Qwen3-Next 采用了混合架构让人眼前一亮,其中重要的 Gated DeltaNet 模块设计优雅,最大限度地在工程效率和模型效果之间探索平衡,值得学习了解。
TL; DR
- DeltaNet:线性 attention 可以看作矩阵状态的累积记忆,DeltaNet 通过 delta rule 更加精确地更新 KV 关联,缓解传统线性 attention 记忆过载问题。
- Gated DeltaNet:引入 α 门控,实现选择性遗忘与灵活记忆管理,提高检索精度和稳定性。
本文来看一下 Gated DeltaNet,来自 Qwen3-Next[1],对应博客:Qwen3-Next[2],hybird 架构的又一配置,它算是线性 attention 的一种。内容主要来自 DeltaNet Explained (Part I) | Songlin Yang[3],算是一篇学习笔记。
背景
众所周知,attention 的的计复杂度随序列长度呈二次增长(于是,自然就有了线性 attention 等替代方案)。
- K:上下文 token 的“检索标签”。
- V:上下文 token 携带的实际信息。
- Q:“要从上下文中找什么东西”的 query,检索时,可以直接在完整的 key 列表里搜索。
QK^T:计算 Q 和 K 的相似度,得到每个 token 对当前 query 的重要性。Softmax 后成为归一化的权重(attention)。
前阵子看到一个有意思的说法,”把 Q, K 理解成网络中任意两个节点的一个边“,即:
- token = 网络中的“节点”。
QK^T= 节点之间的“边权”或“连接强度”。
Attention 的注意力权重可以看作动态生成的连接图,它其实是一种数据(token)驱动的动态网络结构。可能这也是 attention 之所以效果好的原因之一吧。
再通俗点,Q 是当前 token 想“问什么”,K 是过去 token 的“索引标签”,V 是过去 token 的“内容”,然后多个 head 拼接起来。
可以这样理解一个 head:当前 token 带着一个 Q,去翻找之前所有 token 的 K,找到最匹配的几个(给它们高权重,其他权重比较低),然后把它们对应的 V 拿过来加权得到结果。最后多个 head 拼接组合成答案。具体过程是:用当前的 Qj 去和所有 Ki 做点积,得到相似度,经过 softmax 得到重要性权重,然后加权求和 Vi 得到最后输出。
从二次到线性
早在 2020年,Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention[4] 提出的线性 attention 用基于核函数的点积线性注意力取代了传统的基于 softmax 的注意力机制,并通过将其重新表述为带有矩阵状态的线性 RNN,大幅降低了推理过程中的内存需求。
早期版本在语言建模任务上表现不如标准 attention ,但最近的改进——比如引入类似 LSTM 的数据依赖型门控机制(如 GLA[5] 和 Mamba2[6])取得了一定效果。
不过,在线性 attention 中,管理长序列信息仍然存在挑战,尤其是在上下文检索任务中,传统 attention 依然保持优势,这是很正常的。
线性 attention 可以被解释为实现了一种基于外积的键值关联记忆,这种记忆方式的容量有限:最多只能存储和模型维度相同数量的正交 key-value 对。当序列长度超过该维度时,“记忆冲突”就不可避免,从而阻碍了精确的检索。
Mamba2 通过引入一个简单的门控更新规则来解决这一局限,St = α_t St−1 + v_t · k_t^T。不过,这种方法并未考虑不同键值关联的重要性差异,可能导致内存利用效率不高。如果模型需要遗忘某个特定的键值关联,那么所有键值关联都会被同等程度地遗忘,使得这一过程缺乏针对性和效率。
结合了 delta rule 的线性 DeltaNet(Linear Transformers Are Secretly Fast Weight Programmers[7]、Gated Linear Attention Transformers with Hardware-Efficient Training[8])能够通过顺序地(软性地)用新键值对替换旧键值对的方式,有选择性地更新记忆。该方法在用于测试上下文检索的合成基准任务中表现出色。然而,由于这一过程一次只能修改一个键值对,模型缺乏快速清除过时或无关信息的能力,尤其是在需要进行上下文切换、必须清空先前数据时。因此,在真实任务中的表现往往仅处于中等水平,这很可能归因于缺乏有效的记忆清除机制。
本文认识到 门控更新规则 与 delta rule 在记忆管理中的优势具有互补性,因此提出了一种简单直观的机制——门控 delta rule。这一统一规则实现了灵活的记忆控制:当设置 αt → 0 时,可以立即清空记忆;而当设置 αt → 1 时,则能够在不影响其他信息的情况下有选择性地更新特定内容(等效于纯 delta rule)。
线性 attention
根据 DeltaNet[9] 的解释,标准 attention 如下:
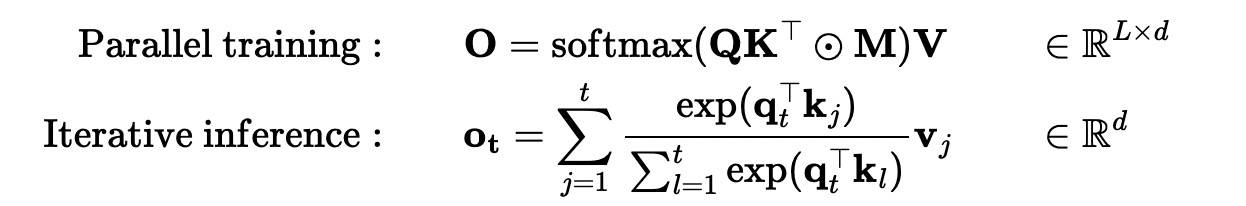
下面的式子是对输出 o 展开后的情况。而线性 attention 如下:
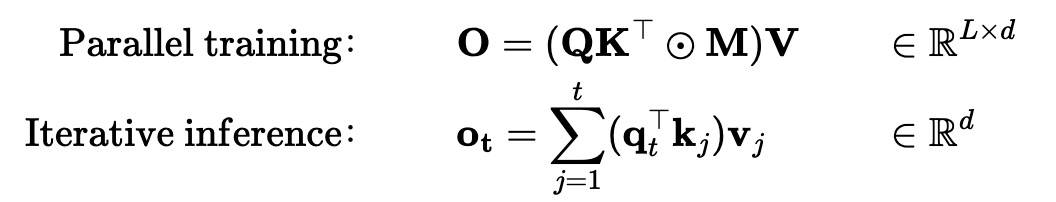
如文章所言,去掉 softmax 并不能立刻降低计算复杂度(矩阵乘法复杂度还是二次方),但是带来了一个关键的数学属性:线性——输入和输出之间是矩阵相乘的形式,可以进行代数操作。这一特性,特别是结合律,能够以高效的方式重构计算。
推理时,可以按下面的方式重写:
前面的等号是因为 qk 相乘是实数:k^T q = q^T k ∈ R,后面的则是结合律:(vk^T)q = v(k^Tq)。
定义状态矩阵:
可以进一步写为:
可以看到,线性 attention 本质上就是一个具有矩阵值状态的线性 RNN。
此时,我们只需要存储和更新 St 而无需维护所有先前的 KV 对,这显著提高了效率:
- 时间复杂度从 𝑂 (
L^2d) 降低到 𝑂 (Ld^2)。 - 空间复杂度从 𝑂 (
Ld) 降低到 𝑂 (d^2) 。
这对于长序列建模比较友好,由于生成过程是 memory-bound,移除 kv cache 在 L 远大于 d 时能够显著降低推理延迟。
记忆对比
看起来很完美,但线性 attention 这种固定大小的状态矩阵意味着它无法完美地保留所有历史信息,使得精确检索变得尤为困难。更正式地说,线性 attention 实现了一种键值关联记忆,它是键和值之间外积的总和。如式(3)所示,就是 t 个 token d×d 外积矩阵的累加。
简单来说,就是每个 key-value 对 (k_j, v_j) 通过外积贡献一块“记忆痕迹”,累加后得到的 M 这个“压缩的全局记忆库”。检索时,就是用 query 去读这个记忆矩阵,
此时,多个 key-value 对会“挤在一起”,互相干扰,导致模型无法精确地检索出原始信息。
而标准 attention 不是像线性 attention 那样直接存 outer-product 当记忆,而是通过 softmax 给每个 query 动态算权重。换句话说,每个 query 都能独立决定“去看哪些 key”,而不是所有 key-value 对都被压缩进一个固定大小的矩阵。没有这种“固定的记忆槽位”的特性使其理论上可以处理任意长度的序列。
它们的对比如下:
| 特性 | 线性 attention | 标准 attention |
|---|---|---|
| 记忆表示 | 所有 KV 外积 → 压缩到固定 d×d 矩阵 | KV 各自单独存储(K V 都是 N×d 矩阵) |
| 容量限制 | 受限于模型维度 d,槽位数 ≈ 维度d,压缩到低维空间 | 受限于序列长度 N(计算/显存成本) |
| 检索方式 | 从压缩矩阵里“解码”出信息(记忆可能冲突),最多存 d 个正交的 K-V 对 | Q 和所有 K 计算相似度,再挑 V, 每个 token 的信息都可以独立被访问,由 softmax 权重控制重点关注哪一个 |
| 检索复杂度 | Q 直接读表 (K决定写到哪一行/列,V 决定内容),复杂度O(1) | 每次看所有 K,看哪个跟 Q 匹配,复杂度 O(N) |
| 类比 | 固定大小的记忆格子,更像压缩的全局记忆表 | 像数据库:K=索引,V=内容,Q=检索 |
| 是否抑制不相关 key | 取决于核函数,基础版本所有 key 线性叠加 | 是,通过 softmax 自动压制低相关项 |
| 是否累积所有历史 | 是,KV 矩阵不断累积 | 不是,每次重新计算权重 |
注意,这里提到的记忆是指“本次输入上下文的临时记忆”。每次输入一个序列,模型都会为其中每个 token 生成新的 KV,像是短期工作记忆。
维度瓶颈和记忆过载
Songlin 大佬在 DeltaNet Explained (Part I) | Songlin Yang[3] 中给出了具体示例,来说明线性注意力机制的这种“记忆过载”问题。根据式(3),假设所有 K 被归一化为单位长度,当我们尝试检索与特定 K 关联的值时,我们有:
意思是,通过 Kj 从 KV对集合中检索对应的值 Vj。
理想情况下,Kj 只应该和它自己对应的 Kj 有高相似度(内积大),和其他 Ki (i≠j) 正交(内积为 0)。但实际上 Ki^T Kj 对于 i≠j 并不等于 0,这会“污染”检索结果,进而产生检索误差。
为啥 K 不正交?因为在一个 d 维向量空间中,最多只有 d 个相互正交的向量。这也是为什么增加 head dimension(即 K 的维度)可以缓解这个问题,因为 “空间更大了”,可以容纳更多正交或相似正交的 K。
这种理论限制在实践中的表现是:在语言建模中,与 softmax attention 相比,普通线性 attention 表现不佳(差距很大)。主要原因是“内存过载”:在这个 K 值关联存储系统中,我们只能添加新的 K 值关联,而无法擦除现有信息。随着序列变长(语言模型中,序列长度一般远大于 K 的维度),这会导致“检索错误”的累积,从而降低性能。这里还引用了 David Eagleman 的话:“记忆的敌人不是时间,而是其他记忆。”
而 softmax attention 是“稀疏化”的:它通过 softmax 把注意力集中在少数几个相关 token 上。本质是“选择性注意”,不是“全量累加”。所以即使 K 不正交,softmax 也能通过归一化抑制不相关的键,从而减少干扰。而线性 attention 是“全量线性组合”,没有这种抑制机制,导致容易被噪声淹没。
近期的门控变体线性 attention(GLA、Mamba)通过结合遗忘机制,显著缩小了语言建模任务中与标准注意力的性能差距。然而,这些模型仍然面临上下文检索和精确复制能力方面的根本挑战,比如难以精确从长上下文中“复制”某个特定 token(填空、复制任务)。有论文证明,线性 attention 在表达能力上天然弱于 softmax attention,尤其在需要“精确匹配”或“稀疏检索”的任务上。
DelataNet
终于来到了我们的主角——DeltaNet。
首先看 DeltaRule,Delta Rule 是神经网络中一项基本的误差校正学习原则。它的核心思想非常简洁:根据期望值(目标值)与实际结果(预测值)之间的差异(delta)来调整模型的参数。
DeltaNet 就是将这种纠错机制应用于线性 attention。它不再简单地累积键值外积,而是基于预测误差来更新自身状态:
注意与式(4)进行对比,多了中间一项,且最后一项多了系数 β。
- βt ∈ R,是学习率。
- kt ∈
R^d,是输入。 - vt ∈
R^d,是目标。 S_{t-1} kt ∈ R^d,是当前预测值。
还有另一种理解方式,把 S_{t-1} kt 想象成从记忆中检索与当前 kt 相关的 “旧的V”。当遇到与同一 K 关联的新值 Vt 时,不是直接盲目覆盖,而是谨慎地进行更新:
其中 Vt new 是旧值和当前值的学习组合,由动态的 𝛽𝑡 ∈ (0,1) 控制:当 𝛽𝑡 = 0 时,存储内容保持不变;当 𝛽𝑡 = 1 时,旧的 V 完全替换为新值。DeltaNet 在 MQAR[10] 和 MAD[11] 上表现不错,超越了其他线性 attention。
为什么 DeltaNet 在上下文检索方面为何更胜一筹?它的更新规则可以通过在每个时间步 t 内依次最小化期望输出和预测输出之间的均方误差(MSE)来推导得出。
最小化损失,
η 为 β 时,就是式(8)。DeltaNet 在每一步都最大限度地减少了 MSE,而减少大错误对于准确检索至关重要。
相较而言,传统线性 attention 采取的是线性损失函数,
负号表示我们希望最大化 ⟨Skt, vt⟩ ,即让 Skt 尽可能接近 vt (从内积角度衡量相似性,完全一致时内积最大)。让模型输出 Skt 尽可能与真实值 vt 相似 —— 这正是我们的学习目标!
计算梯度:
注意这里用到矩阵求导公式:
当 ηt=1 时,式(13)就退化成了标准 attention 形式。
总的来说,DeltaNet 可以真“纠正错误”,让状态精确跟踪目标向量,而线性损失只能“累加信息”,不能纠错、容易漂移且不稳定。换句话说,线性损失是一个累加器,无法撤销之前的错误或不重要贡献。
学习对比
刚刚开始时提到了 Delta Rule,博客[12]也给出了简单实现。
1 | import numpy as np |
看起来和反向传播很像,实际上就是单层线性神经元,我们平时用反向传播一般是多层神经网络+非线性激活。比如之前在 NumPy教程[13]中写过的:
1 | def sigmoid(x, derive: bool = False): |
输出是 sigmoid,一般用于二分类。
网络架构
如下图所示(来自 DeltaNet Explained (Part III) | Songlin Yang[14]),

可以看到,和标准的 Attention 看起来有点类似,不过这里没有旋转位置编码,因为 DeltaNet 目标是构建一个“可训练状态空间模型”,状态动力学本身提供序列敏感性。
qk L2
根据 DeltaNet 核心方程(来自式8),训练的稳定性取决于转移矩阵 At 的特征值,如果 At 不稳定(特征值大于 1),随着 t 的增加,状态会发散,会出现梯度爆炸、模型不收敛的情况,如下所示:
At 在方向 kt 上的特征值为:
推导如下:
所有垂直于 kt 的方向,特征值 = 1,即方向保持不变,如下式所示:
刚刚说了,要使训练稳定,要求特征值局对峙小于等于 1,即:
因为 𝛽 ∈ (0,1),考虑最坏情况(β=1),可以得出:
而 kt 经过 L2 Norm 后,其范数为 1,自然满足条件。同时,当 β=1 时,
是沿着向量 kt 的正交投影矩阵。它可以清除方向 kt 上的信息,
但不改变正交方向:
即除了 kt 方向,其他方向的信息全部保留。这是一种可控的、选择性地遗忘某一个方向的更新方式。
放在 DeltaNet 中,这意味着每次更新都会通过移除可能干扰当前 key 方向的分量来“清理”状态。这有助于随着时间的推移保持不同 key 向量之间更清晰的分离,从而减少前面提到的记忆过载问题。
另外,L2 归一化还可以提升模型性能。这与自注意力架构最新的 QK 归一化趋势相符,Qwen3 使用了 qk-norm,来自图像领域,OLMo 用在 LLM 训练上,可以看这里:R1后范式最佳实践:Seed-Thinking和Qwen3 | 长琴[15]。
输出归一化
The Devil in Linear Transformer - ACL Anthology[16] 证明,线性注意力中的归一化分母会导致梯度发散,进而导致训练不稳定。解决办法是:把分母去掉,先不归一化,等到输出阶段再归一化。这一方法已经成为线性 attention 的主流方法。
Short Convolution
来自 Hyena Hierarchy: Towards Larger Convolutional Language Models | Semantic Scholar[17],也就是 kernel size 很小(比如窗口 4)的 Depthwise Conv1D(每个通道独立做 1D 卷积,不通道混合的轻量卷积),已经成为近年来亚二次注意力模型中的关键组成部分。作者认为它为模型提供了一个“捷径”,使模型能在单层内形成类似 induction head(模型学会“看到 A→B 之后,在后文看到 A,就自动产生 B”的复制机制,可阅读 In-context Learning and Induction Heads[18])的结构,从而大幅提升模型的 in-context learning 能力。甚至在传统 softmax attention 的大规模训练中,小卷积也被证明是有帮助的。
实验结果表明,Short Convolution 和 qk L2 一样,都是非常重要的组件。
Gated DeltaNet
Gated DeltaNet 是 DeltaNet 的升级版,来自 Gated Delta Networks: Improving Mamba2 with Delta Rule[19],其实就是在 DeltaNet 的基础上加了一个门控:
式 24 在式 8 的基础上增加了 α ∈ (0, 1)。它结合了门控机制和 Delta 规则的优点:门控项使得记忆能够自适应管理,而 delta 更新结构则促进了有效的 KV 关联学习。
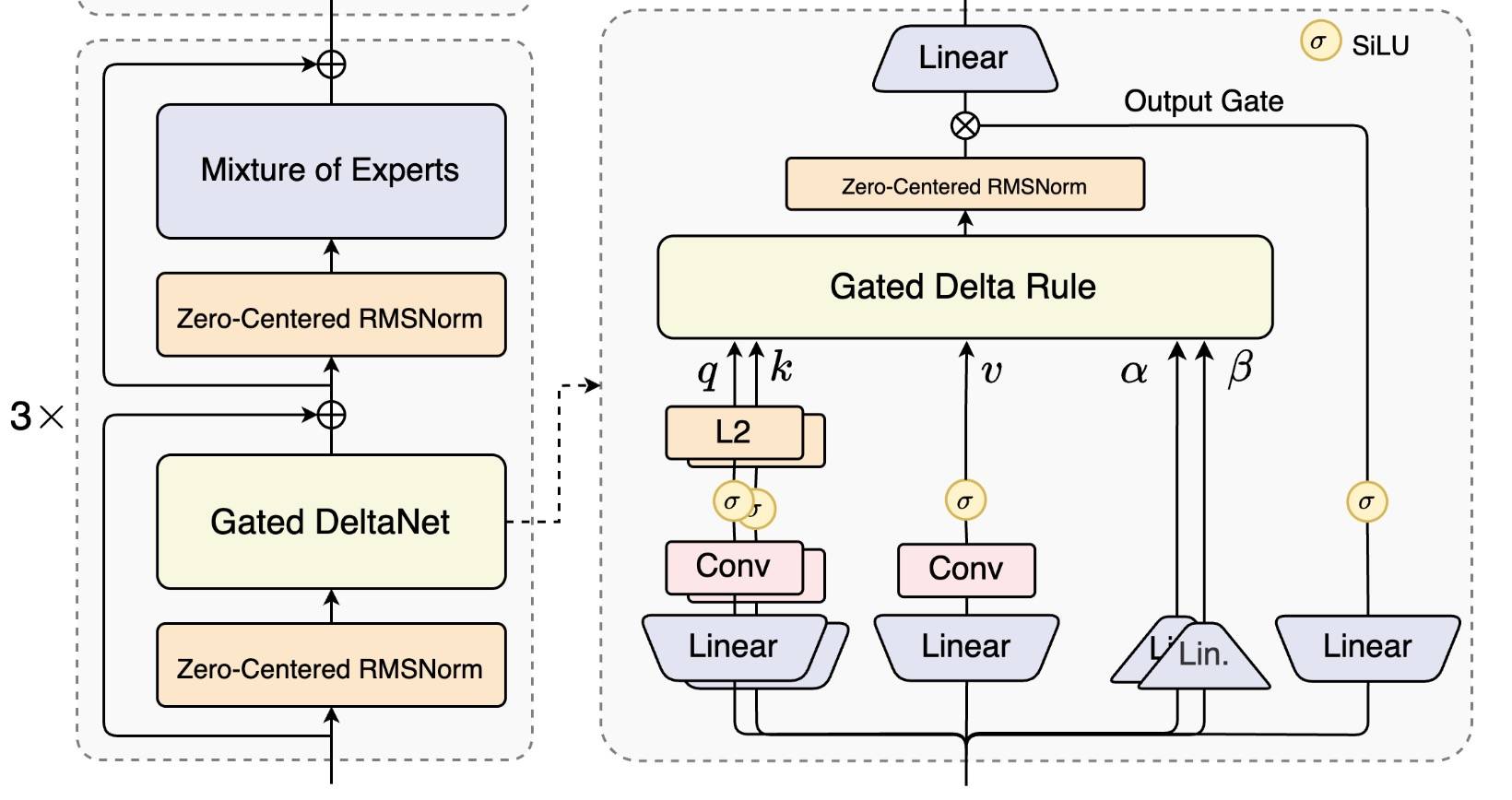
如上图(来自 Qwen3Next[20])所示,和标准 transformer 相比,就是把 attention 换成了 Gated DeltaNet。
其实,“Gated”这个技巧被用在很多地方,我们上篇 Hybrid LLM 之 Gated Attention | 长琴[21] 就是,而且我们还在后面提到了“非LLM时代的 Gated Attention”和“非Attention的Gated”,感兴趣的朋友不妨再回去看一下。
混合架构
虽然 DeltaNet 在检索任务中表现不错,但仍然面临所有 RNN 架构共有的一个根本限制:状态向量的维度是固定的。这个限制导致检索能力存在天然的上限,无论采用什么样的状态更新规则都无法突破。
于是就有了混合架构,比如 Qwen3Next[20],就是 3:1 的混合比例,即 75% 层使用 Gated DeltaNet,25% 层保留标准注意力。
小结
本文简单介绍了一下混合架构中的 DeltaNet,没有太深入细节,也没有涉及比较复杂的代码实现,感兴趣的朋友不妨进一步阅读原文[22]。这么多研究者绞尽脑汁在线性 attention 上,无非是想尽可能地提升模型效率,尤其是降低长上下文的计算开销。注意,主要不是效果,full attention 的效果还是很经得住考验的。
前阵子 MiniMax M2[23] 回归 full attention 也说明了一些问题,因此 M2 的选择是从其他方面提升效率,诚如其在博客 Why Did M2 End Up as a Full Attention Model? - MiniMax News[24] 中所言:“在当前的计算限制下,没有任何模型真正将 softmax attention 推到极限。所以,从实际应用角度来看,高效注意力之间的竞争,本质上就是谁能省算力。对于我们的 M2 设计,我们能否靠节省 token 数实现同样的目标?如果你相信 scaling law,为了实现这个目标,你大概会押注其他途径,而不是高效注意力机制。”
Anyway,混合架构作为工程方案是值得考虑的,尤其是现在上下文越来越长的情况下。而且其算法设计也比较有意思,值得学习。
References
[1] Qwen3-Next: https://huggingface.co/Qwen/Qwen3-Next-80B-A3B-Instruct
[2] Qwen3-Next: https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list
[3] DeltaNet Explained (Part I) | Songlin Yang: https://sustcsonglin.github.io/blog/2024/deltanet-1/
[4] Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention: https://arxiv.org/abs/2006.16236
[5] GLA: https://arxiv.org/abs/2312.06635
[6] Mamba2: https://arxiv.org/abs/2405.21060
[7] Linear Transformers Are Secretly Fast Weight Programmers: https://arxiv.org/abs/2102.11174
[8] Gated Linear Attention Transformers with Hardware-Efficient Training: https://arxiv.org/abs/2312.06635
[9] DeltaNet: https://sustcsonglin.github.io/blog/2024/deltanet-1/
[10] MQAR: https://arxiv.org/abs/2312.04927
[11] MAD: https://arxiv.org/abs/2403.17844
[12] 博客: https://sustcsonglin.github.io/blog/2024/deltanet-1/
[13] NumPy教程: https://github.com/datawhalechina/powerful-numpy/blob/main/src/introduction/ch-all.ipynb
[14] DeltaNet Explained (Part III) | Songlin Yang: https://sustcsonglin.github.io/blog/2024/deltanet-3/
[15] R1后范式最佳实践:Seed-Thinking和Qwen3 | 长琴: https://yam.gift/2025/05/01/NLP/LLM-Training/2025-05-01-Seed-Thinking-Qwen3/
[16] The Devil in Linear Transformer - ACL Anthology: https://aclanthology.org/2022.emnlp-main.473/
[17] Hyena Hierarchy: Towards Larger Convolutional Language Models | Semantic Scholar: https://www.semanticscholar.org/paper/Hyena-Hierarchy%3A-Towards-Larger-Convolutional-Poli-Massaroli/998ac3e945857cf2676ee7efdbaf443a0c6f820a
[18] In-context Learning and Induction Heads: https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html
[19] Gated Delta Networks: Improving Mamba2 with Delta Rule: https://arxiv.org/abs/2412.06464
[20] Qwen3Next: https://qwen.ai/blog?id=4074cca80393150c248e508aa62983f9cb7d27cd&from=research.latest-advancements-list
[21] Hybrid LLM 之 Gated Attention | 长琴: https://yam.gift/2025/09/25/NLP/LLM/2025-09-25-Hybrid-Gated-Attention/
[22] 原文: https://sustcsonglin.github.io/blog/2024/deltanet-1/
[23] MiniMax M2: https://www.minimax.io/news/minimax-m2
[24] Why Did M2 End Up as a Full Attention Model? - MiniMax News: https://www.minimax.io/news/why-did-m2-end-up-as-a-full-attention-model