背景
说起 SFT,可能只要是这一行的,哪怕刚入门都能说道几句,但当我们仔细深入分析后就会发现它没那么简单。就好像你知道自然音阶,也能在钢琴上找到 do re mi fa suo la xi,但弹不好一首曲子。
我们从 SFT 和 RL 的对比讲起。关于 SFT 和 RL 的一般观点是这样的:SFT 主要侧重高效注入知识和技能,获得遵循能力。RL 则通过奖励信号引导模型探索,提升泛化。而 SFT 有两种常见的失败模式:
- 灾难性遗忘和分布外泛化能力下降。
- 倾向于过度约束策略,降低了多样性,缩减了下游 RL 的探索空间。
我们此前在《DeepSeek R1后LLM新范式 | 长琴[1]》中也提到过 SFT、RL、DPO 的区别,并在《RL究竟能不能突破Base边界——关于推理能力外推、稳定性与训练条件的系统分析 | 长琴[2]》中明确罗列:
- SFT 展示出来“相对还可以的固定路径”,因为激活的数据是确定的。
- RL 展示出来“比较好的那条路径”,因为数据是随机 rollout 出来的。
- DPO 介于两者之间,展示出来“相比较还可以的固定路径”。
这个分析是基于当时的一系列相关 paper 实验结果做出的提炼,看起来比较直觉。
SFT缺陷分析
最近的 paper 2604 GFT: From Imitation to Reward Fine-Tuning with Unbiased Group Advantages and Dynamic Coefficient Rectification[3](后面简称 GFT)对 SFT 做了理论上的深入分析。文章证明了 SFT 可以被解释为强化学习的一种特殊情形,其存在两个根本性缺陷:
- 受单路径依赖限制,将学习信号(隐式奖励就是 GT token)局限于确切的专家轨迹,导致探索不足和熵崩溃。
- 优化过程中容易受到梯度爆炸的影响。梯度更新被一个不稳定的重要性权重 (token 概率的倒数)缩放,有效但不熟悉的专家 token 会使该权重过度增大,从而引发梯度爆炸,并使模型趋向于机械记忆和过拟合。
简单来说,就是单路径 + 导致的熵崩。先看这个重要性系数是怎么来的。
SFT 的梯度如下:
它要求模型在面对 时,最大化专家答案 的概率。论文把这个“在专家数据集上算出来的期望”,强行转换成“让模型自己去生成文本(在 分布上)算出来的期望”。这就需要重要性采样系数:如果要将分布 的期望换成分布 的期望,只需要在里面乘以一个修正系数 即可。
又有:
代入梯度得:
下面就好说了,SFT 数据集里,对于某一个提示词 ,正确的专家答案 通常是唯一且确定的,即可认为其概率为 1。可以用一个指示函数来表示:
- 当模型生成的 刚好等于专家答案 时,
- 当模型生成的 不等于专家答案 时,
即:
继续代入梯度后得:
如果放在 RL 框架内看 SFT:
- 奖励极度稀疏:只有完全踩中唯一的专家路线才给 1 分,其余情况(哪怕写得再好、思路再对)一律给 0 分。
- 权重极不稳定:就是前面提到的分母 ,想象一下,有一个非常好但模型目前还没学会的 token,模型对它的预估概率极低,比如 ,求倒数后,权重直接变成 1000,梯度更新的幅度会被直接放大 1000 倍,梯度爆炸。这等于逼着模型去死记硬背,最终导致了灾难性遗忘和多样性崩溃。
其实,和我们之前的直觉是统一的:SFT 就是固定住了某条路径——如果是专家数据,那就是比较好的路径;如果是垃圾数据,那路径就比较烂。
遗忘机制与度量
其实至少早在 2509 RL’s Razor: Why Online Reinforcement Learning Forgets Less[4] 中就已经对 SFT 和 RL 做了一些对比分析(可以肯定,类似的研究肯定还有很多)。他们发现,即使 SFT 和 RL 在新任务上达到相同的性能,SFT 通常通过消除先验知识来获得新任务收益,而 RL 则更好地保留了旧技能。也就是说,SFT 更会遗忘。
大量实验结果揭示了一条经验性遗忘定律:当在新任务 τ 上对模型 π 进行微调时,遗忘程度可被 准确预测,即微调后策略与基线策略在新任务上所对应的 KL 散度。
文章进一步揭示了一个简单但强大的原则—— RL 剃刀(类似奥姆剃刀?):在众多针对新任务的高奖励解中,on-policy 方法如 RL 本质上倾向于选择在 KL 散度上更接近原策略的解,而 SFT 则可能收敛到与基础模型相距任意远的分布。
文章分析认为,这种偏差直接源于 RL 的 on-policy 训练:通过在每一步从模型自身的分布中采样,RL 将学习限制在基础模型已赋予非可忽略概率的输出范围内。为了提升奖励,这些样本被重新加权并用于更新模型,从而逐渐改变策略,而不是将其拉向任意分布;进一步的实验还表明,即使没有显式的正则化,策略梯度方法也会收敛到 KL 极小值解。相反,SFT 则可根据提供的数据收敛到距离原策略更远的解——而这个距离其实就是 KL 散度。
为了进一步证明这个观点,文章构建了一个“最优 SFT”分布,该分布可证明在实现完美准确率的同时最小化 KL 散度。在此最优分布上进行训练所产生的遗忘程度甚至低于 RL——也就是说,SFT 的遗忘其实可以看作是训练数据的一种「偏移」。RL 的优势并非源于其本质上的不同,而是源于其隐含的 KL 最小化机制。只要训练偏向于 KL 极小值解,遗忘就会减少。
当然 RL 和 SFT 还是不同的,表现在:
- 采样分布。RL 中,训练是在从模型自身分布中抽取的输出上进行的,而在 SFT中,这些输出来自外部标注。
- 负样本。RL 中,从策略采样的部分 response 可能是错误的,一般会给一个负的 advantage,将概率从不良输出中推开,而 SFT 则没有。
总的来说,就是文章给的三个 takeaway:
- RL 能够在学习新任务时产生最小的遗忘,而 SFT 虽然能达到相似的新任务性能,但必须以牺牲先验知识为代价。
- 在 SFT 和 RL 中,灾难性遗忘可通过微调后模型与基础模型在新任务上的 KL 散度预测。当 SFT 被明确引导至 KL 极小值分布时,其性能能够超越 RL。
- On-policy 训练解释了为什么强化学习保持的 KL 散度比 SFT 更小。从模型自身的分布中采样,使其贴近基础模型,而 SFT 则将其推向任意的外部分布。
最后,文章提出了一种新的设计维度:算法的评估不仅应基于其优化新任务的能力,还应考量其相对于基础模型在 KL 意义上的保守程度。这里的重点不是离线数据是否有价值,而是持续学习需要更新以保持学习过程接近 KL 的极小路径——这是新的终身学习范式。
其实,这非常呼应我们已知的一些观点,尤其是《RL究竟能不能突破Base边界——关于推理能力外推、稳定性与训练条件的系统分析 | 长琴[2]》中的观点,比如 RL 主要 refine,只有在特定条件下才可能带来真实的能力提升;再比如我们在诸如《DeepSeek R1后LLM新范式 | 长琴[1]》等多篇文章中提到的激活效应——SFT、DPO、GRPO 其实可以具备同样的效果。
泛化机制与条件
介绍完遗忘机制,我们知道,所谓的”遗忘“可能只是姿势(数据)不对,接下来我们看看泛化。
非常巧的是,paper 2604 Rethinking Generalization in Reasoning SFT: A Conditional Analysis on Optimization, Data, and Model Capability[5] 和 GFT 差不多在同一时间(一周前)发表。他们提出了另外一个有意思的观点:SFT 也能泛化,但有一定条件——由优化动态、训练数据和基础模型能力共同决定。问题从 SFT 能否泛化转移到“在什么条件下”、“以什么代价”实现泛化。
几个核心观点罗列如下:
- 表面的泛化能力不足可能是优化不足的产物。长链思维 SFT 过程中,泛化性能表现出一种先下降后回升的模式。
- 训练数据对泛化至关重要。数据质量和数据结构都非常重要。
- 泛化需要足够的模型能力。强的模型在多个领域展现出广泛的泛化能力,而较弱的模型则表现出微弱或负增益。
- 泛化具有非对称性。长链思维 SFT 在性能提升的同时会削弱安全性。
所以,SFT 不能泛化的结论,其本质是某个因子不足,而不是 SFT 本身不能泛化。这也是论文提到的——什么条件、什么代价泛化。
SFT融合RL
其实这个 Mix-policy learning 算是一个比较独立的子方向,比如 HPT[6] 里提到的 LUFFY[7] 在每个 batch 中固定比例地混合离线示范数据和在线 rollout;SRFT[8] 采用单一训练阶段,根据模型策略熵动态调整 SFT 和 RL 损失的权重,验证了在一个 pipeline 中统一这些信号的可行性;AMFT[9] 探索基于元梯度的控制器。这里主要介绍两个工作,一个自然就是刚刚提到的 HPT[6],另一个则是开头提到的 GFT[10]。
HPT:SFT和RL是同一估计器的不同配置
HPT 的论文是 2509 Towards a Unified View of Large Language Model Post-Training[11],算是 Mix-policy learning 的一个集成者,一套框架将各类后训练目标的梯度形式化归约为统一表达式。
我们先从所有后训练算法共有的简单且普遍的目标出发:增加正向轨迹的似然,减少负向轨迹的似然,从而使总奖励的期望 最大化。后训练可以建模为一个旨在最大化期望成功率,同时确保模型策略严格遵循示范数据集行为策略 的过程。
其中 表示来自给定分布的问题,τ 表示轨迹,r 表示(二元/实数)reward 得分, 表示标注示范数据中的行为策略。熟悉 RL 的同学一眼就看能看出来,其实它就是 Reinforce[12] 带一个 KL。
梯度如下:
补充说明下,在 On-policy 理想假设下,因为采样分布就是当前要优化的分布,所以写目标函数时不需要任何重要性采样系数。但是,如果采样策略()和当前优化策略()不一致了(Off-policy),为了修正这个分布偏差,就必须引入重要性采样系数。
结合参考策略 和对数求导技巧,
嗯,重要性系数出现了。注意这个系数的分子因为对数求导技巧被吸收进梯度里面了。
这样做的目的很简单,可以漂亮地兼容 SFT 等其他后训练算法:通过写成 ,我们可以在下表中非常直观地看到不同的算法在更新时,底层的 token 级别权重(分母)到底是谁。
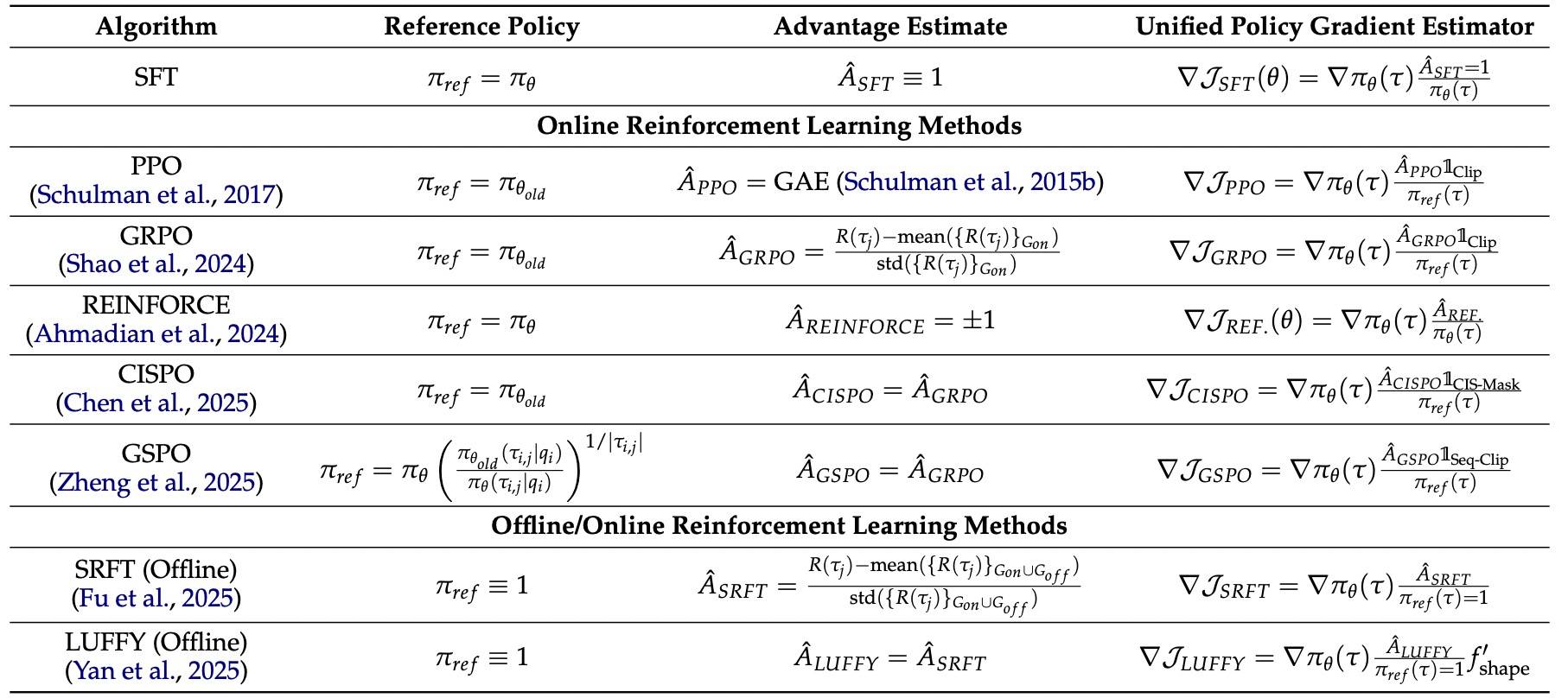
比如 PPO 的分母是旧策略 ,SFT 的分母是当前策略 ,而离线 RL 因为拿不到环境采样概率,只能强行让分母等于 1。
Advantage 也有一个统一的形式:
重点看 SFT 的定义,它被定义为:人类专家(或行为策略)的概率 与当前模型概率 的比值。
- :说明专家喜欢这条轨迹,但当前模型对它的预测概率低(模型还不会),此时 ,就会作为一个正向奖励(正优势)让模型去增大对这条专家轨迹的生成概率。
- :说明当前模型产生这条轨迹的概率已经超过了专家,此时 ,正向推动力就会变小。
再来看 SFT 的梯度,因为采样分布就是专家分布 ,所以式 10 可以写为:
把 代进去:
最终得到:
这正是标准 SFT 交叉熵损失梯度!
后续分析表明,不同梯度形式不仅互不冲突,而且可以作为互补学习信号共同指导优化过程。但是这些梯度估计量具有不同特性,各自梯度分量间存在偏差-方差权衡。所以,需要对梯度中的不同组件(稳定掩码、参考策略、优势估计与似然梯度)进行权衡,后面三项可以从上面的表格中看到。掩码相关可以关注 CISPO[13]、DAPO[14]、GSPO[15]、Clip-Cov[16] 等。
最终,文章提出 HPT(Hybrid Post-Training )算法,动态调整 SFT 与 RL 损失间的混合比例,自适应选择更理想的训练信号。值得一提的是,它是 Binary 选择的,要么激活 RL 的损失,要么激活 SFT 的。更多细节可以阅读原文,这里不再赘述。
GFT:SFT是RL的一个特例
看完了 HPT,我们再看一下 GFT,前面《SFT 缺陷分析》部分其实我们已经能看的出来,它真的和 HPT 非常类似,尤其是 SFT 和 RL 统一的那块。GFT 当然也给出了自己的方案。
在看论文怎么处理之前,我们不妨先想想,你有没有觉得不对劲?这好像和我们真实做 SFT 感觉不一样,SFT 好像并没有前面分析的那么脆弱(权重极不稳定)。
仔细回看,之前在《SFT 缺陷分析》那里的推导有两个隐含假设其实不必然成立:
- 只有唯一一条专家路线正确,其他任何回答方式的概率全部为 0。
- 序列级别完全匹配才算对,哪怕只有一个标点不一样,都不算对。
虽然假设不严格成立,但提供的分析视角——SFT 为什么表现不好,是对的。据此,论文引入了两种关键机制。
第一,分组优势学习。为每个 query 提供多样化的 response,包括:专家示范、教师模型输出、模型自己生成三组。Advantage 计算时,均值和标准差是对应组的。
第二,动态系数修正。主要是针对那个分母带来的不稳定性,具体表现在:
- 当模型通过生成不确定或更加多样化的响应来增强探索时,预测得到的 token 概率 可能会变得很小,从而导致对应的更新系数被异常放大。这点我们之前分析时提到过了。
- 即使是在拟合专家示范数据或教师蒸馏生成的响应时,模型也可能在初始阶段对那些虽然正确但较为陌生的 token 赋予较低概率,这照样会放大加权项。
受梯度裁剪技术启发,论文提出一种简单的校正函数,用于稳定训练过程。
其中, 是一个置信度阈值, 表示 stop-gradient,即概率低于阈值时,停止梯度,非常简单的方法。
重新认识SFT
看到这里,是不是觉得 SFT 其实好像也并没有那么简单?尤其是和 RL 纠缠在一起的时候,更是如此,各种关系非常微妙。这其实就是很多研究可能只是触碰到了一小部分的图景:不同的条件、不同的假设、不同的数据、不同的训练方法等等,稍微一个地方不一样,就可能得出完全不同甚至相反的结论——我们还都在摸索。
SFT分层
刚刚提到不同的条件、假设等,比如 GFT 就有两个隐含假设,再比如 Conditional SFT[17] 有三个条件。其实,很多时候大家都对,但可能触碰到 SFT 的不同层次。这里我们把 SFT 的目标分成三层:激活层、指令遵循、知识注入。
第一层,能力激活层。只需要少量数据即可,我们在《DeepSeek R1后LLM新范式 | 长琴[1]》等多篇文章中提到过,这个是已经被实验证实过的观点。SFT 其实是把概率质量压到某条(或某一族)轨迹上。这也和 Conditional SFT[17] 的观点一致:“弱 base 上几乎没有可激活的东西,SFT 只能硬记”。
第三层,知识注入层。要拉高很多 base 里概率很低的 token,这正是 GFT 里 爆炸的场景,此时更接近 “记忆”,而非 “泛化”。这种情况下,SFT「能泛化」的叙事往往不成立,或者代价是遗忘、安全性不对称下降(具体见 Conditional SFT[17] )。
第二层,指令遵循层。介于第一和第三层之间,一部分是激活,比如 think tag、step-by-step 风格 base 里就有,还有一部分是行为塑性,容易锁路径,正如我们在《RL究竟能不能突破Base边界——关于推理能力外推、稳定性与训练条件的系统分析 | 长琴[2]》中的观点。GFT 的「单路径 + 稀疏奖励」在这里最明显:不是学新能力,而是把输出空间收窄到示范(和教师)分布。
总的来说,SFT 的「可泛化」多半发生在激活层;GFT 中描述的缺陷,在需要大量陌生 token 更新的层面上仍然成立。所以,确实如 Conditional SFT[17] 所言,SFT 不是「能不能泛化」,而是「哪一层在泛化、哪一层在记忆」。
另外,关于 Conditional SFT[17] 说到的先降后升,可以猜测是不是早期按 GFT 机制,快速压分布,看起来像过拟合、多样性掉;但是中后期,如果 base 够强、数据结构好,模型在已激活的子空间里重新找到了更宽的区域(激活的可迁移部分显现)。
实践指南
上面说了这么多机制,在实践中其实可以转成两个问题:
- 这次后训练追求的主要是“激活已有原语”,还是“注入陌生 token / 知识”?
- 以及,为了新任务提升愿意付出多大分布迁移成本(可以粗略理解为 KL shift)?
根据前面内容,整理表格如下:
| 目标 | 更合适的理解 |
|---|---|
| 推理 / CoT 风格 | 少量高质量 SFT 往往就能激活出一条“还可以的固定路径”,但它本质上是在压分布,训练久了依然有熵崩塌/锁路径风险。强 base + 好数据结构时,conditional SFT 的“先降后升”更可能出现。 |
| 新领域知识 / 陌生 token 密集 | 更接近“把低概率 token 拉上来”,天然容易走向机械记忆与遗忘:GFT 的 视角在这里最贴切。此时别轻易相信“多训几步就会泛化”,更该关注遗忘与分布外退化。 |
| SFT vs RL 选择 | 如果希望“学到新任务”但尽量少忘旧能力,优先考虑 on-policy RL(或至少引入 on-policy 成分):RL’s Razor[18] 的结论是遗忘几乎由新任务上的 KL shift 决定,而 on-policy RL 隐式偏向 KL 更小的解;SFT 则可能收敛到离 base 很远的任意解。 |
| SFT → RL / 混合训练 | 经典两阶段(先 SFT 再 RL)不是必然最优。更统一的看法是:SFT/RL 都是同一类 policy gradient 估计器的不同取值,差别主要来自数据源(offline vs rollout)和稳定化部件;因此可以考虑在同一训练里动态混合(例如 Towards a Unified View of LLM Post-Training[19] 的 unified estimator / HPT 思路),在“需要外部锚点”时用示范拉一把,在“已具备起点”时把探索权重交给 RL。DeepSeek R1 的冷启动+GRPO就是这个思路。 |
另外,笔者近期也有一些关于 SFT 的新的感悟。
- SFT 数据分布与效果紧密相关,如果覆盖不足,哪怕 2-3% 的数据也会导致效果断崖式下跌。当时这个实验结果着实令人惊讶,对于没见过的分布,你不行就是不行,没有泛化什么事儿。果然,还是“数据决定上限,算法逼近上限”——机器学习时代的 slogan 依然存在,之所以在 LLM 时代感觉没那么明显,很有可能是 LLM 在训练时已经见过了太多数据。另外,高端的食材往往只需要朴素的烹饪。当你把数据搞好后,什么 DPO、GRPO 可能都打不过朴素的 SFT。这里不少人(尤其新人)可能要存在一个误区,即“DPO、GRPO 更高级,SFT 比较 low”,其实看起来更高级的算法也只是为了更好地利用数据,或压根没有数据没办法才想出来的……
- Instruct 版本不能训的太狠(塞太多数据),这会导致后面继续 SFT 时空间较小,难以调出效果(比如 Qwen 有这个趋势,尤其是 3 以后)。关于这点,我们在《RL究竟能不能突破Base边界——关于推理能力外推、稳定性与训练条件的系统分析 | 长琴[2]》也有个类似结论:“RL 只有在特定条件下才可能带来真实的能力提升:任务在预训练中未被充分覆盖,且训练数据恰好位于模型的能力边缘。”该文章还有个关于中期训练(mid-training)的结论:“中期训练负责植入并稳定必要的先验与原语,RL 负责放大探索、推动能力边界。”
- 保证数据的前提下,Lora 大部分时候能和 Full SFT 效果相当,有时候甚至泛化更好一些。
小结
本文借助几篇 paper 重新思考了 SFT,以及其与 RL 的关系。
- SFT 展示“相对还可以的固定路径”,因此它也可以做能力激活;从统一视角看,它等价于一种极端的、单路径的 RL 化更新,天然更容易压熵、锁路径,并在陌生 token 上触发不稳定更新( 放大)。
- GFT[10] 告诉我们:SFT 的两类缺陷(单路径依赖、更新不稳定)分别对应探索不足和机械记忆,这两者在“知识注入层”尤其致命。
- Conditional SFT[17] 则告诉我们:在强 base、好数据结构、合适优化动态下,SFT 可能出现泛化回升——但它更像“激活层的可迁移部分显现”,而不是把知识注入变成了真正的泛化学习。
- RL’s Razor[18] 提出遗忘定律:遗忘程度主要由新任务上的 KL shift 决定;并由此提出 RL 剃刀:on-policy RL 隐式偏向 KL 更小的解,而 SFT 可以走到离 base 很远的任意解。我们多了一个新的可观测维度:激活常对应小 KL,注入常对应大 KL。
- Unified View / HPT[20] 把 SFT/GRPO/SRFT 等写成同一个 unified policy gradient estimator 的不同组件选择,从数学上来说它们可以是统一的,没有谁更高贵,只有谁更适合。
- “先 SFT 再 RL”并不一定处处需要,更重要的是识别起点——当 base 里有原语时,给 RL 探索空间;当 base 缺起点时,用最小的外部锚点把它推出 pass@k=0。
我们把这些工作合在一起看,并不是要争论“SFT 到底能不能泛化”,“RL 是不是比 SFT 更高级” 这类话题,通过综合分析,我们可以清楚地发现 SFT 里同时存在的两种相反的机制——一种在激活(可迁移、数据需求低),另一种在压缩与牵引(锁路径、易遗忘、知识注入时尤甚)。“SFT 有结构性缺陷” 和 “SFT能泛化” 并不冲突,光不是还具备波粒二象性吗……
Reference
[1] DeepSeek R1后LLM新范式 | 长琴: https://yam.gift/2025/03/15/NLP/LLM-Training/2025-03-15-R1-New-Paradigm/
[2] RL究竟能不能突破Base边界——关于推理能力外推、稳定性与训练条件的系统分析 | 长琴: https://yam.gift/2025/12/31/NLP/LLM-Training/2025-12-31-RL-Are-You-OK/
[3] 2604 GFT: From Imitation to Reward Fine-Tuning with Unbiased Group Advantages and Dynamic Coefficient Rectification: https://arxiv.org/abs/2604.14258
[4] 2509 RL’s Razor: Why Online Reinforcement Learning Forgets Less: https://arxiv.org/abs/2509.04259v1
[5] 2604 Rethinking Generalization in Reasoning SFT: A Conditional Analysis on Optimization, Data, and Model Capability: https://arxiv.org/abs/2604.06628
[6] HPT: https://arxiv.org/abs/2509.04419
[7] LUFFY: https://arxiv.org/abs/2504.14945
[8] SRFT: https://arxiv.org/abs/2506.19767
[9] AMFT: https://arxiv.org/abs/2508.06944
[10] GFT: https://arxiv.org/abs/2604.14258
[11] 2509 Towards a Unified View of Large Language Model Post-Training: https://arxiv.org/abs/2509.04419
[12] Reinforce: https://yam.gift/2025/10/24/NLP/LLM-Training/2025-10-24-ReinforcePP/
[13] CISPO: https://yam.gift/2025/06/19/NLP/LLM-Training/2025-06-19-CISPO-and-Entropy/
[14] DAPO: https://yam.gift/2025/03/19/NLP/LLM-Training/2025-03-19-LLM-PostTrain-DAPO/
[15] GSPO: https://yam.gift/2025/08/14/NLP/LLM-Training/2025-08-14-Token-Level-GSPO-GMPO/
[16] Clip-Cov: https://arxiv.org/abs/2505.22617
[17] Conditional SFT: https://arxiv.org/abs/2604.06628
[18] RL’s Razor: https://arxiv.org/abs/2509.04259v1
[19] Towards a Unified View of LLM Post-Training: https://arxiv.org/abs/2509.04419
[20] Unified View / HPT: https://arxiv.org/abs/2509.04419