本文介绍几篇关于Reward的文章,Reward经历了RLHF的scalar,到LLM-as-Judge,以及DeepSeek-R1的Rule,很自然地逐渐转移到通用领域——如何针对非推理(无标准答案)Query,给出模型响应的Reward。只要解决好这个问题,R1-Zero的方法就可以很自然地扩展到通用领域。而这也可以和之前在DeepSeek R1深度技术解析及其影响 | Yam[1]中提到的强化学习执念很好地融合在一起。
DeepSeek-GRM
DeepSeek-GRM[2](以下简称DS-GRM)就是针对通用领域奖励建模进行优化的一个工作,主要关注:
- 如何Scaling 通用RM,尤其是推理时。
- 如何通过适当的学习方法提高(性能计算)Scaling的有效性。
给出的答案分别是:Pointwise GRM和Self-Principled Critique Tuning(SPCT),最终在Reward这个方向上取得SOTA效果。
背景
RL作为后训练方法在偏好对齐(RLHF)、长文本推理(DeepSeek R1)、环境适应(Deep Research)等方向都取得显著成效,RM在其中的作用非常显著。高质量的奖励信号能够极大提升性能,但是这个信号往往来自条件明确的人工设计环境或可验证问题的规则。
在通用领域依然有挑战,主要是通用领域的标准更加多样和复杂,大部分时候是没有所谓标准答案的。所以,之前才使用偏好对齐方法训练scalar的RM,但这是需要提前标注“偏好”的。另外,考虑到推理时Scaling,如何通过增加推理时计算生成更高质量的奖励信号,以及学习可扩展行为以实现更好的性能计算扩展也是实践时面临的挑战。
总的来说,可以从输入灵活度和推理时扩展性两个角度考察,如下所示:
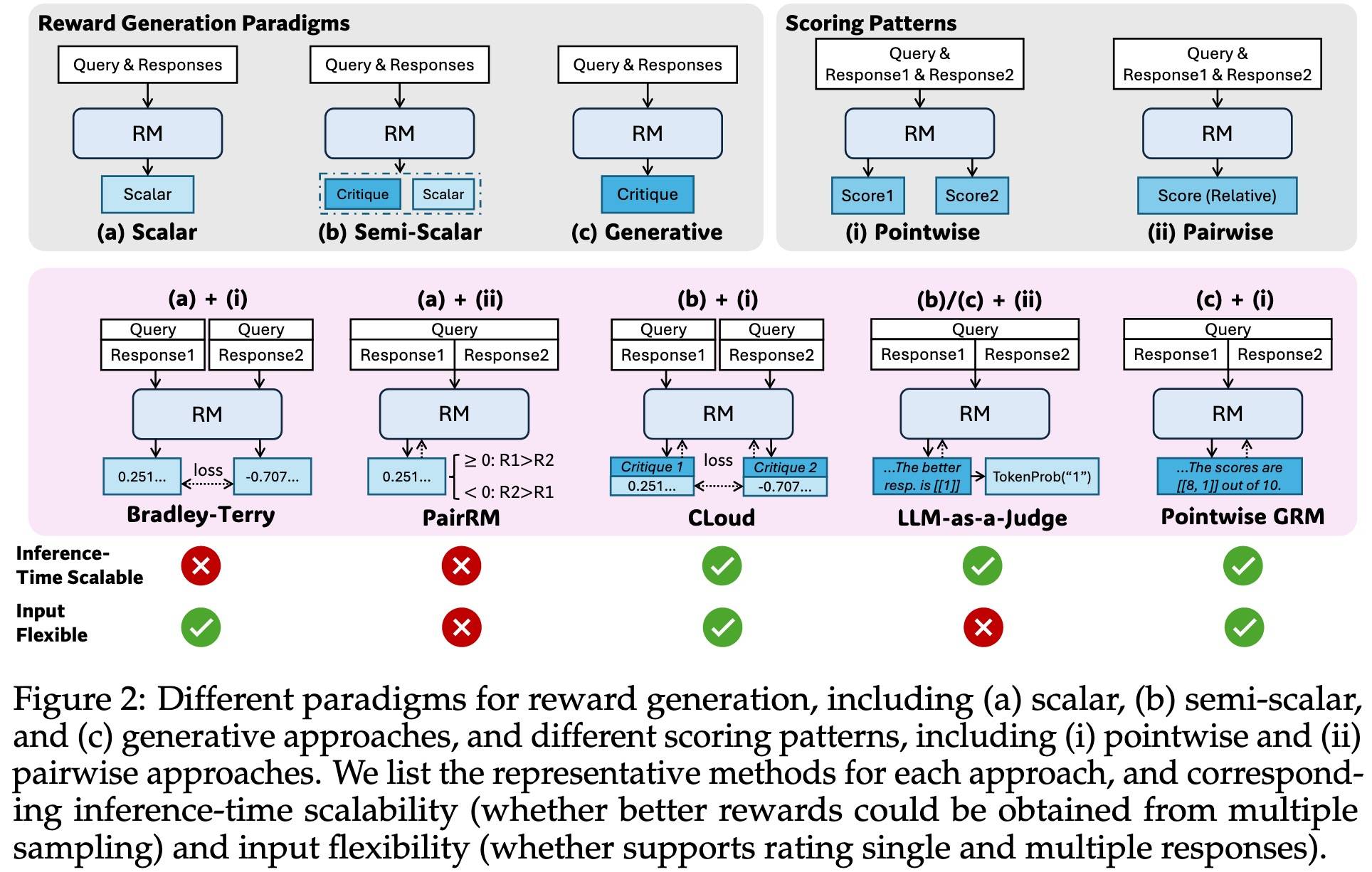
很少有方法关注推理时Scaling,并研究学习到的奖励生成行为与RM推理时Scaling有效性之间的相互联系。因此,DS-GRM的目标是:能否设计一种学习方法,旨在为通用RM实现有效的推理时Scaling?他们发现,RM的推理时Scaling可能通过扩大高质量原则的生成和准确评论的产出来实现。
方法
Principle
DS-GRM基于采样方法——对同样的q和不同的响应,生成大量的奖励,聚集后得到最终奖励。因此RM能否Scaling取决于多次采样能否生成不同的奖励。scalar的RM由于生成的奖励不变,不太适合,DS-GRM采用“原则”(人工制定的标准)引导奖励生成;而pairwise的输入方式则很难对单个响应进行打分。
原则,RULE,各种规则控制演绎!一切都连在了一起。可关注参考文献
[1]后面的文献。
于是,我们有:
x是query,yi是第i个响应,rθ是RM,R是Reward,C是评论,Si是yi的得分,f_extract从生成结果中提取奖励,p是原则。Reward一般是离散的,DS-GRM中Si∈N,且1≤Si≤10。式(1)的意思就是每个Si都从一个(x,yi,p)中获取。
可以看一下原则的效果:
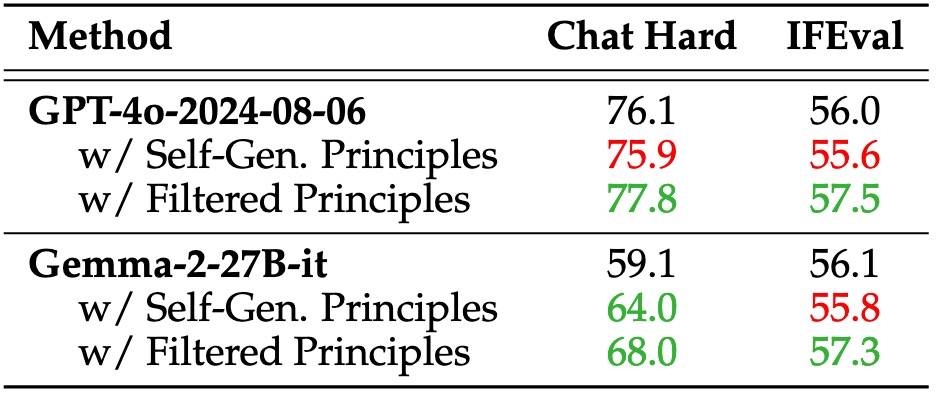
原则使用“GPT-4o-2024-08-06”生成,Filtered是指过滤掉那些相应奖励与基本事实不一致的原则。Filtered效果明显,这应该也是后面要专门训一个Meta RM的原因所在, 它被专门用来识别(二分类)原则和评论的正确性。
恰当的原则能够在特定标准下引导奖励的生成,这对于获得高质量的奖励至关重要。不过,为GRM大规模生成高效原则仍面临挑战(多样+复杂导致不容易找到“恰当”的原则)。因此,DS-GRM提出:将原则从传统的“理解辅助”角色中解耦,并将其融入到奖励生成过程本身,即不再将原则作为前置处理步骤,而是视为奖励生成机制的一部分。
pθ是原则生成函数,与奖励生成rθ共享相同的模型。这使得原则可以根据输入q和响应进行生成,从而自适应地调整奖励生成过程;同时,对GRM进行后训练还可以进一步提升原则及其对应评论的质量与细粒度。
SPCT
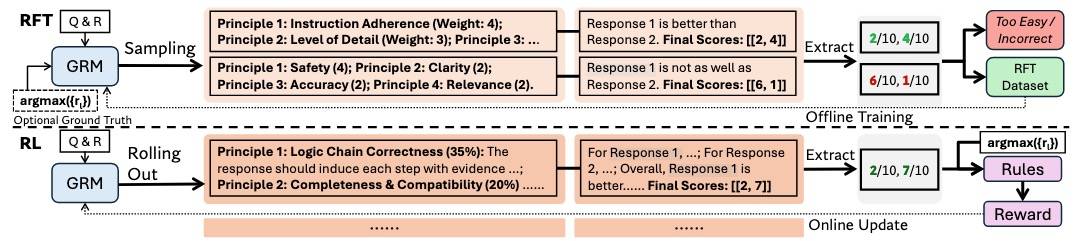
包括两步:
第一步:rejective fine-tuning(RFT),拒绝微调,可以看成冷启动。
-
核心思想:让GRM能够针对多种输入类型生成格式正确的原则与评论。
-
Pointwise GRM:可以为任意数量的响应生成格式一致的奖励。
-
数据构建:下面单独说。
数据构建:
- 除了通用指令数据,还根据query和来自RM数据中具有不同回答数量的回复,使用预训练的GRM采样轨迹。
- 对每个query和对应的多个回复,执行N_RFT次采样。
- 采样是统一的,即拒绝那些预测奖励与真实标签不一致的轨迹(即错误轨迹),同时拒绝那些所有N_RFT轨迹都正确的query和回复(即那些过于简单的样本)。
即,ri表示query x和第i个回复yi的真实reward,预测的pointwise reward 如果满足下面条件则正确:
保证真实奖励只有一个最大值。意思是,只有1个回复,S1要等于r1,超过1个回复,最大r对应的序号j对应的Sj也应该大于其他S。
不过有个问题是,预训练的GRM在有限采样配额内,对一部分query和它们的回复难以生成正确的reward。因此,除了non-hinted采样外,还可选地在 GRM 的提示中附加 (就是告诉它最大的是哪个),这一策略被称为hinted sampling,以期望预测奖励能更好地与真实标签对齐。
对hinted sampling,每个query和相应的回复采样一次,轨迹只有在不正确时被拒绝。另外观察到hinted sampling有时候会在推理时走捷径(可能只是学会了“猜正确答案”,而不是“为什么这个是对的”,这种离线预训练 + 提示采样可能有偏差),从而削弱生成评论的效果。这说明对GRM进行在线RL(模型在使用过程中不断和环境交互、获得反馈、实时优化奖励函数本身)有必要,可能带来益处。
第二步:rule-based RL,基于规则的RL。
- GRM 根据输入的q与响应生成原则与评论,随后提取预测的奖励,并与真实标签进行比较。
- GRPO,没有格式奖励,但用一个较大的KL惩罚参数来确保格式,并避免严重偏见。
给定x和n个响应,第i个output的奖励如下:
Si从oi中提取得到。该奖励函数鼓励 GRM 利用在线优化的原则与评论来区分最优响应,从而有利于实现高效的推理时Scaling。
公式(4)应该有点小问题,argmax那里应该是i(或者Sj > Si也可以)。本想和作者确认下,不过后来发现居然有了新version,已经修正了,很清晰,如下:
ITS
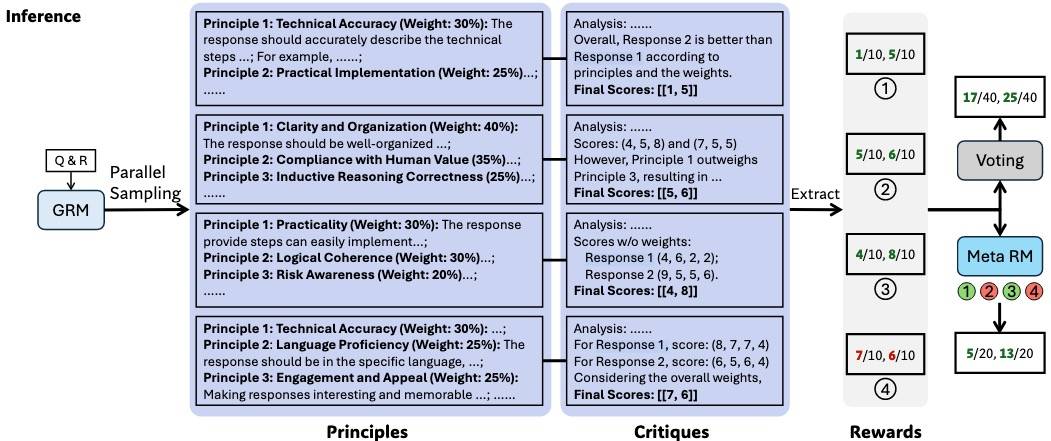
接下来是推理时Scaling,基于采样策略。
其中S*i是第i个回复的最终奖励。与式(1)差不多,不同的是,原则生成了k次,目的是让GRM 生成大量的原则(即p),有利于最终奖励的质量和颗粒度。这里的直觉是,如果每个原则都可以被视为评判视角的代理,那么更多的原则可能会更准确地反映实际分布,从而提升Scaling效果。
最后还有一点是Meta Reward Modeling Guided Voting,即用另一个RM指导投票。原因是多次生成的结果可能存在偏差或质量不高,这个Meta RM(二分类)就用来识别生成的原则和评价是否正确。训练数据包括RFT阶段non-hinted采样得到的轨迹,以及从需要引导的 DeepSeek-GRM 中采样的轨迹。
如上图所示,Naive的voting得到的分数是17/40和25/40,但Meta RM过滤掉了②和④,结果是5/20和13/20。
结果分析
SPCT 提高了 GRM 的通用奖励生成能力,不过提升并不明显,尤其是没有Scaling的情况,大概1个点的样子。
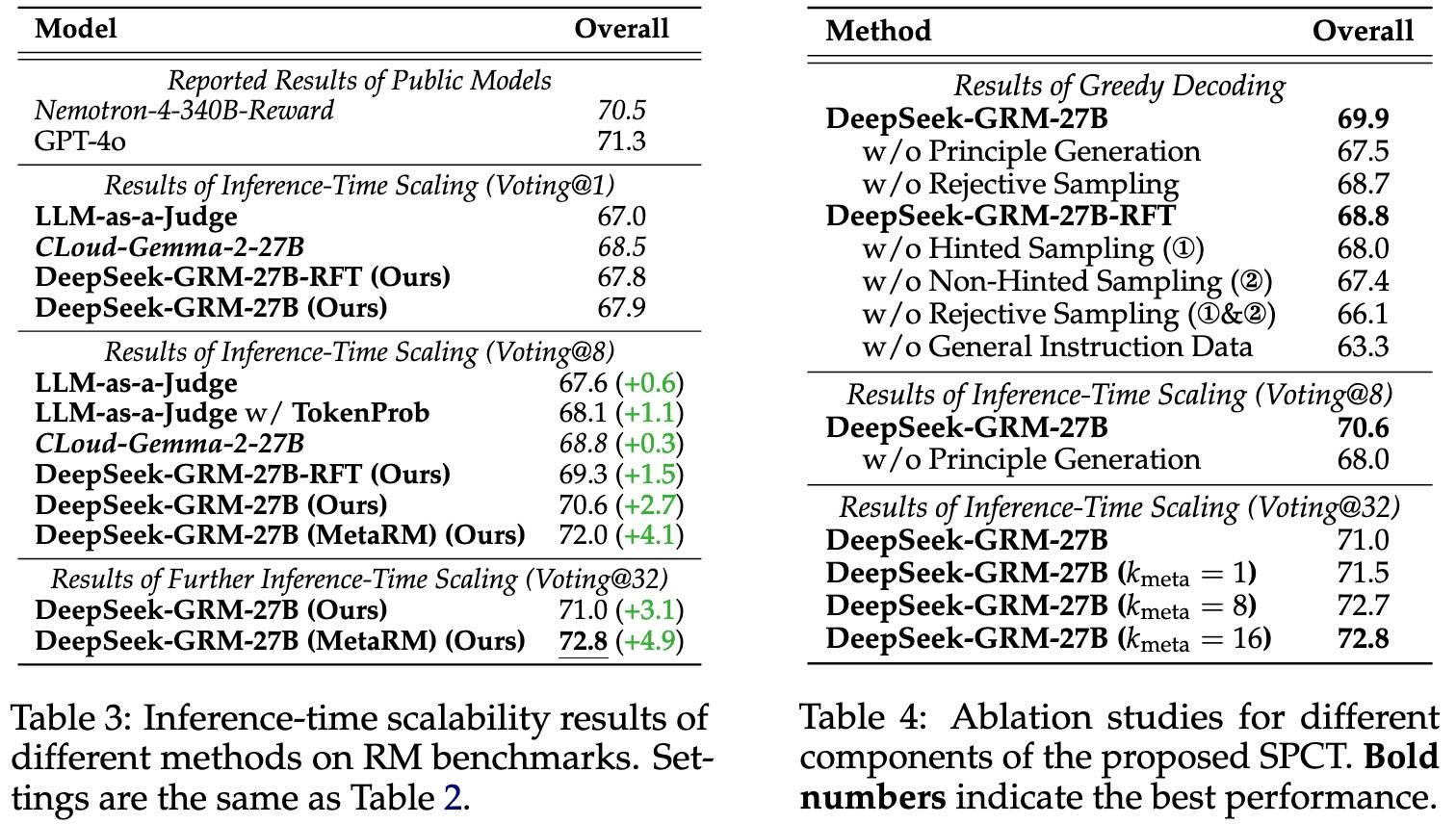
我们直接看Scaling和消融。Scaling效果如左图所示,Scaling到8时,最多能提升4个点,到32甚至能更高一些,MetaRM的作用是1.4个点。消融如右图所示,即使没有拒绝采样评论数据进行冷启动,在线强化学习也可以将性能从66.1提升至68.7,non-hinted采样相比hinted采样似乎更重要。另外,通用指令数据对 GRM 性能至关重要,原则生成作用也比较明显(2个点以上),Meta RM对不同的k比较稳定,整体1个多点的提升。
小结
总的来说:通用指令数据至关重要、原则生成比较关键,non-hinted采样和Meta RM差不多,也是比较符合直观认知的。“原则”也确实是本文给人感觉最有意思的部分,其他方法只是让数据更加高效。
关于原则,最直观的想法就是作为一种“规则”直接计算,我在参考文献[1]后面的文献中提到过多次,比如可读性(一个分级阅读指标)、简洁性、美感等。而本文是将“规则”纳入模型生成中,让模型自己决定规则,避免了显式设计规则,非常Nice的设计。显式规则虽然简单、直观,但也有一些不足,比如可能很难设计出恰当合适的规则,再比如可能把模型“带坏”——只有规则,没有意义。后面这个我举个例子,比如我们设计的规则是“简洁”,模型可能直接输出很多一模一样的简单Token。在实践中,如果任务有合适的定量衡量规则,那不用训RM,DAPO、GRPO什么的直接走起,先看看效果再说;如果没有合适的定量衡量规则,不妨试试本文的方法,让模型自己生成规则,用这个数据训练一个RM作为引导Policy的规则。当然,我们还可以结合使用,即有一些定性规则,将其作为原则生成评价(Pointwise)来训练RM。不过训练RM的前提是必须要有偏好数据集,可别忘了~
RM-R1
好吧,这篇文章[3]的想法直白多了——直接将reward建模过程当做推理过程,当然,目标依然是通用奖励模型。来看个例子一目了然:

其实可以看作是GenRM(生成式奖励模型)的升级版,因为一般的GenRM推理往往较为表面化,难以支撑可靠的判断(有2个文献证明,一个是Judgelrm,另一个就是DeepSeek-GRM)。完蛋,我刚刚读完DeepSeek-GRM,没发现有提到这个观点(GenRM这个点上提的比较多的是Inference Time Scaling),反而是个比较相反的观点,如下:
Moreover, we test DeepSeek-R1 with a downsampled test set containing 300 samples, and find its performance even worse than the 236B MoE RFT model, indicating that expanding long chain-of-thoughts for reasoning tasks could not significantly improve the performance of generalist RM.
而本文观点如下:
We find that integrating long reasoning chains during the judging process significantly enhances downstream reward model performance, consistently outperforming its non-reasoning counterparts (e.g., scalar RM and ordinary GenRM).
另外在相关工作部分也提到DeepSeek-GRM是使用推理模型作为通用奖励模型,可别人明明是基于预训练模型。有点子尴尬,有同学注意到这个细节了么,是不是我理解有误。
梗概
本文发现,直接奖用可验证奖励的强化学习(RLVR)应用于通用RM并不能充分激发模型在奖励建模中的潜力,需要在此之前引入一个结构化推理蒸馏阶段,这个阶段避免了单独使用RLVR使模型偏向关注表层特征。具体来说就是先选择一个Instruct模型,然后采用“评判链”(Chain-of-Rubrics,CoR)提示框架引导结构化且连贯的推理过程。
- 对chat类任务:生成一组评估准则、对应准则的解释,以及针对特定问题的评估内容。
- 对reasoning类任务:正确性通常是优先考虑的因素,因此直接让模型先自行解答问题,再对成对的模型回复进行评估。
另外,本文探索了如何将现有的推理模型直接适配到奖励模型,做法就是直接强化微调(RLVR)。
方法
如下图所示:
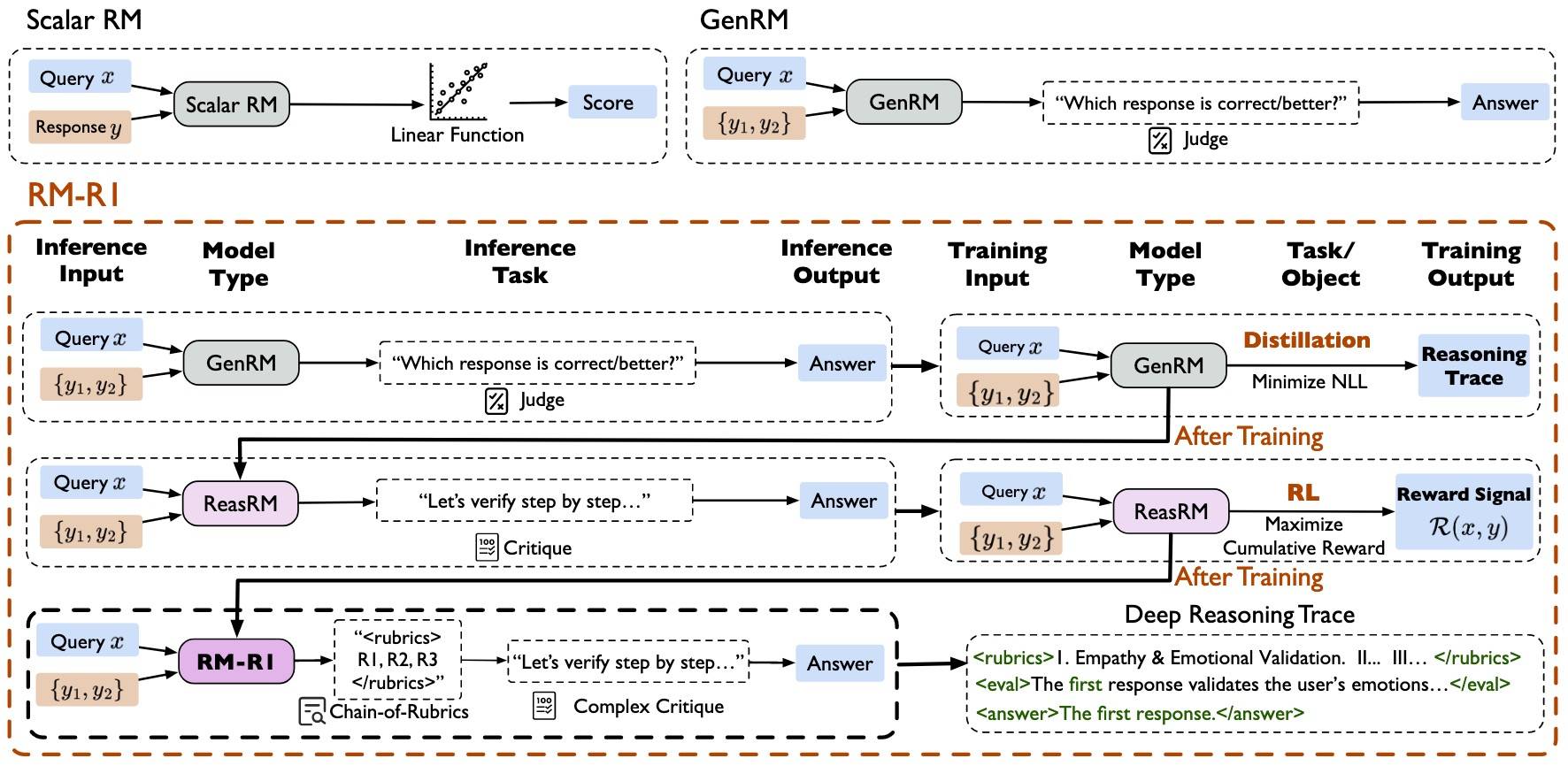
两步走:
- 从任意Instruct模型开始,合成高质量的推理轨迹数据,然后蒸馏。此时模型具备了RM需要的基本推理能力。
- 蒸馏模型会过拟合到训练数据上,使用RL继续训练提升泛化性。
经过两阶段训练后,得到RM-R1。
蒸馏
用o3或claude-3-7-sonnet生成结构化推理过程(轨迹),以解释为什么在给定输入 x(i) 的情况下选择 y(i)_l作为正确答案。l是ground truth标签,推理过程和正确答案构成训练数据的response部分。嗯,其实就是个LLM的SFT。
RL
就是将RM当做Policy,重复R1训练过程(前两步)。ref是训练前的checkpoint,它可以是现成的LLM,也可以是上步蒸馏后的LLM。
提示词
CoR的系统提示词个人觉得设计的不错,可以参考一下:
1 | """ |
推理类模型(如DeepSeek-R1-distilled系列)没有系统提示词,但是有个用户提示词,如下:
1 | """ |
奖励设计
很简单,答案对就1分,不对-1分。
另外,格式奖励没啥影响,可能SFT模型已经学会遵循指令。而且加入格式奖励会显著降低优势(advantage)的计算速度,因为正则表达式匹配的开销会随着回复的 token 长度线性增长。前面这点之前已经讨论过太多次了(比如《R1相关:R1-Zero的进一步理解和探索 | Yam[4]》),不再赘述;关于后面这点存疑,正则表达式速度能有多慢呢……
结果分析
Scaling效果
模型大小和推理时计算与性能表现接近线性趋势。
训练方案
直接复制数学任务上的强化学习方案(方案1)不足以训练出强大的推理奖励模型。显式的Query分类(方案2)和高质量推理过程数据蒸馏(方案3)对于实现稳健且具泛化能力的性能提升都至关重要。
- Cold Start RL,RLVR,格式奖励+答案奖励。用户提示词。
- Cold Start RL + Query Categorization (QC),提示LLM先将任务分类为推理任务或对话任务。系统提示词。对于推理任务,发现答案质量与正确性紧密相关,抽象的(高层次)评判准则可能不如直接评估模型是否能够解题并验证自身答案来得有效。
- Distilled + RL + QC (RM-R1),从更强大的教师模型引入额外的蒸馏阶段,作为RL前的warmup,其动机是,仅使用 RL 时较弱的模型通常无法为聊天任务探索高质量的评分准则和令人信服的推理链。
效果如下表所示:

推理训练的有效性
SFT表示直接在最终答案上微调,distilled表示在强模型的推理链上微调。

RM-R1=Distilled + RL。结论是,推理模型明显提升效果,即便在少量数据下。而且在不同Bench下表现出不错的泛化能力。
训练动态
主要考虑两种不同设置下回复长度和reward的变化情况。
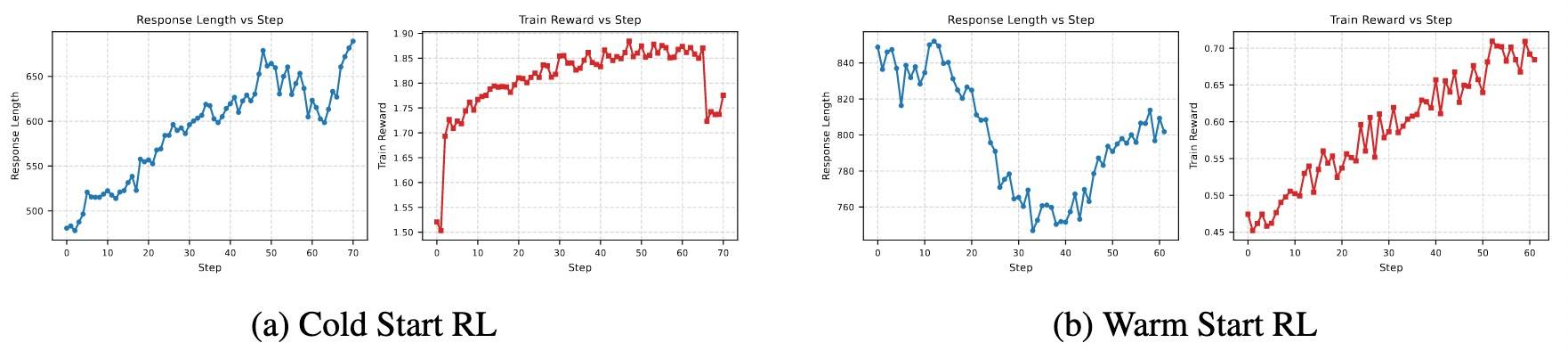
冷启动就是直接RL,热启动在此之前先进行推理链蒸馏。效果如上图所示,冷启动逐步学习推理(回复长度稳定增长),后面不稳定,可能过拟合。热启动一开始就具备一定推理能力(回复长度一开始就长),长度先降后增,奖励曲线更稳定。
小结
总的来说,中规中矩,不少结论和结果事先也大概有个预期。方法上相对比较简单,pairwise,是专注于RM的,没考虑Scaling,意味着在RL Policy时不太友好。可以和DeepSeek-GRM结合起来使用。
TTRL
这个有意思了,没有reward model,也没有规则,那咋打分呢,投票——少数服从多数,大部分的答案是什么样子的,就选择什么样子的作为标准答案。
方法
第一次看到这篇文章[5]时就感觉挺有意思的,正好放在这里,思想很简单,如下:
1 | from collections import Counter |
最大的特点是不需要答案Label。其实敞开了想,即便是没有答案的通用领域也可以用的,无非就是对答案打个标签罢了。答案正确是一种偏好,标签也是一种偏好,投票还是一种偏好。Reward Model的目标就是找到对应的偏好。
结果分析
看最后效果提升还是挺明显的,尤其是对小点的大模型。如下表所示:
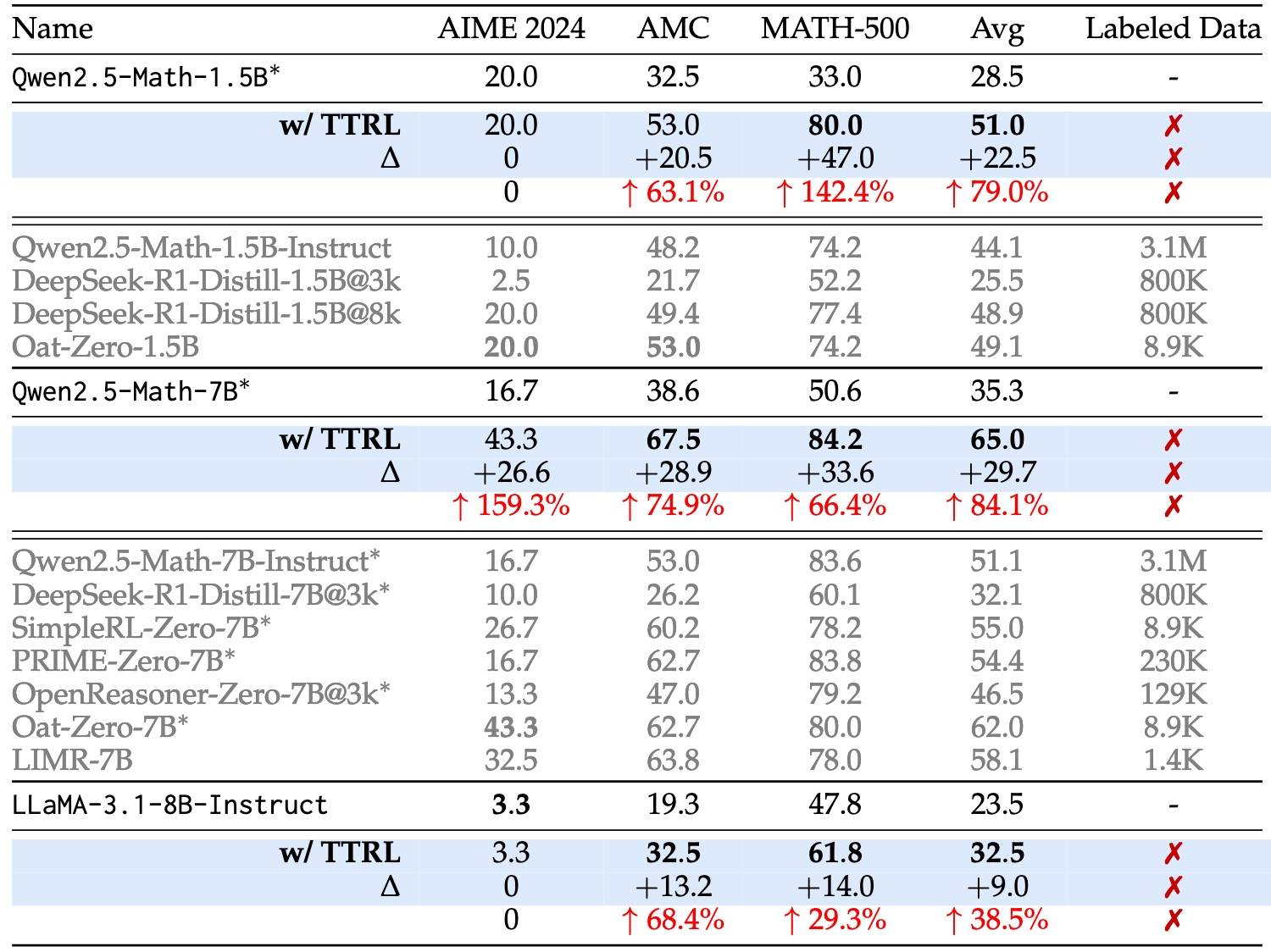
文章后面有分析为什么TTRL有效,主要是两个因素:
- 标签估计。TTRL的标签可能不对,但它依然会生效,原因有两个:
- RL可以容忍一定程度的奖励不准确性,通常具有更强的泛化能力。在RL中,奖励通常是模糊的(比如只有一个大的准则、规则),主要起到引导探索方向的作用,因此对奖励噪声具有较强的鲁棒性。
- 有研究从优化的角度探讨了什么样的奖励模型才是“好的教师”,结果发现,更精确的奖励模型不一定是更好的教学信号来源。因此,由策略模型自身估算的奖励信号,反而可能为学习过程提供更合适的引导。
- 奖励计算。基于规则的奖励是根据预测的答案是否与“标签”相匹配来分配的。即使估计的标签不是真实标签,只要它与一个错误的预测答案不同,系统仍然可以正确地给予一个“负向”奖励。
- 奖励比标签密集,即使估计的标签不准确,也可以提供更多的机会来恢复有用的学习信号。比如一组rollout预测的答案为:11222456,真实Label为3,真实的Reward应该是 00000000;TTRL评估的Label为2,真实的Reward为 00111000,62.5%的准确率。
- 当模型能力较弱时,TTRL 给出的奖励反而可能更准确。模型性能越差,通常犯的错误也越多,这反而有助于更准确地估计奖励。如下图所示,尽管大多时候标签准确率仅在 20%~50% 之间波动,但Reward准确率一开始就达到92%。而且,一开始最常被预测的答案仅占所有预测的16.6%。
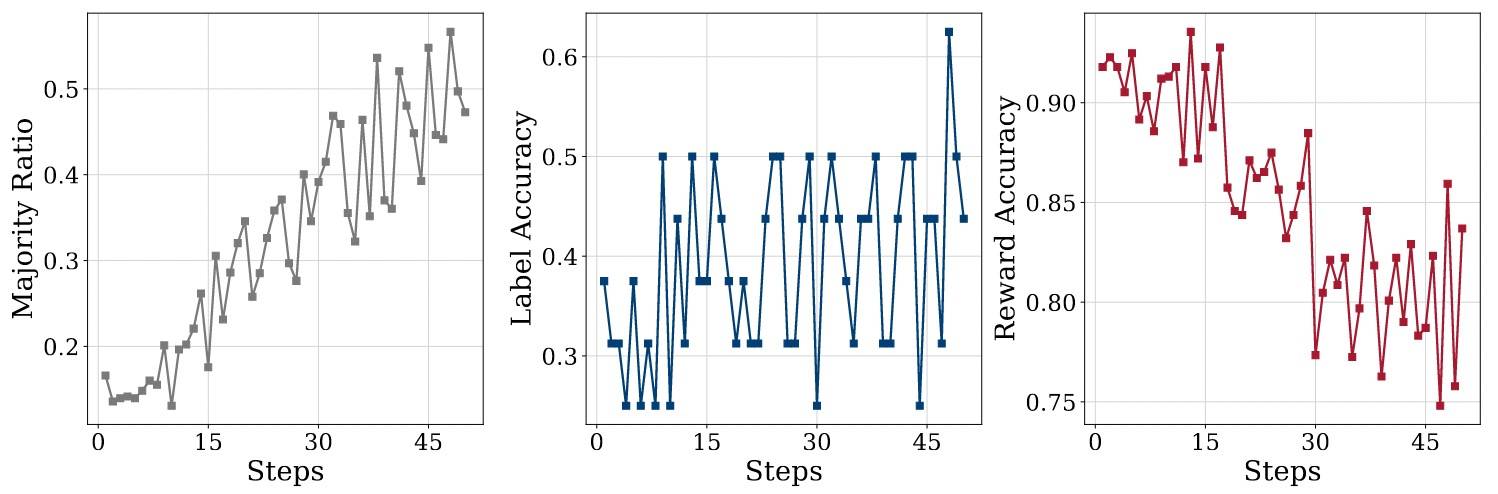
分析完成功,再分析为什么可能失败。主要是两个方面:
- 缺乏目标任务的先验知识。如果模型的先验知识不足以应对数据的复杂性,TTRL 就可能训练失败。消融结果表面,随着题目难度的增加,性能提升幅度和回答长度缩减率都呈下降趋势。说明模型先验知识不足以支持对更具挑战性问题的有效学习。
- 不恰当的超参数。由于奖励估计中可能存在的噪声以及测试数据本身的特性(通常难度较高,并引入了新的特征),超参数的影响被进一步放大,具体表现是持续高熵(不是高烧;D)。有2个参数比较重要:Temperature设置为 1.0(而非 0.6)会增加模型输出的熵值,促进更广泛的探索,并使模型能更好地利用其先验知识进行自我提升;Epoch,规模较小但难度较高的数据集通常需要更多的Epoch,以实现充分的探索。
小结
这个属于探索性质的尝试了,实际中恐怕没人会这么干(手动狗头),虽然它看起来效果还可以。它成功的关键依然是Base模型,并没有超出我们的认知,但确实让人眼前一亮。对没有标签的数据集,可以是很好的开始。
总结
本文介绍了几篇关于RM的文章,这个方向也越来越有意思了,当然也越来越重要了,最近相关文章着实不少,除了本文介绍的三篇,其他还有比如Qwen的WorldPM(关于缩放的,对抗和客观指标可缩放,主观偏好无缩放)、斯坦福的R3(多任务建模)、上交的Reward Inside the Model(利用 LLM 隐藏状态建模)等等。RM正在向着通用、高效方向不断迈进,当然也越来越LLM化。
References
[1] DeepSeek R1深度技术解析及其影响 | Yam: https://yam.gift/2025/02/17/NLP/LLM-Training/2025-02-17-DeepSeek-R1/
[2] DeepSeek-GRM: https://arxiv.org/abs/2504.02495
[3] 文章: https://arxiv.org/abs/2505.02387
[4] R1相关:R1-Zero的进一步理解和探索 | Yam: https://yam.gift/2025/04/10/NLP/LLM-Training/2025-04-10-Think-More-about-R1-Zero/
[5] 文章: https://arxiv.org/abs/2504.16084
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。