今天介绍一篇 Agentic RL 相关的比较巧妙的论文:2605 GAGPO: Generalized Advantage Grouped Policy Optimization[1],如果用一句话简要概括,那就是:“用 GROUP 的方法计算 V”,效果不错,以至于当时看了第一反应是怀疑。不过仔细阅读全文后,发现确实很有意思,而且实验也比较全面。
它的出发点很简单——不要 Value 模型,怎么把后续结果有效地回传到每个中间步骤。本文提出的 GAGPO = Generalized Advantage Grouped Policy Optimization,它是一种无需 Critic 的 RL 算法,能够实现精确的、与步骤对齐的时序 credit assignment。
做法更加简单——从采样得到的 rollout 中构建一个非参数化的分组价值代理,然后通过 TD/GAE 把最终结果的监督信号沿时间维度传播到前面的每一步(注意是 Step,不是 Token)。
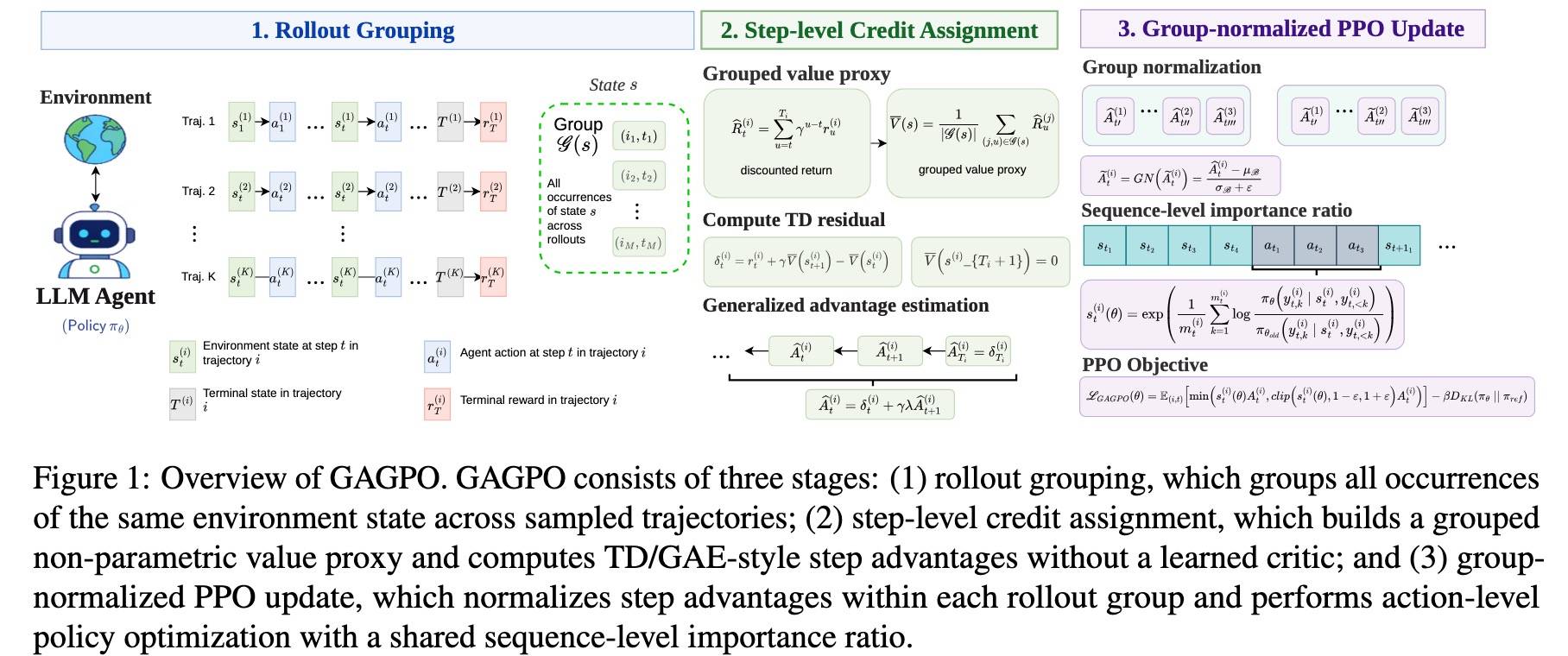
这里的关键就是第二步——用 GRPO GROUP 的方法计算 V,然后用 GAE 的方法计算每一步的 A(注意,每个 Step 的所有 Token 的 A 一样)。而这一步的关键是 Agentic 任务相对稳定的 State。
从Loss开始
基本思想和大概流程已经说完了,我们直接从 Loss 开始看算法细节吧。
标准的 GRPO 形式,这不是重点,我们继续往下。
这个重要性采样系数值得说一下。 是轨迹,我们可以先不管。 是 action 的有效 token 数,这是一个整个 action 层面 sequence-level 的比率。从这点上来说,和 GSPO 是类似的,更多 ratio 粒度建模可阅读《GRPO“第一背锅侠”Token Level X:DAPO/DrGRPO与GSPO/GMPO的殊途同归 | 长琴[2]》。
好了,公式里最重要的 A 要来了。我们前面提到过,A 是 GAE 式计算的(可阅读《R1相关:RL数据选择与Scaling | 长琴[3]》):
其中,λ 是GAE的参数,用来平衡偏差与方差。γ 是折扣因子。 是 TD 误差,定义如下:
递归展开(简单起见过程去掉 i):
其中,最后一步的 V 为 0。这里是根据 A 的定义:,即优势=动作价值-状态价值,终止状态没有后续 reward,按惯例 ,因此 。这些内容我们在《TRPO深度拆解:为什么做后训练应该读懂TRPO | 长琴[4]》也提到过,都属于 RL 的常识。
如何算V
这是本文最重要的创新点,公式如下:
其中,
重点来了——对每个状态 ,相应的组定义为 , 其实就是收集所有轨迹中的 state 为 的,对于每个 step ,根据式(7) 计算折扣奖励。然后根据公式(6) 计算每组状态 的 V,拿到所有状态的 V 后再根据公式(4) 和 (5) 计算 A。
简单来说,因为 Agent 经过的步骤有很多是重复的,我们把每条轨迹这样的步骤(比如 Action 文本)作为组员,计算 R,然后得到 V。这里的 R 也不是轨迹的奖励,而是折扣奖励。如果轨迹失败了,,则中间每一步的奖励都为 0;相反,如果成功了,则按指数衰减,越往前奖励越小。注意,轨迹中间步骤奖励为 0,所以奖励其实是:、、……,第一步的奖励最小。
关键点讨论
看到这里,不难发现,本文方法能起作用的关键是:
- 步骤的输出是稳定的、重复的。如果不是这样,所谓的 V(s) 就毫无意义,或无法计算。所以这个方法不能简单地直接迁移到 LLM 上,大家不妨想想,如果要迁移到 LLM 应该怎么设计呢?
- 步骤不能太多。太多步骤会导致前期奖励很小,如果一开始的步骤非常重要,那其实无法给到足够的奖励。
- 有个假设:越靠近终点的步骤越重要。这是 折扣率隐含的偏置,并不总是对的(比如关键决策点常在轨迹早期)。
总的来看,GAGPO 用折扣率和组内粗暴平均,强行给模型一个“能分清远近、能做路径筛选”的梯度信号。这是比较巧妙的工程 trick。最终效果其实是非常不错的,在 ALFWorld 和 WebShop 上都明显超过 GiGPO[5]。
vs GiGPO
GiGPO 是双层 A 的搞法,episode-level 就是普通的 GRPO,没啥说的;重点是 step-level,引入一个锚定状态(同轨迹中重复出现的环境状态)分组机制,GAGPO 的做法也差不多。 的定义也是一样的,区别只是 GiGPO 是直接用 R 去算 A,GAGPO 则是用类似方法去算 V,然后用 GAE 方法去算 A,感觉可以叫 “双折扣驱动的 step-level 优势函数”。
但是 GAGPO 在实验上居然比 GiGPO 好了很多(看最后两行):
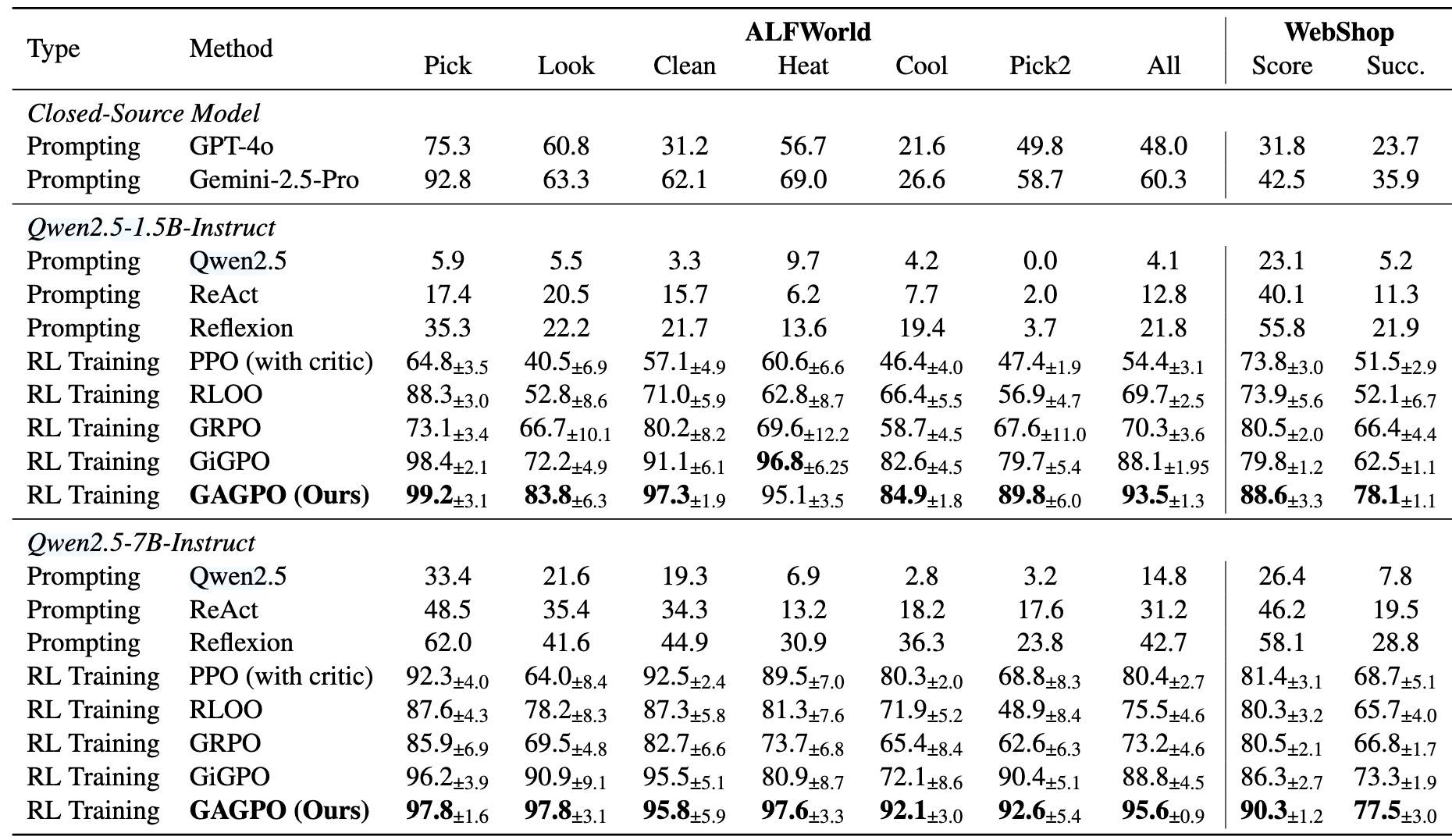
这也是我刚看到这篇 paper 时有点疑惑的地方,感觉得找个时间试一下。盲猜可能是:
- GAE 提供了 bias-variance trade-off?
- V(s) 作为 baseline 减掉之后方差更低?
- 还是说 GAE 提供了时序性质?
小结
本文简单介绍了 GAGPO,GiGPO 把组内信号当 advantage,GAGPO 则把组内信号当 V,然后让 GAE 去算 advantage,有种把 GiGPO 拉回到 PPO+GAE 路线上的感觉。初步分析来看,在状态高度重复、horizon 不太长、reward 最后给的 agentic 任务里,效果比较好。
Reference
[1] 2605 GAGPO: Generalized Advantage Grouped Policy Optimization: https://arxiv.org/abs/2605.13217
[2] GRPO“第一背锅侠”Token Level X:DAPO/DrGRPO与GSPO/GMPO的殊途同归 | 长琴: https://yam.gift/2025/08/14/NLP/LLM-Training/2025-08-14-Token-Level-GSPO-GMPO/
[3] R1相关:RL数据选择与Scaling | 长琴: https://yam.gift/2025/02/27/NLP/LLM-Training/2025-02-27-LLM-PostTrain-PPO-Data/
[4] TRPO深度拆解:为什么做后训练应该读懂TRPO | 长琴: https://yam.gift/2026/05/11/NLP/LLM-Training/2026-05-11-TRPO/
[5] GiGPO: https://yam.gift/2025/07/25/NLP/LLM-Training/2025-07-25-GiGPO/