DrGRPO来自Understanding R1-Zero-Like Training: A Critical Perspective,是oat-zero同一个团队的最新成果。没错,这虽然是一篇综合分析Base和RL的文章,但我们这里重点关注其中的RL部分,尤其是针对GRPO两个偏差的优化。它的发布时间就在DAPO发布一周后。
RL分析
首先是对GRPO的两个偏差的分析。

如式(3)所示,GRPO的两个偏差分别体现在两个红色标记处。
- 响应级别长度偏差:对积极的advantage,这种偏差导致较短的响应获得更大的梯度更新,从而使策略倾向于在正确答案中优先选择更简洁的表达。相反,对于消极的advantage,由于较长的响应具有更大的 |oi|,因此它们受到的惩罚较小,这导致策略在错误答案中倾向于选择较长的响应。
- 问题难度级别偏差:标准差较低的问题(例如,太简单或太困难的问题,结果奖励几乎全为 1 或 0)在策略更新时会被赋予更高的权重。问题级归一化导致不同问题在目标函数中的权重不同,从而在优化过程中产生了难度偏差。
稍微解释一下第一个,乍一看好像无论短还是长的响应,它们的损失函数在 token 级别上都是均值化的,似乎不会有长度偏差。但其核心问题在于:
-
由于归一化,导致每个响应(无论长短)的梯度贡献在整体 batch 里是一样的。
-
但是 advantage计算是基于完整的响应,而不是 token。
这就意味着短的响应和长的响应的 advantage 数值大小是一样的,但是短的响应的每个 token 都能获得更强的梯度更新,因为它的 token 数量少,梯度不会被均摊太多。反过来,短的错误答案被惩罚更严重,梯度更新大,模型更快地减少生成这种错误答案的概率;长的错误答案因为梯度更新小,惩罚力度不够,导致模型不太容易抑制长的错误答案。最终导致正确答案更倾向于短的表达,而错误答案更倾向于长的表达。
这两个发现和DAPO的其中两个发现不谋而合,非常类似(注意是类似,实际上两者是有明显区别的),前者对应的是Token级别的策略梯度损失,后者对应的是动态采样。
神奇的是,现有很多框架的PPO(包括GRPO之前的PPO)实现也存在着长度偏差,见下面的代码清单。论文猜测这种偏差可能来源于预训练,因为预训练时token会被填充到固定长度上下文,而按上下文长度归一化损失有助于数值稳定性。但在强化微调阶段,响应长度是不固定的,这在无意中引入了长度偏差。
1 | def masked_mean(tensor, mask, dim): |
真是非常细节的发现,而且确实有一定道理。虽然本文的两个偏差和DAPO类似,但角度却不相同。
Dr. GRPO
为了解决这两个偏差,Dr. GRPO直接去掉了红色的两项(归一化项)。同时,为了忠实地实现无偏的优化目标,将masked mean 函数中的 mask.sum(axis=dim) 替换为一个常数值(例如生成预算,即最大长度)。
Dr. GRPO的解决方案比较直接,我们顺便回顾一下DAPO是怎么做的。
- 针对响应长度偏差,DAPO将损失计算从样本集改为token级,按token的贡献更新策略。DAPO除以的是所有token数,而Dr .GRPO则除以的是G。
- 针对问题难度偏差,则通过动态采样,去掉了准确度为1和0的样本,因为一个提示词的一组输出都是1或0时,Advantage直接为0了,没意义。这个和Dr. GRPO其实还是有区别的,后者针对的是几乎为1或0的情况,这种情况下DAPO并不会去掉该提示(样本)。所以,两者其实是可以结合的!
实验是在Qwen2.5-1.5B Base上做的,基于规则奖励,正确1,错误0,效果如下图所示:
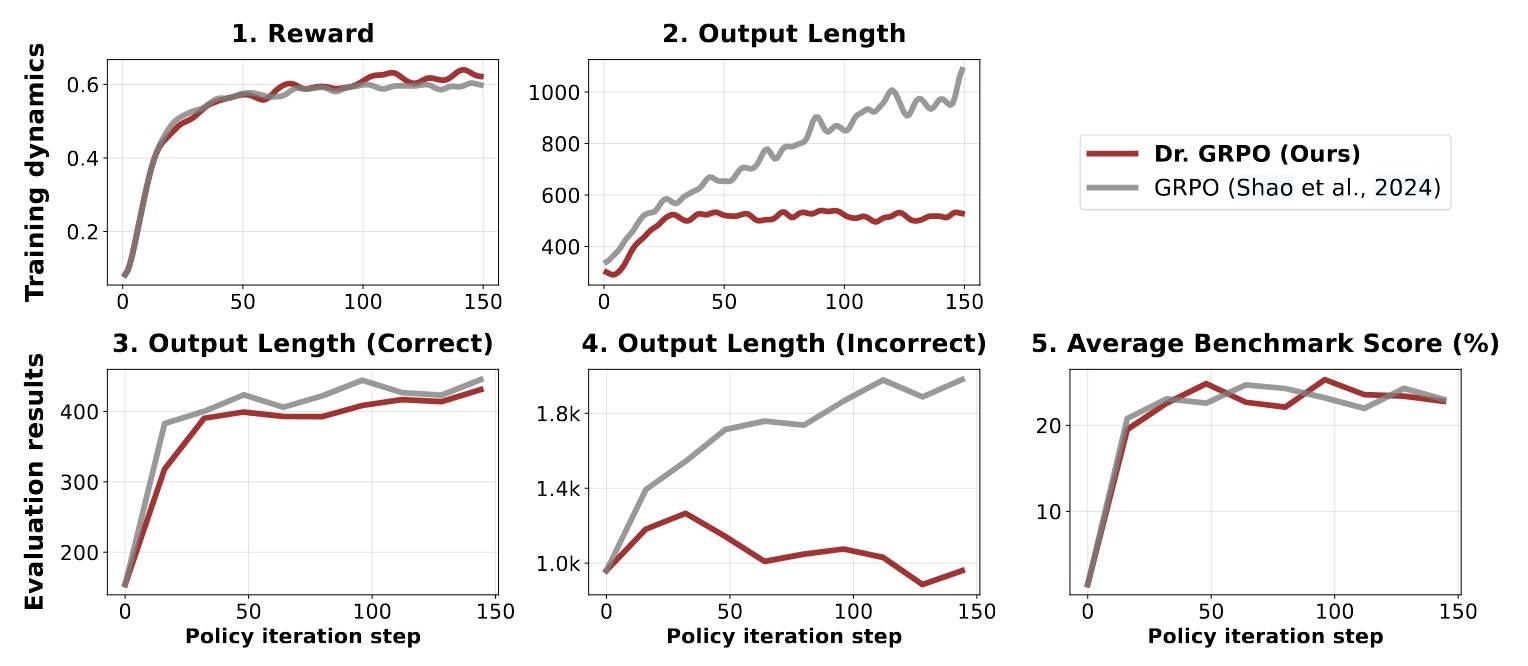
观察到,响应长度随训练奖励增加,与R1-Zero类似,但GRPO在奖励增益放缓时,仍然持续生成更长的回复。尽管这种现象通常被认为是“自然涌现”(Aha),但可能还受到响应级别的长度偏差影响。Dr. GRPO显著减少了错误响应的长度,不仅提高了效率,还能缓解模型过度思考。
这里看起来是有一定道理的,不过我还是有一点疑惑:最终答案错误是不是意味着中间过程都是错的?这个假设如果成立,上面的结论才更有说服力。另外,1.5B的模型有点太小了,结论是否适用于更大模型,比如7B或32B?
模板与数据覆盖对RL影响
因为Base模型(尤其是Qwen2.5系列)本身具备一定推理和指令跟随能力,所以考察了模板如何影响RL训练,以及不同模板和不同问题覆盖范围之间的相互作用。
实验基于Qwen2.5-Math-1.5B,不同数据及分布如下:

结果如下图所示:
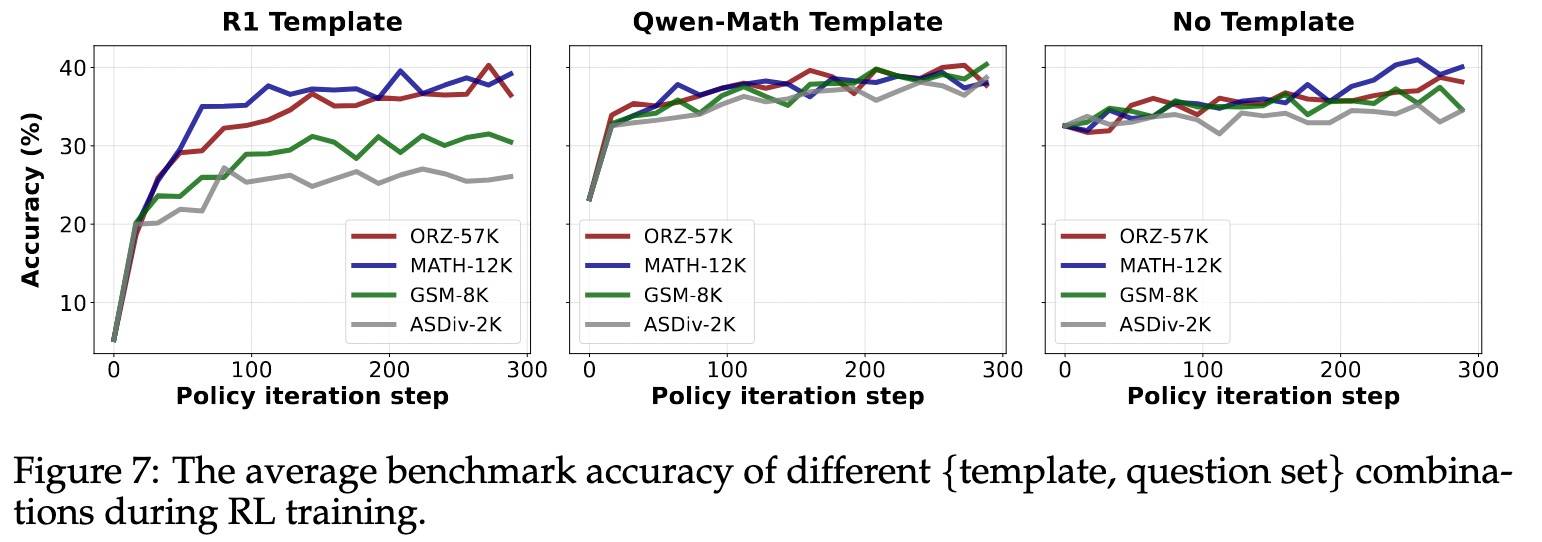
核心结论如下:
- Qwen2.5-Math-1.5B Base已经具备强大数学能力,添加模板反而会破坏其原有能力,RL 训练过程相当于重建这一能力。
- 当基础模型与提示模板不匹配时,模型的提升主要依赖于 RL 调优,因此问题集的覆盖范围至关重要。但如果选择了合适的模板,即使问题集很小且完全 o.o.d.,RL 仍然可以有效强化推理能力。
- 说明,关键在于强化正确的推理行为,而不是向模型注入新知识。
以上观察和我们一直以来的分析是相吻合的,即:能力在与Base,RL(或少量高质量数据SFT)都是在激活能力,也就是“引导”模型释放能力。所以,模板不匹配时需要多样化的数据(可阅读《DeepSeek R1后LLM新范式 | Yam》)。
数学预训练提升RL上限
大多数复现R1-Zero都用Qwen2.5,但Qwen2.5本身已经具备一定推理和Aha能力。这里考察R1-Zero类似的训练方法能否在数学推理能力较弱的基础模型上取得成功。
实验基于Llama-3.2-3B Base,FineMath是在该数据集上继续训练的模型,NuminaQA则是在该QA数据集上基于FineMath模型继续训练的模型。
结果如下图所示:
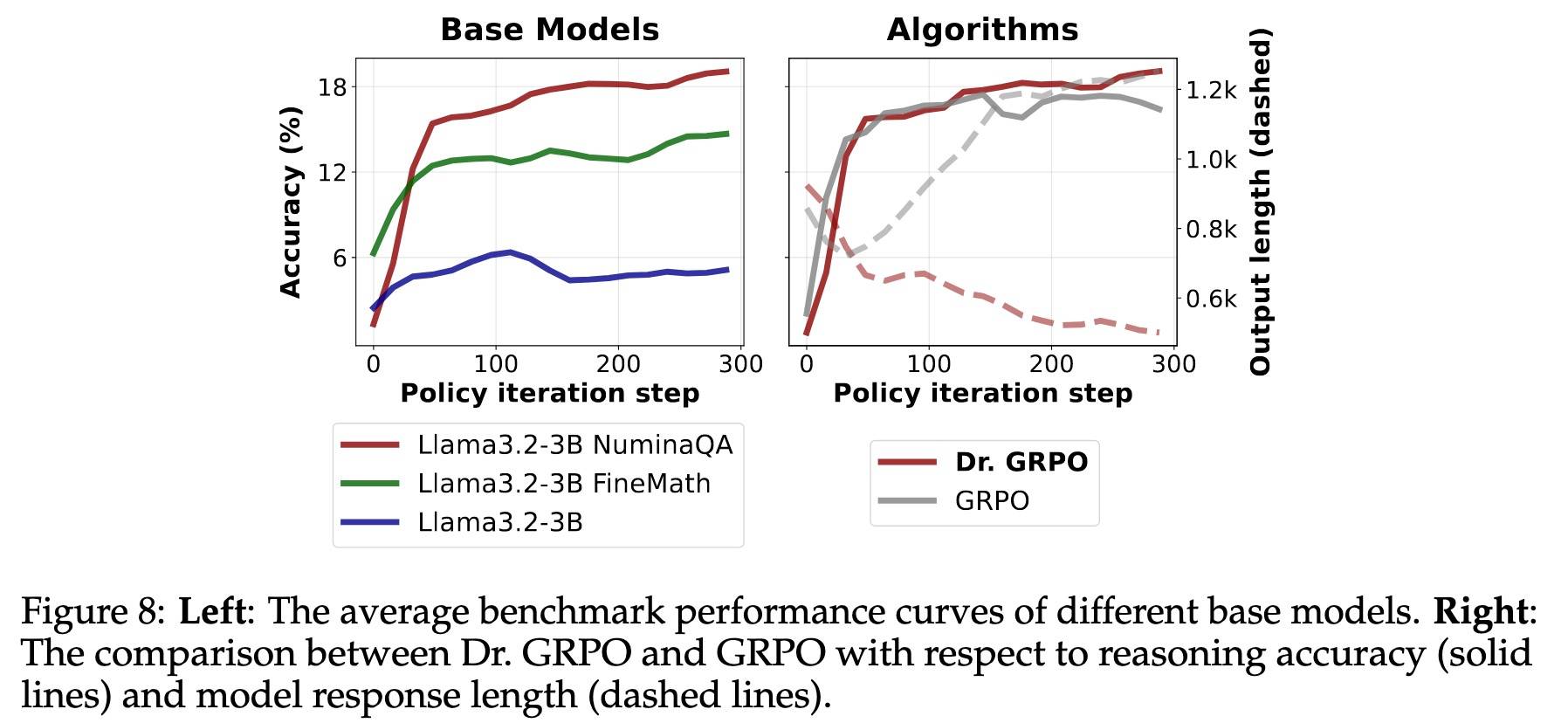
核心结论如下:
- RL可以改善原始的Llama基础模型,但提升较小。
- 加入数学知识后,RL性能提升显著。
- Dr. GRPO和GRPO的表现也和前面一致。
以上结论再次印证了我们一直以来的认知,前面也提到过,即:能力在Base。根据我自己的实验结果,LLaMA3.1-8B模型(一般被认为没有Aha能力)在逻辑推理任务上通过R1-Zero也能带来性能提升,但并没有表现出长度增加的效果,如下图所示。
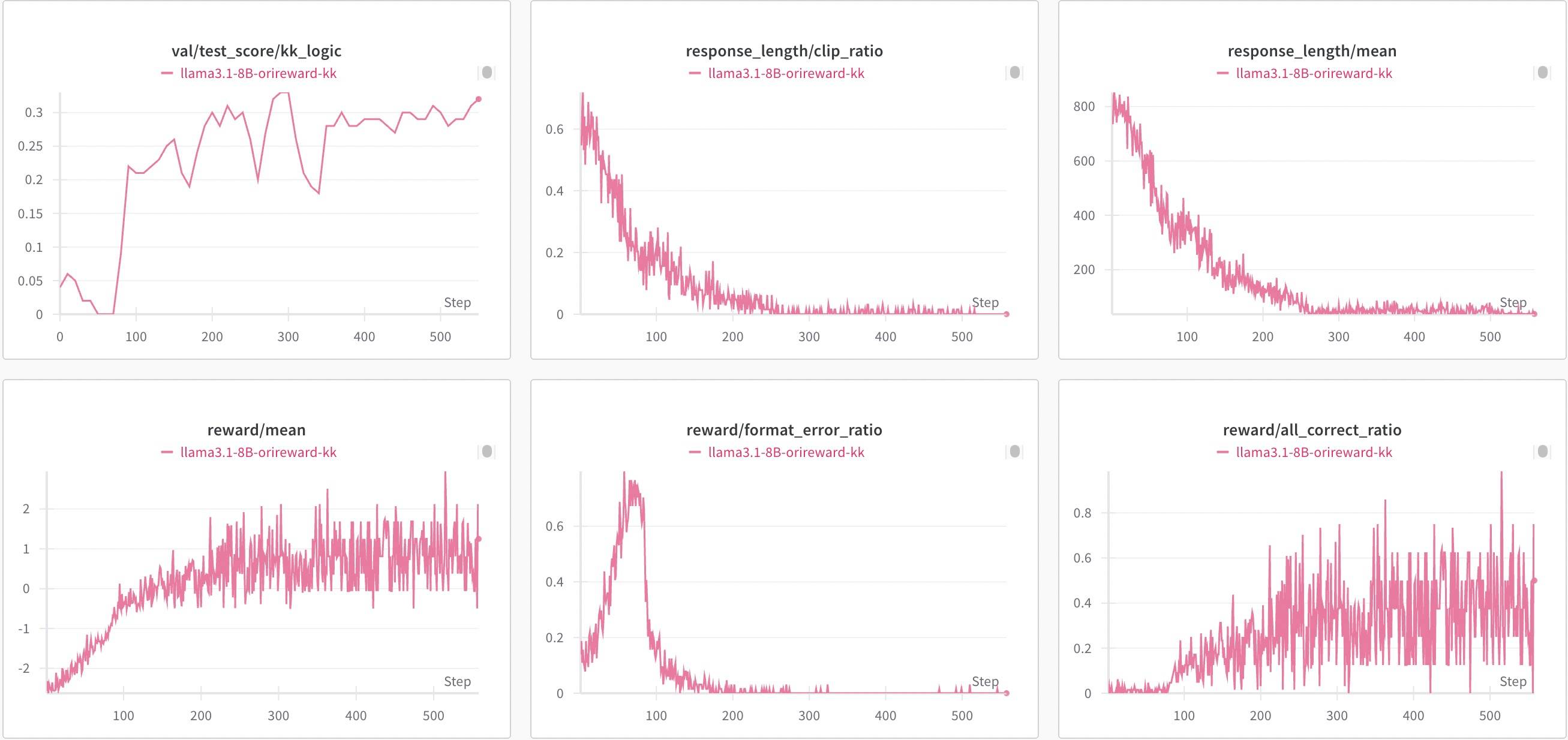
Reward、Acc都在持续增加,但回复长度是一路下降。思考过程一直是模板中的提示词: <think> reasoning process here </think>。当然,这可能和数据集的选择有关(这里只是逻辑题目),但确实没有表现出想要的思考能力,它只是学会了那个格式。不过这个实验也说明,即使Base模型没有很强的推理能力,RL也能提升性能,也会让模型遵循格式。
小结
精彩呀!非常有意思的Paper。我们把GRPO、DAPO和Dr. GAPO的损失函数一起写下来。

看起来一目了然。没想到一个小小的GRPO居然有这么多细节。虽说数据就是一切,但这种算法层面精细地分析和优化永远动人心弦。总的来说,Dr. GRPO解决了响应长度和问题难度两个方面的偏差,关于advantage的计算,Dr. GRPO是可以和DAPO融合的,但是关于响应长度的优化,两者是不相同的。如果更关注单个token的贡献,可以采用DAPO的做法,如果更关注整体回复(是否正确),则采用Dr. GRPO的做法。通俗点来说,那就是:如果只关心结果就用Dr. GRPO的做法,如果更关心过程就用DAPO的做法。
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。