过完年上班后开始关注R1,然后就开始尝试做一些实验,2月底到3月中旬陆陆续续做了不少实验,一直没时间整理,终于抽出点空来简单整理一下,做个记录。
首先,项目是基于Logic-RL[1],之所以选择这个项目有几个主要原因:
- 当时这个复现感觉相对比较规范,飞书文档上记录了一些过程和评测结果(当时其实已经有不少复现了,但很多都没有评测,这种一概略过了)。
- 实在不想看数学的英文,一个是数学本来也不太好,另一个是很多公式在代码里就没法看,不好看Case。这个是逻辑题目,以自然语言文本为主。
- 这个项目基于verl[2]和TinyZero[3],仅做了很少的改动,而verl和TinyZero我之前都了解过,相对比较熟悉。这样上手就比较方便。
所以,R1-Zero相关的实验就都基于这个项目了。因为我的关注点和原项目不同,我更加想验证一些自己的想法(原项目未涉及),所以就另外起了个名字:Yarz-Logic,Yarz就是Yet Another R1-Zero。
基本配置
大部分实验都是在Qwen系列的7B模型上进行的,但同时也涉及到其他模型。所有实验用到的对比模型包括:
- Qwen2.5-7B-Instruct/Base
- Qwen1.5-7B-Base
- Qwen2.5-Math-1.5B-Base
- Qwen2.5-3B-Base
- LLaMA3.1-8B-Base
数据集主要是KK[4]的3ppl(该数据集包含从2ppl到8ppl共7个子集,简单来说就是从易到难)和c3[5],大部分实验都是围绕KK数据集的,c3只是为了进一步验证。所有数据集均为900条训练,100条测试。
数据集示例如下:
1 | # kk |
KK数据集的模板如下:
1 | # Base |
c3数据集的模板如下:
1 | # Base |
调整的参数比较简单,主要包括:
- rollout.n
- Prompt、Response Length
简单复现
调整Reward
当时看了复现后,觉得“所有的都对得1分,只要一个错得0分”有点过于严格,于是将其核心改为:“对1个+0.5分,错1个扣0.5分,全对额外加0.5分”,模型依然是Qwen2.5-7B-Instruct,rollout.n=8,prompt_len=400,response_len=2048。
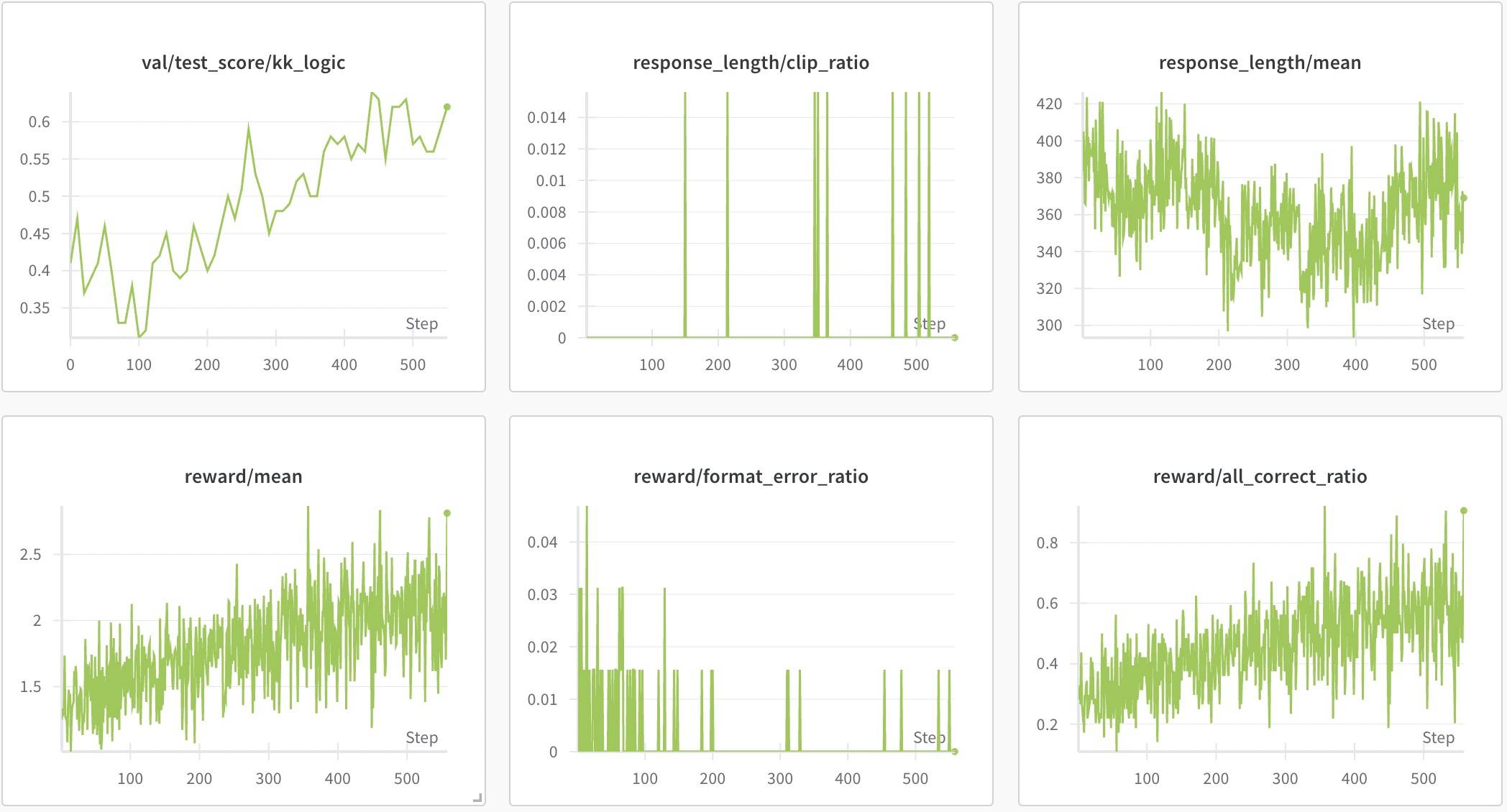
结果如图所示,先看第一排:左边是测试集Acc——所有人身份全对该样本才算对,中间的是回复截断比例,右边是回复长度;然后是第二排:左边是Reward,中间是格式错误的比例,右边是正确的比例(即训练集的Acc)。所有实验的图例均一致,后面不再赘述。
可以明显看到Reward和Acc在一路上升,格式错误率在下降,回复长度则呈现出先降后升的趋势,这和很多实验结果是一致的。观察日志发现,其实在50步前就已经出现了类似verify、rechecking之类的自我反思词汇,之后也会一直存在。
不过,遗憾的是,这样的调整其实并没有作用,不调整reward的结果是这样的:
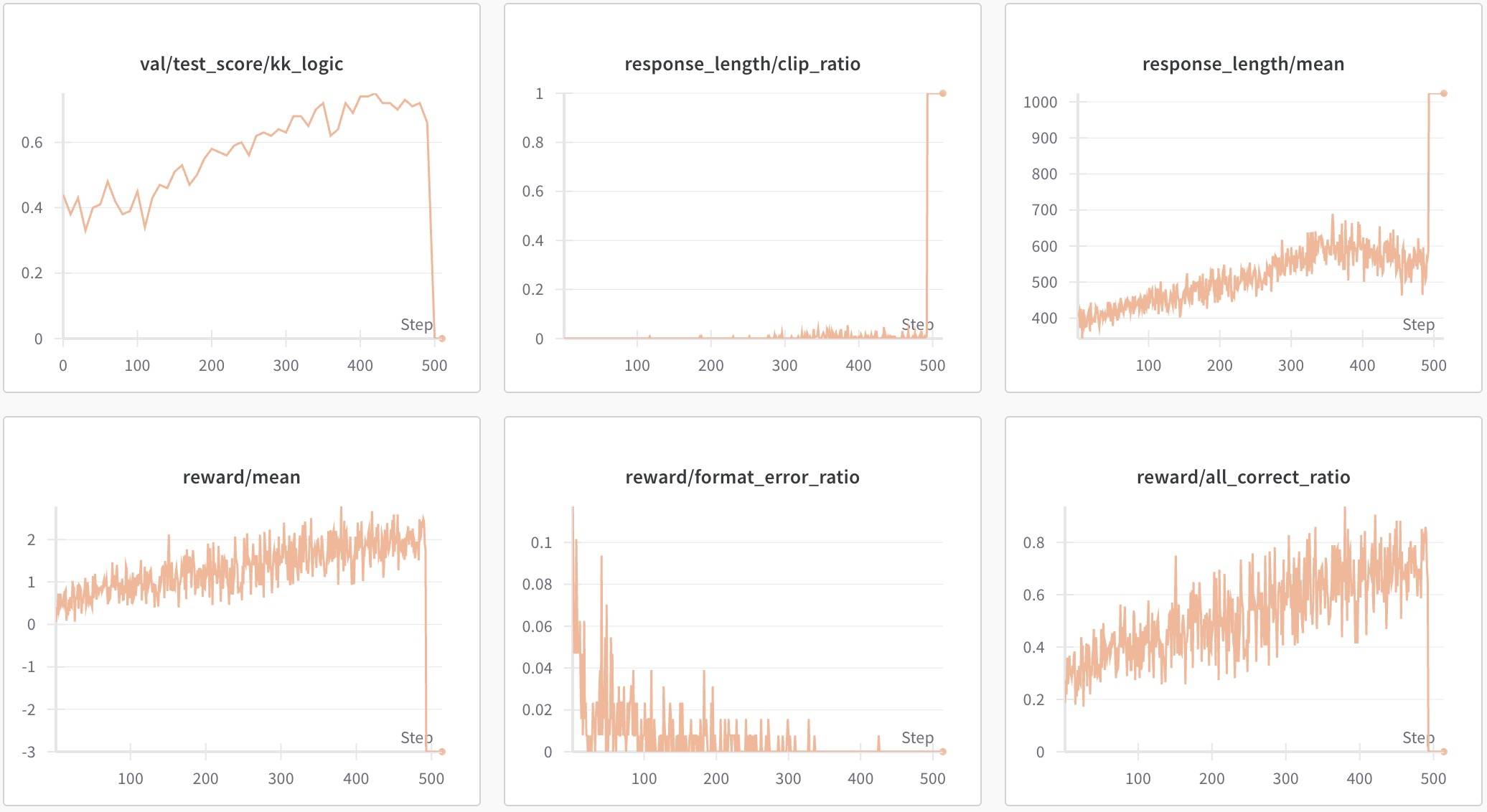
虽然最后崩了,但整个过程其实是没问题的,测试集Acc要高出不少。为什么这样调整reward没效果?我在VAPO:基于价值方法的新突破 | Yam[6]中《验证任务奖励稀疏性》一节有提到过,其关键是验证集Acc的计算标准是“全部对”,意味着“部分结果对给奖励”的奖励方式对最终结果并没有意义。这里真正需要的应该是“过程验证和奖励”,也就是R1-VL[7]提的StepGRPO——step-wise reward,感兴趣的读者可以在《附录》中查看。另外,我们也可以看到,虽然修改后的reward在Instruct版本上性能不如修改前的,但在Base模型上两者其实并没有区别,测试集Acc一路基本在一个水平上。
难度Scaling
接下来在上面基础上将难度从3ppl增加到5ppl,相应配置组如下调整:
- rollout.n: 8->16
- Prompt length: 400->500
- Response length: 2048->4096
同时,对reward(还是调整后的reward)也进行了相应调整
- Format reward: 1 -> 0.8
- No answer: 2.5 -> 3.5
这里由于模型结束Token配置有误,回复长度暴增,而且后面全是eos token,将其添加到stop_token_ids后问题解决。
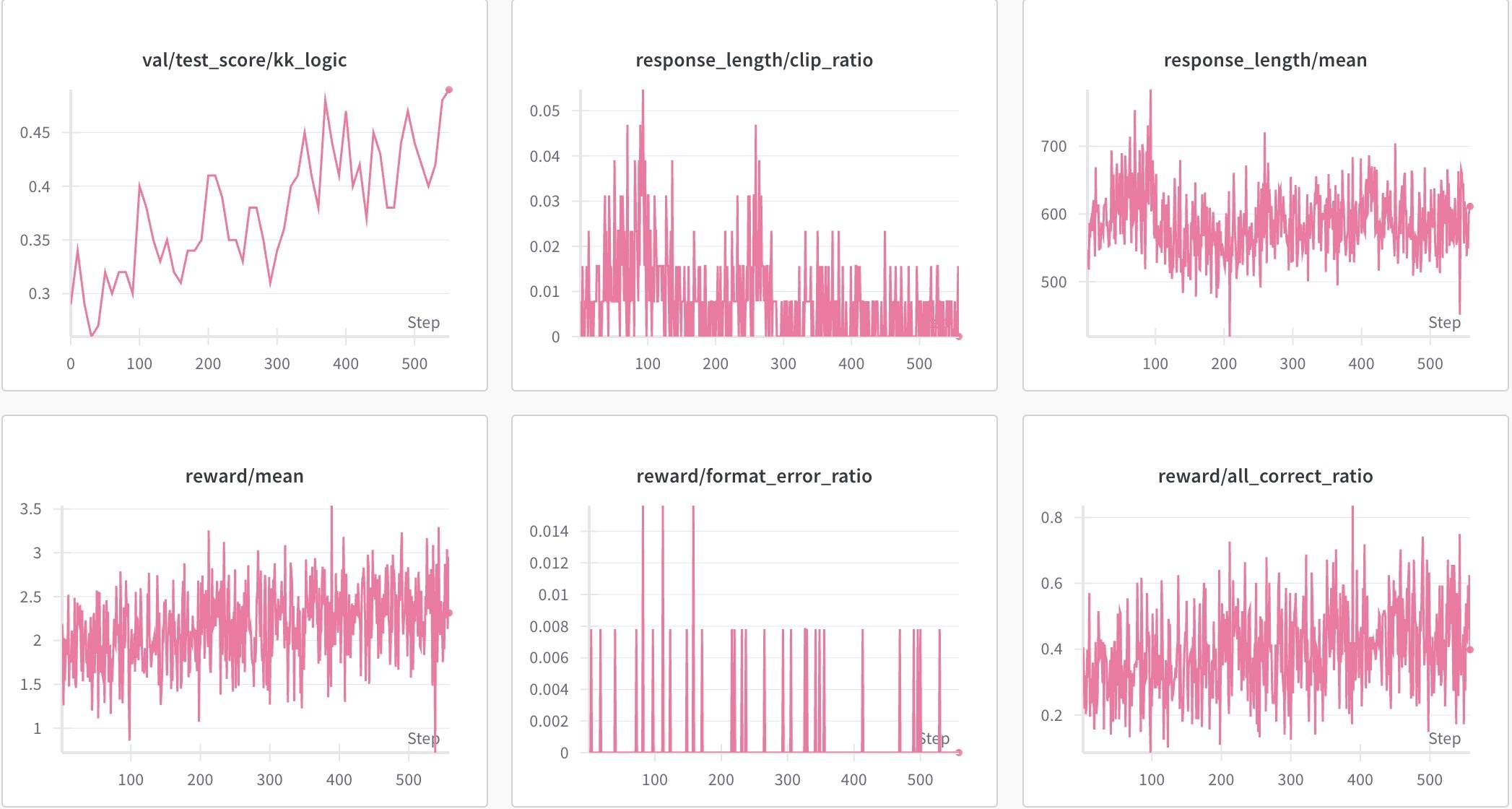
整体趋势和之前差不多,不过性能在下降,毕竟难度增加了。另外,回复长度增加趋势不明显,但整体长度比3ppl有明显提升。虽然在5ppl上测试集Acc不如之前,但在3ppl上达到了0.64,比之前的0.62提升了2个点。
至此,简单的复现基本结束,得到的结论和当时已有的论文一致(部分可见:DeepSeek R1深度技术解析及其影响 | Yam[8])。后面就是在3ppl上进一步验证自己当时的一些设想。
进一步验证
这一章主要验证当初的一些想法,依然是在调整后的reward基础上进行(因为用Logic-RL原始reward的方式是我后面补的:D)。
Base模型
第一个就是Base模型(选择Qwen2.5-7B-Base)。现在大家都已经知道关键在Base模型,但当时还没有这么明确。不过大部分从业人员应该有这个判断了,我自己也是如此,所以就验证了一下。相应配置如下:
- rollout.n: 8
- Prompt length: 400
- Response length: 2048
前几次都崩了,一开始还以为是参数的问题,调整了rollout.n和temperature依然崩。后来发现后面很多pad token,于是将pad token添加到stop_token_ids。另外,又想起DeepScaleR里说的:“错误响应的长度是正确响应的3倍,表明较长的响应通常会导致不正确的结果,直接用长上下文窗口进行训练可能效率低下”,于是将Response Length调整到1024。后面的配置基本都是遵循这个。
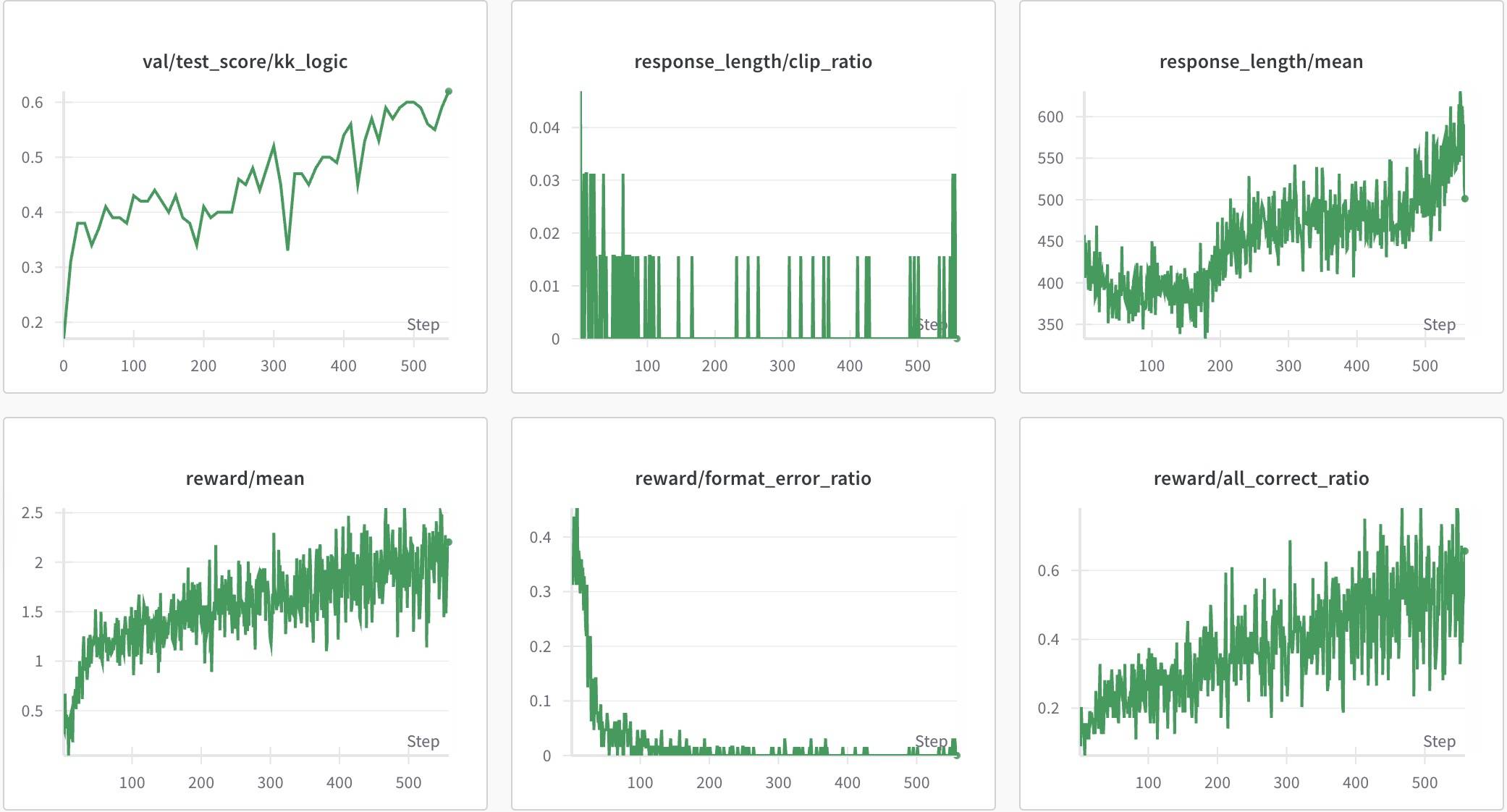
最后的Acc和Instruct版本一样,其他指标趋势也差不多。区别比较明显的是回复长度,虽然也是先降后升,但上升的幅度明显,更加符合预期。放在一起对比一下更加明显。
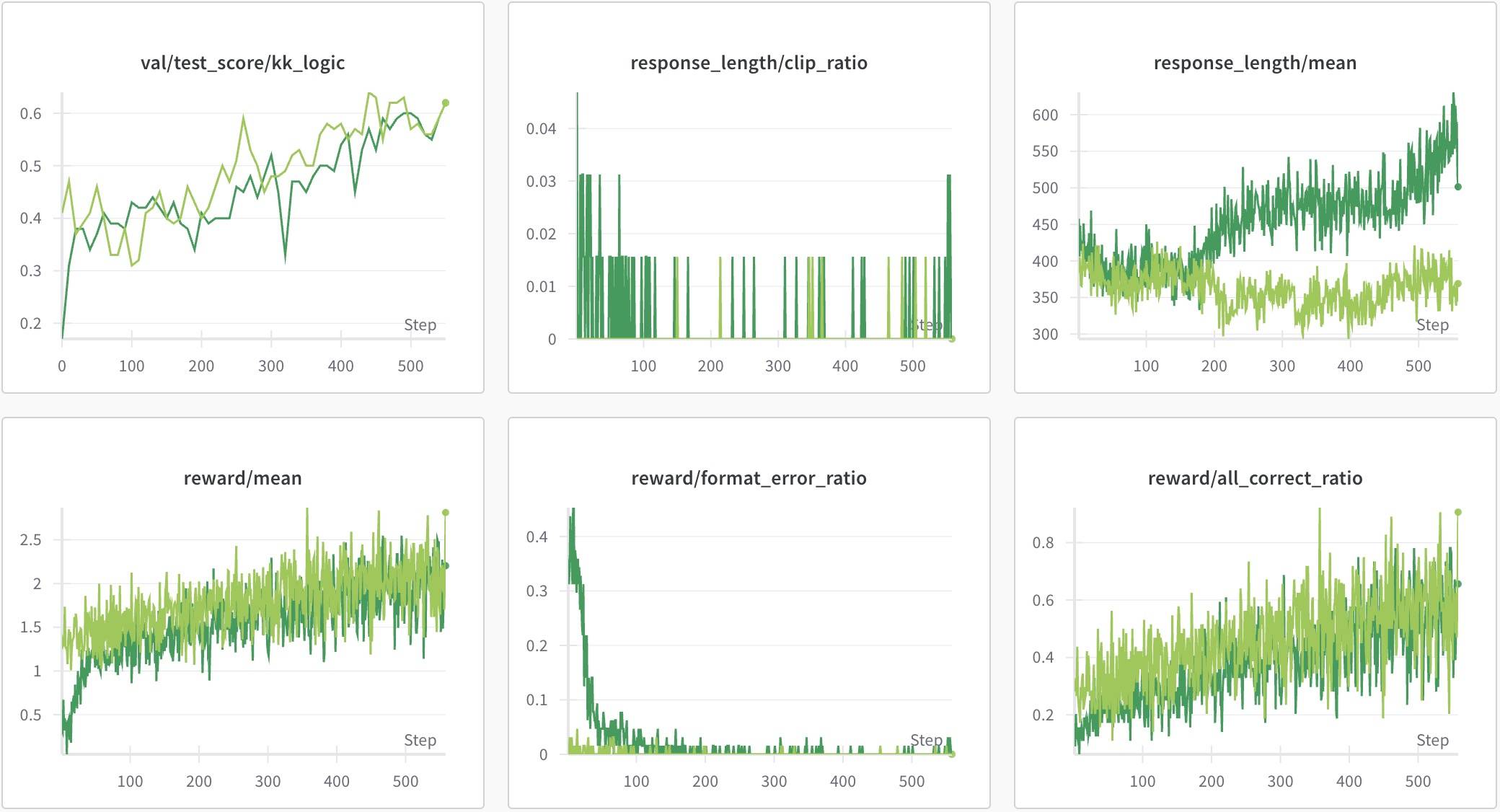
不同系列
接下来要验证的就是只要Base模型具备推理能力,就都应该能复现。虽然还没做实验,但当时觉得这个认识是正确的。于是选了1.5的Qwen1.5-7B-Base进行验证。
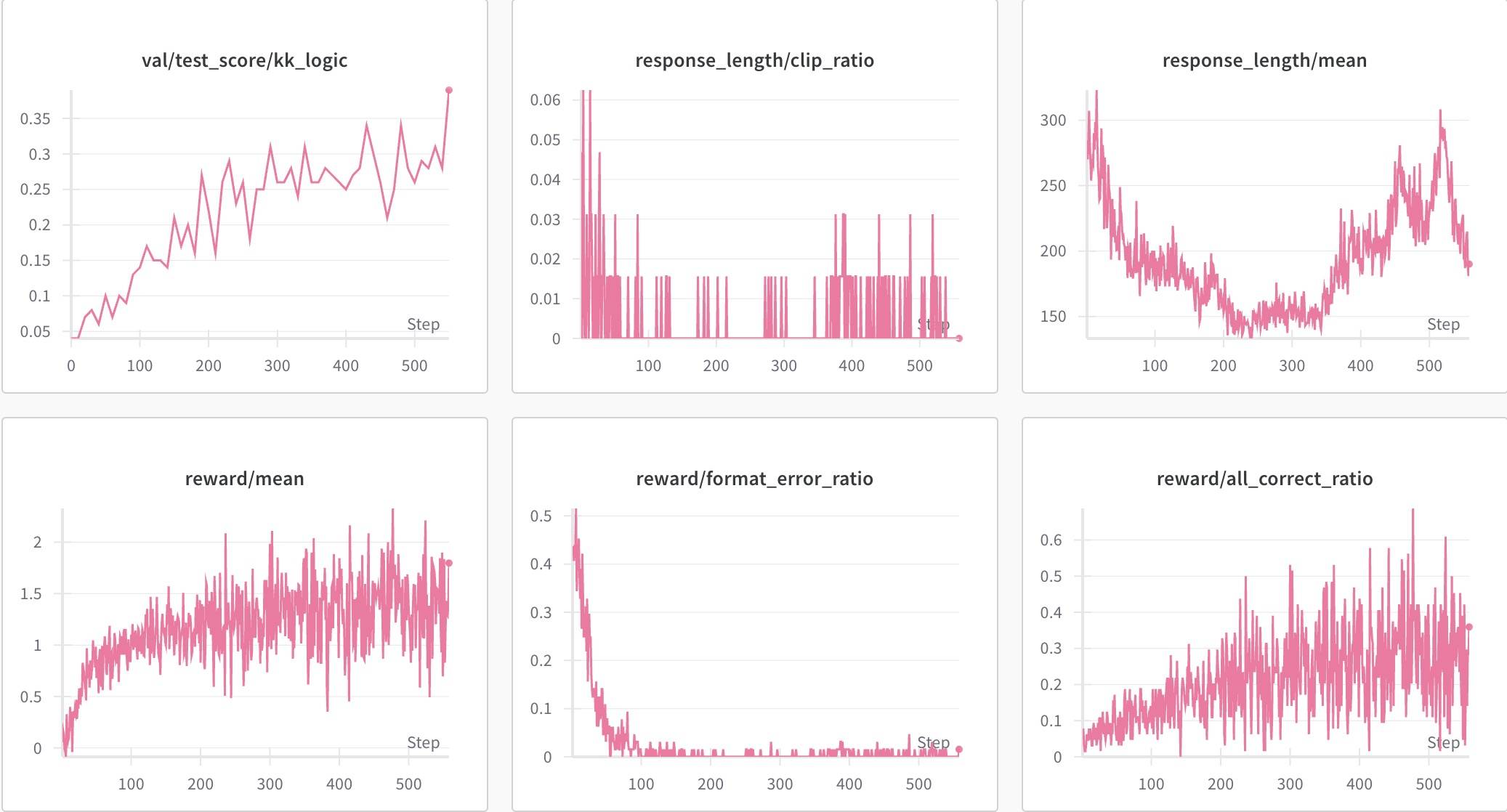
整体趋势差不多,但性能和Qwen2.5-7B-Base差了一个级别,差不多只有2.5的一半多点。还是放在一起对比一下。
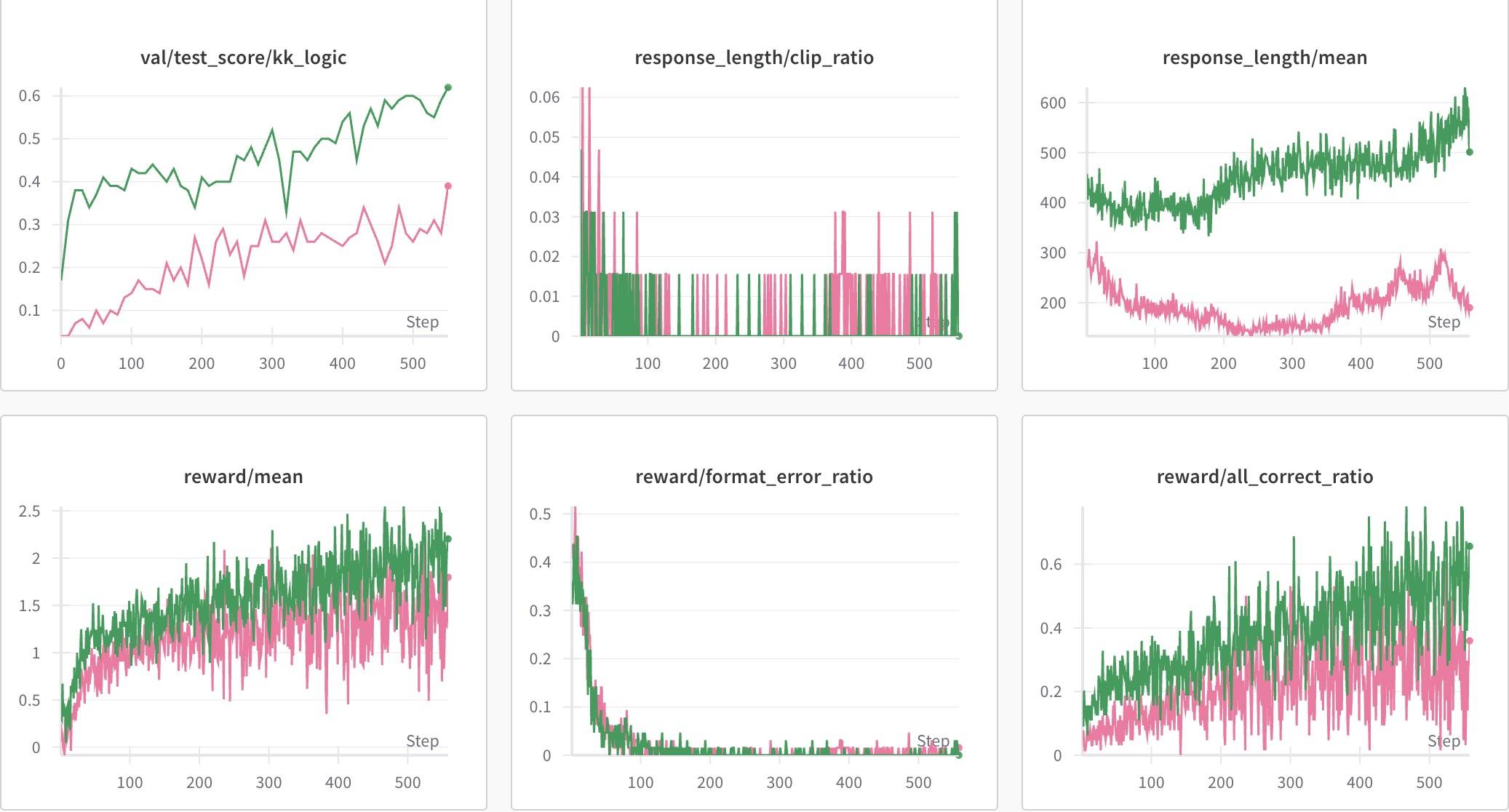
说明Qwen-2.5系列的推理能力得到了很大加强,原因应该就是使用了更多推理类(数学、代码)数据,可见Qwen2.5 Technical Report[9]。
不同Size
再下来要验证的就是不同大小的模型,当时有研究认为3B模型是下限尺寸,于是我先尝试了Qwen2.5-1.5B-Base,回复长度默认1024,后面又补了一组512的,结果如下。
其中,蓝色的是512长度的,最终结果差不多,但回复长度一路下降,可以认为并没有成功复现。但是测试集的Acc绝对提升(差不多30个点)却和Qwen1.5-7B-Base相差不大!
换到Qwen2.5-3B-Base上,整体也差不太多,性能有所提升。不过回复长度呈现出先降后升的趋势。

Math系列
小Size的没有复现是不是因为其本身推理能力比较若呢?于是,新增一组Math系列的,同样是1.5B(Qwen2.5-Math-1.5B)。
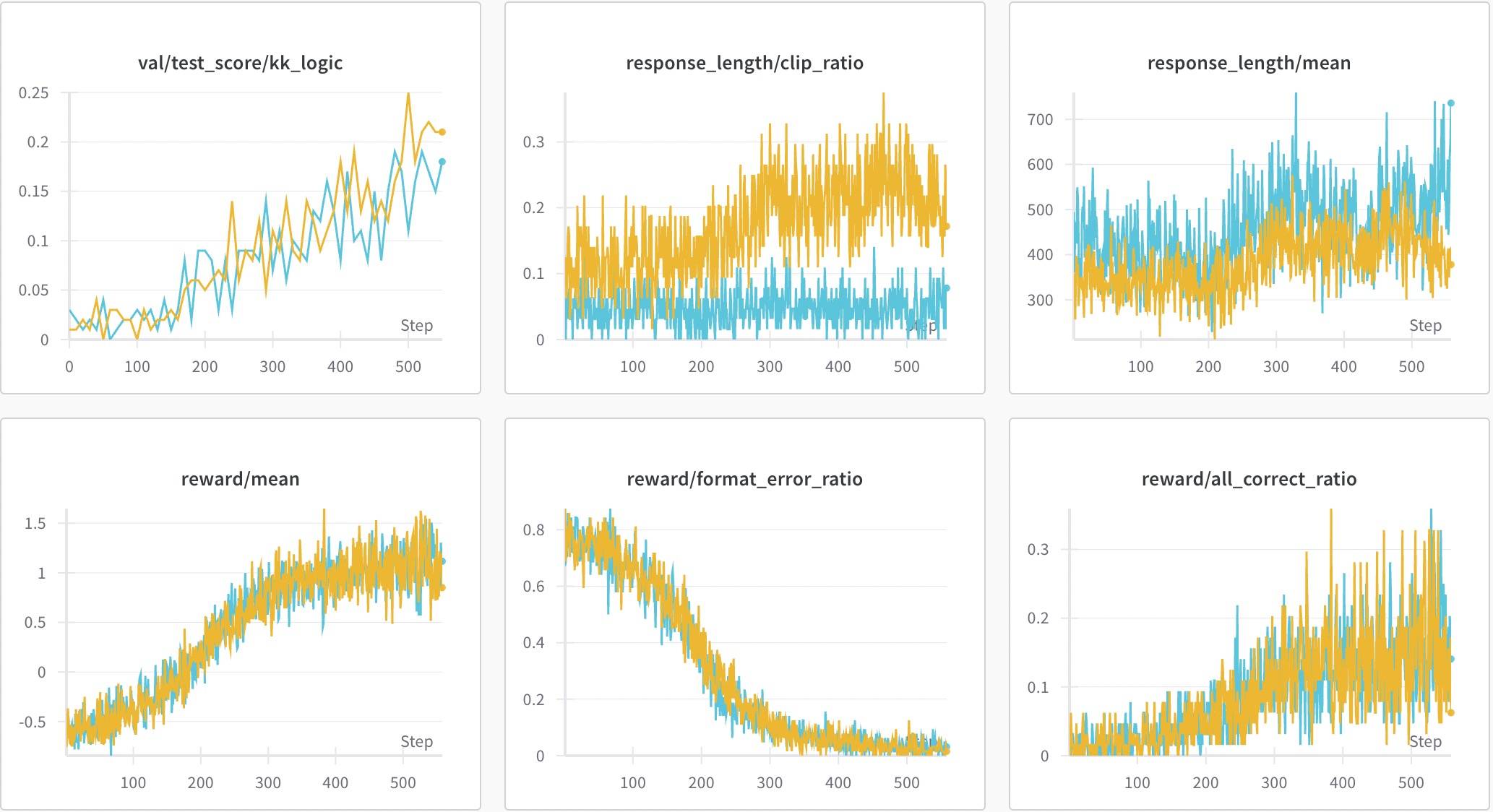
红色的是默认的1024长度,不过观察到clip比例在提高,又补了一组2048长度的,如蓝色所示。两组的趋势差不多,2048的回复长度更长一些(显然),但测试集的Acc却低一些,这也进一步验证了前面提到DeepScaleR的结论——太长的回复通常会导致不正确的结果。这也引发了后续课程学习的探索,比如我们在R1相关:R1-Zero的进一步理解和探索 | Yam[10]中提到的FastCuRL。
同样大小(1.5B)的Math版本比Base看起来更像是想要的结果,不过Acc上却逊色了一些。总体来说,小Size的模型还是弱了一些。
至此,一些初步的验证结束,后续的实验均以Logic-RL原始的reward计算方式进行,即全部正确得分,否则扣分。
其他验证
这一部分实验(除LLaMA外)均以Qwen2.5-7B-Base为Backbone。
RL算法
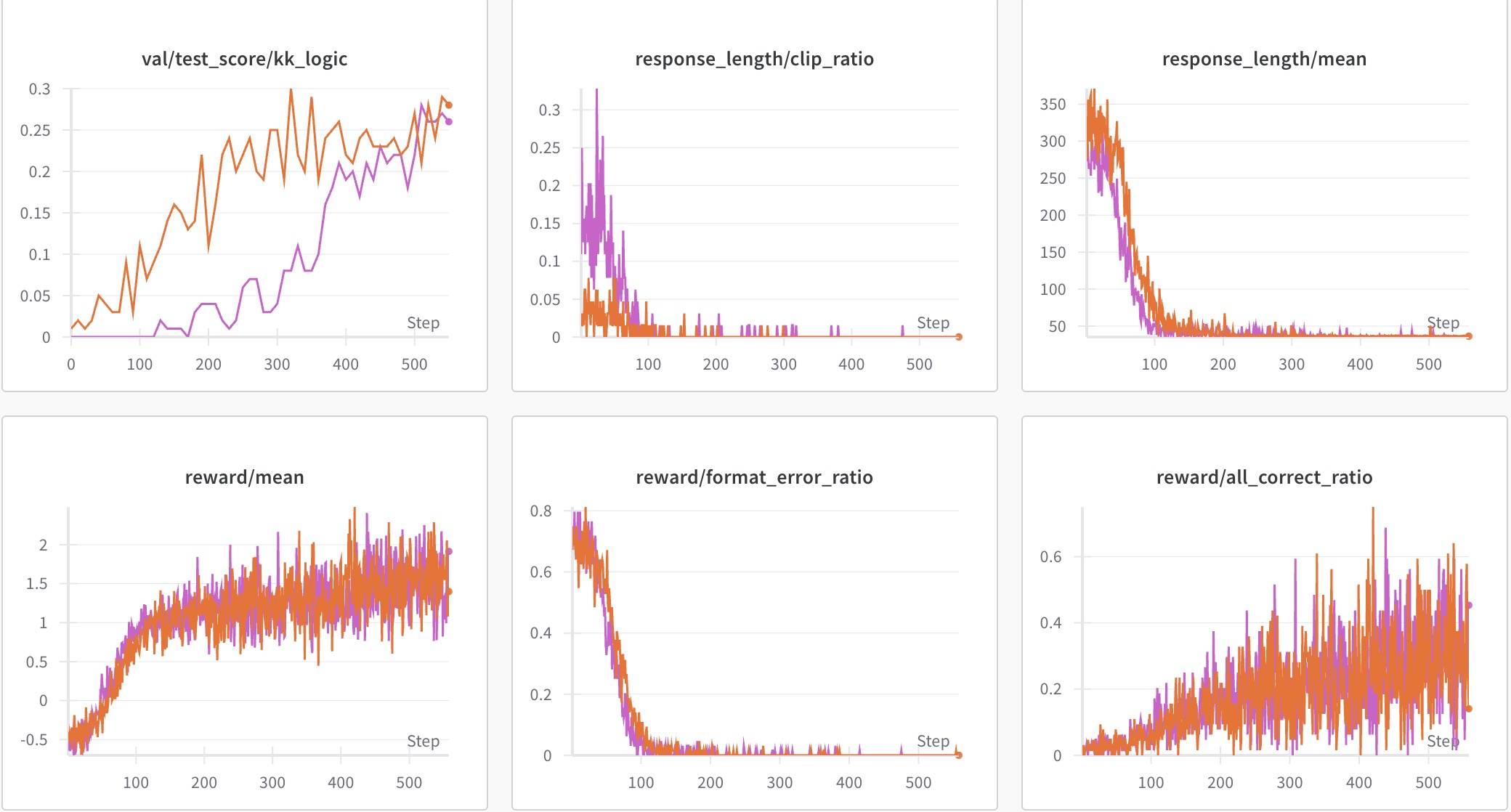
这一部分验证不同的RL算法(主要是reinforce++),以及KL是否会影响结果。模型选择Qwen2.5-7B-Base。
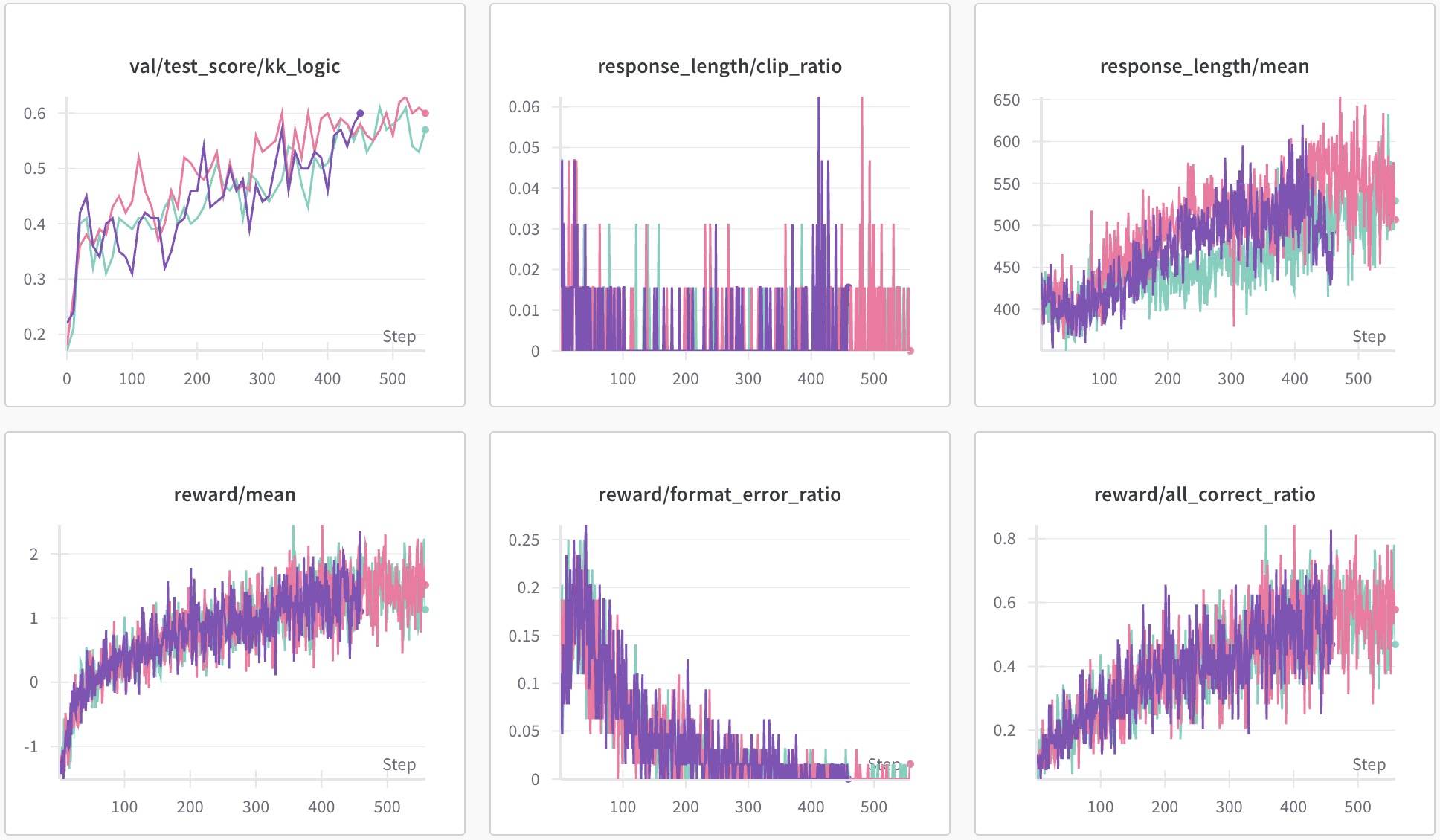
蓝色的是Qwen2.5-7B-Base+GRPO,也是这部分的Base,深一点的红色是reinforce++,淡一点红色的是去掉KL。这个结果不能说区别不大,只能说毫无区别。此结论也与其他研究一致——RL算法不太影响结果,因为核心是Base,大家都是在Base的“约束”下“激活”能力。
通用数据
这里用的是c3数据集,其实是一个意图理解的任务,相比kk肯定是要简单很多的。

测试集初始Acc就有0.9左右,提升幅度不算大。棕色的是基准,也就是Qwen2.5-7B-Base+GRPO,另外两条浅色的是去掉KL的,稍微深一点颜色的是将训练集从900扩到1600的。可以看出,结果基本相差不大,增加数据集能稍稍提升性能。另外,回复长度也是一路下降,当然算不得激活了推理能力。
格式设计
最后是格式方面的实验,因为当时想把这种算法应用在通用领域,所以Instruction肯定是越简单越好,也不需要思考。于是将输入格式调整如下:
1 | The user asks you to solve a logical reasoning problem. List the identity of each person one by one, for example, <answer> (1) Zoey is a knight\n(2) Oliver is a knight\n(3)... </answer>.\n\nUser:{quiz}\nAssistant: |
模型为Qwen2.5-7B-Base+GRPO。
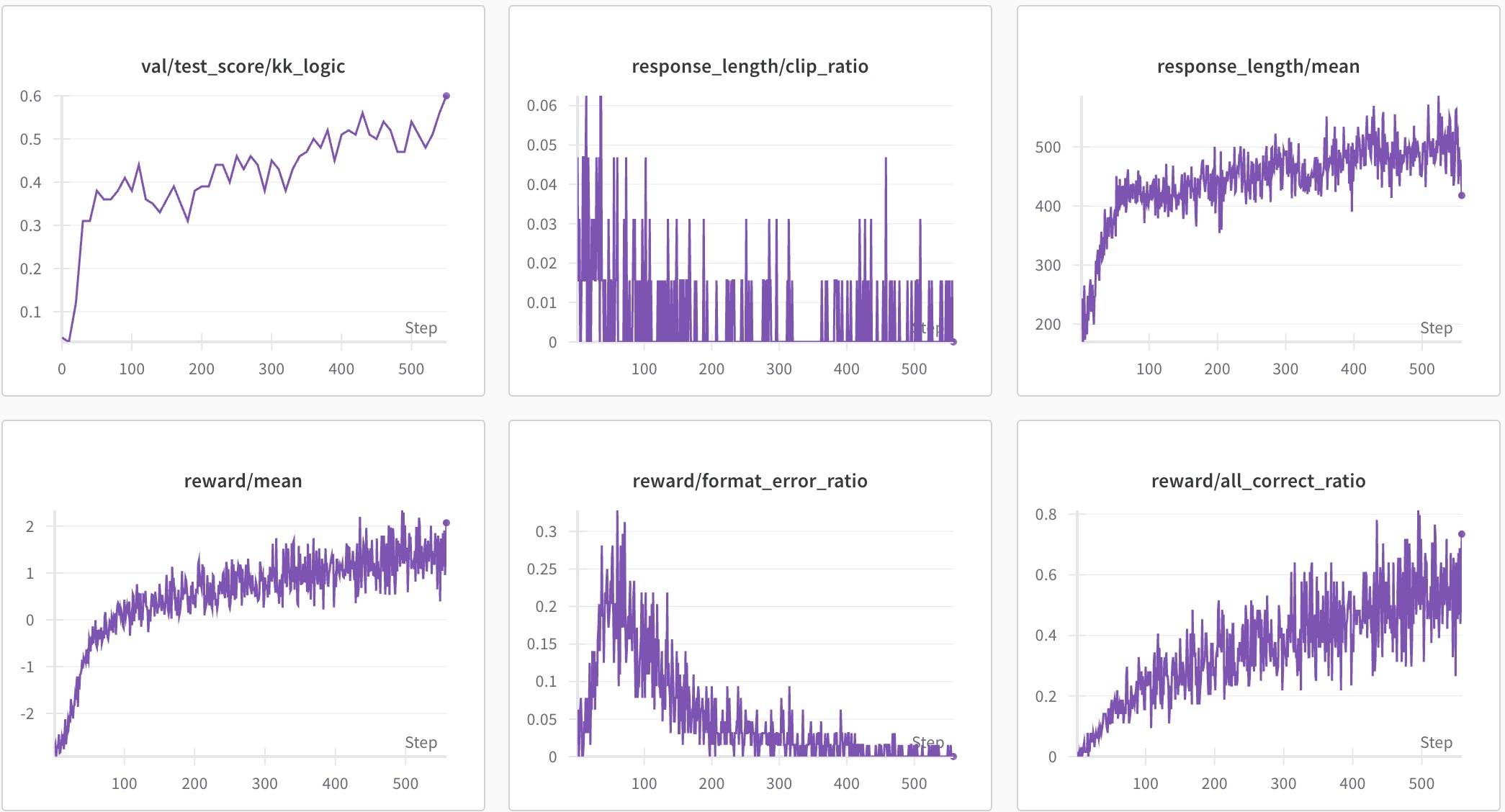
测试集Acc反而比之前更好一些,reward和回复长度也很理想。值得注意的是,模型花了几十步学习到了格式,格式学到后测试集Acc直接接近0.4,进一步训练后超过了0.6。这也进一步说明Qwen2.5-7B-Base本身就具备比较强的推理能力,强化学习可以进一步提升性能。
LLaMA
最后补充一组LLaMA的验证,主要是因为《SimpleRL-Zoo》(可参考R1相关:R1-Zero的进一步理解和探索 | Yam[10])的工作发现LLaMA也可以反思(即Aha),而在此前一般都认为LLaMA系列推理能力较弱。他们的发现如下:
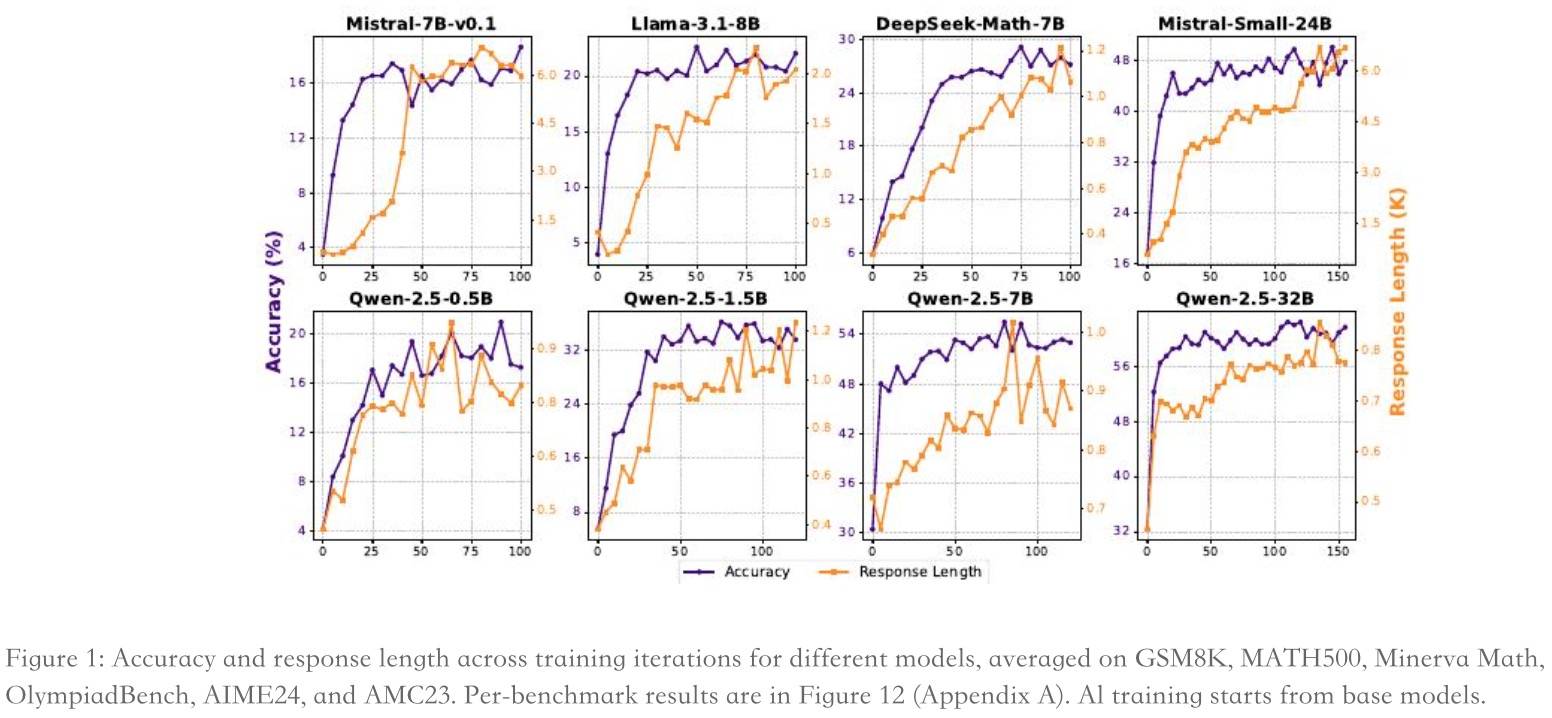
不过这里有个重点是:训练数据的难度必须与Base模型的内在探索能力相匹配,否则训练会失败。嗯,不出意外,LLaMA-3.1-8B在KK 3ppl上验证失败。
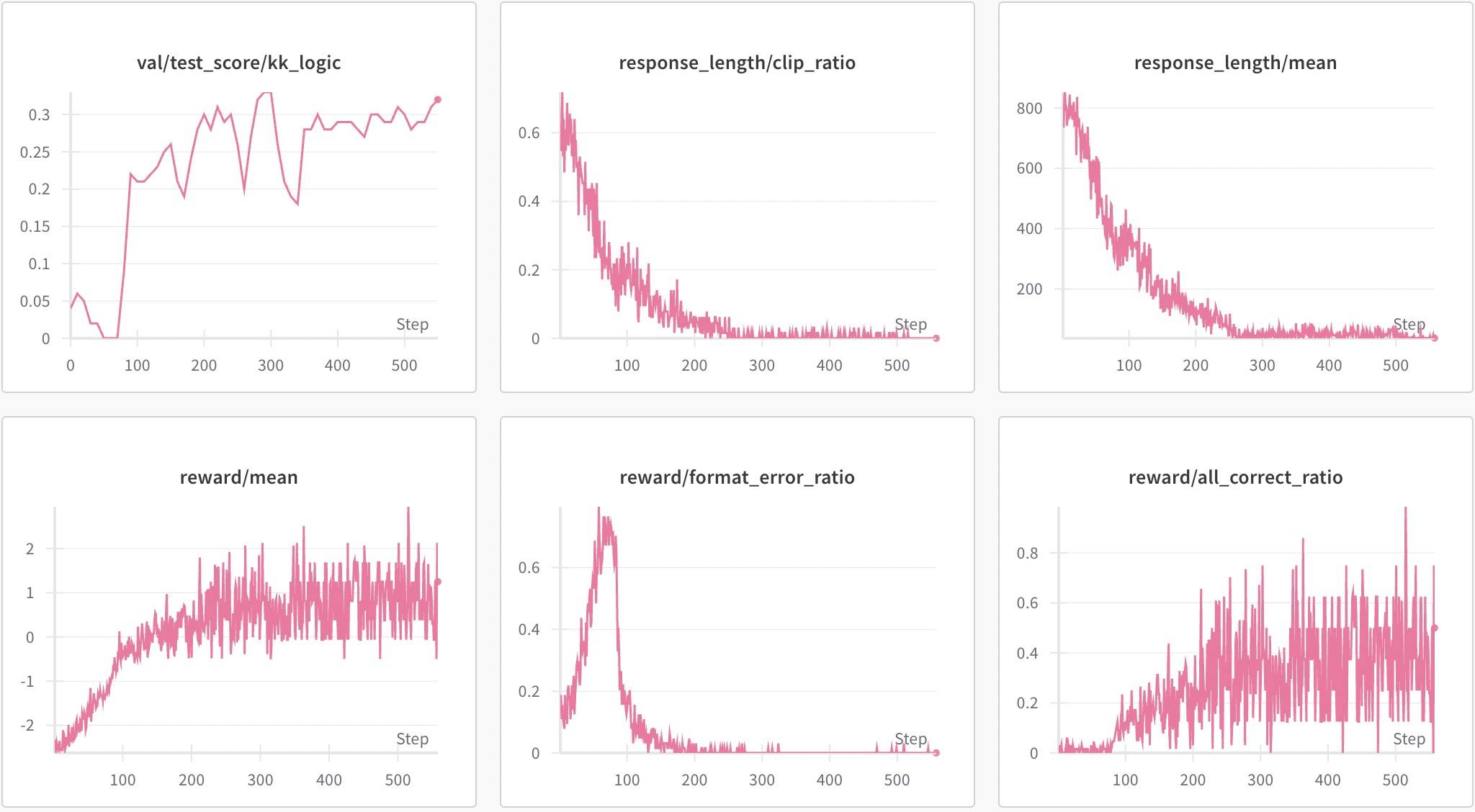
值得注意的是,这里还有一个学习格式的过程,但是Base模型的模板看起来并不特殊,说明LLaMA3.1-8B并没有一开始就“理解”格式。看它reward的起点也可以看出来,比Qwen系列的要低。
小结
本文算是对R1-Zero简单实验后的简单报告,拖了一个多月,总算是抽时间整理了一下。虽然跑了一些实验,但其实都是在验证而已(并没有很多价值),一方面是自己确实非常好奇,想知道是不是设想的那样,另一方面也是一直以来对强化学习的兴趣(在DeepSeek R1深度技术解析及其影响 | Yam[8]中有提到过)。总之,目前除了LLM和NLP,我个人也把大量时间和精力放在了强化和多模态上,尤其是前者,可以通过近期的文章感知到。
实验过程当然不是一帆风顺的,也遭遇过几次训崩的情况,遇到了一些Bug,但总体而言还算比较顺利。一开始本来还想整理成Paper的(这也是为啥拖了这么久),不过同行们实在太快了,看了几篇相关研究后就慢慢息了这念头。但这次实验肯定不是结束,反而是独立研究的开始。
最后附上实验代码:hscspring/Yarz-Logic[11]。另外,24年底建了一个RL+LLM+NLP相关研究收集的库:hscspring/rl-llm-nlp: Reinforcement Learning in LLM and NLP.[12],欢迎关注。
附录
StepGRPO
StepGRPO包括两个阶段:policy warmup和step-wise policy 优化。第一步主要是让策略模型能够生成合适的逐步推理路径,需要相关标注数据训练。
第二步才是真正的算法部分。主要引入2个基于规则的逐步奖励:
- StepRAR(逐步推理精度):
- 对每个Q,使用GPT-4从推理路径抽出一组关键推理步骤。
- 对提取的步骤进行精炼,去除冗余内容,仅保留推理所需的核心少量词语。另外,还将每个提取出的关键步骤扩展为多种等价格式,避免因格式差异导致的匹配遗漏。比如“\frac{6}{3} = 2”写成“6/3 = 2”。
- 计算关键步骤的匹配比例k。
- 根据式(1)计算1 ≤ t ≤ T的StepRAR。
- StepRVR(逐步推理有效性):
- 保证推理路径除了准确外,还遵循逻辑结构清晰、连贯推进的过程。
- 通过两个关键标准来定义 StepRVR:推理完整性(δc)和推理逻辑性(δl)。
- 推理完整性要求包括:背景分析、逐步推理过程以及最终答案。推理逻辑性要求必须按这个顺序出现。
- 任何一个不满足则0分,两个均满足1分。
- 每条推理路径的总体奖励等于两种奖励之和。
StepRAR计算公式如下:
References
[1] Logic-RL: https://github.com/Unakar/Logic-RL
[2] verl: https://github.com/volcengine/verl
[3] TinyZero: https://github.com/Jiayi-Pan/TinyZero
[4] KK: https://huggingface.co/datasets/K-and-K/knights-and-knaves
[5] c3: https://github.com/nlpdata/c3
[6] VAPO:基于价值方法的新突破 | Yam: https://yam.gift/2025/04/19/NLP/LLM-Training/2025-04-19-VAPO/
[7] R1-VL: https://arxiv.org/abs/2503.12937
[8] DeepSeek R1深度技术解析及其影响 | Yam: https://yam.gift/2025/02/17/NLP/LLM-Training/2025-02-17-DeepSeek-R1/
[9] Qwen2.5 Technical Report: https://arxiv.org/pdf/2412.15115
[10] R1相关:R1-Zero的进一步理解和探索 | Yam: https://yam.gift/2025/04/10/NLP/LLM-Training/2025-04-10-Think-More-about-R1-Zero/
[11] hscspring/Yarz-Logic: https://github.com/hscspring/Yarz-Logic
[12] hscspring/rl-llm-nlp: Reinforcement Learning in LLM and NLP.: https://github.com/hscspring/rl-llm-nlp
[13] R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization: https://arxiv.org/abs/2503.12937
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。