R1 之后,GRPO 等强化学习框架的成功让我们相信“反馈”是提升推理力的关键。
然而,当任务无法被规则验证时,这一框架就不太好用了。
本文介绍一种“无验证器”新范式,让模型用 Reference 自我强化,重新定义奖励建模。
TL;DR
- 传统 RLHF 依赖验证器或 RM 打分,但很多开放任务无法简单验证。
- NOVER: 基于 PPL 设计奖励,引入策略代理同步与效率奖励,稳定训练。
- Reinforcing General Reasoning: 直接最大化参考答案概率,以“正确答案的似然”替代验证器。方差更低,与 RLOO、PPO 等技术兼容。
- 逆向激励: 先生成答案,再生成自评得分,无需标准答案。适合创意、写作等难以客观评判的任务。
- Reference 进一步妙用: 帮助模型思考“为什么这是答案”,可用于生成高质量数据。也可与逆向激励结合。
R1 之后,GRPO 已经成为后训练的一个强有力工具,但对一些无法用规则验证的任务,就有点难搞。最 Naive 的方法就是训练一个 Reward Model,用这个 RM 给输出打分。
或者,用 LLM 作为验证器,验证生成结果和参考答案是否等价。不过这对验证器要求很高,如果验证器不那么精准,整个优化方向将出现很大偏离。另外,也容易 reward hacking。而且,实际训练时,这个 LLM 也是要占用推理资源的。
更进一步的方法更可能是让验证器 LLM 输出推理过程和结构化结果,比如我们在 Reward Model建模 | 长琴[1] 介绍过的建模方法。这篇文章最后还介绍了一个 TTRL,它其实算是一种无验证(Verify-Free)的 RL,我们后面再介绍几篇相关的。本文主要介绍介于两者之间的无验证器(Verifier-Free)的 RL,个人觉得可以算是一种 RM 建模新范式。
没有外部验证器(无论是规则或模型)要怎么给奖励?那只能依赖策略自己。接下来,我们基于两篇论文介绍具体怎么做,简单来说可以归纳为两类:基于 Reference(可以视为参考答案或标准答案,类似于 SFT 的输出)和基于准则。
基于Reference
奖励基于PPL
首先是这篇 NOVER: Incentive Training for Language Models via Verifier-Free Reinforcement Learning[2],它的出发点就是针对很多场景(社会行为分析、创意写作)很难构建验证器。
那靠什么?SFT 数据。然后将模型自己作为奖励代理,具体来说就是,根据模型推理过程计算基于困惑度的奖励。如下图所示:
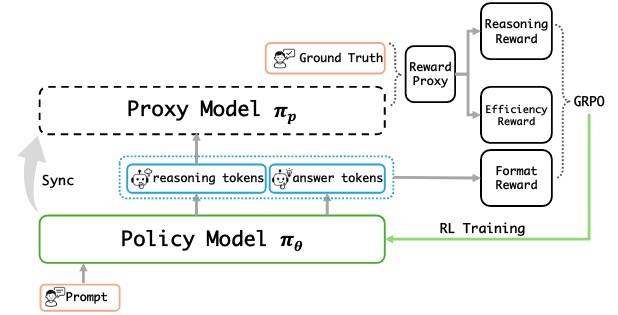
PPL作为代理
核心思想是 GT(GroundTruth)的 PPL。给定 prompt p,GT g,推理 token t 和答案 token a,使用代理模型根据下式计算推理过程的 PPL:
N 是一个基于推理 token 长度的归一化因子。
Pr 越小,根据推理 token 生成正确答案的概率越高。
策略代理同步
没有使用冻结的 Ref 作为代理,而是直接使用策略,它们有共同的目标:在给定高质量推理的情况下,最大限度地减少正确答案的困惑。而且,冻结的 Ref 可能与不断更新的策略模型产生偏离。
需要强调的是,使用 πθ 作为 πp 并不意味着模型同时扮演“运动员”和“裁判”(这应该也是不直接把 πθ 用作 πp 的一个原因吧)。因为 πp 并不进行主观评判,而是依托客观的真实标注来进行公平评估。
实际操作时,从同一个 ckpt 初始化 πθ 和 πp,然后定期按指数平滑法将 πθ 同步给 πp:
α 表示同步率。
无验证器奖励
观察到不同样本相对困惑度改进存在很大差异,导致 clip 比率高方差和训练不稳定。为了缓解此问题,将推理困惑度离散化为推理奖励 Rr。具体来说,基于排序:
n 表示 n 个生成,k=1 或 n。前者表示只要最佳的生成,适用于主观上有正确答案的任务;后者根据 ppl 排名向所有生成结果分配奖励,适合主观或开放式任务。
为了避免推理过程太长(并不是越长越好),再来一个效率奖励:
再加上格式奖励 Rf,最终奖励为:
代理诅咒
利用 PPL 作为代理可能带来代理诅咒:即不精确的奖励可能导致 reward hacking。
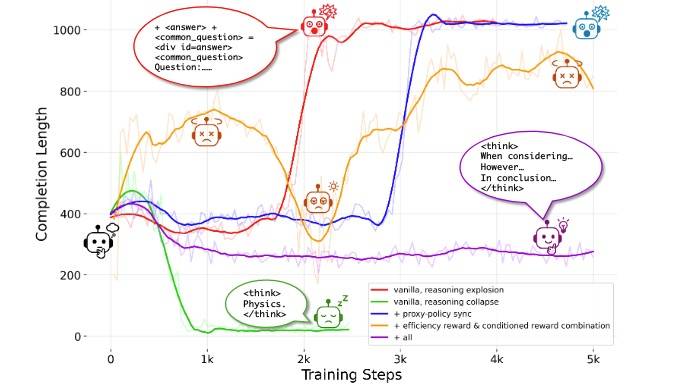
我们重点关注这方面的消融结果。
- Rf + Rr 可能导致推理爆炸(红色,推理过程过长甚至混乱、胡言乱语)和推理崩塌(绿色,几乎不再思考,只输出极少的推理内容)。问题源自 proxy 和 policy 不匹配。
- 加入 Policy-Proxy Synchronization,对应蓝色,后期仍会出现失控输出的情况。
- 加入一个 Re(奖励推理简洁且有效的行为),并将不同奖励按条件组合(式6,格式对时其他奖励才有意义)。对应橘色,带来了部分自我恢复能力(无效的生成奖励为 0),不过效率依然不高。
- 完全整合所有机制在一个统一的训练框架,训练过程变得非常稳定(紫色)。
推理模式转变
实验结果显示效果不错,堪比 SFT,甚至更优。另外观察到,在 CoT Prompt 配置下,随着模型训练,受效率奖励影响,推理模式逐渐从 CoT 经典的 Decomposition 转为跳过冗余推理步骤,直接给出中间结论,导致直接推理模式比例显著上升。同时,其他类型的推理模式也开始出现并逐渐趋于稳定,反映出模型推理能力在有效性与高效性之间的平衡发展。
注意,一共六种推理模式:
- Direct(直接推理):直接回忆事实信息、定义或既定概念,而不进行进一步分析或转换。
- Decomposition(分解):将问题系统性地拆解为可管理的组成部分,建立清晰的步骤、中间目标或方法框架。
- Enumeration(列举):列出多种可能性、选项、替代方案或情况,而不立即选择或确定具体的一项。
- Reflection(反思):重新审视、质疑或重新评估先前提出的观点、假设或结论。
- Assumption(假设):引入假设性条件或前提,作为后续推理的基础。
- Causation(因果):建立事件、行为或条件之间的因果关系。
奖励基于策略概率
第二篇论文是 Reinforcing General Reasoning without Verifiers[3],也是关注无法规则验证的领域。而且,有意思的是,这篇论文是 25 年 5 月 27 日提交的,而上一篇 NOVER 是 5 月 21 日提交的。距离如此之近,也是缘分啊。
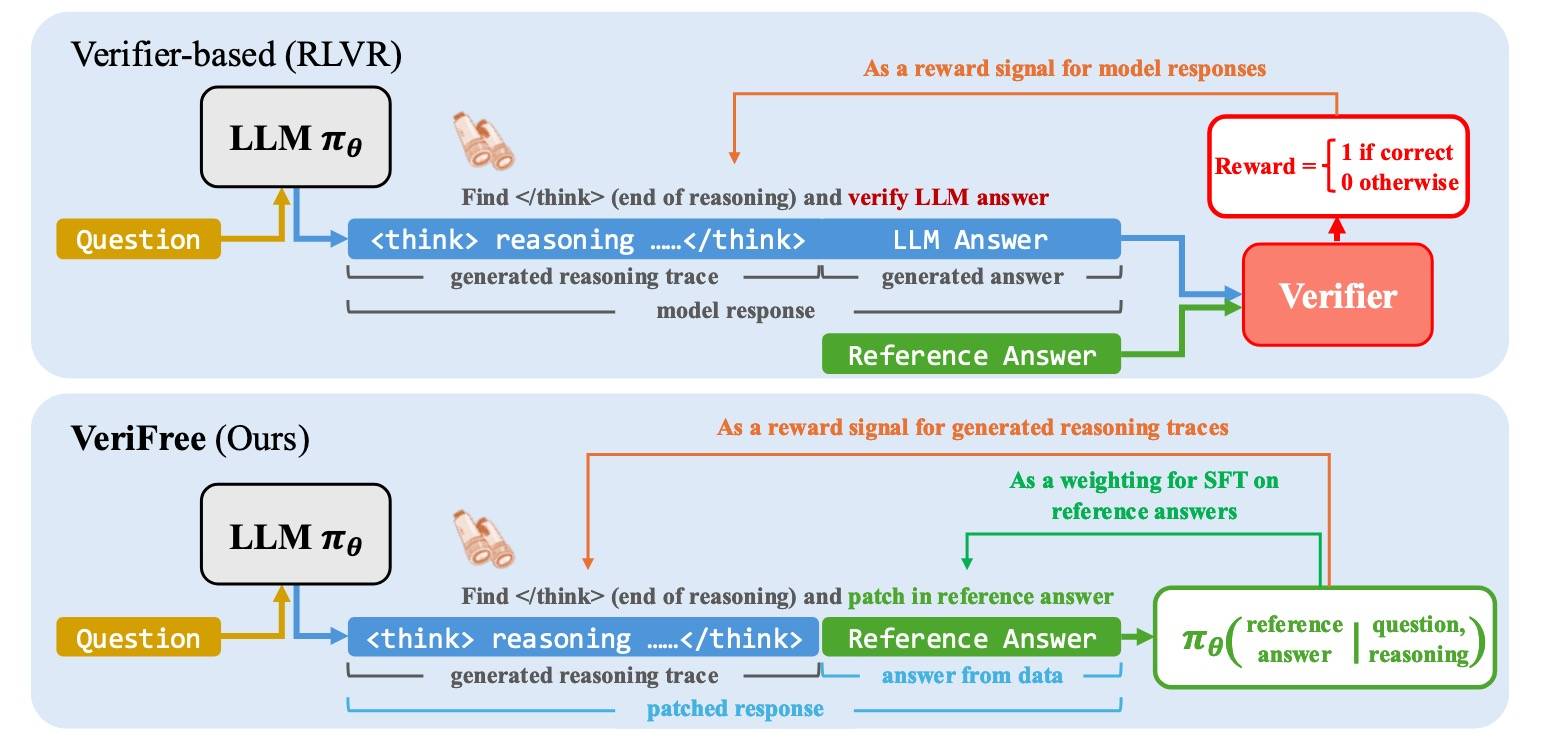
本文的方法是使用 RL 直接最大化生成参考答案的概率。具体做法是:给定一个问题,只生成推理轨迹,然后拼接上参考答案。然后,根据问题和推理轨迹评估参考答案的可能性。这个可能性既可以作为推理轨迹上策略梯度的奖励信号,也可以作为参考答案监督训练的权重项。
简单来说,就是自己生成推理轨迹,然后让推理轨迹和参考答案对齐。如下图所示:
目标与梯度
目标函数如下:
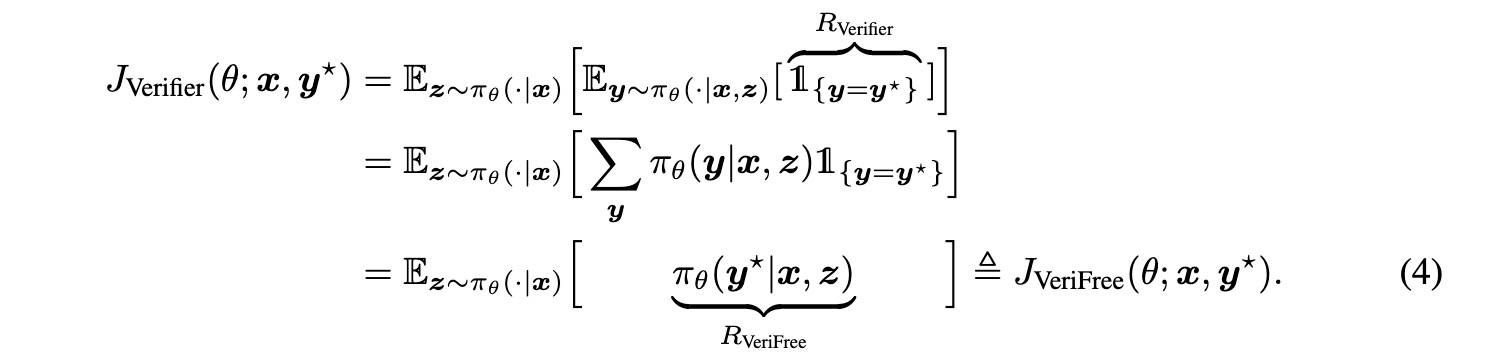
其中,y* 为参考答案,z 是推理轨迹。有验证器和无验证器是等价的。
梯度为:
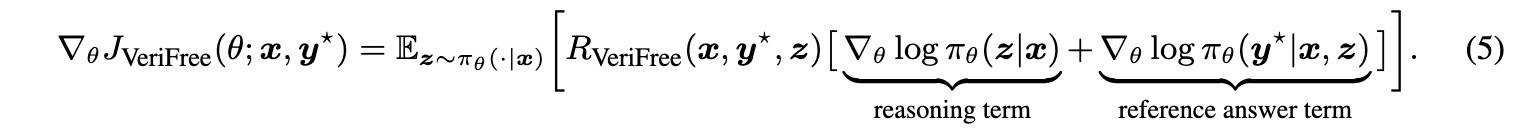
证明过程如下:
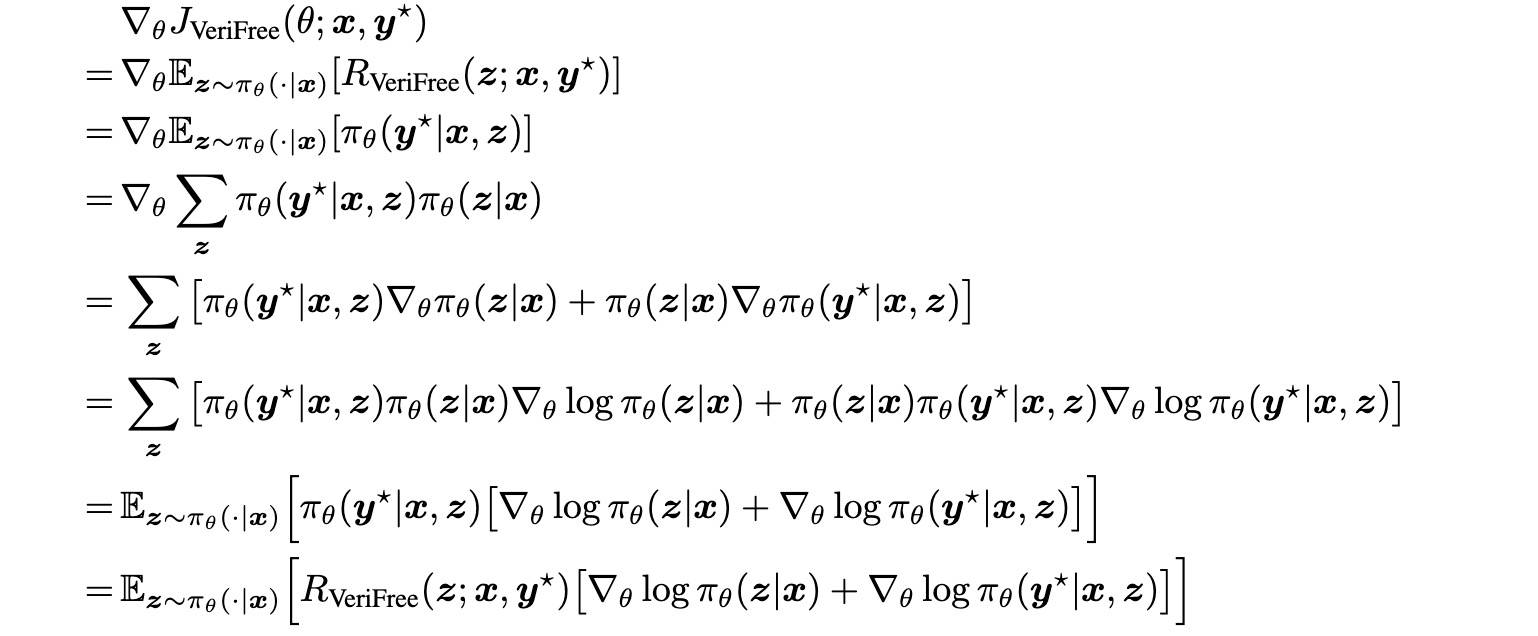
而这也与验证器的梯度等价:
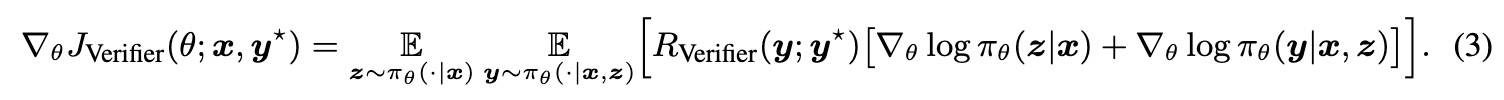
直观来看,式(5)中的“推理项”可以理解为一个策略梯度,其中:
- 对某个推理轨迹 z 的奖励是策略在给定该推理轨迹 z 时,策略生成正确答案
y*的概率。 - 而“参考答案项”可以被视为一个基于奖励加权监督学习项,用于在给定 z 时学习正确答案
y*。
计算过程
计算过程如下:

可以看到,还是很直观的。
多种方案对比
而且,仔细看,这个其实和前面的 NOVER 是非常类似的,NOVER 的核心奖励是 GT 的 PPL,而最小化 PPL 就等价于最大化序列概率。殊途同归呀。本文还给出了其他两个设计:

后面两个式子,JLB 来自论文 Learning to chain-of-thought with Jensen’s evidence lower bound[4],LaTRO 来自论文 Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding[5],这篇论文居然是来自 2024 年的。这些方案的核心就是把模型输出拆分成推理轨迹和答案两个部分。
后面两个方案效果不如 R1-Zero,但本方案却差不多甚至超过 R1-Zero。另外,本方案还有个好处:减少方差。直观来看,在估计梯度时,方差主要来源于两个采样过程(推理轨迹和答案),本方案去除了“答案生成”这一随机性来源,因此方差得以降低。
最终梯度
除此之外,本方案的梯度估计与其他方差降低技术完全兼容,比如RLOO、GRPO 的奖励归一、PPO 的 clip 等。本文针对每个提示采样多个响应,并将 RLOO 基线应用于式(5)中的推理项。同时,采用 DrGRPO[6] 中的长度归一化方法,得到最终的 on-policy 梯度估计器:
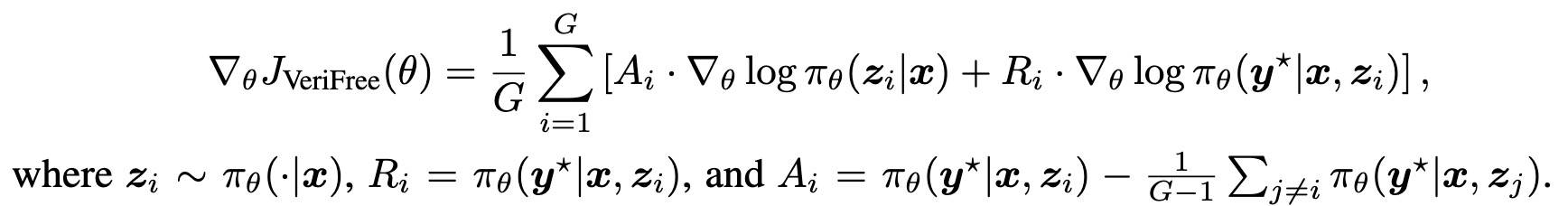
以及一个 PPO 的版本:
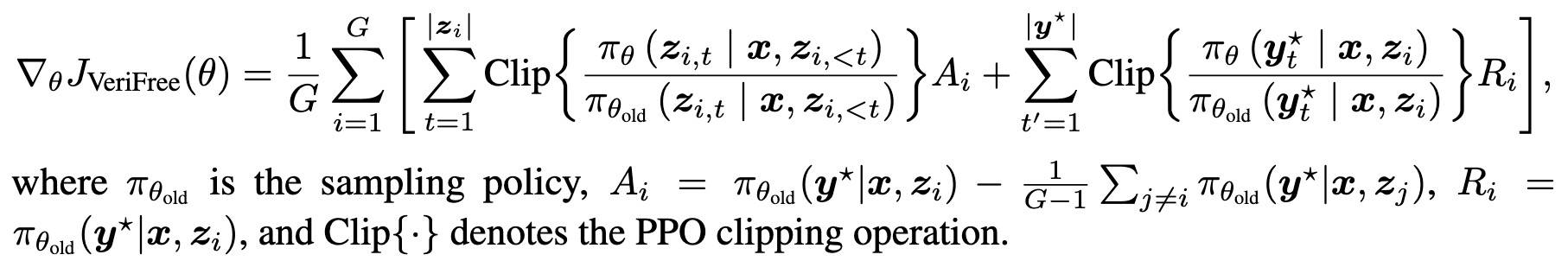
patch方案
好了,迄今为止应该差不多了,最后还有个问题是如何 patch 正确答案。本文提到了一个细节,如果不想等全部答案生成完后再替换(这样会浪费资源生成答案,但其实没用),就需要在遇到答案开始标记后直接停止采样。这里要确保这个标记在词表中。
两者区别
不知道大家有没有一个疑惑,Reinforcing General Reasoning(RGR)会不会也存在 NOVER 的“运动员-裁判”问题?确实,表面来看,两种方案非常相似,奖励都来自策略本身。但其实两者还是有一些区别的:
- 在 NOVER 中,模型评估的是“自己预测参考答案时的困惑度”,奖励依赖的是模型分布;而在 RGR 中,参考答案
y*是固定不变的外部监督信号,模型只是在学习提高其生成概率。 - NOVER 中的 PPL 是通过另一个模型(πₚ)计算出来的“打分”;而 RGR 的
reward = log πθ(y*|x,z),本质是对数似然最大化,与交叉熵监督一致。 - 在 NOVER 中,reward 来自一个外部采样和排名机制(PPL排序),不可微,容易引入偏移;而在 RGR 中,reward 实际上是一个可微的目标函数。
总之,NOVER 让模型评价“自己预测得多好”,RGR 则是让模型学习“如何预测得更好”。RGR 的奖励不是“模型对参考答案的评价”,而是模型生成参考答案的概率本身。模型在优化“自己生成正确答案的能力”,而不是“自己对正确答案的看法”。
再进一步,RGR 虽然保留了 GRPO 的一些技术外壳(比如 rollout),但本质上已经从 “RL-from-reward” 转向了 “RL-from-likelihood”。它的 rollouts 只是采样估计的手段,用来计算梯度项中关于 z 的期望。也就是说,RGR 是可以不 rollout 的,但是为了防止极端情况下可能出现的不良优化路径(log πθ(y*|x,z) 高分,但和真实或期望的推理不一致),采用了降低方差、稳定训练的技术。这是一种解决训练稳定性与估计方差的工程化优化手段,而不是为了解决“自我评分”的根本病因。
基于准则
前面基于 Reference 的方案相对来说还是比较直观的,总的来说就是把 Reference 作为奖励信号源。这部分介绍的基于准则就有点巧妙了,它来自 NOVER 后面介绍的“逆向激励训练”。
文章采用 SS-GEN 创意写作数据集,该数据集同时提供了标准答案故事和结构化评分标准。所谓逆向是指:先生成故事 token,再生成评估 token(传统的是先生成推理 token,再生成答案 token)。这是以过程为结果的策略,引导生成过程满足评分规则,而在训练过程中无需标准答案故事!
有没有觉得很巧妙?而且效果还不错!
我们来稍微推广一下:对于没有标准答案的任务,只要我们有一些评判规则,就可以用 RL 先让模型生成答案 token,然后再继续生成对答案的评估 token,然后用评估得分作为 reward。实际推理时,思考完直接 stop 不继续生成就行了(比如 stop_token 加一个 <answer>),也不降低线上推理耗时。
不过,个人觉得需要注意的是,评判规则本身应该有一定的区分性,而且 Base 模型也应该能够利用这些规则准确评估生成结果,能够区分出好结果和不好的结果。否则整个过程就没意义了。
我们附一下论文里关于这个创业写作任务的评分标准:
- 清晰的结构(Clear Structure):标题、引言、正文、结论,各司其职。
- 描述多于指导(Describe more than Direct):描述性句子的数量应至少是指导性句子的两倍。
- 合适的视角(Appropriate Perspective):社会故事不使用第二视角,以免过于直接;描述负面行为时不使用第一人称,以保护读者的尊严与自尊。
- 积极的语气(Positive Tone):以积极的方式描述情境或引导行为。
- 准确的表达(Accurate Expression):使用清晰、明确、无歧义的语言。
- 合适的词汇(Appropriate Vocabulary):选择对读者来说最舒适、最准确的词汇。优先使用积极动词,避免使用可能引发强烈情绪反应的词语。
Reference另一作用
GRPO 依赖 Base,更像是在已可采样的完成结果之间重新分配概率,而非生成全新的输出。所以,当任务超出模型的能力范围或偏好领域时,训练往往会坍缩到仅强化一小部分熟悉但次优的输出,而那些潜在更优的完成结果则始终未被探索。
RAVR: Reference-Answer-guided Variational Reasoning for Large Language Models[7] 认为 Reference 仅用来计算奖励有点浪费,可以利用它来帮助模型推导出更好的推理路径。这基于认知科学中:回答“为什么这是答案”通常比回答“这是什么答案”更容易。实验结果也显示,对于许多困难问题,即使 LLM 多次尝试仍无法采样出正确的推理路径来解答问题,一旦提供答案,它便能够生成合理的推理过程。
这不禁让我想到了另一篇类似的论文:Reverse-Engineered Reasoning for Open-Ended Generation[8],它引入了逆向工程推理(REER):不是通过反复试错或模仿来“正向”构建推理过程,而是从已知的良好解决方案“逆向”探索,通过计算发现可能产生这些解决方案的潜在、循序渐进的深度推理过程。
RAVR 将参考答案的概率视为对生成推理的奖励,并通过最大化该奖励来增强模型思考“为什么这是答案”的能力。与此同时,RAVR 还最小化后验分布与仅基于问题的先验分布之间的 KL 散度,以帮助模型更好地思考“答案是什么”;反过来,先验分布也对后验的行为起到正则化作用。
这个思路的问题是训推不一致(推理时没有正确答案),本文从变分推断的角度来解决这一问题,将“基于参考答案生成的推理”(后验)视为“仅基于问题时思考标签内推理”(先验)的变分近似。通过最大化基于答案分布的期望推理效用并最小化两种推理分布之间的差异来优化证据下界。
不过,如果我们用这个思路来生成推理数据就不需要考虑这个问题了。文中用到的系统提示词如下:
1 | <|im_start|>user |
我们只要稍微改一下适配到自己的任务即可用来生成高质量的推理轨迹数据。
**如果再结合 NOVER 的逆向设计,是不是还可以用来生成高质量的答案数据。**再次感觉这个逆向设计真的很巧妙,思路一下打开。
小结
本文针对无法使用规则的任务,首先介绍了两种基于 Reference 的“无验证器”奖励设计范式:基于 PPL 和策略概率。然后介绍了基于准则的“逆向奖励”,一种无需 Reference、先生成答案再生成评判结果的设计方案。最后,还是 Reference,我们既不用它验证结果,也不用它计算奖励,而是用它来生成数据。不得不说,真“Reference 的妙用”啊~
References
[1] Reward Model建模 | 长琴: https://yam.gift/2025/06/09/NLP/LLM-Training/2025-06-09-RM-Modeling/
[2] NOVER: Incentive Training for Language Models via Verifier-Free Reinforcement Learning: https://arxiv.org/abs/2505.16022
[3] Reinforcing General Reasoning without Verifiers: https://arxiv.org/abs/2505.21493
[4] Learning to chain-of-thought with Jensen’s evidence lower bound: https://arxiv.org/abs/2503.19618v1
[5] Language Models are Hidden Reasoners: Unlocking Latent Reasoning Capabilities via Self-Rewarding: https://arxiv.org/abs/2411.04282
[6] DrGRPO: https://yam.gift/2025/03/28/NLP/LLM-Training/2025-03-28-LLM-PostTrain-DrGRPO/
[7] RAVR: Reference-Answer-guided Variational Reasoning for Large Language Models: https://www.arxiv.org/abs/2510.25206
[8] Reverse-Engineered Reasoning for Open-Ended Generation: https://arxiv.org/abs/2509.06160v1
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。