TL;DR
-
EXAONE: 改进 GRPO,通过移除 Clip 保留探索性 Token,并利用非对称采样引导模型远离错误路径。
-
Kimi: 从 KKT 条件推导出 RL 目标函数,将长推理过程视为“隐式搜索”,并利用逐步升温长度惩罚解决“过度思考”问题。
-
MiMo: 采用反向 KL 散度进行多教师蒸馏(MOPD),实现“寻找众数”的精准能力迁移。
-
MiniMax: 针对 GRPO Clip 问题,采用带 Stop-gradient 的重要性采样与 Token Mask 机制,不丢弃探索梯度同时确保训练平稳。
-
Qwen: 将重要性权重回归序列级别,引入长度归一化解决 Token-level 高方差,同时增强了 MoE 路由的稳定性,并进一步演进为平滑剪裁的 SAPO。
结论: 行业正从简单的奖励最大化转向更精细的分布对齐、隐式规划引导和训练稳定性控制。
这是一篇开始的比较早的文章了,一直没写完,正好赶上最近几个团队多有新作发布,就一并梳理掉吧。
EXAONE
最开始是想写 2507 EXAONE 4.0: Unified Large Language Models Integrating Non-reasoning and Reasoning Modes[1] 这篇文章的,主要是它提出的 AGAPO 优化方法,也算是 GRPO 的变种。
做法如下:
- 移除 clip,避免丢弃探索性 token。这个探索性 token 我们在 GRPO优化在继续——CISPO和熵 | 长琴[2] 中我们提到过,当时的做法是,通过使用裁剪并断开梯度的熵项增强优势函数。
- 非对称采样,对于全错样本,不是全部丢弃,而是在优势计算中会分配一个较小的负奖励,这种负反馈用以引导模型远离错误的推理路径。这和 DAPO[3] 的动态采样不一样,倒是和 CISPO[4] 思想有点类似。
- 组级与全局优势,组内使用 LOO 计算优势,在 batch 内归一化。这应该来自 Reinforce++和它的KL Loss选择 | 长琴[5]。
- 序列级累计 KL,引入 KL 惩罚项目的是保留 SFT 阶段学到的能力。
最终损失函数如下:
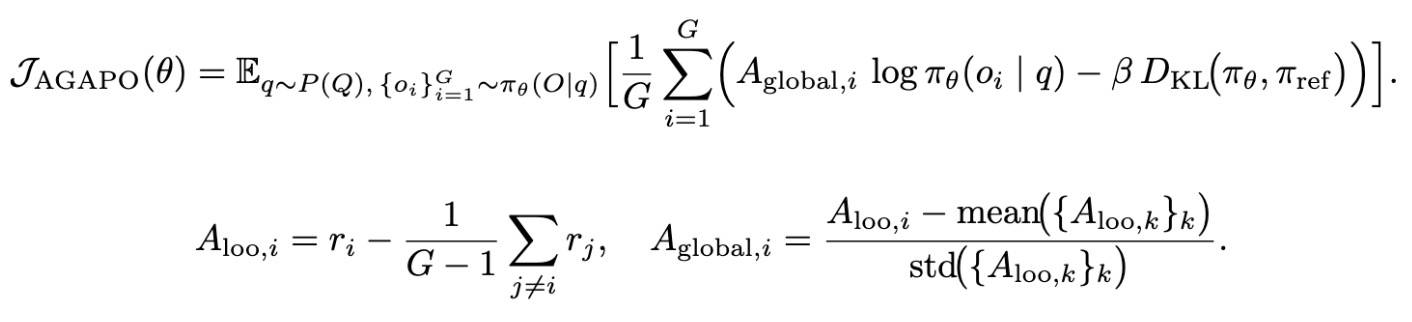
有意思的是,它的后续版本 2601 K-EXAONE Technical Report[6] 还是用的它,不过稍微有一点点额外的调整。
- 借鉴 MiniMax M1 的 CISPO[4],采用了带截断重要性采样的 off-policy 梯度目标。
- 使用零方差过滤:对于其采样 rollout 获得完全相同奖励、从而优势值为零的 prompt,直接予以丢弃。
- 去除了 KL 惩罚项。这是 ORZ[7] 的做法。
- 在整个 RL 训练阶段,冻结 MoE 的 router。
最终损失函数如下:
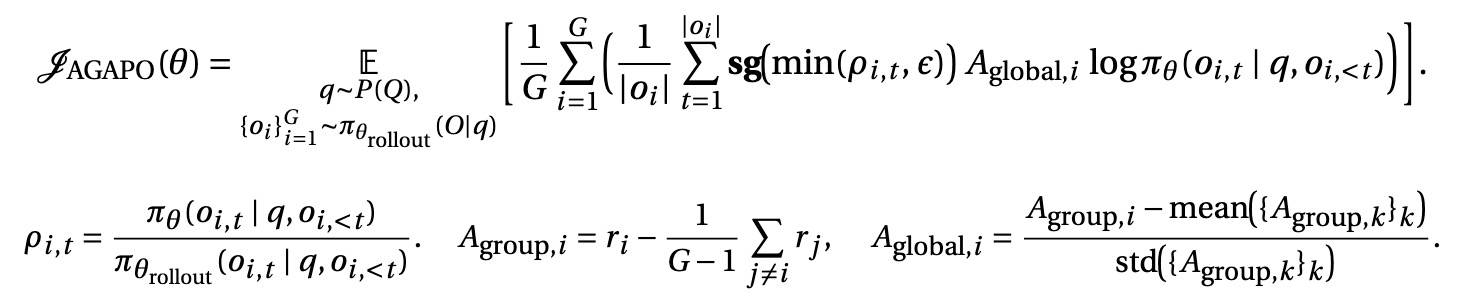
Kimi
Kimi-1.5 和 Kimi-2 都用了同一套优化方法,这是从优化角度重新从头到尾梳理后得出来的方法,过程极其有意思。我们来重点看看。
优化视角
Kimi 从解决复杂问题的 CoT 方法出发,自然转到进一步增强推理能力的 planning 方法,并提出,这些方法的核心思想在于:在价值估计的引导下,显式地构建一个由“思路”(thoughts)组成的搜索树。
“思路(thoughts)”和“反馈(feedbacks)”都可以被视为中间推理步骤,而且这两者都可以表示为语言 token 的序列。因此,可以将一个规划算法视为一个直接作用于推理步骤序列的映射。
在这一框架下,规划算法所使用的搜索树中存储的所有信息,都被展平为提供给算法的完整上下文。这为生成高质量 CoT 提供了一个耐人寻味的视角:与其显式地构建搜索树并实现规划算法,不如训练一个模型去近似这一过程。
以上都是 Kimi-1.5 的原文。看到了么,从优化出发,自然地转到用 LM 去近似。这点在之前其他论文是没有提过的。
文章继续说道,在这里,思考的数量(即语言 token 的数量)可以类比为传统规划算法中分配的计算预算。长上下文窗口能力使得这种方法在训练阶段和测试阶段都能够无缝扩展。如果这一设想可行,模型就能够通过自回归预测,在推理空间中隐式地执行搜索。由此,模型不仅学会解决一组训练问题,还会逐步具备有效处理单个问题的能力,从而在未见过的测试问题上表现出更强的泛化能力。
换句话说,用 LM 近似其实本质上还是在做优化,只不过是在“隐式”地进行。我很喜欢这一部分的分析,必定出自某个优化大佬。
然后,很自然地才到了 RLVR,生成 CoT 的质量由其是否能够导向正确的最终答案来衡量。优化目标就是奖励期望最大化。
RLVR 的目标是:训练一个能够同时发挥基于简单提示的 CoT与引入规划机制的 CoT各自的优势。在推理阶段,模型仍然以自回归的方式采样语言序列,从而避免了在部署时采用复杂规划算法所需的高成本并行化机制。
这是对前面定性分析的实践描述。
论文继续分析这一方法与简单的基于提示的方法的区别:模型不应只是机械地遵循一系列既定的推理步骤。相反,它还应当利用已探索的全部思路集合作为上下文信息,学习关键的规划能力,包括错误识别、回溯以及解法的逐步改进与精炼。
有没有一种追本溯源,形成闭环的感觉。对 GRPO 和 RL 的理解无疑能更上一层,真是相见恨晚!
策略优化
KKT
我们先从 KKT 说起,瞬间回到了 Hard-SVM, Soft-SVM 和 KKT | 长琴[8] 啊!KKT = Karush–Kuhn–Tucker,是用来解决这样一类问题:
即在约束条件下目标函数的最优解。
因为有了约束,所以直接求导还不够,因为最优解可能在边界上,导数不一定为 0,因此必须把“约束”纳入一阶条件,这就是为什么需要 KKT 条件。这是运筹规划领域非常常见的一类问题。
为了把“约束”放到目标函数,就引入了拉格朗日函数:
λ 和 μ 分别是等式和不等式的约束因子。
我们都知道 KKT 有四个条件[9],
分别是:驻点条件、互补松弛条件、可行性、对偶可行性。
KKT到RL
其实迄今为止我们知道的大部分 RL 问题都可以看成一个约束优化问题,
引入不等式约束乘子 μ≥0,
这里有两个隐含约束:
对于每个 y 的概率约束(省掉最后一项常数项),
对 π(y) 求导并让其等于 0,
整理后得,
两边 exp,
最后一项是常数。上式两边对 y 求和,
上式左边必须等于 1,于是,
令分母和项为 Z,于是我们有,
进一步化简可以得到,
左边是 reward + 常数(Z 对每个 x 是常数),右边是最优策略相对于 reference 或旧策略 的 log-ratio。在每一轮,πi 不更新,仅用来采样、计算 KL,并做 log-ratio 的基准。
Surrogate Loss
我们不知道最优的 π(π∗),但可以从 ref/旧策略 采样,让 πθ 去拟合这个等式。也就是让上面式子尽量相等。
于是,可以构造一个平方损失,
用旧策略 πθᵢ 的样本,回归一个 log-ratio + reward 的线性关系,当 loss→0 时:πθ→π∗。
不过 μ logZ 我们并不知道,因为 action 空间巨大,不好计算。注意,它在梯度里只起到 baseline 的作用(常数),它不依赖于 y,影响方差,但不影响期望。
论文提到两种估计方法,方法一是蒙特卡洛 log-sum-exp,用 k 个样本采样近似:
方法二是,作者发现,使用抽样奖励的经验平均值效果不错:
论文说,当温度参数 μ 变得很大时,μ logZ会收敛到在参考策略 πθi 下的期望奖励,所以用样本平均奖励去近似是合理的。根据 Z 的表达式,我们有:
当 μ→∞ 时,r/μ≈0,对指数函数做一阶泰勒展开,
两边取 log,
利用泰勒展开 log(1+x) = x + O(x^2),得到,
注意,x 平方每一项的阶都是 O(1/μ^2) 或更小,因此可以吸收到二阶项,O(x^2) = O(1/μ^2)。最终得到,
也就是说,当 μ 很大时,μ logZ 近似等于期望 reward。
代入式(15)求导,可得:
除以 -2μ,在 k 个 response 上的梯度就是文章给的式子,
注意,该 loss 的目的在于施加一阶最优性条件,使残差趋近于 0。我们关心的是其驻点而非严格的下降路径,因此在推导中忽略整体符号和尺度常数是可以的。
式子左边看起来很熟悉,这不就是 REINFORCE with baseline 么?主要区别在于采样不是来自当前策略 πθ,而是来自参考策略 πθi(off-policy)。而式子右边就是一个 log-ratio 的 L2 惩罚,这不正是 KL 的 K2 估计[10]么?或者说,它就是一个 K2 风格的 KL 正则。现在再结合式(5),看起来更加清楚。很多 RL 算法其实也是这个基准的变体。
价值函数
价值函数在 RLVR 场景下可能不适用,文中举了个例子:一个包含一定错误的推理步骤,可能相对于当前策略具有负优势而受到惩罚。但如果它最终能成功纠错并最终到达正确答案,它就可以从这种“试错”过程中学习到有效的模式。这种学习过程反而是应该特别鼓励的,诚如文章所言:“我们应当鼓励模型探索多样化的推理路径,以增强其解决复杂问题的能力。这种探索式训练会产生大量有价值的经验,支持模型关键规划能力的形成。我们的主要目标并不局限于在训练问题上获得高准确率,而是着眼于为模型赋予有效的问题求解策略,从而最终提升其在测试问题上的整体表现。”
长度惩罚
针对训练过程中观察到的“过度思考”现象,引入“长度奖励”抑制 token 长度的快速增长,从而提升模型的 token 使用效率。如果一组响应的 max_len = min_len,表示所有响应的长度相同,此时长度奖励=0,否则根据下式计算,
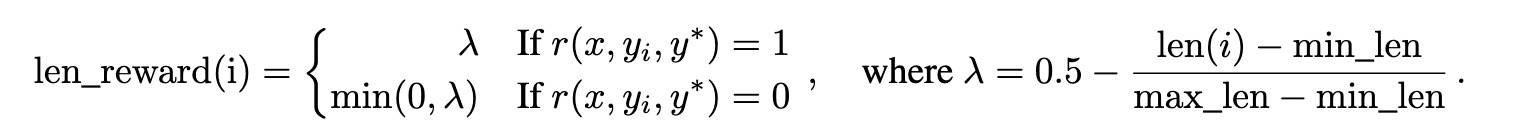
本质上鼓励生成较短的正确回答,并对较长的正确回答进行惩罚,同时明确对答案错误且过长的回复施加惩罚。
实验中发现,长度惩罚在训练初期可能会导致训练速度变慢。为缓解这一问题,在训练过程中逐步“升温”长度惩罚的策略,即训练初期采用标准策略优化而不加入长度惩罚,随后在训练的剩余阶段施加固定的长度惩罚。
采样
采用了两种采样方法提高训练效率。
- 课程采样:从较容易的任务开始训练,逐步过渡到更困难的任务。
- 优先采样:重点关注模型表现不佳的问题,按 1-成功率 的比例采样。
Mimo
Mimo[11] 的 RL 遵循标准的 GRPO,同时借鉴了几个新的实践方法。
MiMo-V2-Flash[13] 采用了一个被称为 MOPD(multi-teacher on-policy distillation)的方法,将多教师(领域)蒸馏表述为一个在线策略强化学习目标。
反向KL
学生策略与教师策略之间的反向 KL 散度损失定义为:
为什么是反向 KL?这不禁让人想起了 MiniLLM[14] 这篇论文,请看下图:
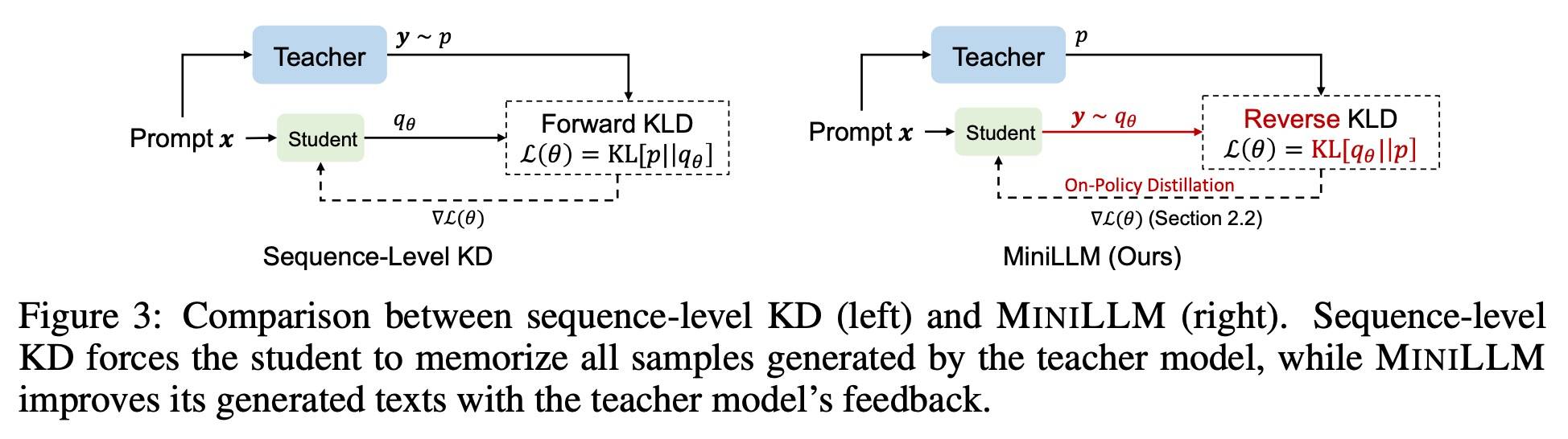
p 是教师模型,q 是学生模型。左边是我们非常熟悉的正向 KL,右边则是反向 KL,它们的区别如下:
| 正向KL | 反向KL | |
|---|---|---|
| 采样 | 从教师模型采样 | 从学生模型采样 |
| 公式 | D(T|S) = E_T (log T/S) | D(S|T) = E_S (log S/T) |
| 特性 | Mean-fitting,均值拟合 | Mode-seeking,寻找众数 |
正向 KL,学生模型会试图覆盖教师模型的所有概率区域。如果老师有两个峰,学生会试图变胖来把两个峰都盖住。这是传统监督学习蒸馏常用的方式,也是我们非常熟悉的方式。
反向 KL,学生模型会倾向于锁定在教师模型的一个高概率波峰上,而忽略其他区域。这意味着学生模型会避免学习教师模型中大量的长尾分布,生成的结果会更加真实可靠。这非常适合 MiMo-V2-Flash 这种多领域蒸馏的情况——蒸馏每个领域教师的擅长能力。
最终 Loss 写成如下形式,
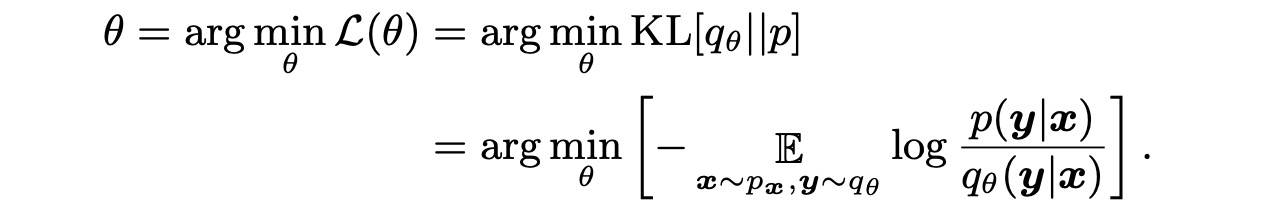
可以看到,这和式(25)是一样的。
MOPD Loss
采用来自 𝑰𝒄𝒆𝑷𝒐𝒑![15] 的训练-推理重要性采样,舍弃那些差异较大的 token。IcePop(冰棒)主要是稳定 MoE 训练的。MOPD 的代理损失如下:
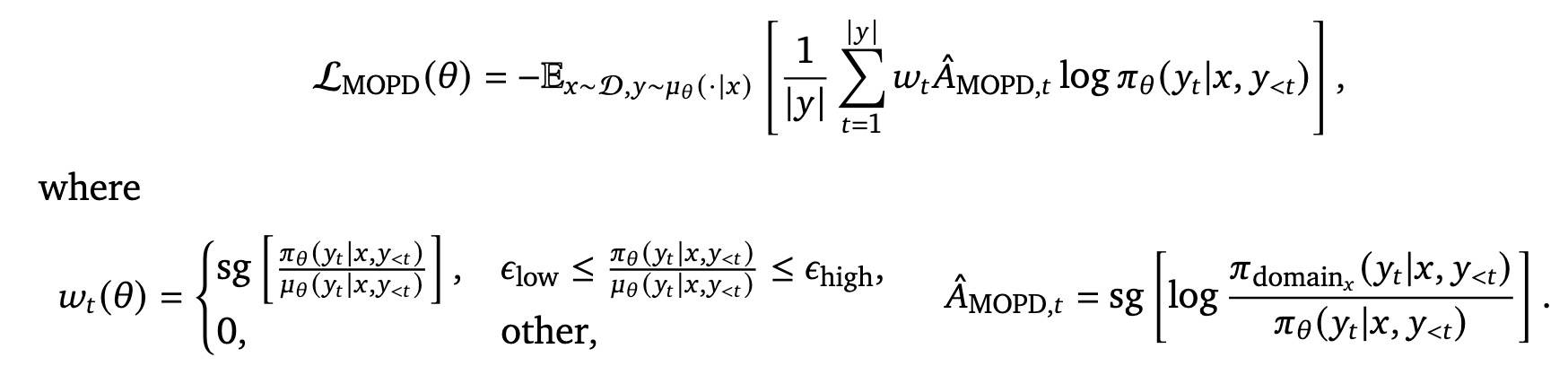
MOPD 的优势会与其他类型的优势结合使用,
这个损失来自 MiniMax-M1[16] 的 CISPO[4],从标准 REINFORCE 出发,引入重要性采样比率(off-policy 与采样分布不一致)。不同的是,MOPD 是序列级别的。
MiniMax
既然刚刚提到了 CISPO,这里就再一并回顾一下 MiniMax-M1 提出的这个 RL 优化算法。MiniMax-M2 没有 paper,想来应该和 M1 差别不大(当然,我们知道 M2 用了 Full Attention)。
CISPO 我们此前在 GRPO优化在继续——CISPO和熵 | 长琴[2] 中专门介绍过,也是观察到 GRPO 中的不当 clip 可能会将关键推理 token 剪掉,导致无法参与后续梯度更新。因此,CISPO 被设计为明确避免丢弃 token,即使是那些对应较大更新的 token,同时通过内在机制将熵控制在合理范围内,以确保探索过程的稳定性。损失函数如下(直接截博客图了):
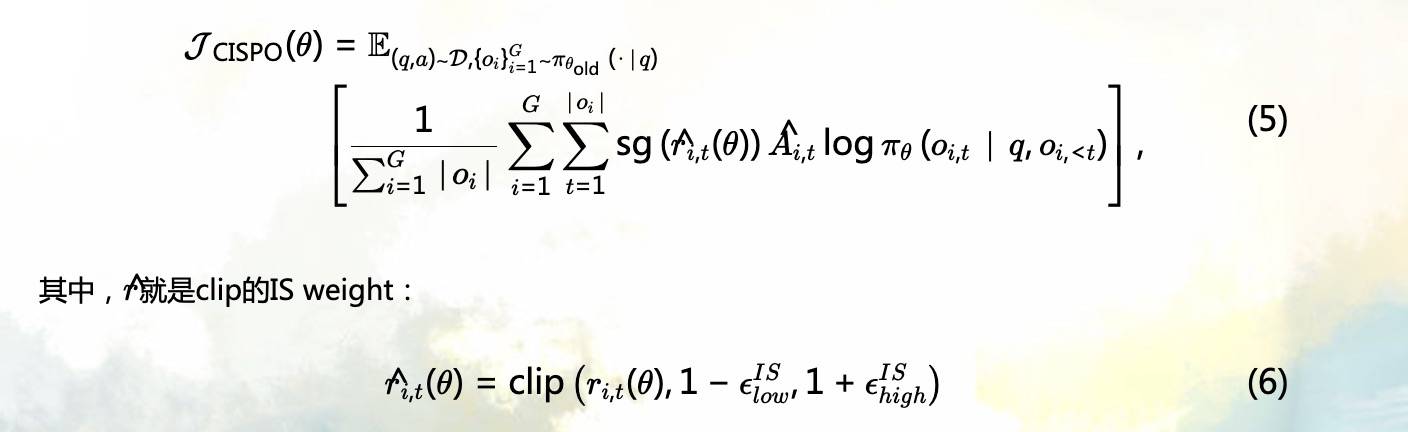
这里 sg 意思是将 IS 当做一种固定的 reweighting 因子,衡量采样分布和目标分布(新旧策略)之间的差异。不参与梯度就不会因为 clip 导致 update 被截断,进而导致 token update 被强行剪掉。
另外,还提出一个通用公式,引入一个按 token 的 mask,然后就可以通过超参数调优来控制是否以及在何种条件下应舍弃来自特定token 的梯度。

简单来说,就是让过分放大奖励和过分惩罚的 token 损失为0,完全不参与梯度更新,一定程度上等价于 PPO 带梯度的的 clip。
Qwen
既然回顾到这里了,也一并回顾下 Qwen3 的吧,Qwen3 发布的比较早,当时 paper 没有详细披露 RL 设计,不过后面专门发了相关论文,就是这篇 2507 Group Sequence Policy Optimization[17],也简称 GSPO。我们在 GRPO“第一背锅侠”Token Level X:DAPO/DrGRPO与GSPO/GMPO的殊途同归 | 长琴[18] 中介绍过这个研究。
GSPO 引入了长度归一化,目的是解决 token 级别的重要性权重计算方式在训练中引入的高方差噪声。因此,重要性权重的单位应该和奖励的单位一致,都是序列级别的。损失函数设计如下(还是直接截博客图):
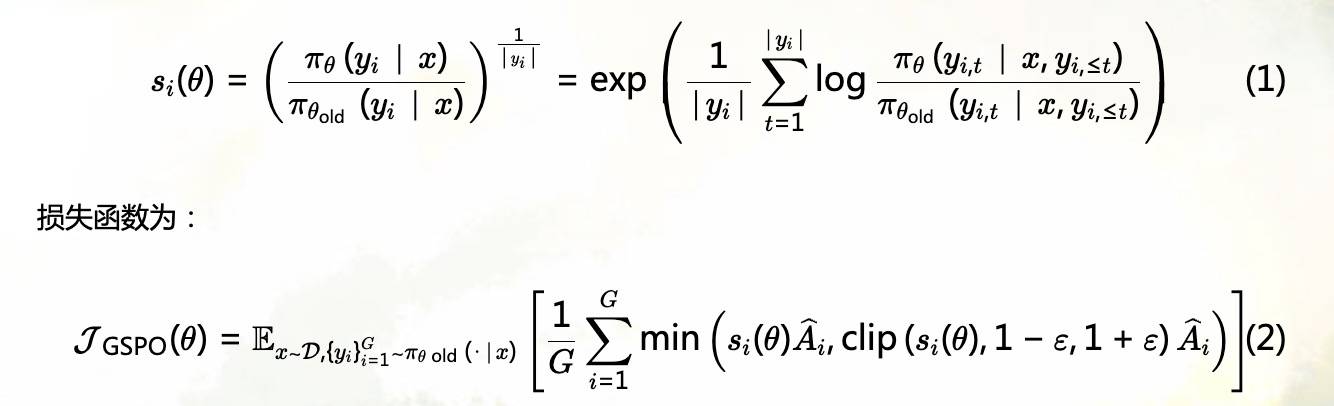
当然,后面还有一个 token 级别的变种,这里就不贴了。由于 GSPO 仅关注序列级的似然,反而能使 MoE 的训练更加稳定(专家激活波动会导致训练无法正常收敛),这也算是一个整的外部性了。
Qwen 团队近期还发表了一篇动态 clip 的升级版本:2511 Soft Adaptive Policy Optimization[19],让训练更加稳定。
小结
本文我们赏鉴了几个有名开源模型的 RL 设计,除了 Qwen3,其他几个模型都是近期有新版本发布,看完就想正好整理一下。印象比较深的还是 Kimi,比较喜欢从头推导。其他的做法相对比较实践,其实另一个非常工业化的是美团,他们的 2510 Higher Satisfaction, Lower Cost: A Technical Report on How LLMs Revolutionize Meituan’s Intelligent Interaction Systems[20] 真是延续了其技术博客[21]的工业实践性。总之,看得很爽,写得更爽,希望你也能看得爽。
最后,附上一张 AI 整理的图,我做了一些校正。
| 模型 / 算法 | 核心优化目标 | 稳定性控制 | 新颖点 | 解决的痛点 |
|---|---|---|---|---|
| EXAONE (AGAPO) | GRPO 变体 + 序列 KL | 移除 Clip,保留探索性 Token | 非对称采样(针对全错样本分配负奖励) | 避免过度裁剪导致的探索不足 |
| Kimi (RLVR) | KKT 推导下的 Surrogate Loss | L2 风格的 log-ratio 惩罚 | 隐式搜索树近似;升温长度惩罚 | 推理回溯能力与“过度思考”平衡 |
| MiMo (MOPD) | 反向 KL (Mode-seeking) | 训练-推理重要性采样截断 | 多教师在线策略蒸馏 | 多领域专家能力精准迁移 |
| MiniMax (CISPO) | REINFORCE + IS 重加权 | Stop-gradient;门控 Mask | 不剪断数据流,只剪断风险梯度 | 防止关键推理 Token 梯度丢失 |
| Qwen (GSPO) | 序列级策略优化 | 长度归一化 + 序列级似然 | 权重单位与奖励单位对齐 | Token 级高方差及 MoE 路由波动 |
References
[1] 2507 EXAONE 4.0: Unified Large Language Models Integrating Non-reasoning and Reasoning Modes: https://arxiv.org/abs/2507.11407
[2] GRPO优化在继续——CISPO和熵 | 长琴: https://yam.gift/2025/06/19/NLP/LLM-Training/2025-06-19-CISPO-and-Entropy/
[3] DAPO: https://yam.gift/2025/03/19/NLP/LLM-Training/2025-03-19-LLM-PostTrain-DAPO/
[4] CISPO: https://yam.gift/2025/06/19/NLP/LLM-Training/2025-06-19-CISPO-and-Entropy/
[5] Reinforce++和它的KL Loss选择 | 长琴: https://yam.gift/2025/10/24/NLP/LLM-Training/2025-10-24-ReinforcePP/
[6] 2601 K-EXAONE Technical Report: https://arxiv.org/abs/2601.01739
[7] ORZ: https://yam.gift/2025/02/27/NLP/LLM-Training/2025-02-27-LLM-PostTrain-PPO-Data/
[8] Hard-SVM, Soft-SVM 和 KKT | 长琴: https://yam.gift/2020/08/13/ML/2020-08-13-SVM-Hard-Soft-KKT/#对偶问题
[9] KKT 有四个条件: https://www.stat.cmu.edu/~ryantibs/convexopt-F16/scribes/kkt-scribed.pdf
[10] K2 估计: http://joschu.net/blog/kl-approx.html
[11] Mimo: https://arxiv.org/abs/2505.07608
[12] orz: https://yam.gift/2025/02/27/NLP/LLM-Training/2025-02-27-LLM-PostTrain-PPO-Data/
[13] MiMo-V2-Flash: https://arxiv.org/abs/2601.02780
[14] MiniLLM: https://arxiv.org/abs/2306.08543
[15] 𝑰𝒄𝒆𝑷𝒐𝒑!: https://ringtech.notion.site/icepop
[16] MiniMax-M1: https://arxiv.org/abs/2506.13585
[17] 2507 Group Sequence Policy Optimization: https://arxiv.org/abs/2507.18071
[18] GRPO“第一背锅侠”Token Level X:DAPO/DrGRPO与GSPO/GMPO的殊途同归 | 长琴: https://yam.gift/2025/08/14/NLP/LLM-Training/2025-08-14-Token-Level-GSPO-GMPO/
[19] 2511 Soft Adaptive Policy Optimization: https://arxiv.org/abs/2511.20347
[20] 2510 Higher Satisfaction, Lower Cost: A Technical Report on How LLMs Revolutionize Meituan’s Intelligent Interaction Systems: https://arxiv.org/abs/2510.13291
[21] 技术博客: https://tech.meituan.com/
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。