本文借着Voila[1]顺便聊一下音频端到端(OMNI)的进展,以及个人的一些理解。这玩意儿就是从2024年5月份GPT4o发布后开始逐渐火热起来,尤其是2024年下半年,看看[2]短短的几个月出了多少codec的文章。当时我们也做了一些尝试,没取得什么大的成果,不过倒是验证了蛮多想法。
语音交互
首先,聊聊为什么要做语音交互。借用Voila里的观点,语音交互相比文本有如下优势:
- 语音自然而然地支持丰富、动态和类似人类的交互。
- 语音带有丰富的声音线索(如语气、音调变化和节奏)和其他方式无法复制的微妙情感细微差别。
这其实很容易理解,人是社群生物,需要彼此交流,而聊天是最常见、最本能的交流方式。我们可以很容易地通过一个人的语气了解他当时的状态,甚至可以通过讲话方式和风格大致推测对方的性格。语音中除了语言文字,还包含大量丰富的副语言声音,以及其他非语言类声音,拟人、自然、情感丰富的合成语音让AI更加富有情感、更有感染力、更像人。LLM已经很“人”了,语音不也得跟上。
其实早在很多年前,语音就是相当重要的一个方向,之前的AI应用主要就是各种音箱(比如天猫精灵、小度啥的)、各种车载语音助手、AI外呼、有声书等。这两年,随着LLM的不断发展,各类新应用层出不穷,比如数字人直播、语音播客、AI心理咨询、AI面试培训等等;同时,旧应用也在升级换代。语音交互发展越来越快,也变得越来越重要。我在实时语音交互场景下RAG的机遇和挑战 | Yam[3]的分享中就曾提到过,2025年是Agent元年、语音元年,二者的结合——VoiceAgent更是会迎来爆发式增长。
交互方案
我们非常熟悉Pipeline和端到端两种模式,其实还有一种半端到端模式,对比如下:
- 端到端:语音→模型→语音。
- Pipeline:语音→ASR→LLM→TTS→语音。
- 半端到端:语音→SLM(SpeechLM)→TTS→语音。
端到端模式就是咱们常听到的OMNI,来自Hello GPT-4o | OpenAI[4],最大的特点是:速度快,能够理解输入的语音并据此做出反馈。而Pipeline则是目前大多数情况下的实用方案,只要提到OMNI,大概总会说Pipeline的劣势,比如Voila给出的:
- 延迟。人类交互为300ms(一般在200-500ms之间)。
- 语音细微差别的丢失(即副语言,如语气、重音、情感和背景声音)。
- 反应式、回合制交互无法捕捉到自然、自主语音交互的核心(如反向引导、打断和重叠的语音),导致交互比较机械。虽然可以用VAD检测打断,但缺乏实现自然、动态交互所需的更深入的上下文理解和自主性。
但是至今还没看到哪篇OMNI的研究说Pipeline模式的优势的,这里我随便罗列一下:
- 灵活。每一部分可以随意根据需要切换模型,比如LLM可以随时切换到最新的模型。
- 可控。badCase、定制需求非常容易满足,可以随意增加模块,比如审核、RAG等。
- 更丰富的TTS。独立的TTS系统往往可以支持更加丰富的语音效果。
最关键的是,前面提到的劣势其实完全能够解决或部分缓解。
- 延迟。我们不考虑其他模块,仅ASR、LLM和TTS,其实也可以把推理时间降到300-500ms左右。
- 语音细节丢失。ASR的同时可以再并行一个语义理解模型,输出情绪、事件等多种理解信息,还不额外占用时间。
- 自然交互。可以通过VAD或者自定义的打断检测模块进行识别,加一点工程手段,也可以做到自然流畅的交互。
以上我们已经在实践中做过检验确认。其实OMNI一下子迈的步子有点大,很多基础设施还没跟上,我在实时语音交互场景下RAG的机遇和挑战 | Yam[3]一文中已经提到过了。另外,OpenAI不也在后面推出[5]了Pipeline模式么。完全端到端的方案,谁在实际项目中真正用过谁知道。
其实目前看来比较可行、高效的还是Pipeline,其中最关键的是LLM——我们要尽量复用LLM的能力。现有的端到端模型在理解方面和LLM还有差距,连SLM都不太行。我们知道,LLM最核心的其实是理解,而不是生成,理解是一切的基础。所以,与其期待端到端模型,实际一点还不如期待一下SLM,SLM一般都是以LLM为起点,但同时把“声音理解”做到模型里面,个人觉得更切实际一些。另外还有一个原因,TTS其实是比较庞杂的一个模块,里面涉及到很多内容,但其核心其实就是发声,把它放在端到端模型里面给人感觉比较复杂。
端到端
好了,说回端到端,一个理想中的端到端模型是怎样的?
首先,它依然应该是以LLM为起点的。主要的原因是文本比语音效率高,同一句话100个人用同样的语气说,其特征就有100种,但换成文本特征就1种。要想以LLM的方式训练语音为Token的大模型,真的是事倍功半。因此,LLM为基座,兼容语音和图像模式才是比较务实的做法。
其次,应该支持多轮和上下文,且这些地方都是文本。也就是说,只有当前轮的用户输入是音频,其他均为文本。原因也很简单——文本的信息压缩率最高。从现有研究来看,即便压缩率最高的音频Tokenizer也无法和文本的相提并论。以单码本中文为例,12.5Hz(1秒12个Token)已是极限,一般情况下可能也就5-6个字,对应2-3个文本Token。如果是多码本,那还得成码本数倍数增加。另外,文本也便于支持本轮需要的上下文信息输入,更加符合真实场景。
第三,要支持双工。也就是说,用户和Bot的输出是并行(同时进行)的,只有一方说话时,另一方就体现为静音(听)状态,但其输入是存在的。双工可以做到更自然的交互,既可以“聆听”,也可以“打断”。
最后,应支持Instruct(比如“说快点”、“用四川方言说”、“用温柔的语气说”之类的)或ZeroShot(支持任意音色)的语音输出,或根据对输入内容的理解输出恰当的语音(比如用户听起来比较高兴,则也用开心的语气)。
端到端的模型和相关研究已经有不少了,尤其是2024年下半年,隔几天就一篇,看的人眼花缭乱。不过只记录了部分,感兴趣的读者可以阅读 OMNI论文速览(2024) | Yam[6] 和 OMNI论文速览(2025) | Yam[7]。其中印象最深的就是GLM-4-Voice[8]和Moshi[9]了。
GLM-4-Voice[8]在理解、语音控制、声音效果方面都做得比较好,多轮、问答、指令遵循能力也不错。不过它不支持双工,也不支持音色ZeroShot。另外,推理速度也不错,首音大概1.5秒左右。
Moshi[9]应该是第一个真正能用的端到端双工模型,它的主要问题是架构和训练过程比较复杂。比如Voila这篇论文里提到的,它设计的Inner Monologue 机制需要特定的配置来支持不同的任务,如口语对话、ASR 和 TTS,因此很难使用单个模型来支持所有应用。不过个人觉得Moshi最大的问题是要重训LLM,它是基于字节的,不能复用已有的LLM,这太尴尬了。不过,它的代码写的可太漂亮了,也开源了微调代码,很良心。
Voila关键模块
首先是音频Tokenizer,是我喜欢的多码本,Fish[10]的做法。喜欢多码本有两个原因:
- 效果好。一般情况下,多码本的语音效果是要优于单码本的。
- 与LLM解耦,单独用一个Transformer Decoder来生成音频Token,LLM生成文本Token,这对LLM的侵入最小。
不过Voila是统一用新的Decoder生成文本+音频Token,而原始的LLM提供hidden_states,并没有分开解码。由于输入时包含语音,因此就需要语音Token能表示语义。这里的做法和Moshi一样,将音频Token分为语义+声学,第一层关注语义,后面(三)层关注声学,10w小时数据。总的来说,这里的核心就是音频Code必须有语义信息,不然无法和LLM做适配,音频Token需要扩充到原LLM词表。
另一个关键部分是对齐,这里有亮点。
-
多任务对齐。
- 包括ASR、TTS和指令遵循任务。全部统一成NTP任务。
- ASR:
<human> audio input <voila> text output <eos> - TTS:
<human> text input <voila> audio output <eos> - 指令跟随:TITO、TIAO、AITO、AIAO。只计算response的损失,带Audio的输出都是交错的。
- 虽然论文没提,但从这里也可以看出训练至少包括两步:预训练和SFT。
-
文本-语音交错对齐。
- 每个有语义的文本单元,对应其音频Token。即严格的一一交错。
- 亮点:重复文本Token到num_codebook,而非将其叠加到音频Token上。如下图所示。
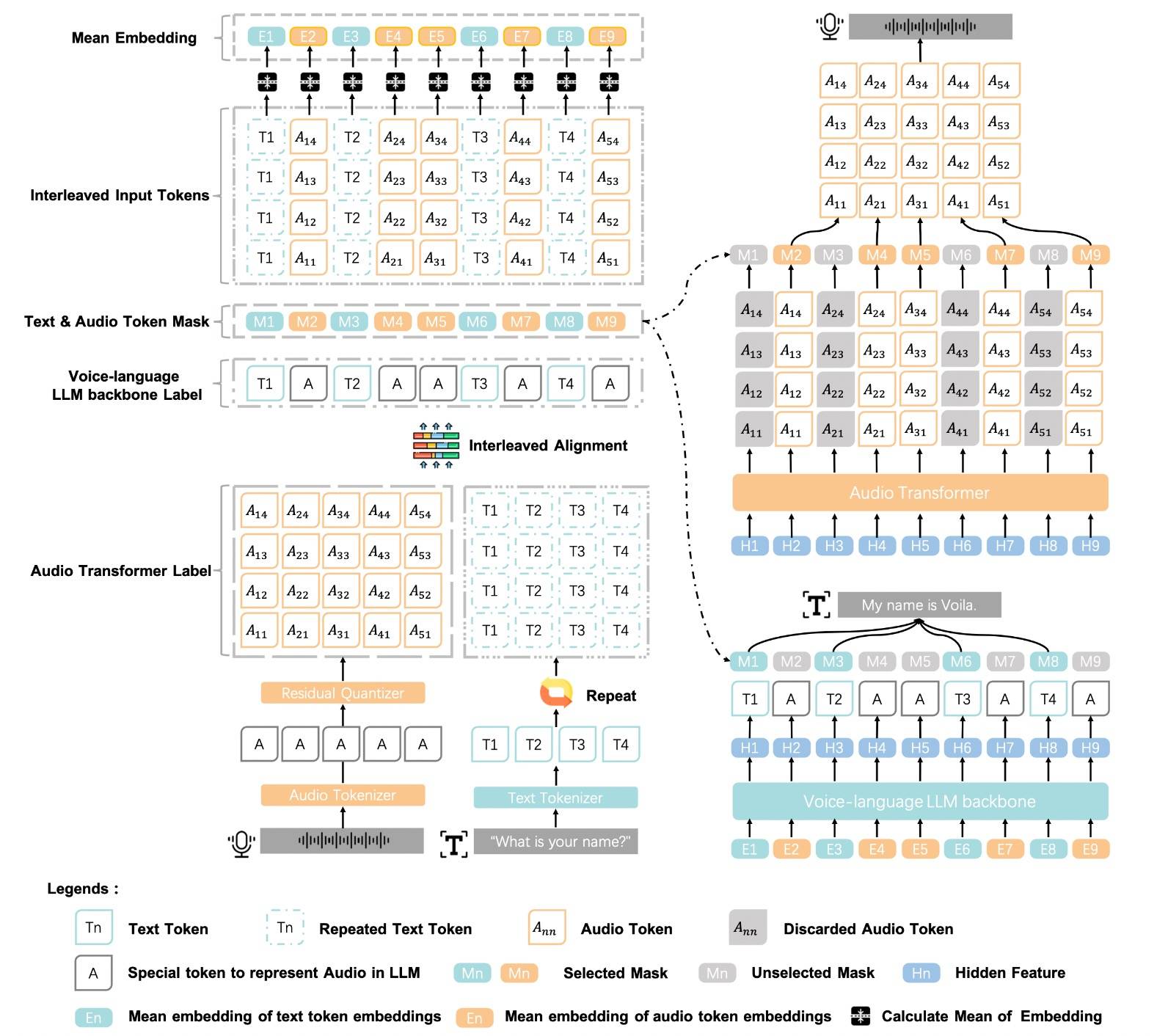
这种对齐方式统一了文本和语音,更加便于后续处理。而且LLM进去后是取平均,也不影响纯文本输入,有意思的设计。
举几个例子,比如TTS任务,对应的输入如下:
1 | # tts (重复4遍) |
其input_ids为:
1 | tensor([[[136448, 136448, 136448, 136448], |
每列是一样的,都可以decode成上面的输入。
再比如ASR,对应的输入如下:
1 | # asr(4个一组,每个的token不一样) |
其input_ids为:
1 | tensor([[[136448, 136448, 136448, 136448], |
每列都不一样,第一列可以decode成上面的输入,其他列的音频Token不一样(多码本)。
当然,aiao的输入看起来和asr差不多,tito的输入则和tts的差不多。如果输出带音频,则可以给一个Reference实现ZeroShot。
最后,受Voila启发,也说一下我自己认为的理想设计:
- 多码本,其实4码本应该已经足够了,最多8码本。
- LLM生成语义Token,新的Decoder生成音频Token。
- 按文本Token粒度交错对应音频。
具体细节就不一一展开了,简单示例如下:
1 | # 旧 |
假设T1为输入,T2为输出,则输入的T1=A+VocabSize,即扩充后的Index,输出的T2就是Text Token。也就是说,只需把语义Token扩充到词表即可,无需扩充声学Token。
Voila核心逻辑
这里从代码实现角度简单介绍Voila的核心(推理)逻辑。
音频4个码本都扩充进词表,而不是只有语义部分。因为它是用一个Decoder解码文本+语音Token。
重点是文本的Token也扩充到音频的码本大小维度,前面已经提到过了,输入大概是这样的:
1 | T1 T2 T3 A11 A12 A13 A14 A15 |
当然,实际是交错的,一个Text Token对应多个音频Token。
支持 aiao、tito,asr和tts,a是Audio,t是Text。主要是输入,需要区分带音频和不带音频的情况(因为要做拼接处理),输出就交给模型了。
所以无论是哪种类型的输入,输入大小为:(B, L, num_codebooks),然后进来后需要Embedding:
1 | inputs_embeds = self.model.embed_tokens(input_ids) |
这一步,input_ids里面不管是文本+语音,还是单模态,这里都取了平均。如果是纯文本,那等价于输入还是一维;如果是音频,那就是num_codebooks个码本上对应的Embedding取平均。
接下来进去的是LLM,其实可以把音频的Embedding平均看成是对应的文本Embedding,这里的Embedding一般是用Whisper之类的模型,论文直接用简单的Lookup Embedding。当然,它还有一个alpha版本,就是除了Embedding,还加上了音频的(语义)特征,其实就是Word2Vec的特征抽取器。如下所示:
1 | audio_embeds = self.feature_extractor(audio_datas) |
不过个人对此Adapter类做法无感,这不就等于做了一次ASR么……
LLM输出的大小是(B, L, hidden_dim),生成时,L=1。这个输入会传给音频Decoder,这个是Fish的实现逻辑。简单来说,对每个输入,生成num_codebooks个音频Token,大小为:(B, 1, num_codebooks),当然所有生成的结果就是(B, L, num_codebooks)。
这个生成的结果是文本和语音是相互交错的,大概长这样:
1 | [[128390, 131874, 134240, 136020], |
后面这同时2个Token其实是一个中文的词语,我们把这3个字解码出来就是:
1 | tokenizer.decode([88126, 108263, 23897]) == "您 可以" |
中间的108263就是” 可“(注意带空格的),说明模型训练时中文语料是分词了的。
还有一个是参考音频的问题,这里做法比较简单,直接通过另一个模型获取Embedding,然后padding后加到inputs_embeds上。注意,这里只有第一次带上下文输入时才会加,逐Token时就不加了。
1 | ref_embs = self.ref_emb_linear(ref_embs.to(self.ref_emb_linear.weight.dtype)) |
这意味着你可以在输入时ZeroShot一个音色,这一模式适用于chat、双工、TTS等。
小结
本文通过Voila[11]介绍了OMNI相关的进展和个人看法,总的来说,这篇论文的设计还是比较有意思的,而且也不复杂。OMNI目前虽然可能不太好应用在真实场景下,但作为一个前沿方向还是非常不错的,看着这么多五花八门的设计也是大开眼界。另外,本文开头也说了,2025年是Agent、语音元年,VoiceAgent类产品已经冒出来很多了,接下来只会更加火热,个人还是比较看好这个方向,值得期待。
References
[1] Voila: https://github.com/maitrix-org/Voila
[2] 看看: https://github.com/ga642381/speech-trident?tab=readme-ov-file#trident-speechaudio-codec-models
[3] 实时语音交互场景下RAG的机遇和挑战 | Yam: https://yam.gift/2025/01/05/MM/2025-01-05-RAG-and-Voice-Agent/
[4] Hello GPT-4o | OpenAI: https://openai.com/index/hello-gpt-4o/
[5] 推出: https://platform.openai.com/docs/guides/voice-agents
[6] OMNI论文速览(2024) | Yam: https://yam.gift/2024/12/31/Paper/MM/2024-12-31-OMNI-Papers-2024/
[7] OMNI论文速览(2025) | Yam: https://yam.gift/2025/03/08/Paper/MM/2025-03-08-OMNI-Papers-2025/
[8] GLM-4-Voice: https://arxiv.org/abs/2412.02612
[9] Moshi: https://arxiv.org/abs/2410.00037
[10] Fish: https://github.com/fishaudio/fish-speech
[11] Voila: https://arxiv.org/abs/2505.02707