好吧,准确来说,GiGPO[1](Group-in-Group Policy Optimization)还是GRPO,只不过它扩展到Agent范围。简单来说,就是把采样轨迹分成多个组,每个组当然对应关键步骤。稍微通用一点来看,其实是更加细粒度的GRPO。很自然地,有两个不同的级别:
- episode-level:与GRPO没两样,最终结果作为奖励基准。
- step-level:新加部分,也是GiGPO的创新点。引入一个锚定状态分组机制,它通过识别不同轨迹中重复出现的环境状态(锚定状态),回溯性地构建步骤级的组。来自同一状态的动作被归为一组,从而实现微观层面的相对优势估计。通过锚定状态,不同轨迹之间的step就变得可以互相比较,这点很重要。
背景
GRPO的效果、重要性啥的就不多说了,大家都在追也说明一些情况。当然不是说都在追的热点就是好的,但起码说明它是一个可以关注的方向。
说句题外话,好多媒体总喜欢搞一些吸引人眼球的标题,类似什么《Karpathy戳破强化学习神话,首提AI复盘式进化!暴力试错将死》之类的,可以说,只要是稍微有点名气的大牛,随便说点啥媒体就一窝蜂上去看看能不能搞点“大事情”。大部分人又都喜欢走捷径,简单来说就是想要一个“最好的”方案,这样其他东西就都不用看了(这也算一种省力法则)。但我们都知道,任何科学领域的发展都不是一蹴而就的,长期的摸索、失败、苦闷才是常态,那种“高光时刻”的时间简直微不足道。连站起来都摇摇晃晃,不是得先慢慢练习站稳、走好再跑么。
本文就是把运行环境转移到Agent,这和解数学题、生成代码之类的任务还是有区别的。
- 首先,Agent的行为往往在一个长回合中展开,包含数十个决策步骤和数万Token;
- 其次,奖励更加稀疏,有时候只有在结束时才出现,导致单个步骤信用难度分配大大增加。
于是就有本文提到的问题:Can we preserve the critic-free, low-memory, and stable convergence properties of group-based RL while introducing fine-grained credit assignment for long-horizon LLM agents?
GiGPO的做法我们开头也说了,就是把每个动作的信用分配到两个维度:episode和step。基本思想就是,在相同任务和初始环境条件下,组内的许多轨迹由于无效动作或陷入循环,会在多个时间点上遭遇相同的环境状态(不然组内就无法比较了)。
GiGPO
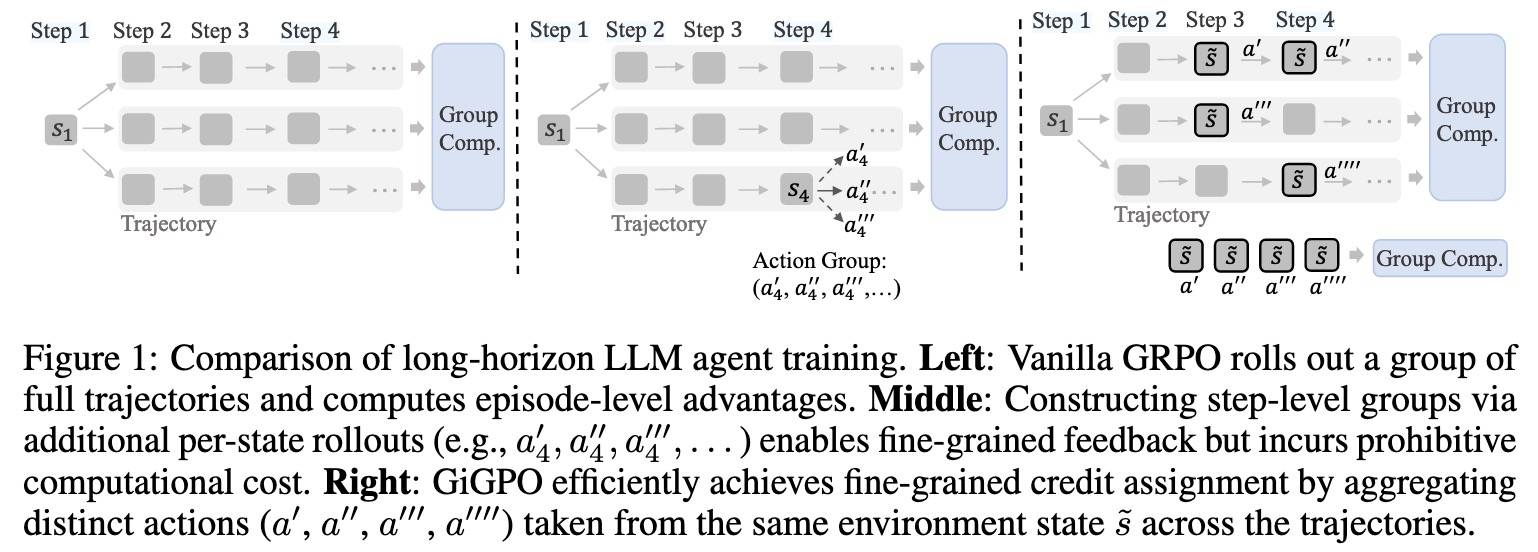
右边是GiGPO的做法,中间是最直接能想到的做法,只不过这样做计算量大而且比较繁琐。GiGPO的做法算是前两种方案的折中方案,个人感觉设计还是比较有意思的,所以也就单独记录一篇。
Episode-Level Advantage
这个和GRPO是差不多的,如下:
τ是采样轨迹,R自然是奖励,R(τi)等于1或者0。
有个不同的是Fnorm,GRPO默认的是std,也就是标准差。但是 DrGRPO[2]发现有问题难度偏差问题:标准差较低的问题(例如,太简单或太困难的问题,结果奖励几乎全为 1 或 0)在策略更新时会被赋予更高的权重。因此,本文使用固定化归一化因子,其实就是和DrGRPO中的方法,即Fnorm=1,这会产生一个最多相差常数缩放因子的无偏估计器(无偏的留一法估计器)。
标准的REINFORCE留一法(RLOO)定义如下:
考虑如下变换(推导与DrGRPO类似):
也就是说,设置Fnorm=1相当于对A^RLOO(τi)进行了重新缩放,而将优势函数按一个常数缩放不会影响策略梯度的动态过程(因为它可以被吸收到学习率中)。简单来说,就是Fnorm=1时优势的估计是无偏的。
总的来说,episode主要关注宏观信用分配,鼓励策略发展连贯的、贯穿整个轨迹的行为,以最大化整体任务表现。
Step-Level Advantage
这个就是本文的重点创新了。因为Episode只能提供整体优势,但是Agent这种场景轨迹太长了,而且一般都可以分成一系列步骤,因此还需要针对性地设计细粒度Step-Level的优势。
Naive的方法就是前面图片的第二种方法,即每个状态采样新动作,但开销太大而且很繁琐。本文通过引入「锚点状态分组」简化了实现。
什么是「锚定状态分组」?所有采样轨迹来自同一task x 且初始条件相同,许多环境状态会在不同轨迹之间,甚至同一条轨迹的不同时间步中重复出现。通过对这些相同状态进行分组,动态构建Step级别的分组。具体来说,所有轨迹会有一组状态集合,每个唯一状态可以被视为一个「隐式锚点」,被称为「锚点状态」。每个锚点状态分组的定义如下:
然后是如何计算相对优势。尽管每个(a,r)都包含一个奖励,但在长时间跨度任务中,该奖励还是可能非常稀疏,为了更好地衡量长期影响,对每一步设计一个折扣因子γ ∈ (0, 1]。Reward定义如下:
每个Action不仅有即时奖励,还有后续影响。此时,式(4)的r可以替换为式(5)的R。
每个锚点状态和动作的Step级别相对优势为:
总的来说,step关注微观信用分配,提供了关于同一状态下不同行动相对优劣的细粒度反馈,提供了step级别的指导。这对于在长时间跨度任务中优化Agent的决策至关重要(后面消融也证实了这点,尤其是复杂任务上更明显)。
Final Loss
式(1)和式(6)合起来构成最终Advantage(group-in-group advantage),在全局和局部两个层面进行信用分配。
注意是Action粒度的Advantage,同一轨迹的AE是一样的。
最终损失函数如下:
没啥多说的,GRPO的变种。
胡思乱想
这里记录一点不一定正确的个人想法,来自于前面式(3)的推导。式(3)得到的是无偏留一估计器,意思是这种估计方式在数学期望上是准确的,不会系统性地高估或低估某个值。
留一法(Leave-One-Out)是一种机器学习交叉验证技术,比如在某一轮训练中,把一个样本拿出来作为验证,其余训练。
Fnorm=1是一个简化的trick,本身是有偏的,但通过乘一个因子(N/N-1)就可以得到与无偏的留一估计器一致的结果。这在实际训练时也比较方便,避免了每次都单独计算 leave-one-out 平均(需要移除当前样本)。也就是说,A^RLOO本身就是一个经典的无偏估计,它通过“去掉当前样本、只用其他样本求平均”来估计 baseline。而设定Fnorm=1(即直接用所有样本的平均作为 baseline)虽然本身是有偏的,但在乘上因子后刚好和 RLOO 等价。
不过代码实现上并没有乘因子,可能出于以下几个原因考虑:
- N比较大时,因子约等于1。比如N=32(BatchSize),因子就是1.032,差异是3%左右,比较小。
- 轻微的偏差有时等于隐式的正则化。
- 工程上实现简单(避免了
N^2复杂度的逐个leave-one-out操作),代码更加统一。
到这里,我们很容易就想到同样不使用标准差归一的RMSNorm:
当然这和留一法没啥关系,单纯的想到而已。不过stackexchange上有人也提了一个类似的相关问题:normal distribution - Should standardization be done using leave-one-out? - Cross Validated[3],看起来也比较有趣。
其实这些方法里多少都有一点统计学的影子,说到统计学,突然又想起一个概念:自由度,它是指在计算某个统计量时,数据中能“自由变化”的独立变量个数。
举个简单例子,对变量a和b,a+b=1,那么自由度就为1,因为只有一个变量能真正”自由变化“。
再说标准化,估计平均值m时,由于样本中的n个数都是相互独立的,任一个尚未抽出的数都不受已抽出任何数值的影响,所以自由度为n。但估计总体方差时所使用的样本方差的计算需要用到均值,均值m在抽样后就确定了。所以,大小为n的样本中,只要n-1个数确定了,第n个数就只有一个能使样本符合均值m的数值。换句话说,样本中只有n-1个数可以自由变化,只要确定了这n-1个数,方差也就确定了,所以样本方差的自由度是n-1。
那为啥我们在深度学习,比如LayerNorm计算时是除以N而不是N-1呢?这里的根本原因是:深度学习中我们并不是在做”估计“,它只是一种”变换“操作——将激活值变成均值为0、方差为1的形式,便于训练。而统计学中,我们是期望通过样本”估计“总体的”真实方差“,如果除以N会低估真实方差,所以需要修正,用N-1使估计无偏。更进一步,在深度学习中,我们更关心的是数值稳定和训练动力学,使用N不引入额外偏移,对稳定性有好处,但限制了网络的表达能力。所以LayerNorm还引入可学习的缩放和平移参数,允许网络调整到最优形状。
其实本质上,LayerNorm这类操作并不关心”有偏“还是”无偏“,它不是在试图还原真实的总体方差,仅仅只是归一化这组激活值。N或N-1的问题不是更正确或更错误的问题,而是哪个更有利于训练表现。所以,同样是计算方差,不同的上下文下所关注的点可能并不相同。
好了,就想到这里,莫名有种很多知识都相通的感觉。
小结
本文主要介绍了GiGPO这一针对Agent训练的GRPO推广算法,主要做法是把Advantage分成全局和局部两个维度,全局的等同于标准GRPO做法,局部的通过锚定状态构建步骤级别分组,为了考虑Action的未来影响在奖励计算时引入折扣因子(这其实是来自经济学中的一个概念,古典经济学时间价值的思想),和GAE里的思想也是一样的。介绍完GiGPO,我们又胡思乱想了一些关于无偏估计、自由度的关联,感觉到知识的魅力。
其实在读论文的时候,我就一直在想这个算法除了论文中提到的场景,还可以怎么用到工作中,或者其他哪些地方。后来看到一篇图像相关论文时,突然想到,这个算法是不是可以用在视频生成中?看起来视频生成的过程和Agent完成一项任务有一些共同之处,不过前提当然是Base模型本来的生成能力就不错了,另外可能也会很费卡。。。
References
[1] GiGPO: https://arxiv.org/abs/2505.10978
[2] DrGRPO: https://yam.gift/2025/03/28/NLP/LLM-Training/2025-03-28-LLM-PostTrain-DrGRPO/
[3] normal distribution - Should standardization be done using leave-one-out? - Cross Validated: https://stats.stackexchange.com/questions/224982/should-standardization-be-done-using-leave-one-out
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。