TL;DR
本文系统梳理了让LLM"先规划再回答"的各类方法,从数据构造(结构化中间表示、层次抽象)、机制设计(注意力对齐、思维 token 注入)到认知启发(ACT-R分层、元思维进化)逐层深入,最后追问"规划的本质",指出显式token规划存在局限,潜在空间(latent)规划或许更接近真正的思考——非线性、可中断、全局感知。
当 reasoning 成为一种数据格式后,下一个很自然的想法就是 “如何 reasoning”,由此引出的做法可谓是五花八门。本文就尝试从这一角度进行梳理,探讨「如何思考(规划)」,或者等价于「如何构造思考数据」。毕竟,重点一直都是「搞数据」和「搞高质量数据」。
注意,思考和规划大多数时候是一个意思,但规划多了一点显式约束的意思,思考过程也隐含了规划信号。
先规划再响应
最容易想到的的 naive 方案,论文 2505 Learning to Plan Before Answering: Self-Teaching LLMs to Learn Abstract Plans for Problem Solving[1](LEPA)就是训练 LLM 在处理问题细节之前,先制定预期计划,这些计划作为解决问题的抽象元知识。
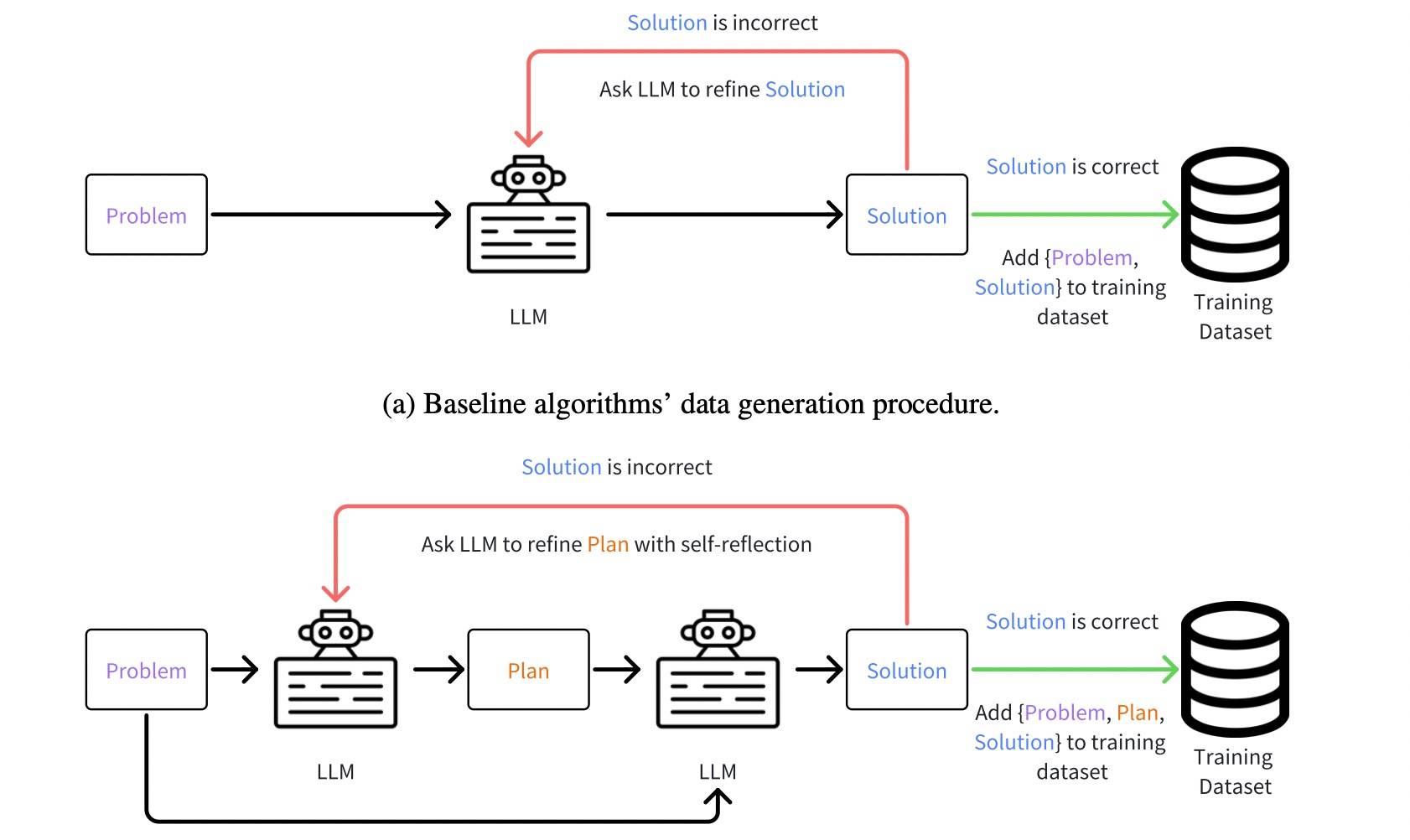
具体而言,在数据生成过程中,LEPA 会提示 LLM 先制定一个包含高级问题解决步骤的预期规划,然后生成一个与问题和规划都相符的解决方案。如果解决方案正确,则将 “规划 - 解决方案对” 存储到训练数据集中。否则,会要求 LLM 反思规划和错误的解决方案,并改进规划,直到它成功促使 LLM 生成正确的解决方案。
Agentic 也是类似做法,只不过反馈的是执行或 action,Self-Steering Language Models[2] 提出 DisCIPL(Distributional Constraints by Inference Programming with Language Models)的“自引导”语言模型方法,其中规划器模型生成特定于任务的推理程序,并由一组跟随者模型执行。
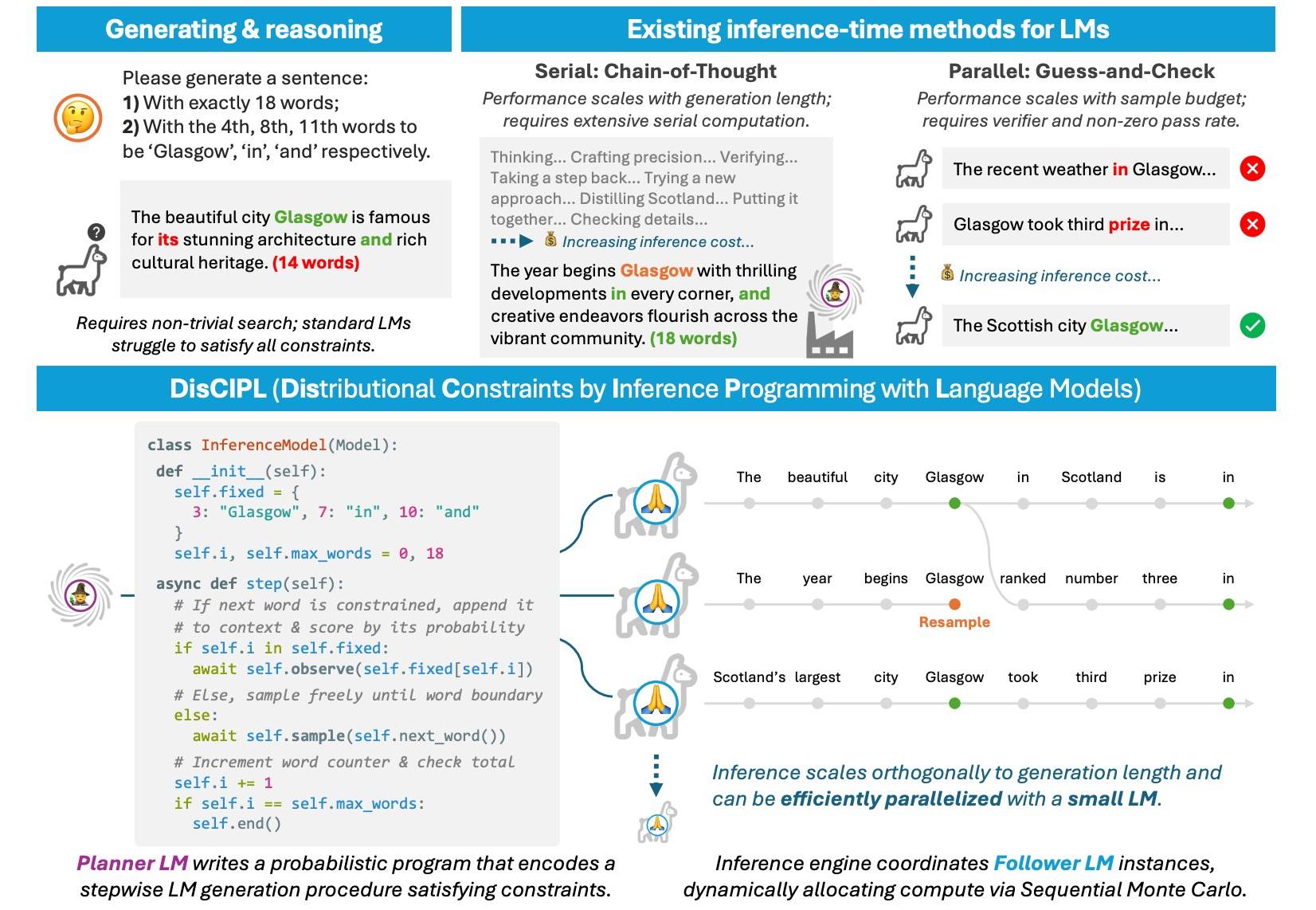
一个规划器语言模型(Planner LM)编写推理程序,以定义逐步计算过程,从而引导一组跟随者语言模型(Follower LMs)。该方法结合了串行与并行方法的优势:规划器通过构造保证正确性,而跟随者则通过协同搜索高概率序列。
如何做好规划
数据角度
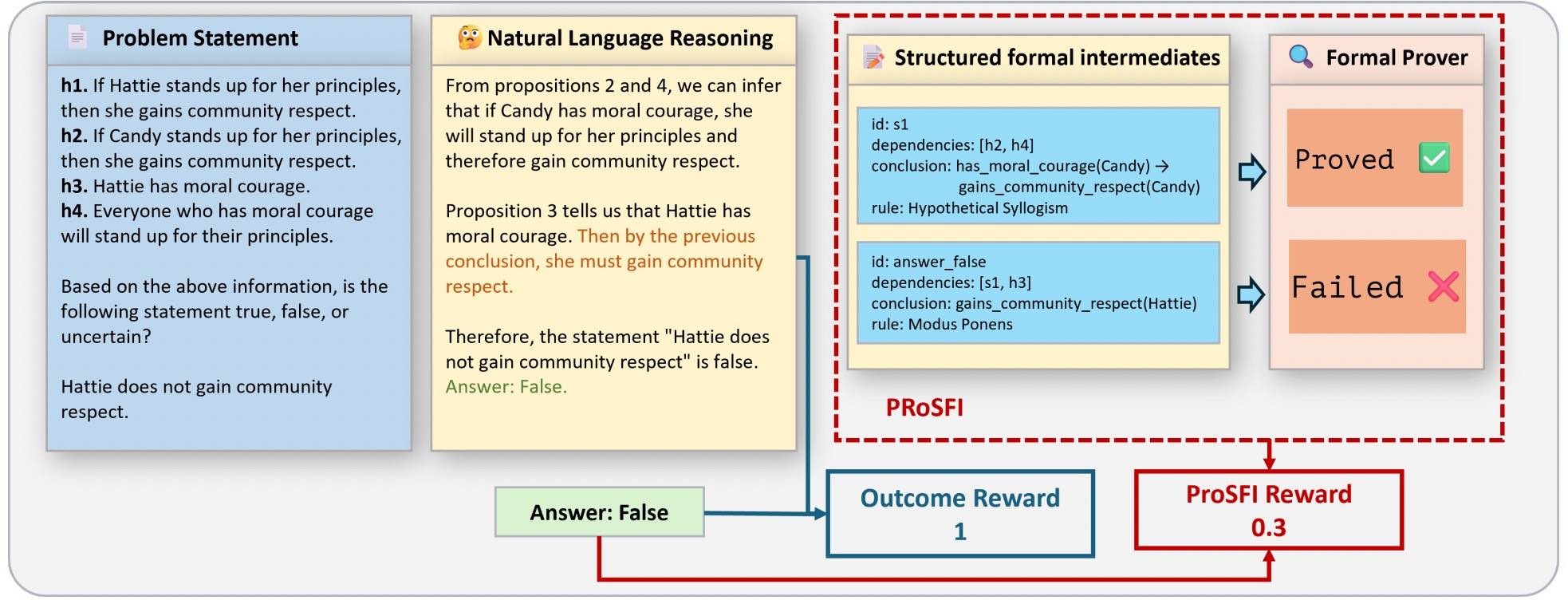
最直观的做法是结构化过程。2603 Learning to Generate Formally Verifiable Step-by-Step Logic Reasoning via Structured Formal Intermediaries[3] 针对的是中等规模模型直接生成极难形式化证明的成功率低下的问题。具体做法就是让模型首先输出与自然语言对应的结构化形式化中间表示,用于刻画逻辑依赖关系、推导出的结论,以及对形式推理规则(如假言三段论)的应用。随后利用形式化工具对这些中间步骤进行严格检验,构建出一条只有推理链条完全正确的解答才能获得奖励的强化闭环。
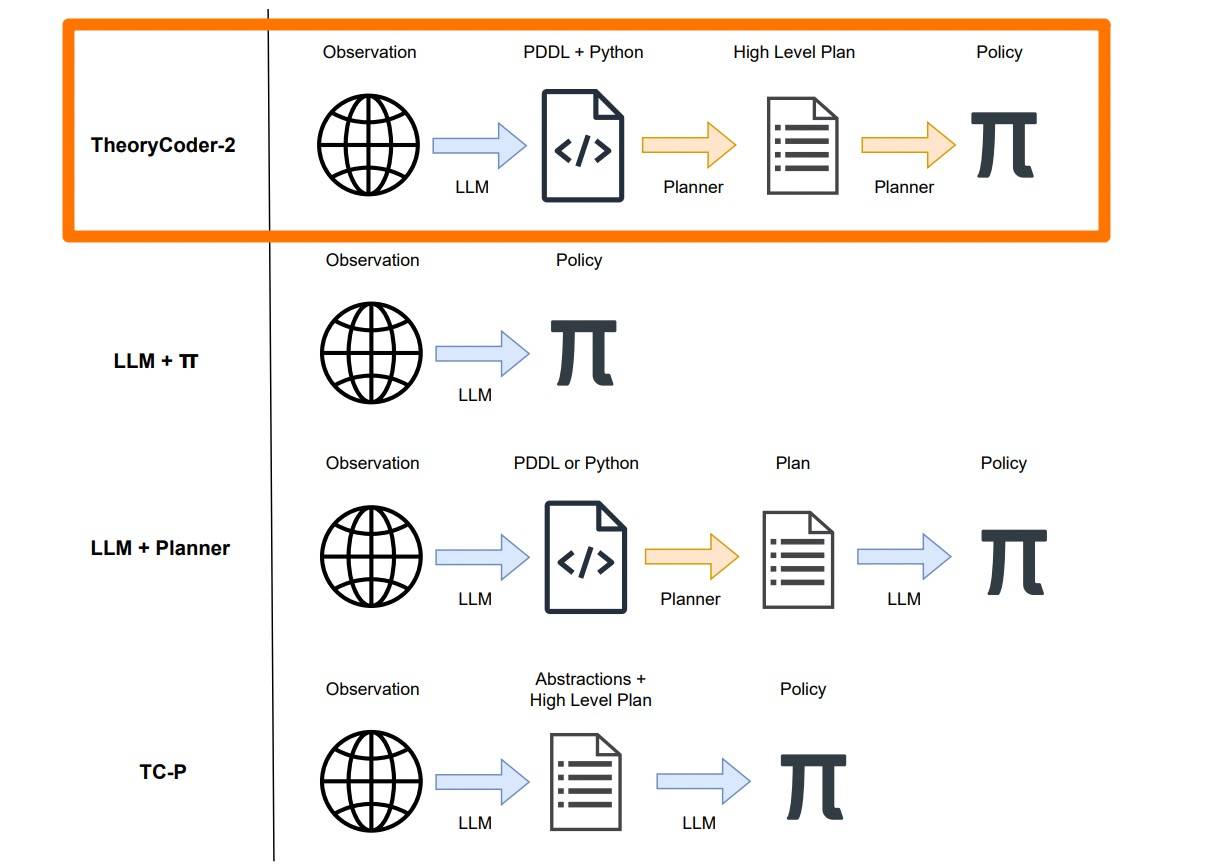
2602 Learning Abstractions for Hierarchical Planning in Program-Synthesis Agents[4] 的做法要更进一步,它利用 LLM 的上下文学习能力,通过从经验中合成抽象概念并将其整合到分层规划过程中,主动学习可重用的抽象概念,而不是依赖于人工指定的抽象概念。虽然是个代码 agent,但这种从经验中先学习抽象概念,然后再进行分层规划的做法是通用的。
还可以从具体数据反推,比如 2503 Reasoning to Learn from Latent Thoughts[5],它将网络文本视为冗长人类思维过程的最终压缩结果,认为可以通过推断和解压缩的思想来增强观察到的数据,实现更高效的学习——推理学习。这是显式地建模和推断文本生成过程中潜在的思维模式,其出发点来自人类学习——人类能够从相同的压缩文本中高效学习,比如,当我们阅读一篇研究论文时,我们会分析具体的主张,将其与先验知识相结合,并尝试“解压缩”作者的原始思维过程。
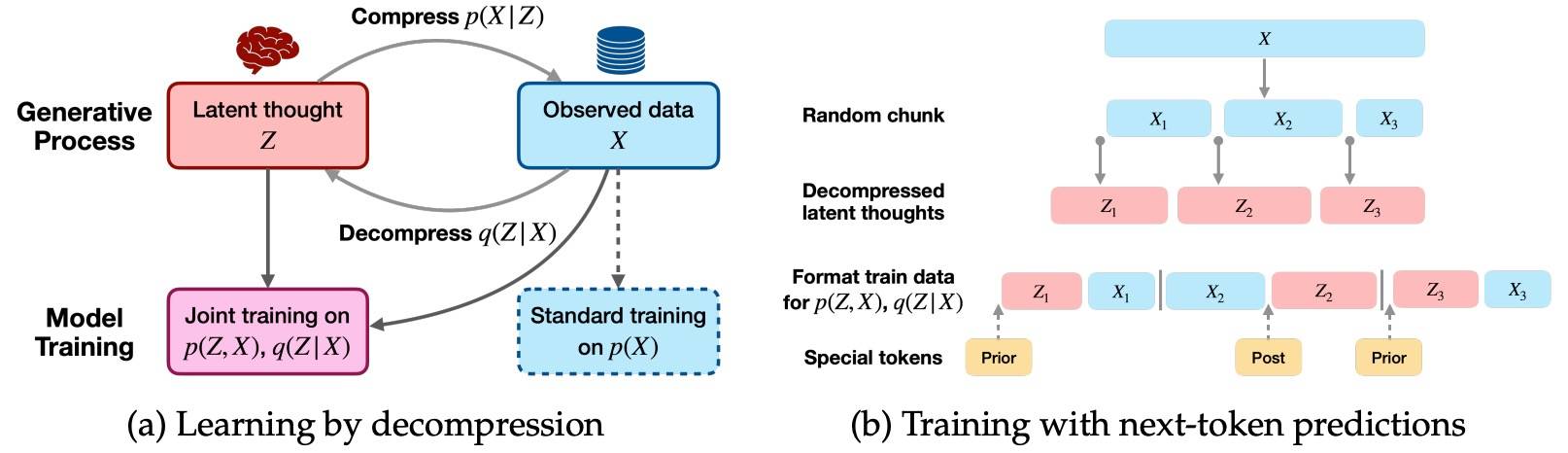
注意, Latent thought 依然以自回归的方式对每一段文本进行建模。
机制角度
首先看 2510 Self-Anchor: Large Language Model Reasoning via Step-by-step Attention Alignment[6],它的做法是显式地对齐大语言模型的注意力。这基于两个关键洞察:(1)复杂的推理问题可以分解为结构化的计划;(2)每个分解后的计划可自然地作为注意力对齐的组成部分。
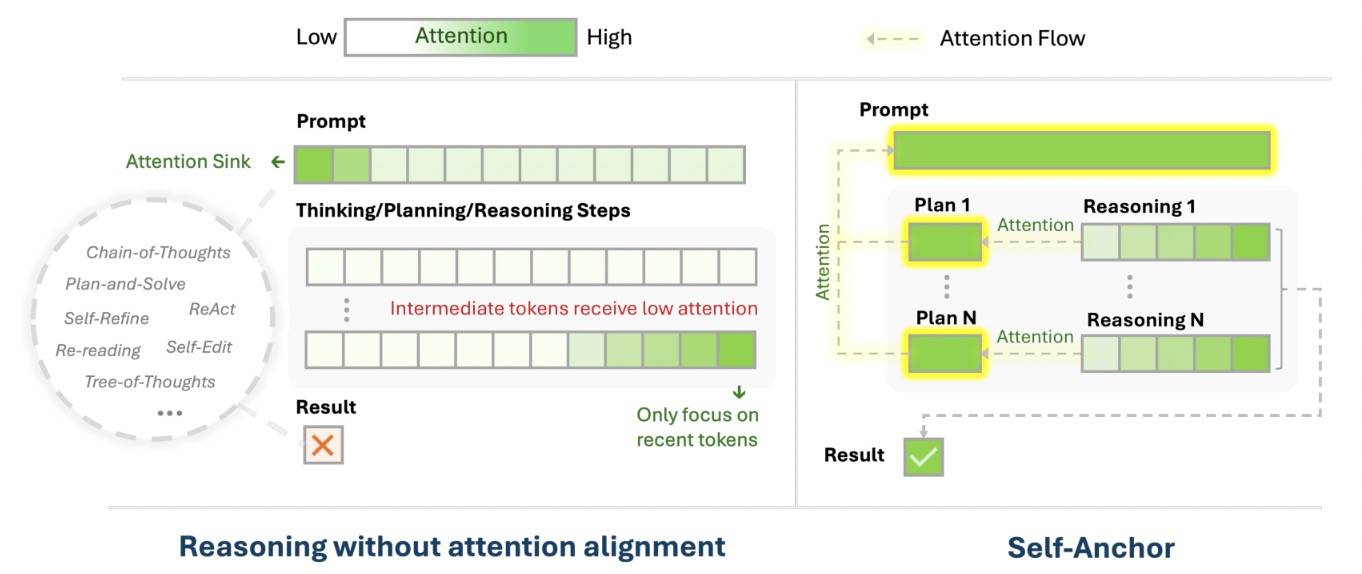
具体而言,Self-Anchor 将原始提示词分解为具有相应推理步骤的计划步骤。在生成过程中,它会自动选择并引导模型注意力聚焦于提示和相应的计划。这使得 LLM 能够持续关注问题声明和当前的推理目标,从而防止在不断扩展的推理步骤中出现注意力偏差。从形式上看,这个就是简单的规划,不过是从显式注意力角度出发的。
2510 Attention-Aligned Reasoning for Large Language Models[7] 也是类似思路,通过交替进行规划步骤和执行步骤,显式地引导注意力,在全局目标(原始问题)与局部目标(当前规划步骤)之间取得平衡。

比较有意思的是 2503 Effectively Controlling Reasoning Models through Thinking Intervention[8],它的做法有点像 CoT 的魔法语句:“Let’s think step by step”——策略性地插入或修改特定的思维 token 来显式地引导 LLM 的内部推理过程。
论文分析表明,推理过程的注意力主要集中在模型内部,而不是外部输入 token。因此,标准的提示工程效果有限,因为模型几乎不会将注意力指向这些提示。相比之下,在采用 Thinking Intervention 的注意力图中,可以观察到在推理过程中,模型对显式注入的干预 token 的内部注意力显著增强。
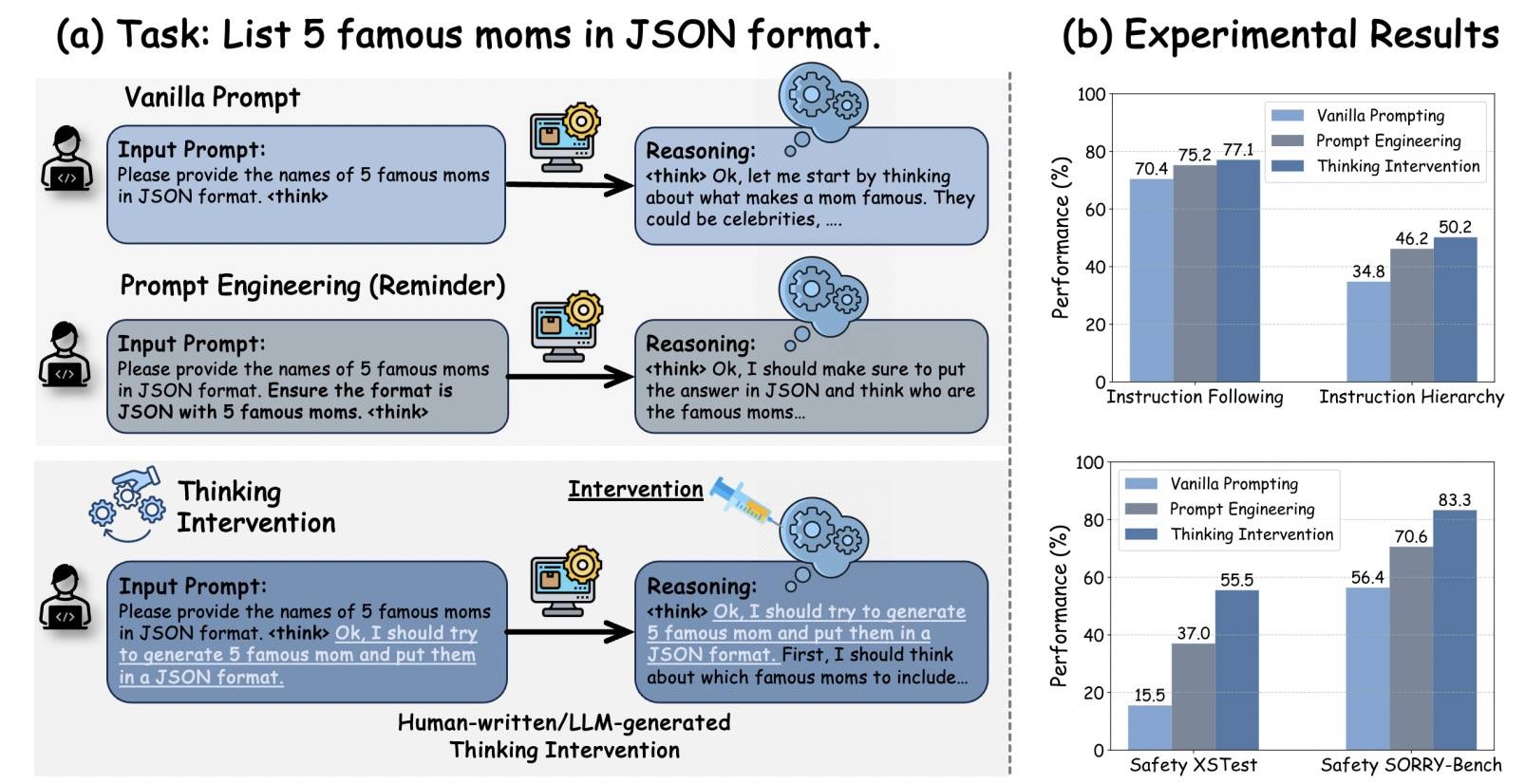
下面是一个展示如何将 Thinking Intervention 与 Vanilla Prompting 和 Reminder Prompting 等提示技术相结合的示例,可用于指令遵循任务。

还有一些相关的消融:
- 干预位置:相较于早期阶段的干预,在推理后期施加的干预效果明显减弱。
- 干预序列的复杂度:更长的干预序列显著提升了安全对齐效果,但由于指导过于严格,整体遵循率有所下降。
- 叙事视角:不同人称在性能上差异极小。
其实说到 steering,突然想到之前写过一篇《激活诱导LLM指令跟随 | 长琴[9]》——Activation 诱导的实验,感兴趣的读者可以查阅。近期的 2604 From Weights to Activations: Is Steering the Next Frontier of Adaptation?[10] 进一步将其定位为一种独特的自适应范式。
认知角度
前面的规划多少还是有点具体,缺乏一个抽象的设计。这里我们来看几个从认知角度设计(更高级)思考的做法。
首先是 2602 Think Fast and Slow: Step-Level Cognitive Depth Adaptation for LLM Agents[11],它基于 ACT-R 理论,设计了四个层级的认知结构,涵盖从本能反应到策略性规划的各个层面。具体包括:L1(本能反应)、L2(情境意识)、L3(经验整合)和L4(战略规划)。然后再训练智能体在每个步骤中动态调整认知深度,其核心思想是,合适的认知深度应最大化最终行动的置信度。
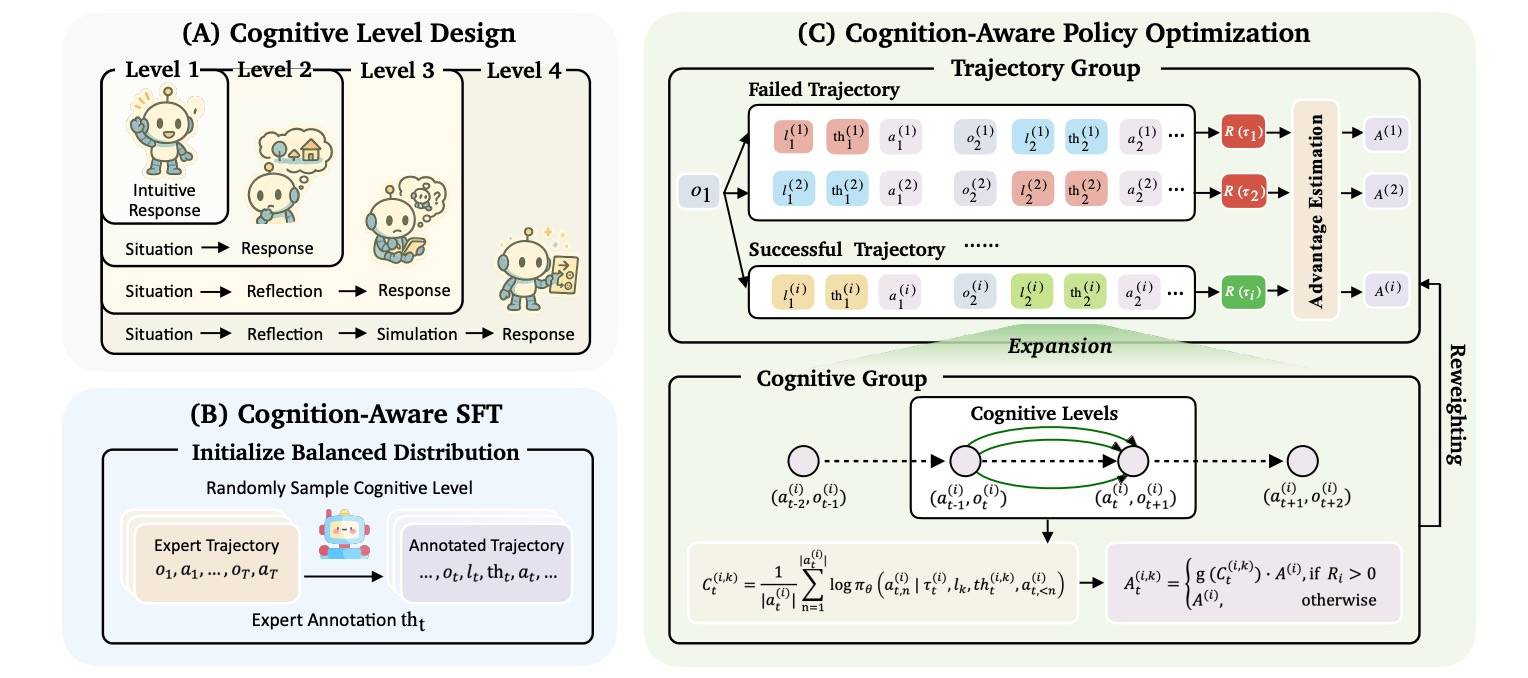
为此,还提出了两阶段训练方法,重新定义了 SFT 和 RL。
- 认知感知监督微调(CoSFT),用于构建稳定的特定层级认知模式。
- 认知感知策略优化(CoPO),用于通过置信度感知优势重加权来实现步骤级的权重分配。
2503 MetaScale: Test-Time Scaling with Evolving Meta-Thoughts[12] 的是模型如何主动选择最合适的认知策略来解决特定任务,而不是所有任务一个策略。提出meta-thinking:LLM 在生成回答之前,会首先反思其解决问题的方法,选择最合适的认知策略。
具体来说,先初始化一组候选元思维,然后采用多臂老虎机算法结合上置信界选择策略,在奖励模型的引导下,迭代地选择并评估这些候选元思维。为了进一步提升适应性,采用遗传算法对高奖励的元思维进行进化,不断优化并扩展策略池。
UCB:Upper Confidence Bound,其中心思想是,不断地调整你对每个 action 的 confidence。如果你对一个 action 的长远价值越不确定,你就应该更多地尝试这个 action;如果你对其价值已很确定,就不需再浪费时间试验这个 action。
感兴趣的读者可以阅读:“心有麟熙”《强化学习炼金术》系列笔记 | Yam[13]
整个方案如下图所示:
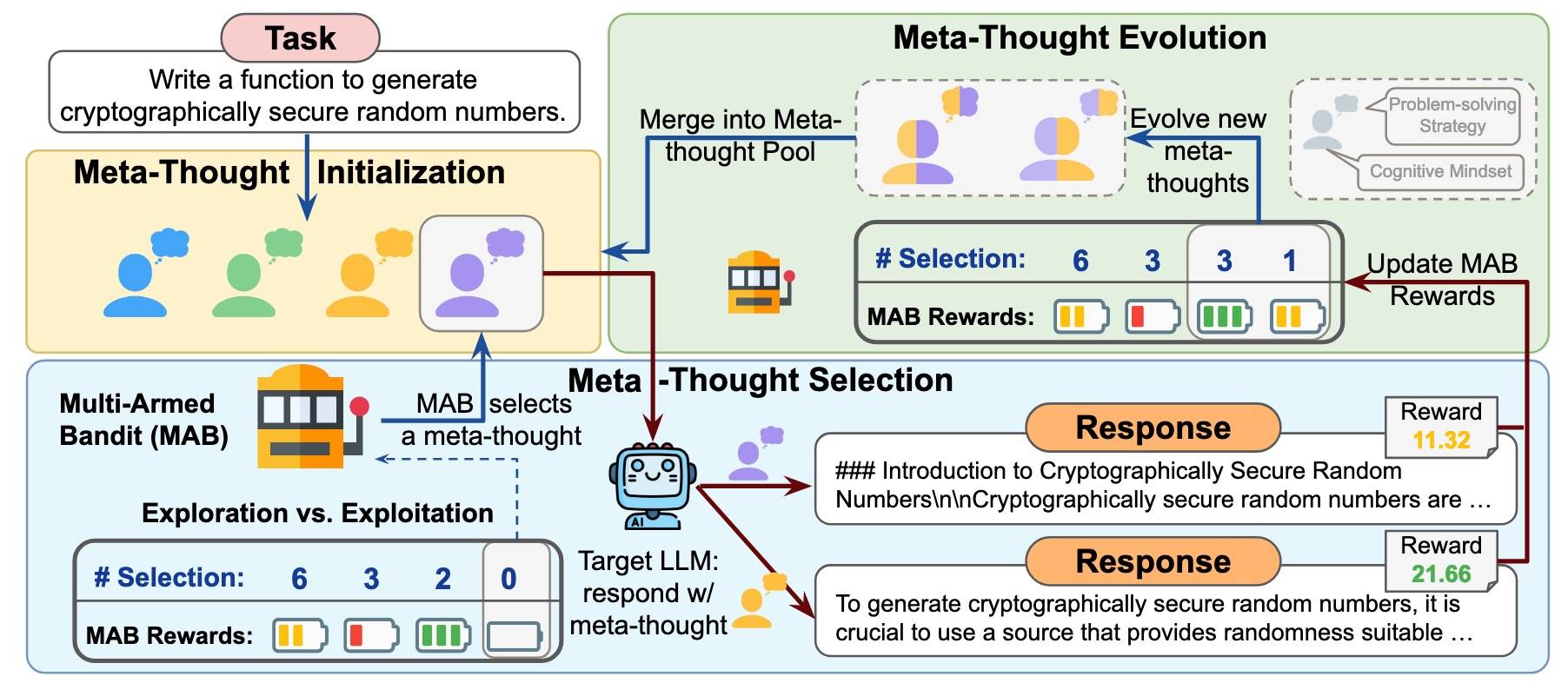
受人类认知过程启发,一个元思维包含两个元素:
- 认知心态:模型为完成任务而采用的适当视角、专业知识或角色。
- 问题解决策略:在既定心态下,模型用来构建合理解决方案的结构化模式。
MetaScale 通过三个阶段为输入任务构建有效的元思维:
- 初始化:为输入任务生成多样化的推理策略池。包括:
- LLM 被提示自我构建的策略,反映出不同的问题解决启发式方法和认知模式。
- 从外部数据集(由高级模型生成的大量任务-解决方案对数据集)中找到与当前任务相似的任务,从中提取的可用于当前问题的思维模式构成的衍生策略。
- 选择:每次迭代步骤中选择最有前景的元思维来生成回答。
- 将推理时元思维的选择形式化为一个多臂老虎机问题,其中每个元思维选项充当一个“臂”,目标是基于所选元思维最大化相应模型回答的奖励。
- 使用 UCB 引导选择过程,平衡探索和利用。
- 进化:定期应用遗传算法来进化元思维。
- 通过累计的 UCB 识别出的高性能元思维被选为父代,以生成下一代新的子元思维。
- 与典型遗传算法的交叉或变异策略不同(在这个场景下可能会产生没意义的策略),本文提示目标LLM自行决定如何结合父代元思维的推理启发式,并将其进化为改进后的版本。这种方法更加灵活和对上下文敏感。
最终,在开闭源模型上,相比 CoT、Best-of-N 都有一定提升,分析发现:
- 增加采样预算可以进一步受益。
- 进化增强了最佳元思想的选择。
- 可以生成有针对性的专家级解决方案。
总的来说,通过先确定思维策略再生成回复的推理时设计(无需训练),MetaScale 取得了不错的效果。
如果说 MetaScale 的策略是自底向上的,那 2503 ThinkPatterns-21k: A Systematic Study on the Impact of Thinking Patterns in LLMs[14] 就是直接分析不同思维模式如何影响不同规模模型的性能。
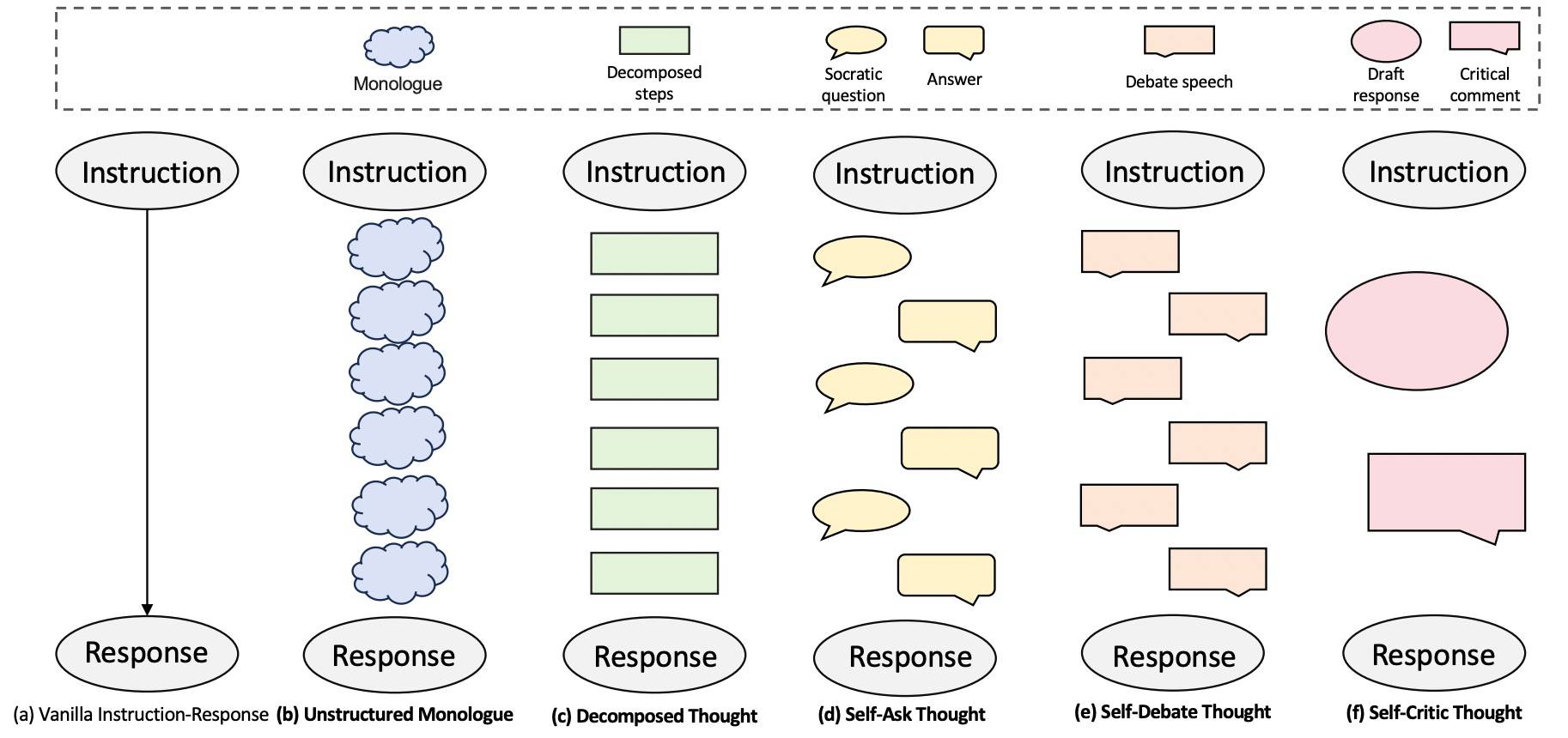
每种思维模式的特点如下:
| 思维模式 | 中文名称 | 类型 | 特点 |
|---|---|---|---|
| monologue | 独白 | 非结构化 | 模拟人类自然的内心独白,自由思考,不受限制。 |
| decomposition | 分解 | 结构化 | 分而治之,将问题分为问题理解、组件识别、子问题分析、关联映射、整合策略及答案验证。 |
| self-ask | 自我提问 | 结构化 | 受到苏格拉底式提问启发,根据用户指令从多个角度迭代生成子问题,并自行回答。 |
| self-debate | 自我辩论 | 结构化 | 在单一推理过程中通过采用对立观点来进行结构化的内部辩论。 |
| self-critic | 自我批判 | 结构化 | 先生成草稿答案,然后对其进行批判性评估并提供详细评论,最后生成优化后的输出。 |
论文有两个发现:
- 较小的模型(<30B参数)可以从大多数结构化思维模式中受益,而较大的模型(32B)在采用诸如分解等结构化思维方式时,性能反而会下降。严格的结构化推理过程似乎限制了模型的灵活性,导致在处理多样化指令时生成的回答不够理想。
- 非结构化的独白在不同规模的模型上表现出广泛的有效性。自我批判思维模式通过生成-评估的两阶段思维过程,在不同模型规模下展现出卓越的稳定性。
总的来说,思维模式在小模型下有一定效果,但模型变大后反而不行。这貌似也是可以理解的,如论文所言,思维模式在某种程度上其实是把模型”限制“在了一个路径上。另外注意,这里模型是要训练的。
重新思考规划
我们已经看到了如何规划(或者说思考),也知道这个过程其实本身也是在造数据——Reasoning 本身就是好数据——这是 R1 给我们的启示。那接下来自然而然的一个更本质的问题就是 “什么是规划”?
前面介绍的所有方案其实都是离散 token 的显式思考构造,思考或规划能否有不一样的形态呢?答案是显而易见的,还记得我们在《DLM 漫谈:并行不是重点,模式才是 —— 从 ARM 到 DLM 的 LLM 第二曲线 | 长琴[15]》中的讨论吗,在文章结尾,我还“大(大)放(胆)厥(预)词(测)”——「个人反倒觉得 DLM Think 这个角度不错,尤其是 latent Think——看起来更加符合直觉,Token Think 看起来着实有点邪修,而且现在越来越邪……」
DLM 漫谈中介绍了不少 latent think 的文章,最近也有不少相关的文章,比如 2604 LatentUM: Unleashing the Potential of Interleaved Cross-Modal Reasoning via a Latent-Space Unified Model[16] 还把所有模态表示建模在一个共享的语义 latent 空间。再比如去年就有 2502 Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach[17],一种新型语言模型架构,能够通过在潜在空间中进行隐式推理来扩展测试时的计算能力。该模型通过迭代循环块(Recurrent Block)来实现,从而在测试时展开到任意深度。这与主流推理模型通过生成更多词元来扩展计算能力的做法截然不同。
好吧,自然来到了建模方式,AR、Diffusion、刚刚提到的 Recurrent Block,虽然我本人没有具体去调研,但可以肯定方法只会更多。不过主流方式应该还是前两种。前两种一定好吗?事实上肯定不是的,但没办法,它们生态最好,有很好的“基础”。其实 DLM 的起点也是 ARM 啊,从零开始着实是困难。从这个角度看,那确实“好”——毕竟站在了巨人肩膀上。
除了上面提到的,关于 latent think 比较有意思的研究也多了起来,比如 2604 Therefore I am. I Think[18] 发现,可检测的、早期编码的决策会塑造思维链在推理模型中的表现。文章证明了在任何推理 token 生成之前,工具调用决策可以从模型激活值中强烈预测。注入或抑制期望的决策方向会出现后续行为翻转。进一步分析发现,后续的思维链通常会对引导引起的决策翻转进行合理化,而非抵抗这些翻转,说明在这些情况下,思维链充当了事后的辩护。虽然看起来和前面提到的《激活诱导LLM指令跟随 | 长琴[9]》类似,但这里明显更加强调思考前状态对决策的影响,有种“我其实早就想好了只是没说出来而已”的感觉。
再比如类似的 2604 Latent Planning Emerges with Scale[19],将潜在规划定义为 LLM 拥有内部规划表征,这些表征既能够促使生成某个特定的未来 token 或概念(前向规划),还能对先前的上下文进行塑造,使其能够支持该未来 token 或概念的生成(逆向规划)。在研究了 Qwen-3 系列模型后,发现潜在规划能力随模型规模的增加而增强,4-8B 就已经展现出初步的规划机制,但即便是大模型,也很少进行长距离的前瞻规划。
好了,感觉差不多可以对“规划”来一个新的定义或认知了,综合所有已知信息,个人认为好的规划(或思考)应该至少具备以下几要素:
- 能引导生成方向。这是最根本的特质,不然规划本身就无从谈起。看起来显式 token 或 latent 好像都可。
- 可多次启动执行。生成过程中应该可以随时停下来进一步“规划”,而不必须是一开始就固定住的,总之想法应该是动态变化的。显式 token 在这点上有点不知道是原因还是结果,可以勉强说前面的 token 在“规划”后面的 token。
- 过程是非连续的。规划过程应该是跳跃的,类似人类思考一样,经常不是线性的,而是突然从某个想法跳到另一个。显式 token 在这点上同上,而且相对更加勉强一些,甚至不成立。这点似乎天然就是 Diffusion 的——未成型的、可多步调整、全局调整。
从这几点来看,《DLM 漫谈:并行不是重点,模式才是 —— 从 ARM 到 DLM 的 LLM 第二曲线 | 长琴[15]》中 Latent DLM Plan + ARM Generate 部分介绍的 STAR-LDM[20] 是相对最接近的,它的出发点是人类的写作方式:频繁停顿、反思、提前规划并反复修改文本,以确保整体连贯性、风格一致性以及对全局目标的遵循。这里有多个关键词,前面的很明显就不说了,后面还有个重点 “全局目标”。所以,从这些角度看确实比较 make sense。不过建模细节、数据构造等方面还有很多可以改善的地方,这里不再展开。
小结
本文主要探讨如何规划(思考),从简单的规划出发,到数据、机制和认知等各种不同角度的策略,这既是设计,也是数据——过程就是最好的数据,谁也不知道“高质量”数据的“高”还能有多高。最后尝试重新回归“规划”本质,思考何为规划,如何做好规划。一家之言,请读者多多指正。
Reference
[1] 2505 Learning to Plan Before Answering: Self-Teaching LLMs to Learn Abstract Plans for Problem Solving: https://arxiv.org/abs/2505.00031
[2] Self-Steering Language Models: https://arxiv.org/abs/2504.07081
[3] 2603 Learning to Generate Formally Verifiable Step-by-Step Logic Reasoning via Structured Formal Intermediaries: https://arxiv.org/abs/2603.29500
[4] 2602 Learning Abstractions for Hierarchical Planning in Program-Synthesis Agents: https://arxiv.org/abs/2602.00929
[5] 2503 Reasoning to Learn from Latent Thoughts: https://arxiv.org/abs/2503.18866
[6] 2510 Self-Anchor: Large Language Model Reasoning via Step-by-step Attention Alignment: https://arxiv.org/abs/2510.03223
[7] 2510 Attention-Aligned Reasoning for Large Language Models: https://arxiv.org/abs/2510.03223
[8] 2503 Effectively Controlling Reasoning Models through Thinking Intervention: https://arxiv.org/abs/2503.24370
[9] 激活诱导LLM指令跟随 | 长琴: https://yam.gift/2025/07/01/NLP/LLM-IF/2025-07-01-Activation-Steering/
[10] 2604 From Weights to Activations: Is Steering the Next Frontier of Adaptation?: https://arxiv.org/abs/2604.14090
[11] 2602 Think Fast and Slow: Step-Level Cognitive Depth Adaptation for LLM Agents: https://arxiv.org/abs/2602.12662
[12] 2503 MetaScale: Test-Time Scaling with Evolving Meta-Thoughts: https://arxiv.org/abs/2503.13447
[13] “心有麟熙”《强化学习炼金术》系列笔记 | Yam: https://yam.gift/2018/05/07/AI/2018-05-07-RL-Series/
[14] 2503 ThinkPatterns-21k: A Systematic Study on the Impact of Thinking Patterns in LLMs: https://arxiv.org/abs/2503.12918
[15] DLM 漫谈:并行不是重点,模式才是 —— 从 ARM 到 DLM 的 LLM 第二曲线 | 长琴: https://yam.gift/2026/03/01/NLP/LLM/2026-03-01-DLM/
[16] 2604 LatentUM: Unleashing the Potential of Interleaved Cross-Modal Reasoning via a Latent-Space Unified Model: https://arxiv.org/abs/2604.02097
[17] 2502 Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach: https://arxiv.org/abs/2502.05171
[18] 2604 Therefore I am. I Think: https://arxiv.org/abs/2604.01202
[19] 2604 Latent Planning Emerges with Scale: https://arxiv.org/abs/2604.12493
[20] STAR-LDM: https://arxiv.org/abs/2602.20528
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。