paper: Reformer: The Efficient Transformer
code: trax/trax/models/reformer at master · google/trax
Abstract
Transformer 在训练时成本过高(尤其是长句子),文章提出两种改进方法:
- 将点乘的 attention 替换为局部敏感哈希,复杂度从 O(N^2) 降为 O(N logN),N 为句子长度。
- 标准残差 Layer 替换为可逆残差 Layer,使得训练中只存储一次激活值,而不是 N 次,N 为 Layer 数量。
Introduction
现状:多参数(0.5B 每层)、多层(64)、长序列(11000,音乐、图像更长)。
除此之外还需要考虑以下资源占用:
- N 层需要存储 N 次激活值用来反向传播。
- 前向传播层也会占用大量内存。
- 序列长度在计算和存储上都是 O(N^2) 复杂度
Reformer 使用的技术:
- Gomez et al. (2017) 提出的可逆层,整个模型存储一份激活值。
- 分离前向传播层的激活值,放在块中节约内存。
- 基于 LSH 的近似 Attention。
结果显示和标准 Transformer 相比,训练过程影响不大。只有 LSH 可能会影响训练。
LSH Attention
Memory-efficient attention
将标准的 Dot-product Attention 改为每次只计算一个 Q:
这样虽然效率降低了,但只使用和序列长度成比例的内存。
Where Q, K, V come from
注意此时每次只传一个激活张量。正常情况下使用 3 个不同的线性层,在这里 QK 使用同一个线性层(shared-QK Transformer),实验显示这并不影响性能。
Hashing attention
计算 $$QK^T$$ 时,对每个 Qi 只关注 K 中最相近的 m 个 key。
LSH
就是用来寻找上面提到的最相近的 m 个 key。LSH 表示对向量哈希,相近的向量有较高概率得到相似的哈希结果,而不相近的则相反。
(Andoni et al., 2015) 提出的哈希方法,为了获得 b 个哈希,先固定一个随机矩阵 R:
LSH attention
首先重写标准的 Attention,对一个单独的 query position i 在某一时刻:
Pi 表示位置 i 处查询所涉及的集合,z 表示分开的函数(比如 softmax 中的归一化项)
为了 Batching,设置 $$\widetilde{\mathcal{P}}_i = {0, 1, …, l} \supseteq \mathcal{P}_i$$,mask 掉不在 Pi 中的元素:
然后考虑 LSH attention,其实就是限制一个 query position 的 Pi:

上图的 a-b 显示出 LSH 的不同:a 图显示 attention 矩阵是稀疏的,但是计算时并没有利用这一点;b 图的 qs 和 ks 根据 hash bucket 排序,相似的 attention 就以较高概率落在了同一个 bucket,这样原来的 attention 就可以通过每个 bucket 的 attention 近似得到。
此时,每个 bucket 往往大小不同,不方便跨桶批处理;另外 qs 和 ks 的数量可能不相等(实际上一个 bucket 可能包括一些 qs 但是没有 key)。解决这个问题的方法如下:
- 设 $$k_j= \frac{q_j}{||q_j||}$$ 使得 $$h(k_j) = h(q_j)$$
- 根据 bucket number 排序,在每个 bucket 中,根据 sequence 的位置
如 c 图所示,同一个 bucket 的会聚集在对角线附近。然后可以把 m 个连续的 qs 作为一块作为 batch,如图 d 所示,对应如下设置:
实际中设置 $$m = \frac{2l}{n_{bucket}}$$,l 是序列的长度,平均 bucket 大小为 $$\frac{l}{n_{bucket}}$$,并且假定 bucket 增长到两倍大小的概率足够低。
Multi-round LSH attention
哈希时总是有很小的可能性将相似的项目放入不同的存储桶中,可以通过多轮哈希降低这种可能性:
Causal masking for shared-QK attention
为了在 LSH Attention 中应用 masking,将每个 query/key 向量与位置索引相关联,使用用于对 query/key 向量进行排序的相同排列对位置索引重新排序,然后使用比较操作来计算掩码。
除非没有其他有效的 attention 对象,否则不允许一个位置和自己计算 attention,因为这种 attention 一般比和其他位置的计算结果更大。
上面这块是真的云里雾里,没有特别看懂,先记一下。。。
Analysis on a Synthetic Task
这个任务(复制符号序列)主要是确认 LSH Attention 的性能表现。
-
每个训练和测试数据都是 0w0w 的形式,
w ∈ {1,...,N=127} -
每个 w 长度 511,总长度 1024
-
根据之前的符号预测下一个符号,只考虑序列的后半部分
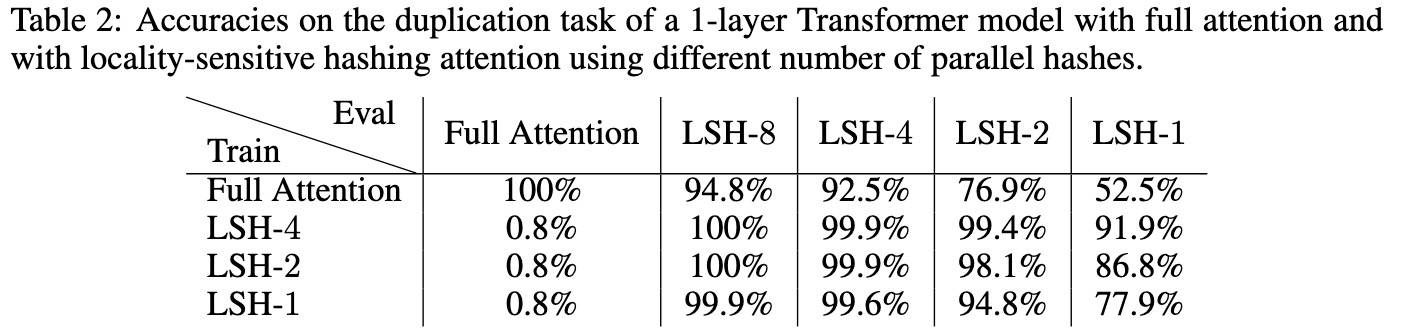
结果显示,原 attention 和 LSH attention 可以一起使用,只是精度降低了。4 个哈希的模型达到了几乎完美的精度。
Reversible Transformer

从上表可以看出,每一层前的激活函数已经是 b·l·d_model 的大小了,所以 n_l 层 layer 的内存至少也是:b·l·d_model·n_l,更糟糕的是,在 Transformer 的前馈层中将会进达到:b·l·d_ff·n_l,大 Transformer 中 d_ff = 4k,n_l = 16,如果 l=64k,这要再用掉 16G(一个 float 占 4 个字节)的内存。
这部分主要是如何降低时空复杂度:使用【可逆层】处理 nl 部分,chunking 处理 d_ff 问题。不同方法的影响结果如下:

RevNets
Gomez et al. (2017) 提出可逆残差网络,主要思想是允许仅使用模型参数从下一层的激活中恢复任何给定层的激活。当反向传播从网络的输出传播到网络的输入时,可以一层一层地反转各个层,而不必为返回过程使用中间值。
一个可逆层对输入/输出对起作用,形式如下:
可以通过减去(而不是增加)残差来反转图层:
Reversible Transformer
用在 Transformer 中就是把 attention 和 feed-forward 放在一个 block 中,放在上式中,F 就是 attention layer,G 是 feed-forward layer:
可逆 Transformer 不需要在每一层存储激活,因此省掉了 n_l 项。实验显示,在参数数量相等时,表现和标准 Transformer 一样。
Chunking
前馈层中的计算在序列中的各个位置之间是完全独立的,因此可以将计算分为c个块:
通常是并行执行所有位置的操作对这一层处理,但是一次对一个块进行操作会减少内存。除了前馈层外,对于词汇量较大(超过 d_model 个单词类型)的模型,还对输出中的对数概率进行分块,并一次计算序列各部分的损失。
Chunking, large batches and parameter reuse
有了分块和可逆层,在整个网络中用于激活的内存与层数无关。我们可以在不进行计算时在 CPU 内存之间交换层参数。 在标准的 Transformer 中,这是低效的,因为向 CPU 的内存传输速度很慢。 但是,在 Reformer 中,批次大小乘以长度要大得多,因此使用参数完成的计算量将摊销其传输成本。
Experiments
sharing-QK 和可逆层的影响

LSH Attention
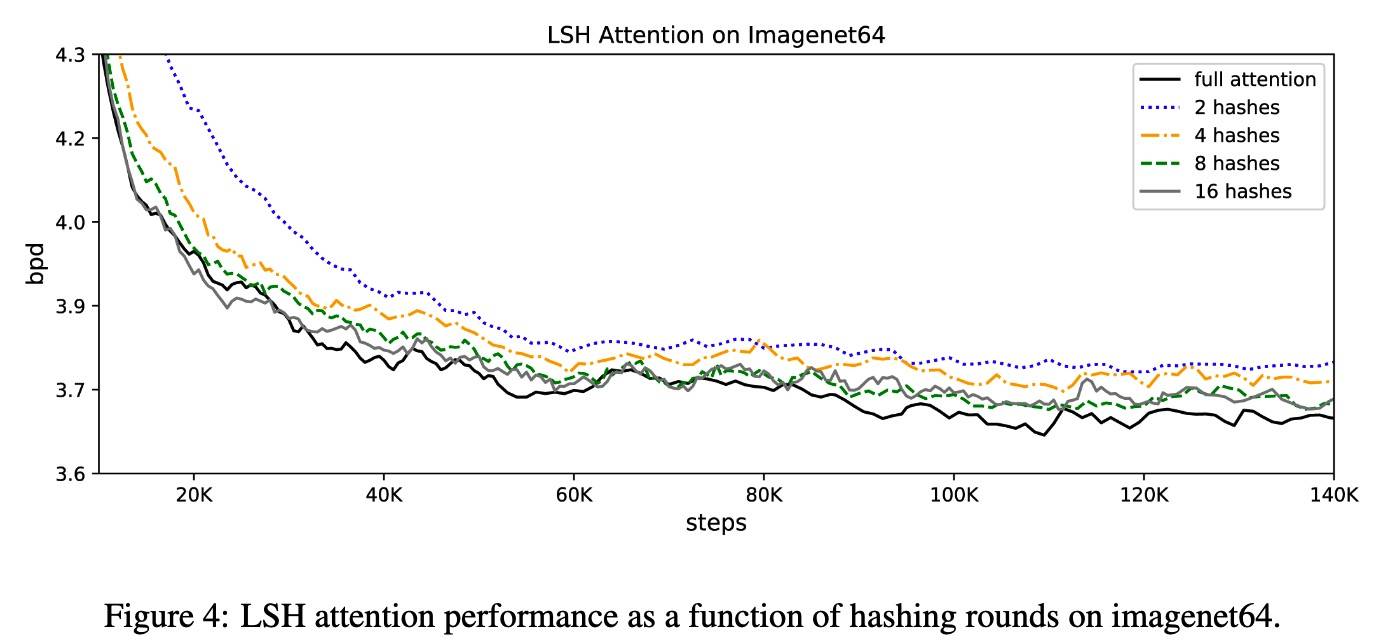
其中纵坐标的意思是 bits per dim。
Reformer
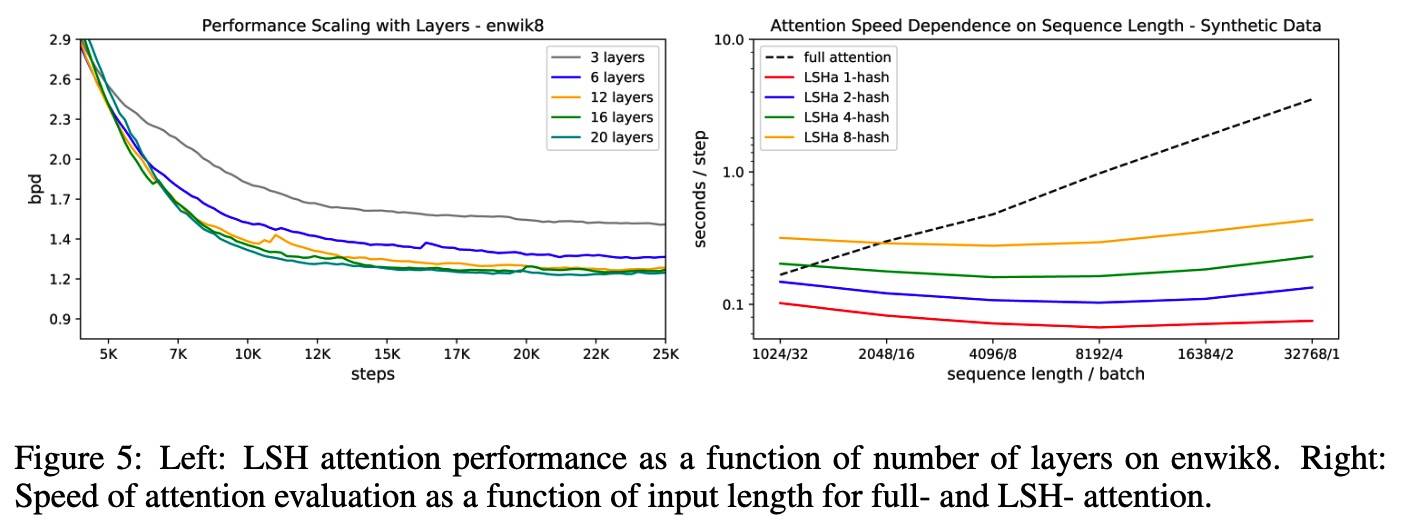
Related Work
Transformer 应用
- 音乐:Cheng-Zhi Anna Huang, Ashish Vaswani, Jakob Uszkoreit, Noam Shazeer, Curtis Hawthorne, An-drew M Dai, Matthew D Hoffman, and Douglas Eck. Music transformer: Generating music with long-term structure. arXiv preprint arXiv:1809.04281, 2018.
- 图像:
- Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, and Alexander Ku. Image transformer. CoRR, abs/1802.05751, 2018. URL http://arxiv.org/abs/1802.05751.
- Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, and JonathonShlens. Stand-alone self-attention in vision models. CoRR, abs/1906.05909, 2019. URL http://arxiv.org/abs/1906.05909.
- 语言模型:
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. CoRR, abs/1810.04805, 2018. URL http://arxiv.org/abs/1810.04805.
- Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019.
减少内存占用和降低计算要求
- 标准方法(如精度降低和梯度检查点):Nimit Sharad Sohoni, Christopher Richard Aberger, Megan Leszczynski, Jian Zhang, and Christo-pher R ́e. Low-memory neural network training: A technical report. CoRR, abs/1904.10631, 2019.URL http://arxiv.org/abs/1904.10631.
- 更有效的 Transformer:
- Sainbayar Sukhbaatar, Edouard Grave, Piotr Bojanowski, and Armand Joulin. Adaptive attention span in transformers. CoRR, abs/1905.07799, 2019a. URL http://arxiv.org/abs/1905.07799.
- Sainbayar Sukhbaatar, Edouard Grave, Guillaume Lample, Herv ́e J ́egou, and Armand Joulin. Augmenting self-attention with persistent memory. CoRR, abs/1907.01470, 2019b. URL http://arxiv.org/abs/1907.01470.
- 利用 Attention 层的稀疏性
- Sparse Transformer(利用分解的稀疏表示):Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse transformers. URL https://openai.com/blog/sparse-transformers, 2019.
- 利用 product-key attention 增加 key 空间也能够减少前馈层的内存需要:Guillaume Lample, Alexandre Sablayrolles, Marc’Aurelio Ranzato, Ludovic Denoyer, and Herv ́eJ ́egou. Large memory layers with product keys. CoRR, abs/1907.05242, 2019. URL http://arxiv.org/abs/1907.05242.
外部存储器
- Memory Networks: Jason Weston, Sumit Chopra, and Antoine Bordes. Memory networks. CoRR, abs/1410.3916, 2014.URLhttp://arxiv.org/abs/1410.3916.
- Scaling Memory Networks:
- Antoine Bordes, Nicolas Usunier, Sumit Chopra, and Jason Weston. Large-scale simple question answering with memory networks. CoRR, abs/1506.02075, 2015. URL http://arxiv.org/abs/1506.02075.
- Sarath Chandar, Sungjin Ahn, Hugo Larochelle, Pascal Vincent, Gerald Tesauro, and Yoshua Bengio. Hierarchical memory networks. arXiv preprint arXiv:1605.07427, 2016.
- 如何正确 query memory
- 作为任务提供的其他监督信息
- 启发式地确定:Felix Hill, Antoine Bordes, Sumit Chopra, and Jason Weston. The goldilocks principle: Reading children’s books with explicit memory representations. CoRR, abs/1511.02301, 2015. URL http://arxiv.org/abs/1511.02301.
- 需要在训练之前固定内存的限制被解除
- Adam Santoro, Sergey Bartunov, Matthew Botvinick, Daan Wierstra, and Timothy P. Lillicrap. One-shot learning with memory-augmented neural networks. CoRR, abs/1605.06065, 2016. URLhttp://arxiv.org/abs/1605.06065.
- 考虑了具有近似最近邻的内存查找,但仅用于外部内存中的查找:Jack W Rae, Jonathan J Hunt, Tim Harley, Ivo Danihelka, Andrew Senior, Greg Wayne, AlexGraves, and Timothy P Lillicrap. Scaling memory-augmented neural networks with sparse reads and writes. In Advances in Neural Information Processing Systems, (NIPS), 2016.
Conclusion
Reformer 将 Transformer 的建模能力与可以在长序列上高效执行的架构相结合,即使对于具有大量层的模型也可以使用较少的内存。这将有助于大型,参数丰富的 Transformer 模型变得更加广泛和易于使用。除了能处理非常长的连贯文本,还可以对时间序列建模,进行音乐、图像和视频生成等。