一直对 EmbodiedAI 比较关注,大概是从 2103 A Survey of Embodied AI: From Simulators to Research Tasks[1] 开始,主要是一直对机器人感兴趣,看了《超能陆战队》后就总想自己也搞一个,再加上自己也是搞 AI 算法,关注到这个方向其实是比较自然的。后面陆续出来 RT-2: Vision-Language-Action Models[2]、SayCan: Grounding Language in Robotic Affordances[3]、2303 PaLM-E: An Embodied Multimodal Language Model[4] 等研究(都是 Google 的),不过再往后就基本没怎么关注了。工作忙起来了,事情也多起来了。
不过事情来到 2026 年就不一样了,记得我在 2025 年底跨年夜晚上发了一条朋友圈:“2025是RL、多模态、AI Coding年。2026继续,再补一个Embodied AI”,没几个月过去已经开始应验,现在半年过去简直要暴走。我自认为自己在这个方向还是比较浅薄的,所以准备补一补,多读几篇相关论文,本文就从《2602 Beyond Imitation: Reinforcement Learning-Based Sim-Real Co-Training for VLA Models[5]》开始吧。
VLA 虽然发展很火,但迄今为止还是非常不成熟的,我把这个阶段称为“大混战”,8 成初创企业会死掉,剩下 2 成浴火涅槃。其中不成熟的一个重要表现就是“数据”——具身智能一般而言是要和真实社会交互的,可是真实世界采集数据麻烦啊,还很难重复、不可控,收集周期长、成本高。所以,常见的做法就是模拟环境弄数据,唯一的不足就是“不真实”,导致模型可能有偏差。那解决方法自然是 Sim-to-Real,本文就是讲这个的。
背景
大多数 Sim-Real 协同训练方法依赖 SFT,它们将仿真环境视为静态标注数据来源,但没能充分利用大规模闭环交互过程。所以,这些方法在真实世界中的性能提升和泛化能力往往受到限制。本文提出的协同训练框架能够利用交互式仿真训练,同时保持模型在真实世界中的能力。我们看看是怎么做的。
其实对于 Sim-to-Real 的 gap,早期主要用域随机化,近几年开始通过提升仿真环境的视觉逼真度和场景多样性来缓解。但这是有代价的,比如仍然需要对几何结构、材料属性、接触动力学、传感器感知等进行精确建模。既增加了系统的复杂性,也限制了其在不同任务之间的可扩展性。简单来说,Sim 要搞好也没那么简单。
所以,很自然地,就有人开始联合利用 sim 和 real 数据进行训练,也确实取得了不错的效果,但训练方法依然是 SFT 为主,sim 数据依然作为大头的静态标注数据。同时有研究发现,在行为克隆任务上,SFT 的 VLA 容易受到分布偏移影响,产生累积误差,这些误差会随着执行过程不断积累,最终影响模型鲁棒性。为了解决这个问题,近期一些工作开始上 RL,通过让 VLA 策略在与环境持续交互的过程中进行学习和优化,能比 SFT 有更好的任务完成率和泛化能力。但是一旦应用到真实世界机器人,通常也只能依赖基于领域随机化的零样本 sim-to-real 迁移,由于 gap 存在,性能会明显下降。
本文提出基于 RL 的 Sim-Real 协同训练框架,通过利用仿真环境中的交互式学习来提升模型能力,同时保持其在真实世界中的性能。重点是后面半句。具体做法简答来说就是两阶段:一阶段 Sim + Real 混合数据 SFT,已有的方法;二阶段 Sim RL,重点是引入一个基于真实世界标注数据的辅助监督损失作为 anchor。好吧,这思路其实就是 Anchor-GRPO。
方法
其实前面已经说完了,我们稍微看一点点细节吧。
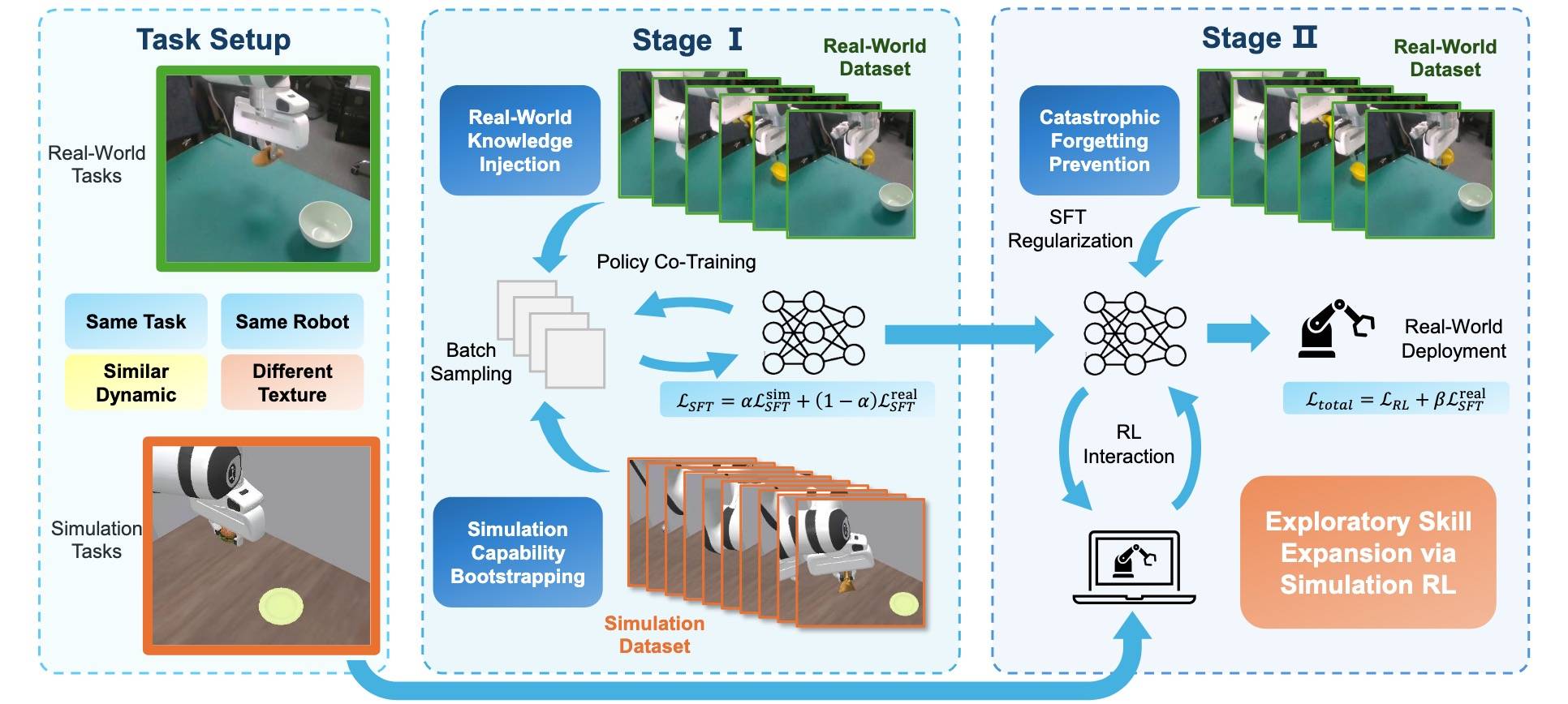
阶段1: SFT Co-Training for Policy Initialization
Loss 就是两个数据集的结合,重点看一下 Loss 具体怎么计算。
其中,
表示时间跨度为 的预测动作序列片段。
表示对应的专家动作序列。
是数据集, 是轨迹, 是对应的自然语言指令。
是第 条轨迹的长度, 是观测值, 是动作。一条轨迹是由一系列“观测-动作”对组成,表示智能体看到 后执行了动作 。
Unif 是均匀分布,表示时间步 是从集合中等概率随机采样得到的,就是说,在训练时,模型不会总是从轨迹的开头或结尾开始学习,而是随机选取轨迹中的任意一个时刻作为起点。
另外注意,这里是 Action Chunk 训练,意味着模型需要学会从任意中间时刻 开始,预测未来长度为 的动作序列。
Loss 取决于具体的 VLA 架构和动作表示方式。常见的选择包括:
- NTP
- 连续动作 L1 回归
- 扩散模型的去噪
阶段2: Sim-Real Co-Training with Real-Regularized RL
我们看图里,目标函数是两个,SFT 和 RL,我们重点看后者。RL 的目标:
表示奖励函数依赖于状态 和语言指令 。动作从 VLA 策略中采样,,状态转移遵循 。
- :表示以观测 和语言指令 为条件,由参数 定义的 VLA 策略所输出的动作分布。
- :表示环境的状态转移概率(或确定性转移函数),即在状态 执行动作 后,下一状态 的分布。
注意:原文中写的是 ,但严格来说是 ,不过很多时候大家都这么简写。
直观来看,RL 项使策略能够利用大规模仿真交互来探索多样化的行为并提升任务性能;而真实世界监督项则充当正则化器,将策略锚定在真实演示数据上,从而缓解 RL 微调过程中的灾难性遗忘问题。
消融
主要是两点:
- 第一阶段中的仿真数据如何影响 RL 优化;
- 真实世界 SFT 在第一阶段和第二阶段中分别扮演何种角色。
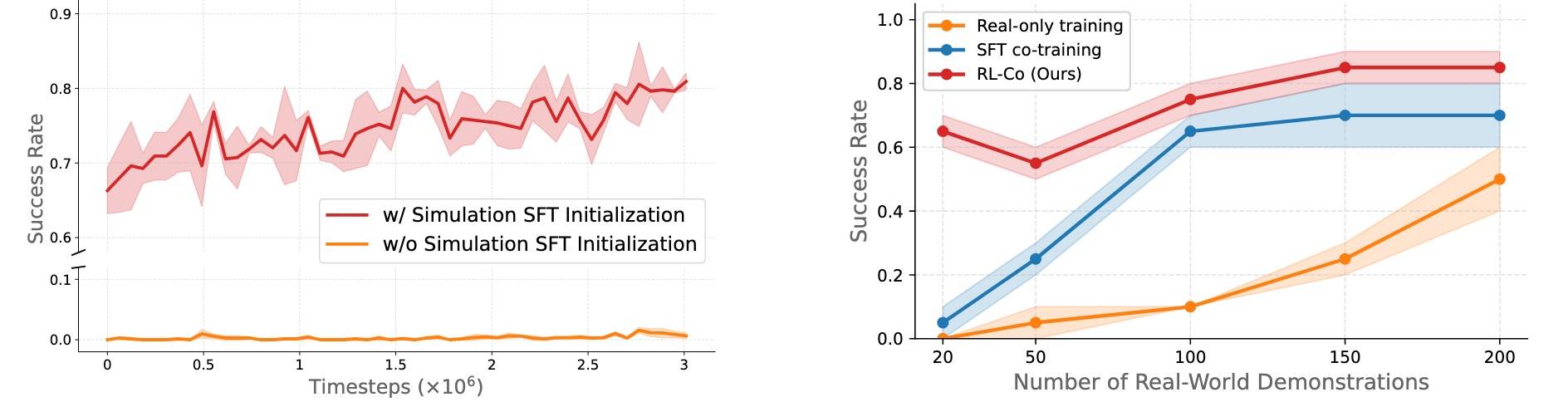
第一点看左图,第一阶段的 sim 数据必不可少,没了直接不干活儿了。右图是数据效率,你会发现其实并不需要那么多 real 数据,协同框架的数据效率最高,协同 20 条等价于 SFT 100条。
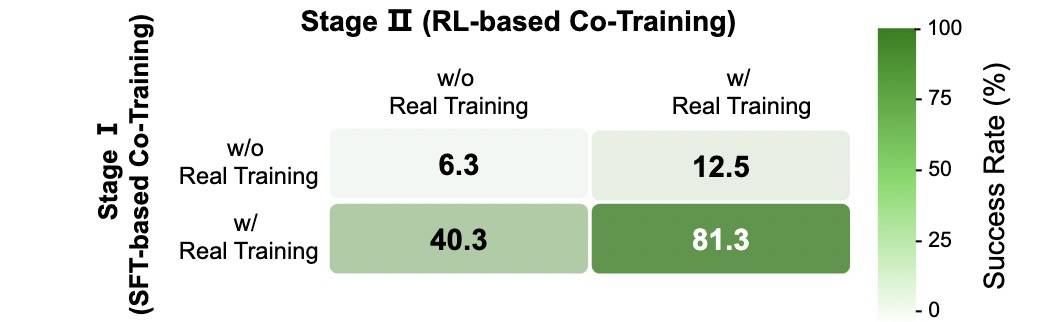
第二点看此图,第二阶段移除了 real SFT 正则化项后,成功率直接从 81.3% 降到 40.3%;同样,第一阶段移除 real SFT 后,最终性能只有 12.5%。说明与 RL 相比,SFT 在利用有限的 real 数据方面具有显著更高的数据效率(40.3 vs 12.5)。
小结
看完再回头想想,这个看起来好像就是训练上稍微做了一个小的调整(混合真实数据),哈,事实上论文正是在说他们自己的框架:RLinf[6],官方介绍是这样子的:
RLinf 提供了一整套可复现的 SOTA 强化学习配置,用户无需额外工程改造,只需直接运行官方脚本和配置文件,即可复现论文级或业界领先的训练效果。
在具身智能任务上,RLinf 在 LIBERO、ManiSkill、RoboTwin 等多个基准中达到了或接近当前最优的成功率。在智能体任务(包含数学推理)上,RLinf 基于 DeepSeek-R1-Distill-Qwen 系列模型,在 AIME24 / AIME25 / GPQA-diamond 等基准上达到 SOTA 表现。
感觉好像不需要专门写,不过已经整理完了,就这样吧,下篇再见。
噢对了,有同学可能好奇,VLA 为啥把 Language 扯进来,这关键是目前 LLM 依然是智商高地,说的图像推理其实本质上还是 Language 推理。距离真正的图像推理还有距离——其实图像推理的说法也不对,准确来说应该是视觉推理。这是和 LLM 推理不同的路线,但其实两者也不冲突,也许推理本身是模态无关的——模态只是输入信号罢了。
Reference
[1] 2103 A Survey of Embodied AI: From Simulators to Research Tasks: https://arxiv.org/abs/2103.04918
[2] RT-2: Vision-Language-Action Models: https://robotics-transformer2.github.io/
[3] SayCan: Grounding Language in Robotic Affordances: https://say-can.github.io./
[4] 2303 PaLM-E: An Embodied Multimodal Language Model: https://arxiv.org/abs/2303.03378
[5] 2602 Beyond Imitation: Reinforcement Learning-Based Sim-Real Co-Training for VLA Models: https://arxiv.org/abs/2602.12628
[6] RLinf: https://rlinf.readthedocs.io/zh-cn/latest/rst_source/start/index.html