TL;DR
Reinforce++ 通过移除 critic 并在整个 batch 上全局归一化 advantage,解决了 GRPO 对特定 prompt 过拟合和奖励 hacking 的问题。同时也揭示了一个隐藏细节:GRPO 广泛使用的 k3 KL 惩罚项虽保证非负,却引入偏差和不对称梯度;而 Reinforce++ 改用无偏的 k2形式,提升了训练稳定性。
本文介绍Reinforce++[1]算法,基于 Reinforce 的算法包括RLOO(REINFORCE Leave One-Out)、ReMax、GRPO等,这些方法独立估计对每个输入响应的 advantage,可能导致对更简单的提示过度拟合,并容易受到奖励 hacking,并且可能存在偏差。Reinforce++ 移除了 critic 模型,使用无偏的全局advantage归一化来提高训练稳定性。相关代码参见 GitHub[2]。
Reinforce
Reinforce是一种经典的策略梯度算法,它用采样的回报来估计策略参数的梯度,然后直接更新策略,如下:
J(θ)=Eτ∼πθ[R(τ)](1)
τ 是完整的轨迹,R 是轨迹的总回报。
可以利用似然比技巧(对数求导技巧,我们在这里[3]推导时也见到过),将梯度形式改写成可以采样估计的形式:
∇θJ(θ)=Eπθ[∇θlogπθ(a∣s)⋅R](2)
推导过程如下。先把损失写成积分形式:
J(θ)=∫R(τ)pθ(τ)dτ(3)
然后求导:
∇θJ(θ)=∫R(τ)∇θpθ(τ)dτ(4)
由于 R 不依赖 θ,因此梯度完全由 p 决定。
使用对数求导技巧:
pθ(x)∇θpθ(x)=∇θlogpθ(x)(5)
得到:
∇θJ(θ)=∫R(τ)pθ(τ)∇θpθ(τ)pθ(τ)dτ=Eτ∼pθ[∇θlogpθ(τ)⋅R(τ)](6)
这个就是式(2)。
注意,这里虽然 R 自身不依赖 θ,但 R 的期望值依赖于 θ,因为期望是对策略采样出来的轨迹分布取的。简单来说就是,我们不能改奖励公式,但可以改“抽到好奖励的概率”,即 R 不变,但抽到哪条轨迹的概率可以变。
从Reinforce到++
先看 PPO,它用 GAE 估计 advantage,我们在这里[4]介绍过,不再赘述。GAE 的核心是结合一系列时间步上的时序差分误差,获得对 advantage 的平滑估计。Critic(value model)学习的是一个价值函数,用于评估当前状态的“好坏”或“潜在回报”。主要用来更加精准地估计 advantage,并具备对未见过 token 的泛化性。
ReMax 方法在每个 prompt 上用贪心搜索生成一个回答,然后把这个回答的奖励当作 baseline。但是这个“贪心回答”本身其实只是为了计算 baseline,用掉了一次模型生成机会,却不能直接用于训练优化,因此效率很低。
RLOO 和 GRPO 对同一个 prompt 生成多个回答。RLOO 取“其他回答的平均奖励”作为 baseline,GRPO 是把所有回答的奖励进行归一化,然后把这个归一化的结果作为 advantage,不过这种估计是有偏的,因为它并不是完全等价于真实的 advantage,只是一种简化近似。GRPO 我们已经相当熟悉了,就不多说了,RLOO 可以参考这里[5]的推导。
Reinforce++ 认为多个响应的做法加剧了奖励 hacking 的风险,而且它们分别计算每个 prompt 的 baseline,可能导致对特定 prompt 过度拟合,以及训练不稳定。它的做法是从 PPO 中移除 critic,并使用了全局优势归一化。如下图所示。这种方法是无偏的,可防止特定 prompt 过拟合,并在 Bradley-Terry 和基于规则的奖励模型中表现稳健。另外,还消除了 prompt 截断的需要,并在 RLHF 和长 CoT RL 中具备强大泛化能力。
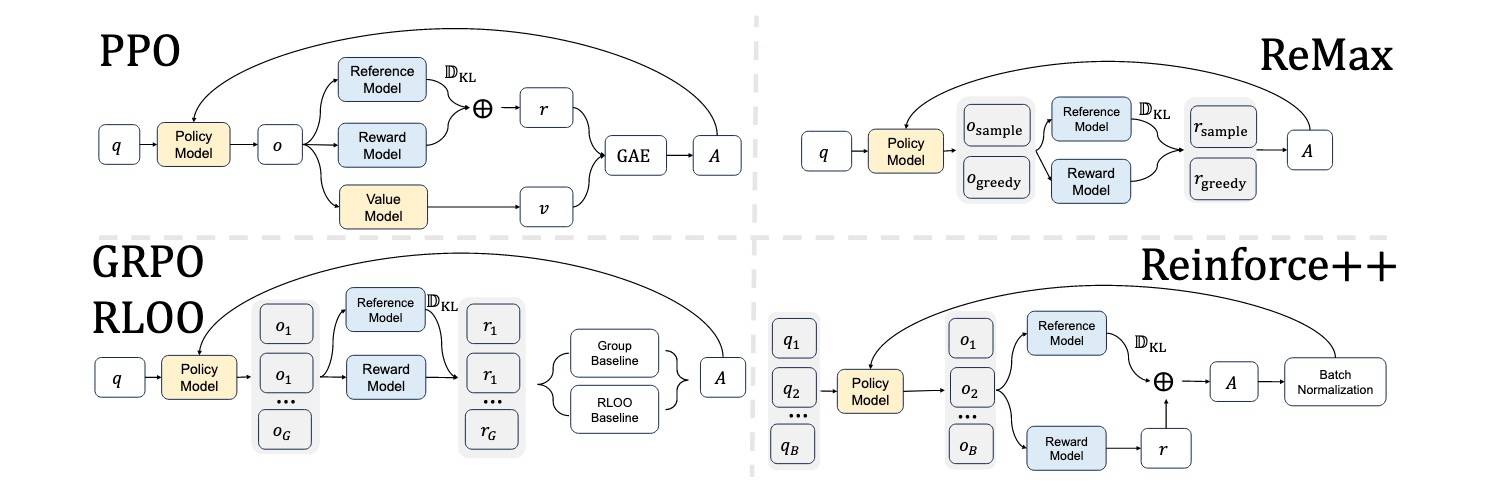
(图片来自原论文)
关于奖励 hacking 和过拟合问题,具体来说:
- 一个 batch 内针对同一个 prompt 优化多个回答时,往往会对某些简单 prompt 下的最优回答产生过拟合(简单问题回复也简单,容易采样到重复回复)。而且还会降低模型输出的多样性,导致 token 级别的 advantage 分布变得单一,从而进一步在这些 token 上过拟合。相比之下,PPO 就好很多,critic 会在 token 级别形成更具泛化性的 advantage 估计。
- 由于奖励来自奖励模型会规则奖励函数,模型就容易“投机取巧”。相比之下,传统 RL 的奖励来自真实环境会更好一些。
为了避免对特定 prompt 的过拟合并提升一个训练 batch 内的 prompt 多样性,Reinforce++ 在每个 prompt 上仅采样一个回答,并在整个 batch 维度上对 token 级 advantage 进行归一化,以增强训练的稳定性。
现在我们已经对 Reinforce++ 有了一个基本的认识了,在展开具体细节之前,先来看看 GRPO 的 advantage 估计。
Advantage有偏的GRPO
还记得我们在 GRPO“又一背锅侠”:Clip的各种拉扯 | Yam[6] 中证明过,GRPO advantage 期望为 0,具体来说,在 G 个 rollout 下归一化advantage 的总和期望为 0,这是确定性的代数恒等式。即 E[∑Â]=0,我们这里要讨论的是 E[ | τᵢ] 的有偏性。其实从直观上来看是容易理解的,因为我们在标准化某一个奖励的时候其实用了包含自身的统计量(均值和标准差)。
具体来说,就是要证明:
E[Ai∣ϵi]=ϵi(7)
其中,A 是优势的估计值,ε 则是真实值。换句话说,它其实是在用真实值估计自己,结果期望还不是真实值。证明过程可以参考原文,这里补充几个细节。
ε 服从 N(0, σ²) ,
ϵi−ϵˉ=(1−N1)ϵi−N1j=i∑ϵj(8)
于是有,
E[ϵi−ϵˉ∣ϵi]=E[(1−N1)ϵi−N1j=i∑ϵj∣ϵi]=(1−N1)ϵi−N1E[j=i∑ϵj∣ϵi]=(1−N1)ϵi(9)
εⱼ 和 εᵢ 独立,εⱼ均值为0,因此 E[εⱼ] = 0。
另外已知,
ϵˉ=N1j=1∑Nϵj,D=N1j=1∑N(ϵj−ϵˉ)2,(10)
则,
D2=N1j=1∑N(ϵj−ϵˉ)2=N1j=1∑N(ϵj2−2⋅ϵjϵjˉ+ϵˉ2)=N1(j=1∑Nϵj2−2ϵjˉj=1∑Nϵj+j=1∑Nϵjˉ2)=N1(j=1∑Nϵj2−j=1∑Nϵjˉ2)=N1j=1∑Nϵj2−ϵjˉ2(11)
这个恒等式把“偏差平方和”转换成了“平方和减去均值平方”,在计算期望时非常有用,它其实来自方差的定义,
Var(X)=E[(X−E[X])2](12)
根据式(11)有,
D2=E[ϵj2]−(E[ϵj])2(13)
于是有,
E[j=1∑Nϵj2∣ϵi]=E(ϵi2+j=i∑Nϵj2∣ϵi)=ϵi2+Ej=i∑Nϵj2∣ϵi=ϵi2+j=i∑NE[ϵj2∣ϵi]=ϵi2+j=i∑N(D2+E[ϵj]2)=ϵi2+j=i∑ND2=ϵi2+(N−1)σ2(14)
对于 j ≠ i,εⱼ 仍然服从正态分布 N(0, σ²)。
虽然 Advantage 是有偏的,不过,对 GRPO 来说这并不重要,它在乎的是”相对更好“而不是”绝对正确“。只要能提供有效梯度,即使有偏,也相对最优。
Reinforce++
我们继续。Reinforce++ 的优化目标依然是 PPO 的目标,
LPPO(θ)=Eq∼P(Q),o∼πθold(O∣q)∣o∣1t=1∑∣o∣min(st(θ)At,clip(st(θ),1−ϵ,1+ϵ)At)(15)
Advantage 如下:
Aq,ot=r(o1:T,q)−β⋅i=t∑TKL(i)(16)
其中,
KL(t)=log(πSFT(ot∣q,o<t)πθoldRL(ot∣q,o<t))(17)
我仔细看了下,这个 advantage GRPO 原始论文[7] 中也提到过,是来自 InstructGPT的论文[8],可真够远的。
Reinforce++ 算法采用基于 KL 的 k1 损失。这种选择的动机是,GRPO 算法依赖于基于 KL 的 k3 损失,
DKL[πθ∥πref]=πθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−logπθ(oi,t∣q,oi,<t)πref(oi,t∣q,oi,<t)−1(18)
如上,公式(18)也是来自 GRPO 原始论文[7]。关于 KL 的估计可以阅读:Approximating KL Divergence[9]。
虽然 k3 无偏,但其梯度估计依然存在偏差。
考虑 KL 估计器,
Lk2=Es∼D,a∼πθold (⋅∣s)−(21(logx)2)Lk3=Es∼D,a∼πθold (⋅∣s)−((x−1)−logx) where x=πθold (at∣st)πref (at∣st)(19)
梯度如下,
k2:logx⋅∇θlogπθk3:(x−1)⋅∇θlogπθ(20)
x 取对数写成减法形式可以得到 k2 的梯度,k3 的梯度利用了式(5),
∇θx=x⋅∇θlogx∇θlogx=−∇θlogπθ(21)
于是有,
∇Lk3=x(−∇θlogπθ)+∇θlogπθ=(x−1)⋅∇θlogπθ(22)
根据式(6),当将对数形式的 KL 项直接加入奖励 r 中时,其所得梯度与 k2 的梯度是等价的,因此,k2 的估计是无偏的。在 x≈1处泰勒展开,logx≈x−1,k3 的梯度就成为 k2 梯度的线性近似。这种近似有两个缺陷:
- 偏差。当当前策略与参考策略差距较大时(尤其是训练后期),近似误差会非线性增大。
- 不对称性。表达式 x-1 在
π_old>π_ref 与 π_old<π_ref 的情形下具有不对称的响应特性。
因此,虽然 k3 计算更简单,但它会引入偏差和更高的方差,因此并不严格优于理论上无偏的 k2 估计。实验结果表明,在 GRPO 中使用 k3 估计相比 k2 估计,会导致更大的方差波动。
为什么GRPO用k3?
既然如此,为什么 GRPO 还是用了 k3 呢?注意,这里说的 GRPO 用 k3 指的是 Loss 部分的 KL 惩罚项。
正好前几天刚好看到这个知乎回答:k3估计的KL散度那么不好,为什么GRPO还要坚持用呢?[10]大概意思是因为 k3 的非负性保证,这一点在 GRPO 原始论文[7] 也有提到。为什么非负性很重要,知乎答案分析后认为,如果 KL 为负,上面的损失函数取负数(训练时要最大化期望,即损失最小)后 KL 这一项本身就很小了,这会导致模型“偷懒”掉到 KL 里面,而不去优化前面真正的目标。结果就是训练极不稳定,所以非负保证可以避免这种偷懒。
但是,我们刚刚已经证明了 k3 是有偏的,所以,该知乎作者又发了一篇文章:k2 loss就是比k3 loss好,以及grpo off-policy、clip_std()[11]。如你所想,k2 被顶了出来。好吧,既然 k2 这么好,为啥 Reinforce++ 在 advantage 中用的是 k1 呢?这篇文章(3.3.2)认为,k2 和 k3 的恒正特性,导致无论 πθ(at|st) 与 πref(at|st) 的概率分布关系如何,根据式(16),
−∇θKL(πθ∥πref)=−Ex∼D,y∼πθold(⋅∣x)kl∇θlogπθ(at∣st)(23)
上面的梯度恒小于0,梯度更新方向会降低当前策略生成任意动作的概率,这种单向惩罚机制容易导致模型崩溃。
这篇文章的分析很精彩,相关英文版见:Rethinking KL Regularization in RLHF: From Value Estimation to Gradient Optimization[12],非常值得一度。
继续Reinforce++
好了,我们继续说回 Reinforce++,计算完 advantage 后,在全局 batch 中归一化所有 prompt:
Aq,otnorm=std(Aq,ot∣Aq,ot∈Dbatch)Aq,ot−mean(Aq,ot∣Aq,ot∈Dbatch)(24)
这有助于避免因 advantage 过大而导致的训练不稳定。由于 batch 一般很大(起码远大于 Group),可以将均值和方差视为常数,不会在策略梯度估计中引入偏差(论文发现,当 N → ∞ 时,估计量的分母收敛到常数 σ,分子中的偏差消失),这也是本文算法采用全局 batch 归一化的基础。
此外,还有一个加了 Group(单输入多个响应)的变体:Reinforce++ Baseline,
Aq,ot=Rq,ot−meangroup (Rq,ot)Aq,otnorm =stdbatch (Aq,ot)Aq,ot−meanbatch (Aq,ot)(25)
其实就是改变了 A 的计算方式(与式子16对比)。另外,KL 损失使用了 k2,而不是 k3,具体分析可以参考上一部分。
与PPO的关系
如果 PPO 使用 GAE (λ = 1, γ = 1),Reinforce++ 变成没有 critic 的 PPO,并额外采用全局 batch 归一化。
GAE 部分其实和之前 StepFun 的 ORZ[13] 的发现是一样的,他们也认为 GAE 参数在 PPO 的推理任务中起着关键作用,λ=1.0、γ=1.0 最理想。这两个参数意味着完全依赖最终回报计算优势(γ=1表示未来所有的奖励都被同等对待,不衰减;λ=1表示完全依赖未来真实奖励来估计优势值),适用于环境较稳定、奖励延迟较长的任务。更多分析可参考 R1相关:RL数据选择与Scaling | Yam[14]。
实践指南
论文后面给出了最佳实践,可以根据不同任务选择不同算法:
- REINFORCE++ Baseline 在样本过滤或更复杂的场景中(如 multi-turn tool-calling)尤其有效。
- REINFORCE++ 更适合难以在相同中间状态下获取多个不同响应的奖励信号的任务(如使用 PRM 训练)。
- REINFORCE++ Baseline 同时支持 0/1 和 -1/1 奖励方案,而 REINFORCE++ 在对称奖励下表现最佳。
小结
本文详细介绍了 Reinforce++,还简单分析了 KL 的几种不同估计方式对训练的影响,真的第 N 次忍不住感慨,细节好多啊!Reinforce++ 从奖励 hacking 和过拟合问题出发,在每个 prompt 上仅采样一个回答,并在整个 batch 维度上对 token 级 advantage 进行归一化。再就是在 reward 中使用 k1,损失函数中则使用 k2(Reinforce++ Baseline)。其实看实验结果,没有感觉到很大提升,不过它本来也是关注在稳定性上,尤其是 OOD 环境。
本文是 GRPO 系列的第8篇,更多可阅读 GRPO系列。
References
[1] Reinforce++: https://arxiv.org/abs/2501.03262
[2] GitHub: https://github.com/OpenRLHF/OpenRLHF/blob/db49b3285282429c5d16c8ffb5f56b196b0bc4f6/openrlhf/trainer/ppo_utils/experience_maker.py#L719
[3] 这里: https://yam.gift/2025/08/14/NLP/LLM-Training/2025-08-14-Token-Level-GSPO-GMPO/
[4] 这里: https://yam.gift/2025/02/27/NLP/LLM-Training/2025-02-27-LLM-PostTrain-PPO-Data/
[5] 这里: https://yam.gift/2025/07/25/NLP/LLM-Training/2025-07-25-GiGPO/
[6] GRPO“又一背锅侠”:Clip的各种拉扯 | Yam: https://yam.gift/2025/09/12/NLP/LLM-Training/2025-09-12-GRPO-Clip/
[7] GRPO 原始论文: https://arxiv.org/abs/2402.03300
[8] InstructGPT的论文: http://arxiv.org/abs/2203.02155
[9] Approximating KL Divergence: http://joschu.net/blog/kl-approx.html
[10] k3估计的KL散度那么不好,为什么GRPO还要坚持用呢?: https://zhuanlan.zhihu.com/p/25862547100
[11] k2 loss就是比k3 loss好,以及grpo off-policy、clip_std(): https://zhuanlan.zhihu.com/p/1892008158626546312
[12] Rethinking KL Regularization in RLHF: From Value Estimation to Gradient Optimization: https://www.notion.so/Rethinking-KL-Regularization-in-RLHF-From-Value-Estimation-to-Gradient-Optimization-1c18637cdeb3800ab47cd01d3fa33ea5
[13] ORZ: https://github.com/Open-Reasoner-Zero/Open-Reasoner-Zero/tree/main
[14] R1相关:RL数据选择与Scaling | Yam: https://yam.gift/2025/02/27/NLP/LLM-Training/2025-02-27-LLM-PostTrain-PPO-Data/
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。