随着 GRPO 在后训练的不断应用和成熟,越来越多的任务都开始采用 RL 作为进一步提升效果的方案。但是对于那些缺乏明确标准答案的场景,除了人工标注外,还有没有其他比较高效、低成本的方案呢?
R1 之后出现了一种比较激进的方案:无验证 RL,模型不再依赖外部验证器,而是仅利用自身内部信号,如一致性、置信度或分布特征等来构造学习信号。
从最早的多数投票(TTRL、SRT),到基于熵与自确定性的强化学习,再到引入语义多样性与进化机制的最新方法,这个方向看似在不断取得进展,但其实这一类方法有个很严重的问题:“绝大多数内部反馈机制,本质上都在推动策略熵持续下降。”
这既解释了它们在训练初期或部分任务的有效性,同时也揭示了很多时候性能退化和探索崩塌的缘由。最新的工作从各个角度提出改进策略,如优势重塑、多样性奖励到进化式选择等等,但归根结底也都是在增加模型的探索能力,或者说平衡探索-利用。那么,对这种新的 RL 范式,你怎么看?
TL;DR
- TTRL / SRT、EM / RENT、Intuitor、EMPO 等方法都在显式或隐式地最小化策略熵。
- 内部反馈奖励几乎必然导致策略熵单调下降,最终引发探索不足与性能退化。
- ETTRL 通过高熵 token 分支 rollout 与基于熵的 advantage 重塑,缓解早期过度自信。
- Darling 将语义多样性显式并入奖励,增加探索。
- EVOL-RL 以“多数选择 + 新颖性变异”模拟进化过程,在稳定与探索之间取得更优平衡。
- RESTRAIN 利用全部 rollout 信号,对低一致性与过度自信样本进行系统性惩罚。
| 方案 | 具体做法 | 特点 |
|---|---|---|
| TTRL 250422[1] / SRT 250527[2] | 多数投票答案 | 部分领域(数学)使用 |
| EM 250521[3] FT | 直接最小化 token 级别熵(类似 SFT) | 数学和编码任务中强 |
| EM 250521[3] RL / RENT 250528[4] | 熵作为奖励 | 能在大型数据集上收敛 |
| EM 250521[3] INF | 将 LLM 输出的 logits 视为可自由优化的参数 | 最小化输出分布的熵 |
| EMPO 250408[5] | 将输出按语义聚类,语义簇熵作为奖励 | 增加一点多样性 |
| Intuitor 250526[6] | 自确定性(输出分布与均匀分布的平均 KL 散度)作为奖励 | 对“更长文本偏好”偏差不敏感 |
| ETTRL 250815[7] | 树状分支 rollout + Advantage clip | 降低成本、缓解早期估计偏差 |
| Darling 250902[8] | 奖励×多样性 | 增加回复的语义多样性 |
| EVOL-RL 250918[9] | 模拟生物进化增加新颖性奖励 | 防止熵崩塌 |
| RESTRAIN 251002[10] | 惩罚低一致性样本同时保留高潜力推理链 | 无监督自我改进 |
无验证
无验证/无监督也算是一种新的建模方式吧,RLIF,即 Reinforcement Learning from Internal Feedback,从模型内部获取反馈。比较早的工作是在 Reward Model建模 | 长琴[11] 中介绍的 TTRL 250422[1]。TTRL 有个问题,就是只能在某些特殊领域(比如数学)使用。
多数投票
SRT 250527[2],《Can Large Reasoning Models Self-Train?》和 TTRL 非常类似,不同的是,TTRL 是在同一组 prompts 上进行训练和测试。而 SFT 目标是利用这种简单的伪标签生成机制,来研究由 RL 驱动的自训练框架的有效性。
研究发现,生成标签的策略会随着梯度更新明显改进,比固定标签效果好。而且,课程学习能持续在更困难的任务上取得进展。不过,长时间训练可能会把模型引导到”完全忽略 prompt,输出同一个模板化的最终答案“的行为。
熵
在训练 RL 的时候,熵绝对是一个相当重要的东西,它的作用大概包括:
- 量化不确定性和引导探索的原则性度量。
- 熵奖励项需要对正则化系数进行精细调参,并且在直接应用于 LLM 时可能会导致训练不稳定。
- 作为塑造策略优势的信号,比如高熵 token 与探索性推理行为相关。
下面的几个方案都是基于熵的。
熵为目标
熵最小化 EM 250521[3],《The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning》基于一个关键假设和一个简单直觉:如果一个模型具备合理的能力,那么当它自信时,更有可能是正确的。文章基于熵最小化设计了三种后训练方法:
- EM-FT:直接最小化 token 级别熵,类似 SFT,但是在模型的输出响应上无监督进行。
- EM-RL:以负轨迹级熵或负 token 级熵作为唯一奖励进行强化学习。
- EM-INF:在推理阶段,通过 token 级估计调整 logit 来降低熵,无需任何训练数据或参数更新。
我们这里只关注 EM-FT。思想也很简单,直接最小化采样轨迹的熵,给定一个 batch(N个)采样轨迹,最小化 token 级别熵。
其中,
当然,还有一个轨迹级别的熵,如下:
注意,和 token 级别不同的是,由于无法枚举所有 y,这里是用平均值代替期望值。这个会被用在 EM-RL 的实验中。
虽然轨迹级和 token 级两种估计器都都可用于计算熵,但在训练中会导致不同的行为。最小化轨迹熵会使策略在“整条轨迹”层面具有更低的熵;而最小化 token 级熵则会使策略在“每一步生成时”都具有较低的熵。
最终结果显示,EM(整体)在模型置信度与正确性高度相关时最为有效,不过对于诸如对齐人类价值观等任务,仅靠置信度并不能可靠地反映输出质量,EM 就不太适用。另外,EM 的有效性依赖于一个关键假设:预训练模型本身已在目标任务上具备一定能力。
熵为推理时目标
看标题就知道啦,这里说的是前面的 EM-INF。讲真的,EM 这篇文章还不错。
EM-INF 的出发点其实也可以理解成:TTRL 并不一定总能得到多数投票的轨迹,而且推理时需要是无监督的。EM-INF 将模型的输出 logits 视为“可优化参数”,并使用梯度下降来更新它们,以最小化这些 logits 所诱导的分布的熵;整个过程不需要对模型参数求梯度、也不需要更新模型参数。
具体来说,zt 是模型在第 t 步最后一层产生的 logit 向量,冻结模型参数,通过梯度下降直接优化这些 logits,以最小化它们所诱导的输出分布的熵。这里只是将 logits 视为可自由优化的参数。为了防止过度优化(否则会退化为贪心解码),还引入最小熵阈值 δ(实验证明 0.1 < δ < 0.5效果最佳)。
对每一步推理,目标定义为:
σ 是 softmax。优化完 logits 后,采样下个 token,因为这种优化不会改变 logit 最大的那个 token,贪心解码结果也不会变化。它本质上等价于对一个拥有 V 个参数、使用 softmax 激活的一层神经网络进行优化。
实验表明,5 到 15 步梯度更新就足够,由于词表大小远小于模型参数,这样的更新在一次前向传播中几乎可以忽略。简单点来说,这个操作就是想让 logits 分布变得更“尖锐”,是“logits 后处理”。
最后说一下,为什么这种优化不会改变 logit 最大的那个 token。有如下命题:tempreture 和 logit 优化都会降低模型输出分布的熵,让高概率 token 概率进一步增加。不过,在高不确定性情况下(即模型预测分布熵较高时),logit 优化可能会改变非顶部 logits 的顺序。相比之下,tempreture 则会保留所有 logits 的顺序,仅按比例使分布变得更尖锐或更平坦。证明见附录A。
熵为奖励
RENT 250528[4],《Maximizing Confidence Alone Improves Reasoning》利用模型自身的置信度作为奖励来提升推理性能。具体而言,将奖励定义为模型预测的 token 分布的负熵。该信号稠密、通用且易于计算,不需要真实答案。
它的出发点我觉得很有意思,如下:
1 | 想象一下你正在参加一场考试。一旦考试开始,就无法获取新的信息,也不能寻求外部帮助。在只能依赖自身推理的情况下,你会如何解决一道难题?你可能会先尝试一个初步答案,评估自己对答案的置信度,并反复修正推理,直到觉得足够确定。当然,置信度并不能保证答案正确——但在没有反馈的情况下,它往往是指导进一步思考的唯一内在信号。在这种情境下,人类倾向于优化置信度,或者等价地,减少不确定性。 |
另外,实证分析发现,对推理链末端的 token(尤其是最终答案对应的 token)最小化熵,与准确率提升的相关性最强。相比之下,响应开头的 token 几乎没有相关性。说明当模型接近最终答案时,它越来越依赖自身的置信度来指导推理,因此鼓励模型在这些最终步骤中保持高置信度,是提升整体性能的关键。
熵定义如下:
其中,
奖励为:
其实就是整个 rollout 所有 token 负平均熵。该奖励鼓励模型在词汇表上生成更加自信且分布更集中的输出,降低预测的不确定性。
总的来看,就是把熵作为奖励信号,非常简洁直白的设计。这和前面提到的 EM 250521[3] 中的 EM-RL 几乎一模一样。EM-RL 以负轨迹级熵或负 token 级熵作为唯一奖励进行强化学习。我们来看一下 EM-RL 具体怎么做的。
首先看序列级别,它利用了式(3),这种估计方式偏好高概率轨迹,在某些场景中比较有用,比如较短的数学任务,需要探索一些可行的解法,但又不希望解法数量过多,此时“多个但有限”的思维链更为理想。Reward 如下:
这是自回归链式法则恒等式。
Token 级别则利用了式(1),这种估计方式偏好在每一步生成时都更加确定和自信的轨迹,使模型将概率质量集中在更少的推理路径上。Reward 如下:
把 H 也带进去就是:
注意看,这个式子其实和式(7)是等价的,只不过少了个平均。
虽然 EM-RL 与 EM-FT 的目标都是最小化策略的熵,但它们的优化方式不同。EM-FT 通过直接对熵求导来最小化熵,而 EM-RL 则使用策略梯度方法。实验发现,EM-RL 能在大型数据集上收敛,并在数学推理与代码生成任务上提升模型性能。
语义熵为奖励
EMPO 250408[5],《Right Question is Already Half the Answer: Fully Unsupervised LLM Reasoning Incentivization》并没有直接把熵作为奖励,而是在潜在语义空间中不断最小化 LLM 对未标注问题的预测熵。
具体来说,也是先进行采样,然后把一组输出结果根据「语义」进行聚类,也就是把输出聚合成不同的簇。这一步可以通过 N-gram、正则表达式等预定义规则或额外的小 LLM 在可接受的计算成本内完成。说实话,这一步按字面量的 N-gram、正则这种恐怕还真不太行,可能仅适用于少部分任务。总的来说,重点是「聚类」,而非如何聚类。
聚类完后,不同类(语义空间)的概率可近似等于对应簇中采样答案的比例:
其中,cj 是第 j 个语义类,|cj| 是类 cj 包含的输出数量。
给定输入 q,模型输出含义分布的语义熵为,
看起来是想让模型输出属于高概率语义簇的答案(最小化 H,最大化 p),这个 p 就是算法的奖励。这个看起来稍微保留了一些多样性,因为簇内输出一般不会一模一样。
为了应对 reward hacking 问题(比如,模型可能利用奖励信号,通过对最常见的语义簇给出高置信度但错误的预测来过拟合,而不经过真正的推理过程),使用了一种简单的熵阈值策略:通过双重阈值标准将优化限制在表现出中度不确定性的输入提示上。
最终目标函数为,
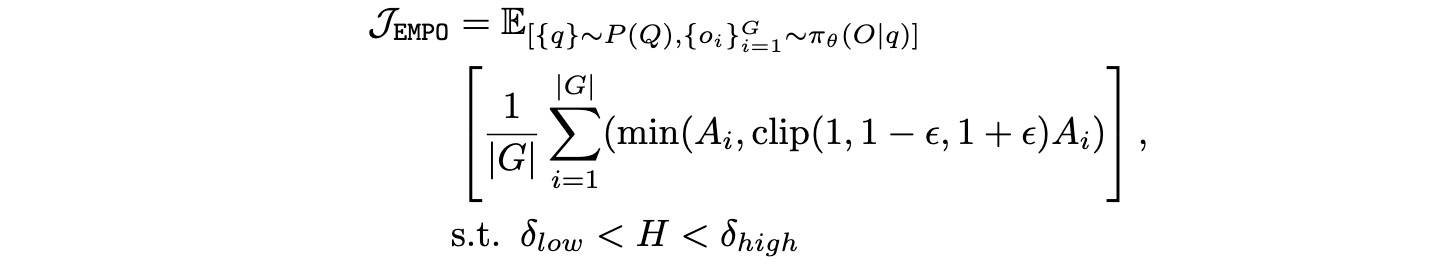
Advantage 的计算就是 GRPO 的做法。注意,目标函数里只有 A(也就是 r)没有 H,H 只是用来过滤的,对不在范围内的簇,嗯,直接扔掉了。
自确定性
Intuitor 250526[6],《Learning to Reason without External Rewards》,以自确定性作为奖励信号。那具体怎么确定这个自确定性呢?本文使用的是:模型输出分布与均匀分布之间的平均 KL 散度。这源自一个观察:LLM 在遇到不熟悉任务或缺乏足够知识时,常表现出较低的信心。相反,更高的置信度通常与正确性相关。
定义如下:
这就是 r,剩下的就和 GRPO 一样了。
相比于基于困惑度或熵的度量方法而言,自确定性对“更长文本偏好”这种常见偏差不那么敏感。Scalable Best-of-N Selection for Large Language Models via Self-Certainty[12] 证明自确定性在从多个候选答案中选择高质量回答时十分有效,而且在各种置信度指标中,它是唯一一个在候选数量增多时效用反而提升的指标。
无验证的问题
250620[13],《No Free Lunch: Rethinking Internal Feedback for LLM Reasoning》发现,无论熵还是自确定性,其实内部都是等价的,它们都优化了相同的底层目标:策略熵,而这也是它们共同的问题:熵太低,模型输出分布逐渐趋向确定性,导致策略探索不足。
《The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models[14]》这篇文章给出了一个等式:
R 是模型表现,H 是熵。
定理1:对表格型 softmax 策略(状态空间有限,用表格表示),相邻两步之间的策略熵差满足:
定理2:基于自然策略梯度(Natural Policy Gradient)的表格型 softmax 策略的参数更新公式:
来自文章《RL策略熵在迭代中是如何收敛的 - 知乎[15]》和《On the Theory of Policy Gradient Methods: Optimality, Approximation, and Distribution Shift[16]》。
于是,有三个命题:
命题1:token 级别熵作为奖励时,最大化该奖励等价于最小化熵。如式(9)所示,一目了然。
命题2:自确定性奖励导致策略熵下降。
根据前面自确定性的定义,我们知道:
对其求导,有:
根据 softmax 导数(附录B),可得导数为:
δ 为 Kronecker delta(y==y’ 为 1,否则为 0)。
假设 η 为学习率,根据式(15)有,
根据熵的定义(H=E(H))有,
因为 logπ 随 π 增加而增加,因此上式熵的差 ΔH≤0。所以,更新过程会导致策略熵降低。
命题3:表格型 softmax 策略,自然梯度更新(附录D),序列级别熵作为奖励会导致策略熵下降。
根据定理1和2,
奖励 r(x,y) 仅依赖当前上下文 x 和生成序列 y,优势函数 A(x, y) 本质上等价于奖励(在常数基线偏移下,即只相差一个与 y 无关的常数项),引入 Advantage 并不会改变“优化目标的本质”,只是降低方差、稳定训练。
奖励与 logπ 强正相关,从而使协方差项为正。因此,每次更新都会导致策略熵下降。
实验结果表明,RLIF 在训练初期能提升性能,随着训练的进行,性能甚至低于训练前的模型。此外,RLIF 对 Instruct 模型几乎没有显著提升,表明一旦 LLM 经过指令调优,其内在反馈的收益递减。
最后,文章还给出两个论断:
- 同一模型家族中,初始策略熵较高的模型(如 Base 模型)可以通过 RLIF 得到提升性能。相反,RLIF 无法带来改进。
- RLIF 会持续减少过渡词的出现频率。其性能提升源于缓解模型的“信心不足”,而性能下降则源于模型“过度自信”。
其实,这个问题是比较直观和容易理解的,因为只能依靠内部信号,模型自然会倾向于在”确定的问题上更确定,不确定的问题上更不确定“。学习过程中奖励信号的质量一路下降,多样性越来越差,最终走向低熵崩塌。这些观点来自也可以在 EVOL-RL 251001[17] 中看到。
优化方案
熵调整优势
ETTRL 250815[7],《ETTRL: Balancing Exploration and Exploitation in LLM Test-Time Reinforcement Learning Via Entropy Mechanism》瞄准了 TTRL 的问题:并行 rollout 带来的高推理成本,以及早期估计偏差导致的过度自信——会降低输出多样性并使性能进入平台期。提出基于熵的机制,通过两种策略:Entropy-fork Tree Majority Rollout (ETMR) 和 Entropy-based Advantage Reshaping (EAR)——增强探索与利用平衡。
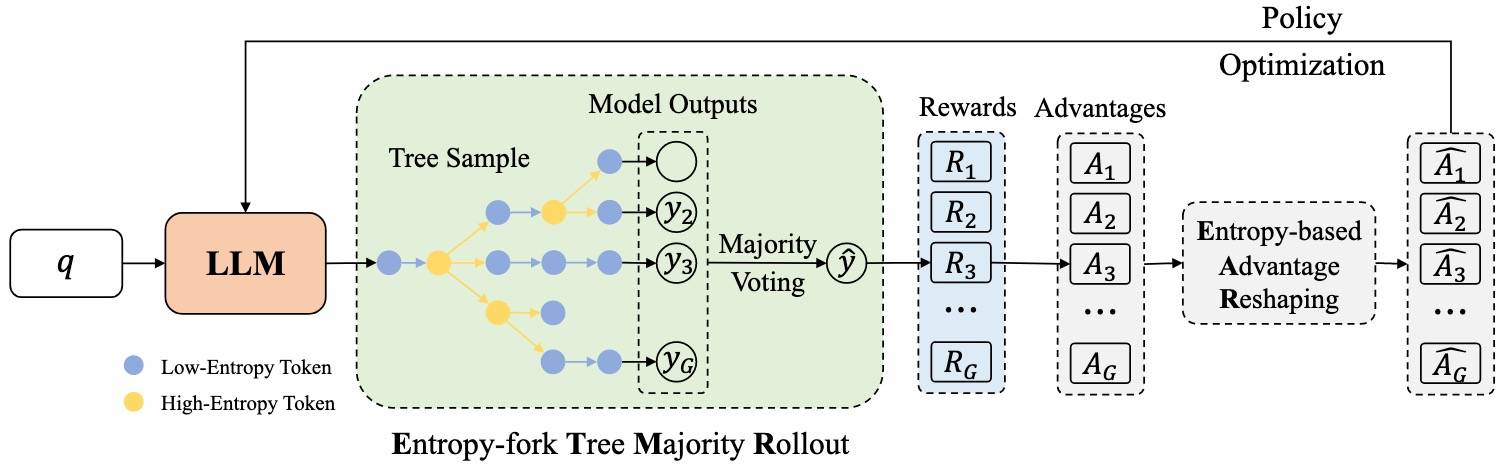
ETMR
针对高开销和探索不足的问题,一种树状 rollout 策略,仅在熵值最高的 K 个 token 处进行选择性分支。基于两点:
- 许多 rollout 含有大量冗余 token。
- 推理中的输出多样性主要受到高熵 token 的影响——这些 token 通常是连接词或过渡词。
借鉴 TreeRL 树形 rollout 方法,复用低熵 token,对高熵 token 选择 top-K 候选来生成多个采样分支。算法过程如下:

EAR
训练初期,多数投票比例通常极低,这意味着只有很小一部分样本能够获得正奖励。此时,模型可能会对错误答案赋予过高的置信度,从而导致所谓的早期“过度自信”。为缓解早期估计偏差问题并维持探索,通过在优势计算中加入响应级别的相对熵奖励项来重塑优势函数。
具体来说,采用 Adv-Clip 作为主要的正则化策略。它的核心思想简单而高效:将 advantage 的取值限制在预设范围内,从而在训练早期直接抑制过大的梯度更新。
裁剪有效缓解了过度自信的问题,但它并未利用每个响应的可靠性等更细粒度的信息。为了进一步优化 advantage 的估计,提出一种基于熵的机制 Adv-Res 作为补充策略:
其中,
avg 就是对组内所有 rollout 的熵求平均,而每个 rollout 的熵等于所有 token 的熵平均。Adv-Res 利用响应熵来评估相对置信度:熵高于平均值的响应被视为不确定,其优势值会被下调;而低熵响应则会得到略微增强的梯度更新。
总的来看,ETTRL 主要是针对 TTRL 早期估计偏差问题,毕竟是无监督,没有奖励信号,于是调低熵高于平均值响应的优势。相当有针对性的优化。
多样性探索
Darling 250902[8],《Jointly Reinforcing Diversity and Quality in Language Model Generations》也关注语义多样性,它引入了一个学习得到的分区函数,用于衡量超越表层词汇差异的多样性。
多样性被定义为一个回答与其他回答的平均成对距离:
这里训练了一个二分类器,用于判断两条回答语义是否等价(分类结果就是 d)。被预测为语义等价的回答会被聚类,从而将所有回答划分为若干语义簇,其中同一簇内的多个成员除了一个代表之外几乎不提供额外价值。感觉和 EMPO 250408[5] 有点类似。
奖励被定义为:
Norm 表示归一化到 0-1。
文章做了相加和相乘的消融,单纯相加可能导致模型偏向优先优化其中一个奖励。相乘放大了与其他回答语义差异较大且奖励高的回答的有效奖励。
此外,序列级损失平均改为 token 级平均,因为前者对较长序列存在偏差;并去除 Advantage 的标准差归一化,因为该操作会放大密集奖励中的噪声。这些操作都来自 DrGRPO[18]。
虽然 Darling 并不专门针对无监督 RL,但其本身是兼容不同设置的,而且也很简单。
新颖性
EVOL-RL 250918[9],《Evolving Language Models without Labels: Majority Drives Selection, Novelty Promotes Variation》解决的是自我确认信号(例如置信度、熵或一致性)作为奖励导致模型过于自信、熵崩塌的问题。将多数投票的答案保留作为稳定性的锚点,同时引入一个新颖性感知奖励,根据每个采样解的推理与其他同时生成的回答的差异程度进行评分。这是“多数票保障稳定性 + 新颖性促进探索”策略,对应了变异–选择原则:选择防止偏移,而新颖性防止崩塌。
所以,这里的重点是怎么设计新颖性感知奖励。一个关键的设计选择是,该奖励策略性地应用于所有解——无论是与多数答案一致的,还是不一致的。
- 对于与多数一致的解,奖励新颖性鼓励模型发现通向正确答案的多条有效推理路径,从而直接抵消 pass@n 性能下降。
- 对于少数解,奖励新颖性对于逃离局部最优至关重要。
这种整合改变了学习过程:它不仅缓解了当前任务中的多样性崩塌,还与持续学习的目标保持一致。
奖励设计:
- 多数(选择)奖励:一个回答的答案是否与有效回答中的多数投票答案一致,得分(yi)为 1 或 -1。
- 新颖(变异)奖励:计算每个回答推理部分的 Embedding,构建余弦相似度矩阵。
- 对于每个回答,计算它与同组其他回答(即多数组或少数组)的平均相似度
s ̄i,以及它与整个批次中任意其他回答的最大相似度mi。 - 平均相似度是按组内计算的,因为多数解与少数解在语义上通常相距较远;若采用全局平均,会被这一差距主导,从而掩盖多数组内部同伴解之间更细粒度的差异。
- 对于每个回答,计算它与同组其他回答(即多数组或少数组)的平均相似度
新颖奖励公式:
α 默认值为 0.5。要想奖励高,则组内平均相似度要小(新颖),同时与其他回答的最大相似度也要小(不和非本组的相似)。它惩罚两种不同形式的冗余:较高的 si 表示与组的语义平均值趋同,而较高的 mi 则表示与某个特定回答近乎重复。该分数同时促进局部和全局的多样性。
将多数标签和归一化的新颖性分数映射到不重叠的奖励区间,得到最终奖励形式为:
另外,对 GRPO 使用非对称 clip(来自 DAPO[19])进一步增加探索。
同时,添加 token 级别的熵正则项,在初始生成过程中维持多样性。
最终的损失为 Lgrpo + Lent。
EVOL-RL 模拟生物进化,平衡了稳定的选择压力与动态的变异机制。多数选择为正确性提供了关键锚点,三部分变异策略创造了稳健的探索动态。
- 熵正则项类似于更高的“突变率”,确保系统始终拥有多样化的解可用。
- 新颖性奖励为这一变异提供方向性压力,为语义上与同伴不同的解提供“生存加成”。
- 非对称 clip 确保当出现高度有益的“突变”——即稀有、新颖且正确的解——时,其强烈的学习信号能够被完整保留至下一代。
总的来看,EVOL-RL 是相当不错的无监督 RL 解决方案,新颖性机制的设计是点睛之笔。
利用所有rollout
RESTRAIN 251002[10],《RESTRAIN: From Spurious Votes to Signals – Self-Driven RL with Self-Penalization》主要针对难以标注的任务,模型必须具备在无直接监督下自我改进的能力,因此经验驱动学习是下一个方向。RESTRAIN(自约束强化学习)不过度依赖虚假的多数投票,而是利用模型整个答案分布中的信号:惩罚过于自信的 rollout 和低一致性样本,同时保留那些有潜力的推理链。
这里的关键问题是,在没有标注数据的情况下,模型如何生成自身的学习信号。常见的方法有:
- 自奖励:模型根据自身判断对 rollout 排序或评分。缺乏充分证据表明能够稳定提升复杂推理任务性能。
- 利用模型的内部一致性。比如 TTRL,不过存在可靠性与稳定性问题,可能导致模型训练崩溃:多次尝试经常生成自一致性低或置信度低的回答;或者在挑战性的推理任务中,多数投票得到的答案本身可能系统性错误,少数 rollout 反而可能包含正确解答。
关键挑战不仅在于生成自我衍生的奖励,更在于确保这些奖励能够提供稳健的信号。RESTRAIN,
- 利用了所有 rollout,而不只是多数投票的。
- 对低置信度的 rollout 施加负优势惩罚。
- 对多数投票脆弱、内部一致性较低的 prompt 进行降权处理。
如图所示:
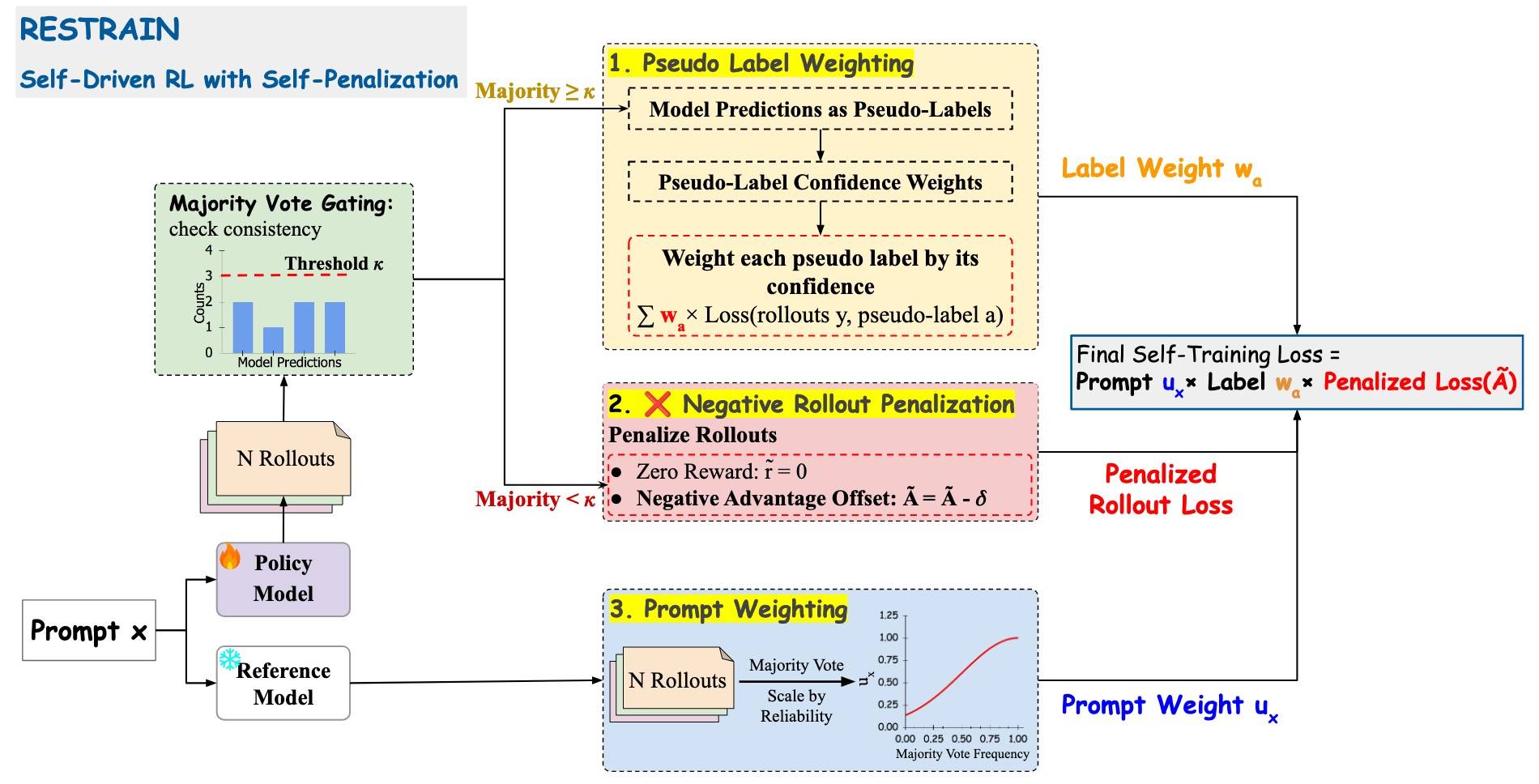
Pseudo-label weighting:伪标签加权机制
为了解决多数投票往往可能虚假的问题,具体做法是:根据观测到的投票数量按比例分配权重。
给定 prompt x,n 个 rollout 构成一组 m 个不重复答案 a,每个答案 aj 对应的数量为 cj。每个 aj 被当做伪标签来计算加权损失:
权重 w 是频率 f 的单调函数 g:
其中,fj = cj / n。g 是一个 k∈[0,1] 为中心、偏差为 σ>0 的高斯函数。加权的偏斜程度由 g 控制:函数 g 越陡峭,概率质量越集中在高频答案上;函数 g 越平滑,权重则在各答案间分布得更广。
Negative rollout penalization:反向 rollout 惩罚
不过,当多数票数量非常少时,Pass@n 往往表现下降,因为模型可能根本没有生成正确的 rollout。即没有答案可以被自信地信任。负向rollout 惩罚假设所有回答均为错误,并施加统一的负向偏移。
其中,M(x) = max_j cj,也就是答案数量最多的对应的值。这个约束让满足 M(x)<κ 的模型预测仅产生负向更新,惩罚所有自一致性较低的 rollout。换句话说,至少有一个答案对应的 rollout 应该有 κ 个。
值得一提的是,这里还是要计算 reward 的,论文附录里的代码也显示需要一个 reward_fn,这和 TTRL 不一样,TTRL 可不需要这个,它是直接拿最多投票的结果作为答案,和这个答案相同的 reward=1,否则 reward=0。这就不是无监督了,除非让 reward=wj。这里写的不是很清楚,而且按整个基调来看,是不应该还需要真实 label 的。
Prompt-level weighting:提示词级别加权
因为有些 prompt 模型表现出高度不确定性,而有些 prompt 则生成高度一致的回答。所以,这里使用一个反映模型置信度的固定权重。为了防止虚假的反馈循环(例如训练过程中置信度膨胀),权重使用冻结的 ref 模型计算一次后保持不变。
从 ref 中采样 n 个 rollout,和上面一样,c 是数量。注意这个权重是提前离线计算好的,训练期间保持不变。
最终损失为:
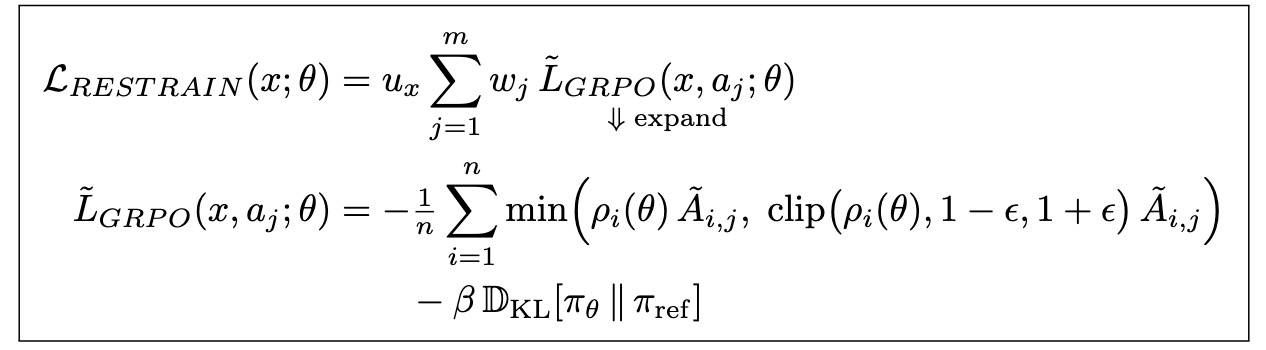
小结
本文梳理了近期关于无验证/无监督 RL 的一些思路,自从 TTRL 打开这扇门后,相关研究层出不穷,这最大的原因自然是针对那些更加常见的没有标准答案的任务。针对此类任务,《Reward建模新范式:无验证器RL与Reference的妙用 | 长琴[20]》其实还是有 RM 建模的,或者说有一个隐式的验证器,而本文介绍的方法并没有,顶多借助外部模型(比如多样性、相似度计算)拿到计算 reward 的某个指标,而不是直接验证结果或答案是否合理、正确。所以,我将其统称为 Verify-Free RL。
既然说到这里了,顺便说一下《Reward建模新范式:无验证器RL与Reference的妙用 | 长琴[20]》中介绍的「基于准则」的方法。我虽然没有尝试过直接让模型连续输出结果+评估,但尝试了先输出结果,再加一轮评估指标并让模型跟着输出评估结果。不出所料,相当严重的 reward hack,模型很快就学会了捷径,输出的内容不咋地,评估都是满分。我脑袋一拍盲猜啊,“让模型连续输出结果+评估” 也大概率会遇到同样的问题。那怎么办呢?说来也巧,正好前段时间发布的 DeepSeekMath-V2[21] 给出了答案——自我验证!Reward 模型对验证结果再验证,简单来说,就是 “评估+评估再评估”,范式就又回到了熟悉的领域。
不过总的来看,无验证的 RL 还是要依赖 LLM 本身的能力,前段时间有《Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?[22]》说 RL 并未激发出全新的推理模式,但同时也有不同结论的其他研究,比如《RL Grokking Recipe: How Does RL Unlock and Transfer New Algorithms in LLMs?[23]》,看来这里面还大有玄机,而且它本身就是底层基础,重要性毋庸置疑,我们择文再议。
附录
附录A:logits优化理论支持
证明:在高不确定性情况下 logit 优化可能会改变非顶部 logits 的顺序,但不会改变 logits 最大的 token,只会让其概率进一步增加。
有概率分布 p(z) = softmax(z),熵 H = -∑pᵢ log pᵢ,所谓 logit optimization 就是在推理时做:
后面的导数可以展开:
其中, δ 是 Kronecker delta 函数,当两个输入相同时输出为1,相同时输出为0。pj 对 zi 求导就是 softmax 的导数,这里不展开了。因为损失函数是负熵,因此实际更新为:
考虑如下等式:
可以证明,存在某些 z 以及两个索引 a, b,使得 za < zb,但 ga > gb。
利用中值定理,存在 c ∈ (pa, pb),使得:
logc +H +1 是 g 对 p 在 c 处的导数。因为是非顶部 logits,我们可以认为 pa, pb(za < zb,所以pa < pb)都很小,且它们差不多大。
所以,我们可以设任意大 η,使得,
说明:在高熵(H大)且两个概率接近(pa≈pb)的情况下,熵梯度可以导致 logits 顺序被改变!
接下来继续证明,b 不能是 arg max z_i,即不能是最大 logit。这是为了说明,熵梯度不会“削弱”最大的那个 logit ,它只会强化 top token 或调整下面的 token。
设 j=arg max_i z_i,即当前最大 logit 的索引,根据熵的性质有,
因为 softmax 单调,pj 就是最大的概率。
考虑 g(pi) = pi(log pi + H),即式(A.4),导数 g′(pi) = log pi + H + 1。当 g′(pi) > 0时,g(pi) 单调递增。
这就是说,对于高概率 token(如 top token pj),它的 gj 是很大的正值,会被进一步提升(因为梯度指向增加)。相反,对于低概率 token(pi很小),它的 gi 可能是负数,可能会被压低。
如果 j 是最大概率的索引,那就意味着,任何概率更低的索引 i 都不可能满足 gi > gj,因此,对于 b ≠ j 有,
在高概率区间(上面的式子),ga 为正且随概率增大而增大;在低概率区间,ga 为负,而其他类别 g 为正,说明低概率类别会被下拉。
注意,这里是 H 而不是 H+1,是因为我们在判断 g 的正负性而非单调性,
说明:logit 优化会让高概率 token 概率进一步增加,也不会改变 logit 最大的那个 token。
附录B:softmax 导数
给定 softmax 函数:
要求 yi 对 zj 的导数,需要分 i=j 和 i≠j 两种情况。
i==j 时:
i≠j 时:
合并用雅可比矩阵表示:
即,
δ 为 Kronecker delta(y==y’ 为 1,否则为 0)。用向量形式表示:
diag(y) 是一个对角矩阵,主对角线上是 y1, y2……,y y^T 是外积。
另外,还有个常见的导数(log softmax),对某个固定类别 c,
可以直接展开求导得到,也可以在前面 J 的基础上乘 1/y 得到。
附录C:KL散度
D_KL(P||Q) 衡量的是当我们使用一个近似分布 Q 而不是真实分布 P 时,所造成的信息损失的期望值。
对于离散变量,展开为:
对于连续变量,则为积分形式:
分解公式可得:
第一项是熵,表示对来自 P 的样本进行编码所需的最小平均比特数(信息量)。第二项是 P 和 Q 的交叉熵,表示使用基于 Q 的最优编码对来自 P 的样本进行编码时所需的平均比特数(信息量)。
即,
它准确地衡量了由于使用近似分布 Q 而产生的额外编码成本或信息损失的期望值。
附录D:自然梯度
这部分来自 GPT 和 Gemini 的结果整理。
自然策略梯度(Natural Policy Gradient, NPG)是强化学习中对普通策略梯度的一种改进,它通过引入“策略空间的几何结构(Fisher 信息矩阵)”来进行更合理、更稳定的梯度更新。
如上式,标准策略梯度更新有一个隐含问题:θ 空间是欧式空间。但策略 πθ 不是,两个参数向量 θ1 和 θ2 的欧氏距离并不能正确反映策略 πθ1 与 πθ2 的“距离”。比如,在 softmax 策略中,即使参数变化很小,策略可能变化很剧烈;或者参数变化很大,但 softmax 输出的策略几乎不变。因此,标准策略梯度会出现更新步长不稳定、在策略空间里偏离最优路径、学习效率低等问题。
NPG 使用黎曼几何中的 Fisher 信息矩阵作为度量,来“规范化”梯度。将更新方向投影到“概率分布空间的自然几何结构”中,梯度方向为使用 Fisher 逆矩阵调整后的方向。如下式所示,
其中,F 就是 Fisher 信息矩阵,定义了策略的“自然度量”,表示哪些方向上策略对参数特别敏感(需要减小步长),而哪些方向上策略变化小(可以加大步长)。它是策略分布关于参数的二阶导数(Hessian 矩阵)的负期望的近似,用于度量参数空间中KL 散度(策略差异)的变化率。
它们关系如下:
假设由 θ 定义的概率分布 P(θ)(在自然策略梯度中,这通常是策略 π),我们想知道当参数从 θ 微小变化到 θ+Δθ 时,两个策略之间的 KL 散度变化了多少。可以对 D_KL 在 Δθ=0 处进行二阶泰勒展开:
有如下几个性质:
- 零阶项为零。Δθ=0 时,
D_KL=0。 - 一阶项为零。两个相同分布之间的 KL 散度梯度(关于第二个参数)在参数相同时为零。即
▽_θ' D_KL(Pθ || Pθ')|θ'=θ = 0。 - 二阶项是关键。Δθ→0时,KL 散度的二阶导数(Hessian 矩阵)恰好等于 Fisher 信息矩阵。
总之,在一个普通的欧几里得空间,两点距离是欧几里得距离;在一个由概率分布参数化形成的策略空间,两点之间的实际距离(KL 散度)由 Fish 信息矩阵定义。
为什么它更自然?这里的“自然”指的是梯度方向与策略空间中的 KL 对齐,KL 衡量了新旧策略之间的信息损失。自然梯度保证了在每次更新时,参数的变化使得策略迈出的步长在策略空间(而不是参数空间)中保持不变。
References
[1] TTRL 250422: https://arxiv.org/abs/2504.16084
[2] SRT 250527: https://arxiv.org/abs/2505.21444
[3] EM 250521: https://arxiv.org/abs/2505.15134
[4] RENT 250528: https://arxiv.org/abs/2505.22660
[5] EMPO 250408: https://arxiv.org/abs/2504.05812
[6] Intuitor 250526: https://arxiv.org/abs/2505.19590
[7] ETTRL 250815: https://arxiv.org/abs/2508.11356
[8] Darling 250902: https://arxiv.org/abs/2509.02534
[9] EVOL-RL 250918: https://arxiv.org/abs/2509.15194
[10] RESTRAIN 251002: https://arxiv.org/abs/2510.02172
[11] Reward Model建模 | 长琴: https://yam.gift/2025/06/09/NLP/LLM-Training/2025-06-09-RM-Modeling/
[12] Scalable Best-of-N Selection for Large Language Models via Self-Certainty: https://arxiv.org/abs/2502.18581
[13] 250620: https://arxiv.org/abs/2506.17219
[14] The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models: https://arxiv.org/abs/2505.22617
[15] RL策略熵在迭代中是如何收敛的 - 知乎: https://zhuanlan.zhihu.com/p/28476703733
[16] On the Theory of Policy Gradient Methods: Optimality, Approximation, and Distribution Shift: https://jmlr.org/papers/v22/19-736.html
[17] EVOL-RL 251001: https://arxiv.org/abs/2509.15194
[18] DrGRPO: https://yam.gift/2025/03/28/NLP/LLM-Training/2025-03-28-LLM-PostTrain-DrGRPO/
[19] DAPO: https://yam.gift/2025/03/19/NLP/LLM-Training/2025-03-19-LLM-PostTrain-DAPO/
[20] Reward建模新范式:无验证器RL与Reference的妙用 | 长琴: https://yam.gift/2025/11/11/NLP/LLM-Training/2025-11-11-RM-New-Paradigm-Verifier-Free-RL/
[21] DeepSeekMath-V2: https://yam.gift/2025/11/29/NLP/LLM-Training/2025-11-29-Reward-Data-Self-Verified/
[22] Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?: https://arxiv.org/abs/2504.13837
[23] RL Grokking Recipe: How Does RL Unlock and Transfer New Algorithms in LLMs?: https://arxiv.org/abs/2509.21016
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。