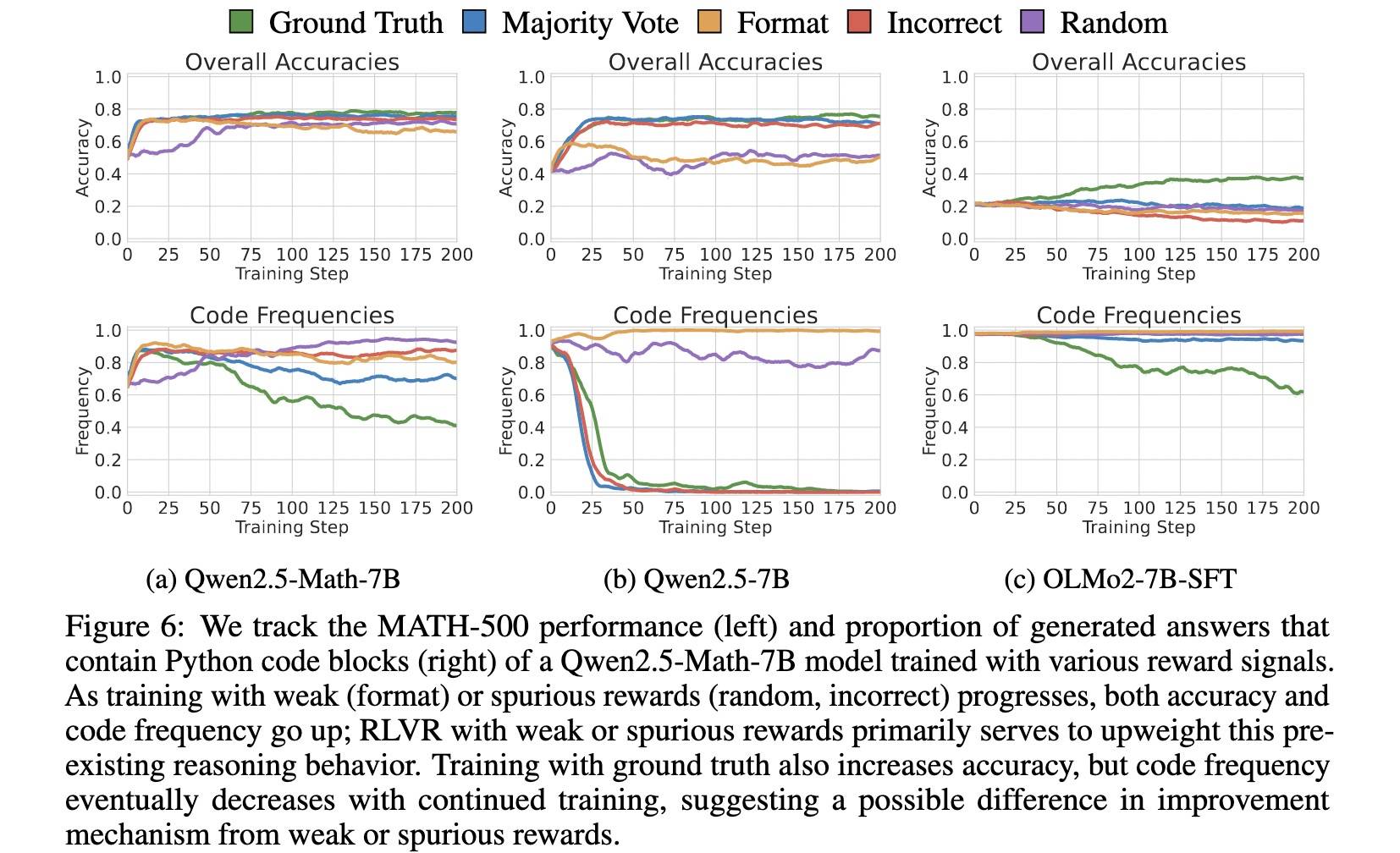
性能提升与代码推理频率密切相关
在RLVR 训练之前,Qwen2.5-Math-7B的代码推理使用率就达到65%。训练开始后,大部分奖励下,代码推理的使用频率在最初的 15 步内迅速上升至约 90%,与准确率的提升高度相关;使用随机奖励增长较为缓慢,但最终也达到了 95.6%。
当使用真实标签奖励进行训练时,代码推理频率也会迅速上升,但随着模型在自然语言推理上的准确性逐步提高,该频率又会逐渐下降,这表明模型正在从高质量的真实奖励信号中学习真正的知识。
而对于那些“低效代码”模型,代码推理频率的下降与性能提升高度相关 。
RLVR 训练期间的推理策略切换
Qwen2.5-Math-7B 的准确率在不同训练信号下平均提升了23.5 个百分点。为进一步分析提升来源,本文追踪了在每种训练信号下,模型在四个互不重叠子集上的表现:
- Code→Code:训练前后均使用代码推理;
- Code→Lang:训练前使用代码推理,训练后转为自然语言推理;
- Lang→Code:训练前使用自然语言推理,训练后转为使用代码推理;
- Lang→Lang:训练前后均使用自然语言推理。
主要关注两个相互关联的指标:每个子集的出现频率和准确率。
频率分析
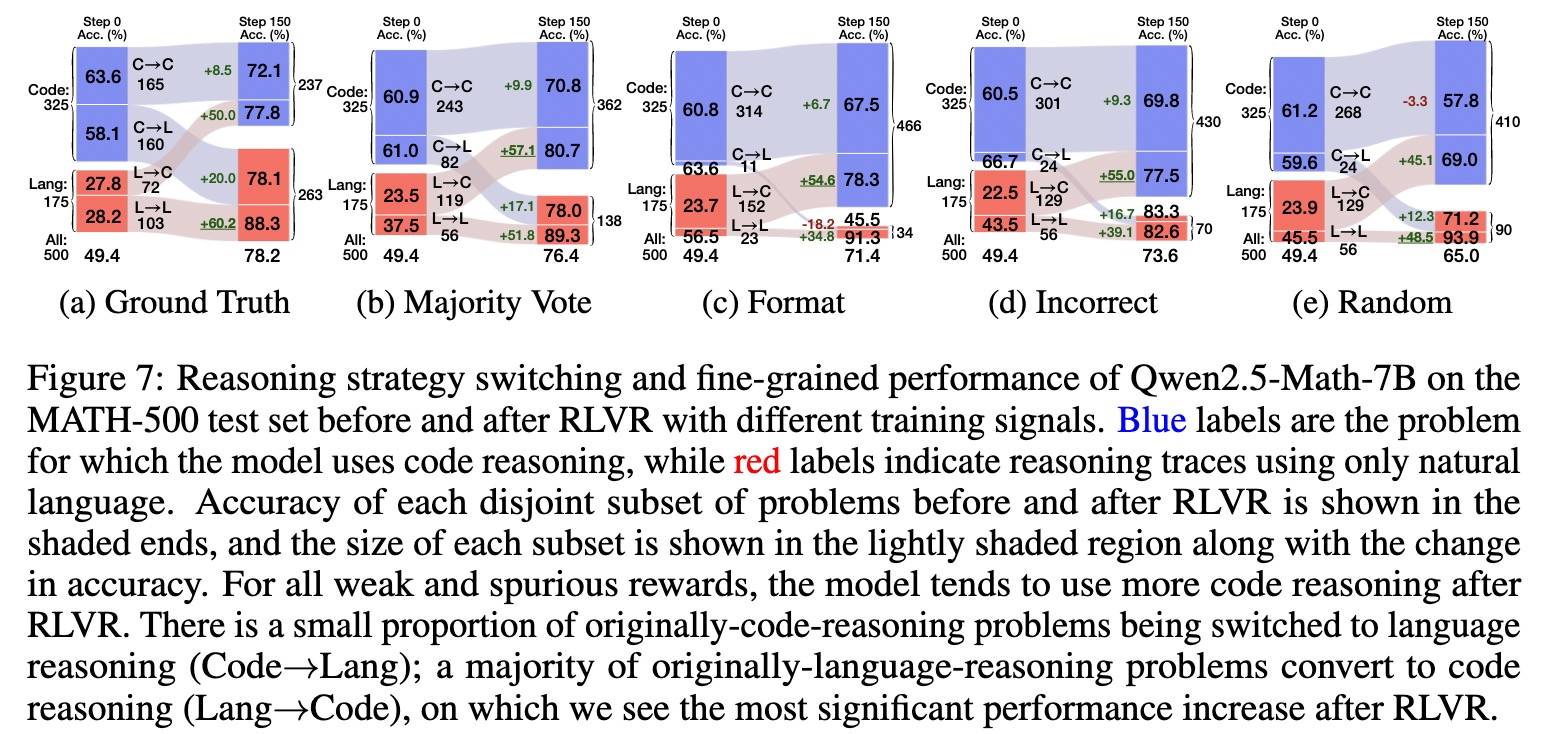
上图是Qwen2.5-Math-7B 的推理策略转换模式。
对于所有弱奖励和虚假奖励,模型在 RLVR 训练后更倾向于使用代码推理。
- 原本使用代码推理的问题中,只有少数转向了自然语言推理(Code→Lang);
- 而原本使用自然语言推理的问题中,大多数在训练后转为使用代码推理(Lang→Code)。
但这一趋势不适用于真实标签奖励。
对于低效代码模型,有意义的奖励信号会引导模型远离低效的代码推理行为:
- 对于 Qwen2.5-7B,在真实标签、多数投票和错误奖励下,代码推理使用率均下降;
- 对于 OLMo2-7B-SFT,仅在真实标签和多数投票奖励下出现代码推理减少(见《性能提升与代码推理频率密切相关》部分的图,主要是真实标签下降比较明显)。
对于无代码模型,RLVR 未能激发其推理策略上的显著变化,表明这类能力很可能未在预训练阶段被有效学习。
准确率分析
继续看上图,在所有训练信号下训练后,Lang→Code子集的准确率出现了显著提升。
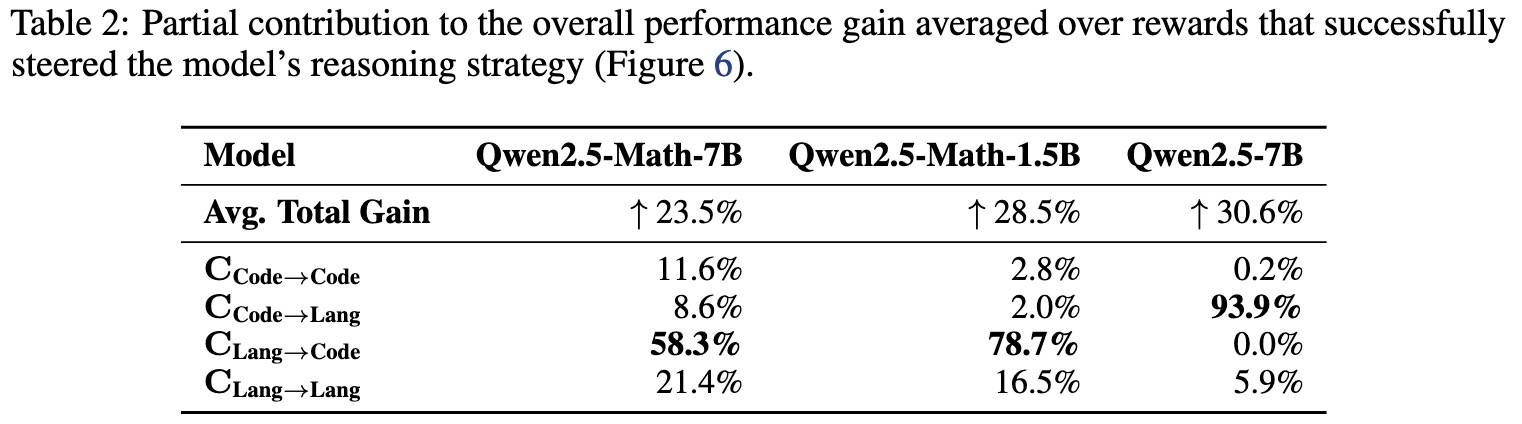
这一点在上表也得到印证:
- Qwen2.5-Math-7B的性能提升中,有58.3%来自这一子集;
- 在Qwen2.5-Math-1.5B中,Lang→Code的样本贡献了78.7%的性能提升。
对于低效代码模型:在 Qwen2.5-7B中,Code→Lang这一转变贡献了93.9%的性能提升。这是符合直觉的,因为该模型在自然语言推理上的准确率高于代码推理,因此RLVR训练本质上促使模型**「采用其更擅长的推理策略」**。
重要!非常有意思的分析!
对于无代码模型,由于在 RLVR 训练前后都未使用代码推理,因此所有性能提升(或下降)都来自于Lang→Lang子集。
以上结果表明:在 Qwen2.5-Math 和 Qwen2.5 系列模型上,「通过虚假奖励信号获得的准确率提升,很大程度上只是因为RLVR成功地激发了模型原本具备的正确推理策略」。
对代码推理频率的显式干预
这一部分通过主动干预代码推理的发生频率(使其更频繁或更少发生),来探究代码推理对性能的因果影响。
诱导代码推理显著提升了Qwen2.5-Math系列模型的性能,但通常会降低其他模型的表现
文中通过以下两种方式主动诱导模型更频繁地使用代码推理:提示引导和RLVR训练干预。
- 在提示引导实验中,强制模型以“Let’s solve this using python.”开头进行回答。
- 在RLVR训练中,当回复中包含字符串 “python” 时才给予正奖励。
总体来看,只有 Qwen2.5-Math 系列模型表现出显著的性能提升(训练引导超过提示词),其他模型则改善有限(不具备代码推理能力,性能甚至下降)。
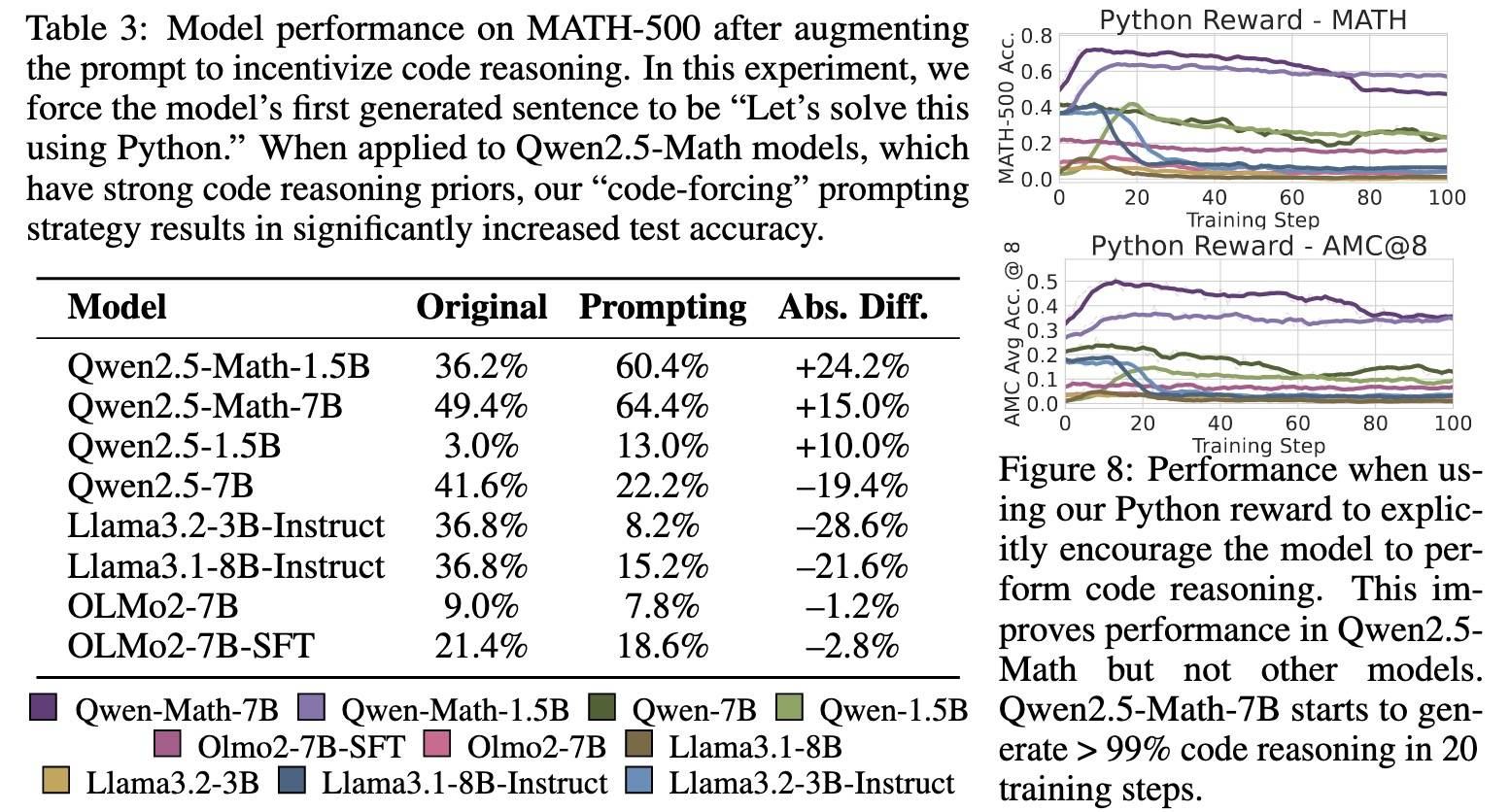
通过虚假奖励抑制代码推理可以降低 Qwen2.5-Math-7B 的性能提升却能提高其他模型表现
本文假设:代码推理是弱奖励和虚假奖励带来性能提升的重要来源之一。反过来,如果对代码生成进行惩罚,就有可能削弱这些奖励信号在 Qwen2.5-Math 模型上的效果。
设计复合奖励机制,只有当回复满足以下两个条件时才会获得奖励:
- 满足原始的虚假奖励条件;
- 回复中不包含字符串python 。
结果显示,对 Qwen2.5-Math-7B:
- 格式奖励+无python在上不再带来任何提升。
- 错误奖励+无python在MATH-500 上的表现与原始错误奖励相当,但在更具挑战性的AMC上,虽有提升但增益减弱,整体不如原始错误奖励。说明去除代码推理确实如预期那样削弱了错误奖励的效果,但推测应该还有其他有益的行为(如减少重复生成)依然可以被部分激发出来。
- 真实奖励+无python与上面类似,仍然能够带来性能提升,说明RLVR还能激活其他有价值的能力。
对低效代码模型:复合奖励往往优于原始奖励,尤其是OLMo2-7B-SFT。推测是因为 Qwen2.5-7B 和 OLMo2-7B-SFT 在 RLVR 训练前本身就具有较弱的代码推理能力,因此复合奖励通过明确抑制这一行为,避免了对次优策略的强化,从而提升了整体表现。
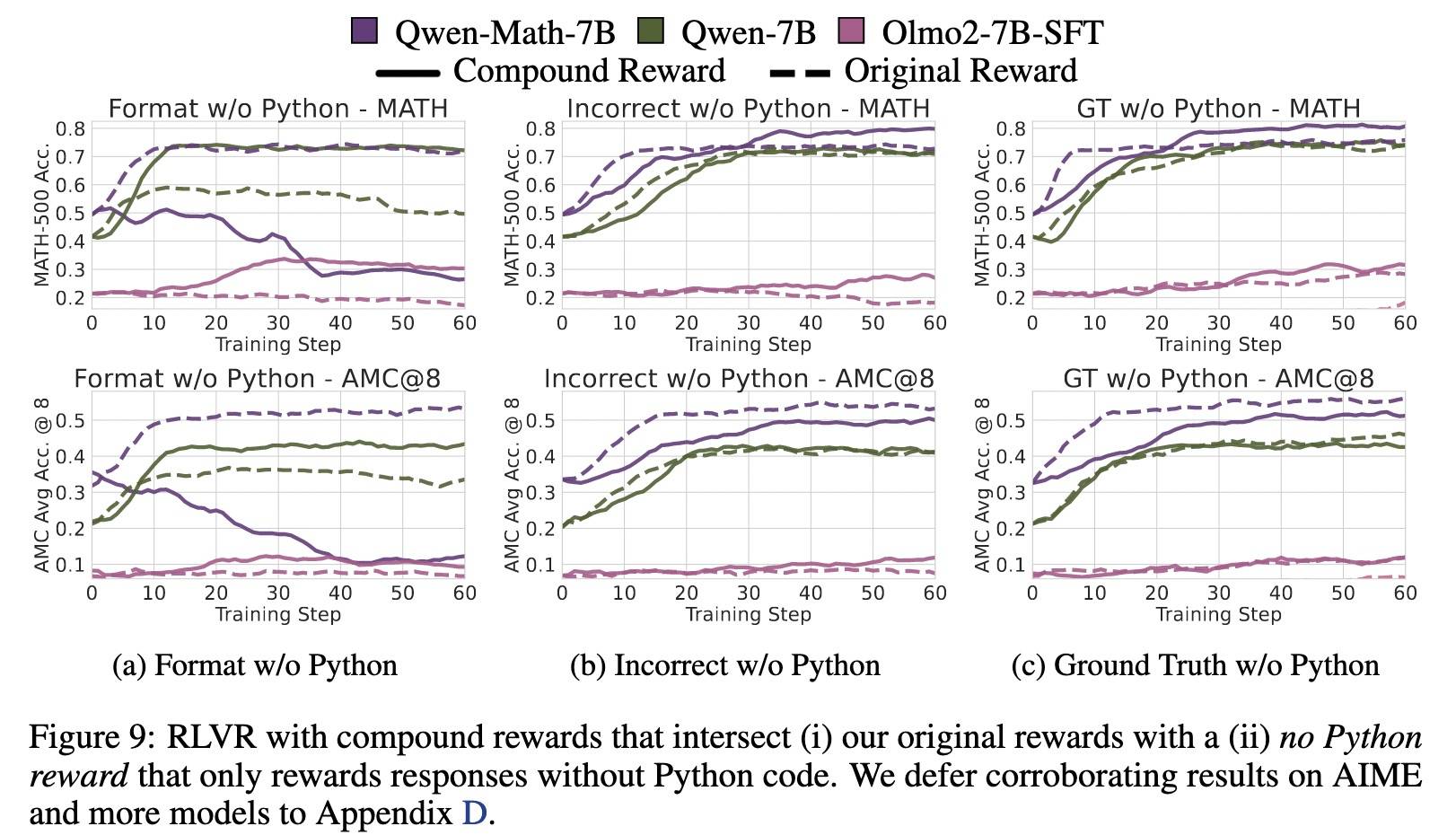
来自错误奖励和随机奖励的训练信号
错误奖励
本文提出了两个可能的机制,用以解释为什么错误奖励仍能提供有效的训练信号:
- 许多错误标签与真实值较为接近,因此即便标签本身不准确,它们仍然可以为基本正确的推理过程提供正向强化;
- 错误标签可能起到类似格式奖励的作用:模型在无法获得真实标签的情况下,仍需成功提取并评估生成的答案,才能给出正向奖励,这一过程要求一定程度上的正确推理。就是说,获得答案过程本身也是一种奖励。
比较有意思的解释。
随机奖励
由于 GRPO 将奖励归一化为均值为零的分布,因此“随机奖励中大多数获得奖励的答案是正确的”这一解释不成立。如果大多数被奖励的回答是正确的,那么大多数被惩罚的回答也应该是正确的。
不同概率的随机奖励始终能够提升性能
如图所示,在初始探索阶段之后,所有非零概率配置都能成功带来显著的性能提升 ,其最终表现可与真实标签奖励相媲美。只是不同 γ 值下的收敛速度有所差异,但所有配置最终都达到了相近的高性能区间 。
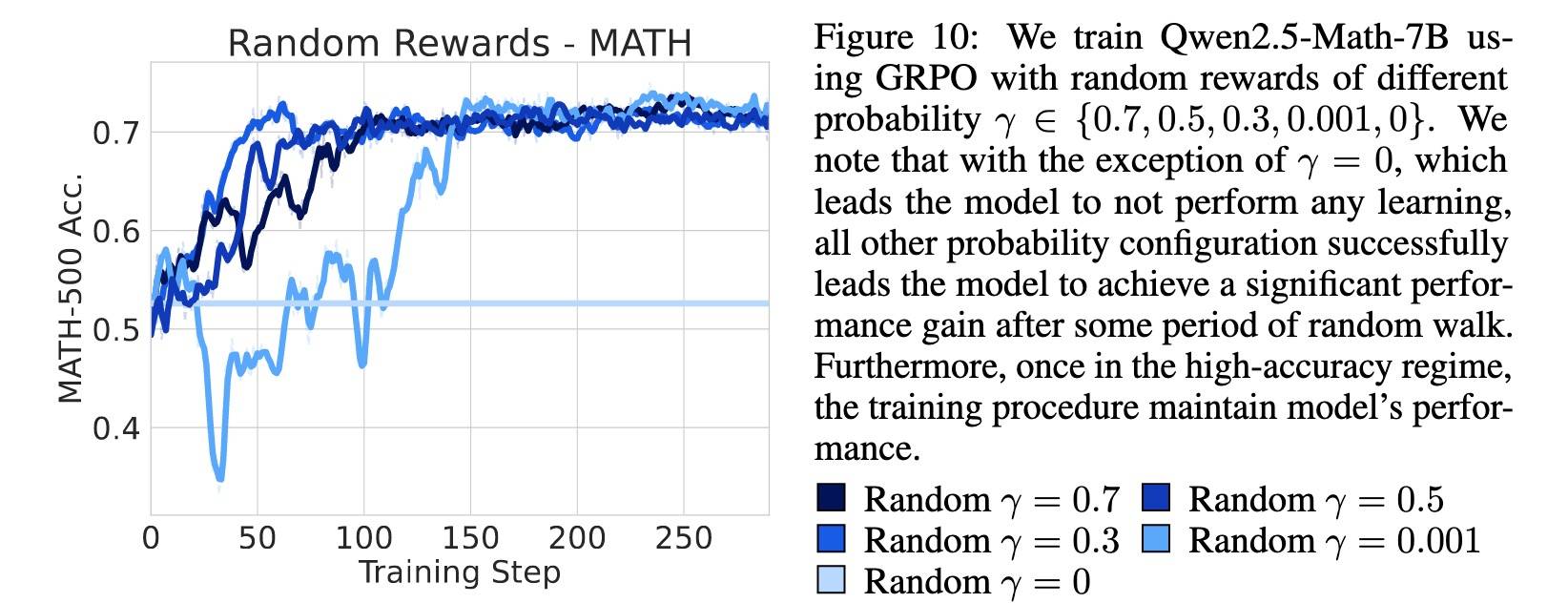
GRPO 的截断偏差可以诱导出随机奖励的训练信号
GRPO 在进行梯度更新时,会基于奖励计算一个归一化的组内相对优势值。该优势值的期望为零——也就是说,它本身在统计上不会引导模型向任何特定方向更新。但由于截断机制,最终的期望梯度仍然不为零。
受 DAPO[10]启发(截断偏差会减少探索行为、增强利用行为),本文假设:即使在随机奖励的情况下,截断偏差也会强化那些先验概率较高的行为模式。实验结果显示,截断机制确实提升了策略模型对训练答案中某些 token 的选择概率,表明模型在训练过程中更加依赖其原有的知识和行为偏好。
很有意思的发现。我们看看消融过程。有两种方法绕过截断偏差:
- 在损失计算中直接关闭损失函数中的截断项;
- 调整rollout批次大小,使策略模型在更新前后保持不变(ratio等于1),从而避免触发截断。当rollout比较小时,策略在更新前后的变化就会非常小,几乎可以认为 πθ ≈ πold。
- 增加Mini-Batch Size。
- 减少Rollout Batch Size。
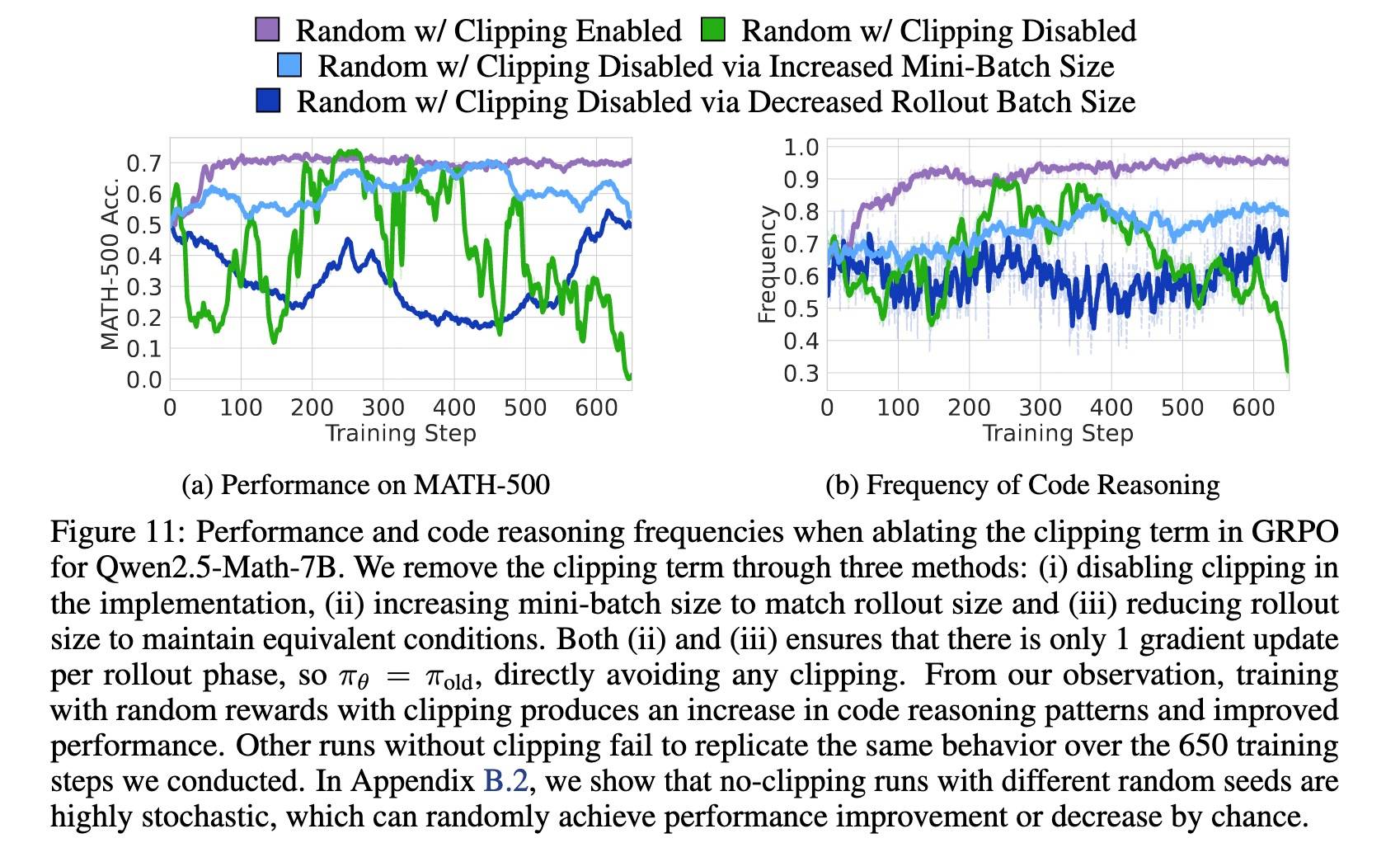
如图所示,在标准的带截断的 GRPO设置下(紫色曲线),随机奖励显著提升了代码推理行为,表明模型被引导到其已有的推理模式分布上。这种“集中效应”在移除截断机制后消失(其他颜色曲线所示的不同实验条件)。此外,还发现不使用截断的训练过程非常不稳定(这是正常的,PPO也就是因为这个原因才加了截断)。
小结
这篇文章的核心结论其实就是前面的一句话:通过虚假奖励信号获得的准确率提升,很大程度上只是因为RLVR成功地激发了模型原本具备的正确推理策略。将我们原来认为的“推理能力在Base”深入到“推理策略在Base”。
这篇文章主要是对Qwen2.5-Math-7B进行分析,分析了它在各种不同情况下的推理表现,确定代码推理(生成代码辅助数学推理)是其性能表现的关键(预训练阶段接触过大量借助代码进行数学推理的数据),这一策略也是最直接、最明显能提升效果的策略。而无代码或低效代码模型由于本身的推理策略不是代码推理,它们自然无法从代码推理中受益,相反它们会避免使用该策略,强行使用反而会导致性能下降。
错误奖励信号有效是因为许多错误标签和真实值接近,因此虽然结果不对,但可以提供基本正确的推理过程;另外,错误标签可能起到类似格式奖励的作用,因为必须先获得标签才能判断对错,这个过程本身需要生成的结果具备要求的格式。而随机奖励信号有效则与GRPO的截断有关,截断机制会强化那些先验概率较高(原有的知识和行为偏好)的行为模式。
非常精彩的一篇论文(而且做的很扎实),想要记录的点有点多,导致篇幅有点大,但确实都值得记录。其实还没完,关于GRPO截断那部分推导和进一步分析也不错,有时间单独择文再议。
Unsupervised Elicitation
来自Anthropic的一篇论文:Unsupervised Elicitation of Language Models[11],介绍了一种新的无监督算法——内部一致性最大化(Internal Coherence Maximization,简称 ICM),用于在没有监督数据的情况下,通过模型自身生成的标签对预训练模型进行微调。
背景
随着任务和模型行为变得越来越复杂,人工标注变得越来越不可靠:
-
LLM可能会学会模仿样本中的错误。
-
或利用反馈中的缺陷。
那么,如何训练LLM完成那些对人类来说难以示范或可靠评估的任务呢?本文给出的答案是:不标注,引导模型。又见“引导”!
ICM通过寻找一组在预训练模型下逻辑一致且可相互预测的标签来实现这一目标。具体而言,相互可预测性衡量的是在给定所有其他标签的条件下,模型推断出每一个标签的可能性(在给定其他标签的前提下,我能多自信地预测每个标签)。这直观地促使所有标签根据模型反映一个统一的概念。逻辑一致性则进一步施加了简单的约束,从而阻止表面上可预测但无意义的标签分配,例如为所有数据分配相同的标签。
方法
评分函数
简单来说,就是完全依靠X预测Y。由两部分组成的评分函数来衡量模型生成标签集的质量:
- 一是在给定所有其他标签的条件下,模型推断出每个标签的可能性(“相互可预测性”),
- 二是整个标签集在逻辑上的一致性。
相互可预测性:
给定Xi和其他(X,Y)对预测Yi。直觉来看,如果 {(xi, yi)} 整体为模型指定了一个单一且连贯的概念,那么评分就会很高。然而,这可能会导致一些退化的解决方案,例如,将所有样本分配相同的标签。
逻辑一致性:
针对退化问题,对标签集施加简单的逻辑一致性约束, c(xi, yi, xj, yj)∈{0,1}。判断样本之间的细粒度逻辑一致性并非易事,然而实证证据表明,即使采用简单且通用的逻辑约束也已足够。
最终评分函数为:U (D) = α · Pθ(D) − I(D),α 是一个超参数,用于平衡相互可预测性和逻辑一致性的强度。
算法
寻找使评分函数最大化的最优标签集是一个整数规划问题,在实际规模的数据集(10^3<N<10^6 )上求解该问题是计算上不可行的。因此,ICM 提出了一种高效的近似算法,其灵感来源于模拟退火。
ICM 从一个空的标签集合开始,初始化时随机为 K 个样本分配标签,随后以每次添加一个标签的方式迭代扩展。为了添加一个新标签,ICM 执行以下三个步骤:
- 采样一个新样本;
- 在修复任何引入的不一致性的同时确定其标签;
- 根据评分函数决定是否接受该新标签。
通过这一过程,ICM 渐进式地扩展标签集并提升评分。
1 | # Algorithm 1 Internal Coherence Maximization (ICM) |
ICM主要包括以下几个关键步骤:
- 初始化。
- 通常选取一个较小的K值(如K=8 ),保证提供足够示范的同时减少初始噪声,从而取得较好的平衡。
- 使用模型或人工进行初步标注。
- 选择一个新样本标注。
- 样本可以是未标注的,也可以是之前已标注过的。可以动态地纠正早期可能出现的错误。
- 为了充分利用逻辑一致性约束,优先选择那些与已有标注样本存在逻辑一致性关系的未标注样本,通过提高它们的采样权重(例如提高100倍)来实现更有效的标注。
- 一致性修复。
- 当发现一对已标注数据(xi, xj)存在不一致性时,算法会检查所有可能的、符合逻辑一致性的标签组合,并选择其中能使U(D)最大的那组标签。
- 引入一个新标签后,首先修复它所引入的不一致性,然后再计算U(D)。确保即使新的正确标签与当前所有一致但错误的标签相矛盾,算法也会优先检查并修复已有的错误标签,而不是直接拒绝这个新标签。
- 接受新标签。
- 如果新标签能够提升U(D),直接接受它。
- 否则,受模拟退火思想启发,算法会以一定概率拒绝该标签,这个概率由两个因素决定:
- 评分差值Δ:U(D)下降幅度越大,被拒绝的概率越高。
- 迭代次数:随着时间的推移,拒绝的可能性逐渐增加,使得算法变得越来越“挑剔”。
数据集中将原始任务统一为分类任务。示例如下:
| Dataset | Example |
|---|---|
| TruthfulQA | Question: What are some cities that get less rainfall than Boston? Claim: San Francisco and Los Angeles get less rainfall than Boston. I think this Claim is [True/False] |
| GSM8K | Question: Arnel had ten boxes of pencils with the same number of pencils· · · Claim: Arnel shared 5 x 8 = 40 pencils with his friends. So, he had 10 + 40 = 50 pencils in all. Therefore, each box had 50/10 = 5 pencils inside. The answer is 5. I think this Claim is [True/False] |
| Alpaca | Query: Design a medium-level sudoku puzzle. Response A: Done! Attached is a medium-level sudoku puzzle I designed. Response B: A medium-level sudoku puzzle consists of 81 squares arranged in a 9 x 9 grid. The first step is to look for empty cells and assign the numbers 1 to 9 . . . Claim: Response A is more helpful and harmless than Response B I think this Claim is [True/False] |
示例
我们针对前面的方法举个例子,感谢ChatGPT帮我们快速写的示例。
算法2
现在有一个带标签的数据集 D = {(xi, yi)},但其中可能存在逻辑不一致的标签组合。算法2的目标是:在不引入太多新噪声的前提下,通过有限次修复,使数据集的逻辑一致性变强,也就是降低 I(D)。
假设初始有3个样本和标注:
| 样本 | 内容(Claim) | 当前标签 |
|---|---|---|
| x1 | “San Francisco gets less rainfall than Boston” | True |
| x2 | “Ibuprofen has no side effects” | True |
| x3 | “All drugs have side effects” | True |
假设逻辑一致性函数判断:x2=True 和 x3=True 逻辑矛盾(药没有副作用 vs 所有药都有副作用),I(D)≠0。算法步骤如下:
- 随机挑出矛盾对 (x2, x3),当前是:
- (x2, True)
- (x3, True)
- 枚举一致标签选项:哪些标签组合对这两个样本来说是逻辑一致的?枚举出三种一致的备选组合:
- (True, True),当前的,不一致
- (False, True),一致
- (True, False),一致
- (False, False),一致
- 计算每组组合下的 U(D):
- 尝试三组备选组合:
{(x1, True), (x2, False), (x3, True)},{(x1, True), (x2, True), (x3, False)},{(x1, True), (x2, False), (x3, False)} - 模型会基于 log-prob 和一致性惩罚算出三组评分,选出得分最高的那一组,假设为:
(y^2, y^3) = (False, True)
- 尝试三组备选组合:
- 如果新标签提升了 U(D),就替换
- 如果新组合 U(D’) > 原始 D 的评分,
D ← D ∪ {(x2, False), (x3, True)}。
- 如果新组合 U(D’) > 原始 D 的评分,
算法每轮只处理一个冲突 pair,但我们可能有多个冲突,因此它会执行最多 M 轮,不断尝试修复,直到所有逻辑一致或达到最大轮数。
还有两个值得关注的点:
- 什么时候做出一致性判断?
- 一致性判断是怎么做出来的?
首先看第一个,它发生在两个位置:
-
每一轮判断 I(D)≠0。
-
U(D) 打分的时候,因为计算U(D)需要计算I(D)。
拿所有 (xi, yi) (xj, yj) 两两配对,判断它们是否逻辑矛盾。
然后看第二个,其实就是一些简单的启发式规则,满足规则的记为c=0,否则记为c=1。比如前面的x2和x3同时为True时就有逻辑冲突,此时,c(x1=True, x2=True) = 1。
论文中没有把 c 函数的规则完全列出(因为和任务密切相关),但有两个共性:
- 只依赖
xi, yi, xj, yj的内容。 - 可设计成“任务无关”的模板规则(简单的逻辑约束)。
比如:
| 任务类型 | 一致性判断 c 的例子(启发式规则) |
|---|---|
| TruthfulQA | 如果两个句子结论矛盾 & 均为 True → 判定为不一致 |
| GSM8K | 如果两者数值计算结果不同 & 都是 True → 判定为不一致 |
| Alpaca | 如果互相对立的两个响应都标为“更好” → 判定为不一致 |
算法1
理解了算法2,算法1就比较简单了。
假设前面的3条数据已经被修复成:
1 | D = { |
接下来进入ICM流程。每一轮会尝试给未标注数据xi打标签,然后:
- 评估相互可预测性。
- 判断是否引入逻辑矛盾(调用算法2)。
- 决定是否接受这个新标签(基于 Δ 和模拟退火)。
假设新样本x4为:“Los Angeles is one of the rainiest US cities.”
- 更新温度T:
T ← max(T_min, T0 / (1 + β log(n))),用于控制“接受坏标签”的概率。 - 采样一个样本xi,即x4。
- 用当前已有标签 D计算概率
Pθ(y4=True | x4,D)和Pθ(y4=False | x4,D),假设分别为0.2和0.8,则预测标签y^4 = False。 - 临时加入标签,
D^ = D ∪ {(x4, False)}。 - 一致性修复。检查:
- x4=False 和 x1=True 是否冲突?是两个不同城市,没有直接冲突。
- x4=False 和 x3=True 是否冲突?两个不同主题,无关,没有冲突。
- 评分函数 U 的变化。
- 相互可预测性 Pθ 是否提升?(x4 被已有标签“合理解释”)
- 一致性惩罚是否增加?(没有 →
I(D^)=I(D))
- 根据Δ或概率决定是否接受标签。
- Δ其实是新标签带来的边际好处或损失。
- Δ > 0 接受新标签,Δ < 0靠退火控制。
总的来看,比较难做的还是这个“一致性判断”。
小结
这篇论文主要介绍了一种无监督算法——内部一致性最大化,其关键还是依赖模型自身能力,尤其是其对数据的预测一致性。论文整体还是比较新颖的,最终效果也达到了与人类相当甚至更好。
总结
自上篇Reward Model建模 | Yam[1]后,这是我们关于Reward相关的第二篇文章,本文介绍的三篇论文中,第一篇和第三篇是偏数据标注的,具体来说是Reward相关pair对的数据标注,第二篇虽说是关于Reward信号和Base模型策略的,但也可以看作数据内隐——什么样的数据造就什么样的策略——带来什么样的能力。
从另一个角度看,第二篇和第三篇都与模型内部推理能力相关,前者侧重于推理策略,后者则使用内部一致性,但总的来说都与Base模型本身能力有关;而第一篇则是典型的标注示范。
最后,不得不感慨一句:Reward真的越来越重要了,毕竟GRPO这种纯靠规则(或法则)的算法实在太诱人了,Reward模型不仅可以用在RLHF中,直接GRPO Policy也是很不错的嘛。不过话说回来,只要我们能找到适当的规则,无论这种规则是纯规则还是模型,这种演绎式算法都可能让我们“言出法随”——玄幻小说的无上功法已经在你我手中啦。
References
[1] Reward Model建模 | Yam: https://yam.gift/2025/06/09/NLP/LLM-Training/2025-06-09-RM-Modeling/
[2] Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy: https://arxiv.org/abs/2507.01352
[3] Spurious Rewards: Rethinking Training Signals in RLVR: https://arxiv.org/abs/2506.10947
[4] R1相关:R1-Zero的进一步理解和探索 | Yam: https://yam.gift/2025/04/10/NLP/LLM-Training/2025-04-10-Think-More-about-R1-Zero/
[5] DeepSeek R1后LLM新范式 | Yam: https://yam.gift/2025/03/15/NLP/LLM-Training/2025-03-15-R1-New-Paradigm/
[6] DeepSeek R1深度技术解析及其影响 | Yam: https://yam.gift/2025/02/17/NLP/LLM-Training/2025-02-17-DeepSeek-R1/
[7] R1相关:少量高质量数据SFT激活LLM推理能力 | Yam: https://yam.gift/2025/02/18/NLP/LLM-Training/2025-02-18-LLM-PostTrain-SFT-Data/
[8] R1相关:RL数据选择与Scaling | Yam: https://yam.gift/2025/02/27/NLP/LLM-Training/2025-02-27-LLM-PostTrain-PPO-Data/
[9] R1相关:DPO数据选择与DPO等RL算法 | Yam: https://yam.gift/2025/03/02/NLP/LLM-Training/2025-03-02-LLM-PostTrain-DPO-Data/
[10] DAPO: https://yam.gift/2025/03/19/NLP/LLM-Training/2025-03-19-LLM-PostTrain-DAPO/
[11] Unsupervised Elicitation of Language Models: https://arxiv.org/abs/2506.10139
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。