DeepSeek-V3.2 发布后,外界讨论大多集中在“新增了工具使用”、“是不是比某某更强”之类的话题。但如果你真正关心模型训练,会发现它最值得研究的地方根本不在模型能力,而是在 后训练(post-training)阶段的一系列稳定性工程。V3.2 不像 V3 带来结构性突破,更像是一次“工程师版本的 V3.2”:没什么光鲜亮丽的大新闻,但每一个小改动都在解决真实训练痛点。
TL;DR
DeepSeek-V3.2 的后训练重点不是“更强”,而是“更稳”。大量技巧围绕 GRPO 稳定性 展开。
- 数据部分:多个领域专用专家 → 生成数据 → 蒸馏到统一模型。
- GRPO 稳定性优化:
- Advantage 去标准差:消除难度偏差,提高样本权重的公平性。
- KL 的无偏修正:基于 K3 + 重要性采样,使 KL 梯度更稳定可靠。
- 序列级 off-policy 掩码:屏蔽高偏差且优势为负的序列,显著提升稳定性。
- MoE 路由保持:固定专家路由,避免 off-policy 和训推框架不同导致的路由漂移。
- 采样保持:保持
π_old与π_θ的动作空间一致,避免采样截断可能带来的稳定性问题。
- 工具使用部分提出更高效的思维轨迹管理方式:只有新用户消息进来才清空工具调用推理轨迹,工具调用历史则始终保留。
DeepSeek-V3.2[1] 正式发布了,功能上来看好像就是增加了工具使用,有人夸有人失望,媒体说什么咱们无需关心,也不做评价。技术人还是认认真真看看其中有没有什么能学到的新技术。关于 DSA 的部分,后面专门说,本文主要说说后训练部分。
专家蒸馏RL
第一个要说的是这个专家蒸馏。针对写作、通用问答、数学、编程、通用逻辑推理、通用agent任务、agentic 编码、agentic 搜索等领域单独训练专用模型,同时支持思考/非思考模式。训练完后用这些模型生成数据,是典型的数据蒸馏,和 R1 的思路一样的。好是好,就是比较费钱。
然后就是 GRPO,推理、agent、对齐一步完成。对于推理类与 Agent 类任务,使用基于规则的结果奖励、长度惩罚以及语言一致性奖励;对于通用类任务,使用生成式奖励模型,并为每个 prompt 提供其对应的评估细则(rubrics)。应该和我们在《Reward Model建模 | 长琴[2]》中介绍过的 DeepSeek-GRM[3] 有一定关系。
上面训练完就是 DeepSeek-V3.2,可以看到,数据部分很重,训练尽量精简。DeepSeek-V3.2-Speciale 是一个变体,在强化学习阶段仅使用推理类数据进行训练,并降低了长度惩罚,另外还引入了 DeepSeekMath-V2[4] 中的数据集和奖励方法。
GRPO优化
接下来要看的是一些 GRPO 算法的优化。
Advantage计算
首先可以看到,advantage 的计算中去掉了分母的标准差,这是异曲同工之妙的DrGRPO——DAPO几乎同时出现的又一GRPO优化! | 长琴[5] 的做法,DrGRPO 去掉标准针对的是“问题难度级别偏差”,因为标准差较低的问题(例如,太简单或太困难的问题,结果奖励几乎全为 1 或 0)在策略更新时会被赋予更高的权重。问题级归一化导致不同问题在目标函数中的权重不同,从而在优化过程中产生了难度偏差。而我们当时也提到,其实 DAPO[6] 也有类似发现,但它的策略是“动态采样”:去掉了准确度为1和0的样本,因为一个提示词的一组输出都是1或0时,advantage直接为0了,没意义。
KL估计
第一眼看到就想到了《Reinforce++和它的KL Loss选择 | 长琴[7]》,在这篇文章里,我们借助 Reinforce++ 讨论了几种 KL 的估计。文中提到,K3 是无偏的但其梯度估计依然存在偏差,其实际上是 k2 梯度的线性近似。不过这里说的 K3 有偏和公式中的重要性系数有关,在谈这个之前,我们先看看 K3 估计器。
我们知道,KL 定义如下,
K3 估计器如下:
注意,式子(1)和(2)在数学上其实是等价的,
式(2)就变成了,
这其实是个恒等式(废话,本来就是构造的)。那为啥要把式(1)重写成式(2)呢?其实在 Approximating KL Divergence[8] 这篇文章我们可以了解到,式(2)是既无偏又方差较低的 KL(K3)估计量。因为对式(1),如果 π_θ 和 π_ref 差别大时,π_θ/π_ref 可能非常大或非常小,导致高方差、训练不稳定。
我们从梯度方面再来看一下。它们两者虽然期望相同,但梯度却不同。
先看标准 KL 式(1)的梯度,
而式(2)K3 的梯度,
和式(1)的梯度只差了一个 “+1”。但是我们看到,式(2)在 π_θ≈π_ref 时接近 0,其导数式(6)也为 0,这能使优化更稳定。
另外,从表达式方面看,式(2)也有更好的数值性质,它不仅在策略比例接近时值为 0,而且它的值本身恒大于等于0,
当 r→0 时,π_θ 远大于 π_ref,g® 是对数级变化的;当 r→∞时,π_θ 远小于 π_ref,虽然是线性增长,但通常在策略更新中我们会避免让 π_θ 太小(clip、KL 惩罚等),所以实际训练中更关注 r→0 的情况。总的来说使用 g® 肯定比直接用 r 更平缓、更可控,更适合优化。
好了,回到本文的优化,它针对的其实是,我们无法直接从正在优化的新策略 π_θ 中采样,只能从 π_old 采样,这就有偏了。而在 K3 基础上,乘上重要性采样权重 π_θ / π_old,就把期望从 π_old “转移”到了 π_θ。
如果对它求导,可以得到,
注意,根据对数求导公式,有:
∇θ π_θ = π_θ ⋅ ∇θlog π_θ∇θ log(π_ref / π_θ) = −∇θlog π_θ
式(9)比式(6)和式(8)比式(2)一样,正好多了个修正的采样权重。
通过这个调整,KL 估计器的梯度变得无偏。这与原始的 K3 估计器形成鲜明对比,尤其是在采样到的 token 在当前策略下的概率远低于参考策略时(即 πθ ≪ πref)。此时,原始的 K3 估计器的梯度会对这些 token 施加比较大的权重,使优化器过度关注这些样本并试图极度拟合它们的 log-likelihood(即使方向可能是负的),这导致训练被噪声 sample 主导,从而不稳定。这些噪声会不断累积,最终损害后续迭代中的样本质量,并导致整个训练不稳定。
另外,文章发现不同领域需要不同强度的 KL 正则化。对于某些领域(例如数学),施加较弱的 KL 惩罚,甚至完全移除 KL,反而能带来更好的性能。
最后再补充一点策略优化的不对称性。我们刚刚提到了 πθ ≪ πref,而没有说 πθ ≫ πref,是因为在实际 RL 训练的上下文中它们的影响和发生频率有显著差异:
πθ ≪ πref:πref认为某个动作相对常见,但πθ认为罕见,样本噪声大。尽管概率小,但它们比值在 K3 梯度中的贡献是个巨大的负数,这会导致不合理的惩罚。这个方向是”破坏性“的,试图过度拟合一个极不可能的样本。方差极高,而且方向是强迫策略向罕见方向移动,导致训练崩溃。πθ ≫ πref:πθ认为某个动作相对常见,概率很高,经常会被采到,样本质量相对可靠,梯度项是巨大的正数。由于 K3 是惩罚项,这个巨大的正梯度会极大地惩罚提高策略概率的行为,并将其推回πref的方向(降低πθ)。虽然是高方差,但这个方向是 “相对保守” 的,因为它在执行惩罚,尝试将策略拉回来。
序列Mask
其实之前我们也介绍过类似的操作,比如《GRPO优化在继续——CISPO和熵 | 长琴[9]》中,CISPO 引入一个按 token的 mask,控制是否以及在何种条件下应舍弃来自特定token的梯度。再比如《GRPO“第一背锅侠”Token Level X2:GTPO双“T”傍地走 | 长琴[10]》中,为了缓解共享 token 的梯度冲突,有选择地屏蔽参与冲突更新的 token 的梯度贡献。
这里主要是为了稳定训练,因为 GRPO 在 mini-batch 上执行多次梯度更新本质上是 off-policy 的,另外推理时框架一般和训练不同,训推不一致会进一步加剧这种 off-policy 程度。因此,本文会对那些导致策略显著偏离(通过旧策略 π_old 与当前策略 π_θ 之间的 KL 散度度量)的负样本序列进行 mask,将其在训练中忽略,以稳定训练并提升对离策略更新的容忍度。
如下所示,
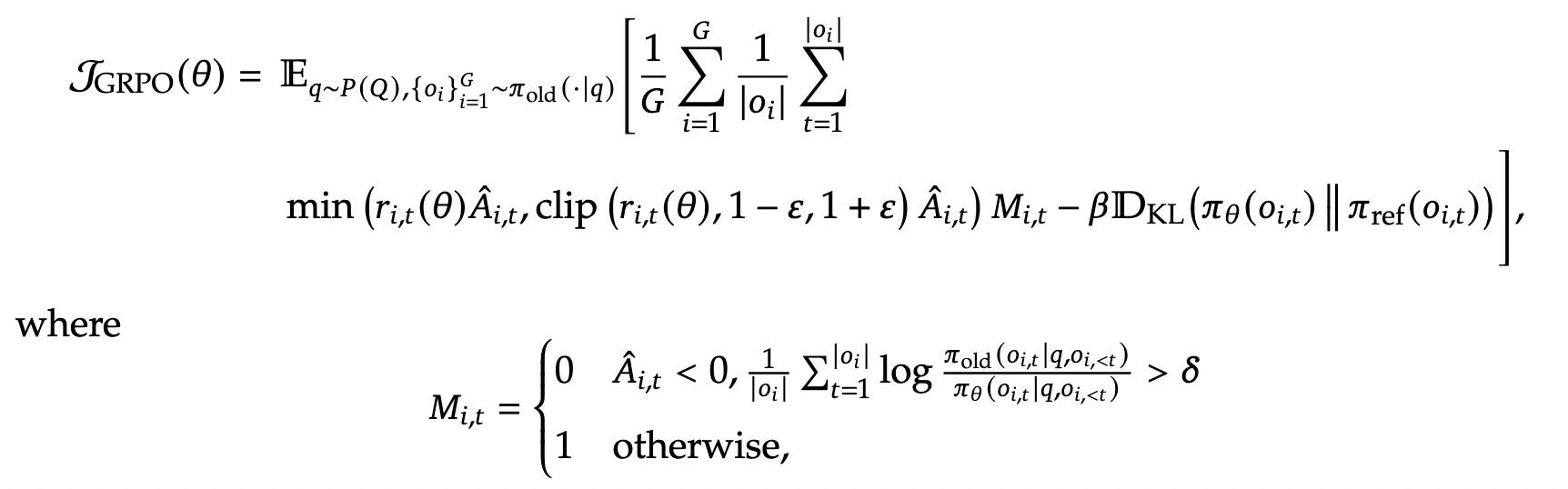
损失中多了一个 Mt。δ 是控制策略偏差阈值的超参数。这里的 π_old 指推理框架直接返回的采样概率,因此旧策略与当前策略之间的 KL 同时反映了上述两类 off-policy。
另外,只对具有负优势的序列进行掩码。直观来说,模型从自己的错误中学习时获益最大,但如果这些负样本高度 off-policy,它们反而会造成伤害,可能误导或破坏优化过程的稳定性。实验结果表明,这一操作明显提升了训练稳定性。
MoE路由保持
主要针对 MoE 架构,由于推理框架与训练框架之间存在差异,再加上策略更新的影响,即使输入相同,推理和训练过程中的专家路由也可能不一致。这种不一致会导致活跃参数子空间的突变,从而破坏优化稳定性,并加剧 off-policy 问题。
关于这点,我们在《GRPO“第一背锅侠”Token Level X:DAPO/DrGRPO与GSPO/GMPO的殊途同归 | 长琴[11]》中 GSPO 那里也看到过,当时的解决策略就是 GSPO,或者说稳定 MoE 是 GSPO 的一个正向副作用。具体来说,GSPO 仅关注序列级的似然(πθ(yi|x)),对单个 token 的似然(πθ(yi,t|x, yi,<t))不敏感。由于 MoE 模型始终保持其语言建模能力,序列级的似然不会出现剧烈波动。个人觉得这个方案很漂亮。
这里的解决方案比较粗暴,直接在推理框架中保留采样时使用的专家路由路径,并在训练阶段强制使用相同的路由路径,确保被优化的是同一组专家参数。实验结果表明,这一操作对 MoE 模型的 RL 训练稳定性至关重要。
采样保持
好吧,连采样也要干涉了。Top-p 和 top-k 采样本质上是一种截断策略,能避免采样到那些概率极低、却会被用作优化目标的 token。但会导致 π_old 与 π_θ 的动作空间不一致,使训练变得不稳定。具体来说,rollout 阶段是在某一部分 token 上采样,但更新时却是全局词表。
为了解决这个问题,从 π_old 采样时保留截断掩码,并在训练阶段将这些掩码应用到 π_θ 上。具体来说,就是保证 π_θ 和 π_old 用一模一样的可选 token 列表。实验结果表明,采样保持可以有效保持 RL 训练过程中的语言一致性。
工具使用
这部分我们主要介绍思维链的上下文管理,就是把“思考能力”融入到工具调用(tool-calling)场景中。本文发现,如果直接复刻 DeepSeek-R1 的策略 —— 即在第二轮消息到达时丢弃推理内容 —— 会导致显著的 token 低效。因为这种方式会迫使模型在每一次工具调用后都必须重新推理整个问题。
因此,设计了一套新的上下文管理机制:
- 只有当出现新的用户消息时,才会丢弃历史推理内容。如果追加的消息仅包含工具相关内容(如工具输出),则推理内容会在整个交互中继续保留。
- 删掉推理轨迹时,工具调用的历史和结果仍会被保留在上下文中。
如下图所示,
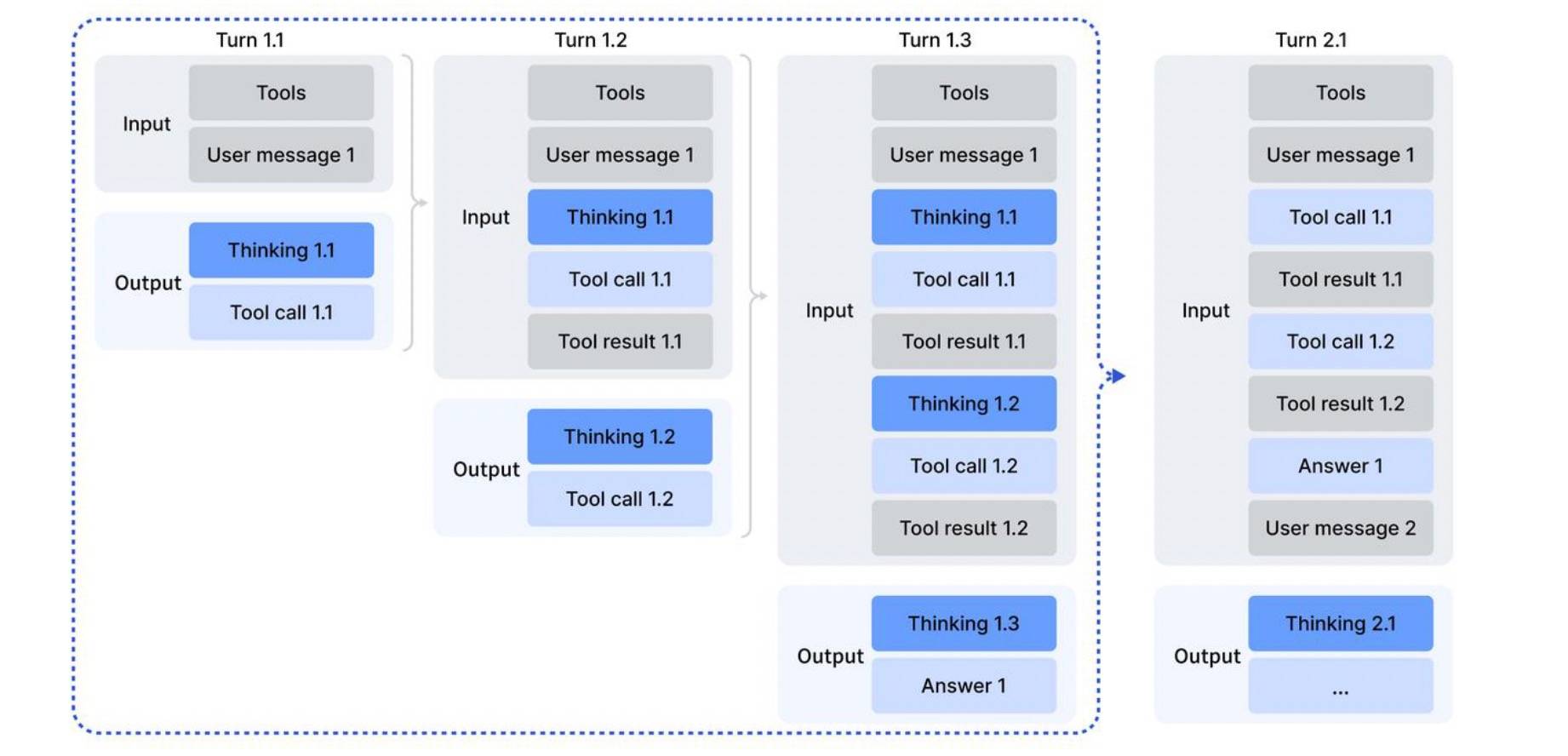
注意看,Trun1.x 因为都是工具输出,所以保留了思考过程,但 Trun2.x 因为有了新的 User message 2,会丢弃推理轨迹,但工具调用历史和结果依然保留。这个设计看起来是比较直观的。
小结
本文我们重点聊了 DeepSeek V3.2 的后训练,虽然没有特别大的创新(毕竟是 V3.2,不是 V4),但细节还是蛮多,尤其是关于 GRPO 稳定性优化方面,所有策略几乎都是为了稳定训练服务。其实我自己在跑训练时也会遇到乱码的情况,不过一般只是稍微调小一丢丢 rollout 的 tempreture,很少从系统层面分析和优化,通过本文也是受益良多。除了 GRPO,我们还简单介绍了数据蒸馏和工具使用的上下文管理。说起来,每个领域专门训一个模型用来生成数据还是挺财大气粗的。
References
[1] DeepSeek-V3.2: https://huggingface.co/deepseek-ai/DeepSeek-V3.2
[2] Reward Model建模 | 长琴: https://yam.gift/2025/06/09/NLP/LLM-Training/2025-06-09-RM-Modeling/
[3] DeepSeek-GRM: https://arxiv.org/abs/2504.02495
[4] DeepSeekMath-V2: https://yam.gift/2025/11/29/NLP/LLM-Training/2025-11-29-Reward-Data-Self-Verified/
[5] 异曲同工之妙的DrGRPO——DAPO几乎同时出现的又一GRPO优化! | 长琴: https://yam.gift/2025/03/28/NLP/LLM-Training/2025-03-28-LLM-PostTrain-DrGRPO/
[6] DAPO: https://yam.gift/2025/03/19/NLP/LLM-Training/2025-03-19-LLM-PostTrain-DAPO/
[7] Reinforce++和它的KL Loss选择 | 长琴: https://yam.gift/2025/10/24/NLP/LLM-Training/2025-10-24-ReinforcePP/
[8] Approximating KL Divergence: http://joschu.net/blog/kl-approx.html
[9] GRPO优化在继续——CISPO和熵 | 长琴: https://yam.gift/2025/06/19/NLP/LLM-Training/2025-06-19-CISPO-and-Entropy/
[10] GRPO“第一背锅侠”Token Level X2:GTPO双“T”傍地走 | 长琴: https://yam.gift/2025/08/30/NLP/LLM-Training/2025-08-30-GTPO/
[11] GRPO“第一背锅侠”Token Level X:DAPO/DrGRPO与GSPO/GMPO的殊途同归 | 长琴: https://yam.gift/2025/08/14/NLP/LLM-Training/2025-08-14-Token-Level-GSPO-GMPO/
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。