paper: 1409.0473.pdf
Abstract
作者猜测 encoder 中使用固定长度的向量(即将句子编码成一个固定长度的向量)可能是 performance 的瓶颈。因此提出一种能够自动 search 源句子中与预测词相关的部分。
Introduction
传统的 NMT 是 phrase-based,如今用 encoder-decoder 架构。一个潜在的问题是 encoder 要将所有的信息压缩到一个固定长度的 vector,在句子长度比较长时(尤其是比训练数据中的句子还长)performance 下降很快。
本文提出一个扩展的 encoder-decoder 模型,每当生成一个翻译的词时,它将在源句子中搜索一系列包含最相关信息的位置,然后基于上下文向量、相关的位置和所有已生成的词预测目标词。
与原来的方法相比最大的特点是,它没有尝试将整个输入的句子编码成一个固定长度的向量,而是编码成一系列向量并在 decoding 时自动选择其中的一部分。这就与句子长度没有关系了。
Background: NMT
在平行语料上学习给定源句子到目标句子的条件概率。
Encoder:
- ht 是 t 时刻的 hidden state
- c 是从 hidden states sequence 生成的向量
- f 和 q 都是 nonlinear function
比如,f = LSTM,q = hT
Decoder:
- y =
- g 是 nonlinear function,可能多层
- st 是 RNN 的 hidden state
Learning to Align and Translate
Decoder
定义每个条件概率为:
si 是一个 t 时刻的 RNN hidden state:
ci 是由一系列的 hidden state 决定,每个 hi 包含整个输入的信息,且 focus 输入句子的 i-th 词附近的部分。
e_ij 是一个 alignment model,评价 position j 附近的 inputs 和 position i 附近的 output 的 match 程度。
a 是一个前馈网络,可以和系统的其他部分一起训练。
a_ij 是目标词 yj 与源词 xj 的对齐(从源词翻译到目标词)概率,i-th 上下文向量 ci 是具有 aij 概率的 annotations 上的 expected annotation。
a_ij 或 e_ij,反映了 hj 相对于前一个 hidden state s_{i-1}在决定下一个 state si 和生成 yi 时的重要性。
Encoder
使用 BIRNN,concatenating 双向 hidden states,让 hj 包含前面和后面的单词。
比如:
模型的结构如下:

Experiment
Dataset: WMT ’14
Models
-
hidden units of encoder and decoder: 1000
-
multilayer network with a single maxout hidden layer
-
SGD + Adadelta
-
minibatch size: 80
-
beam search
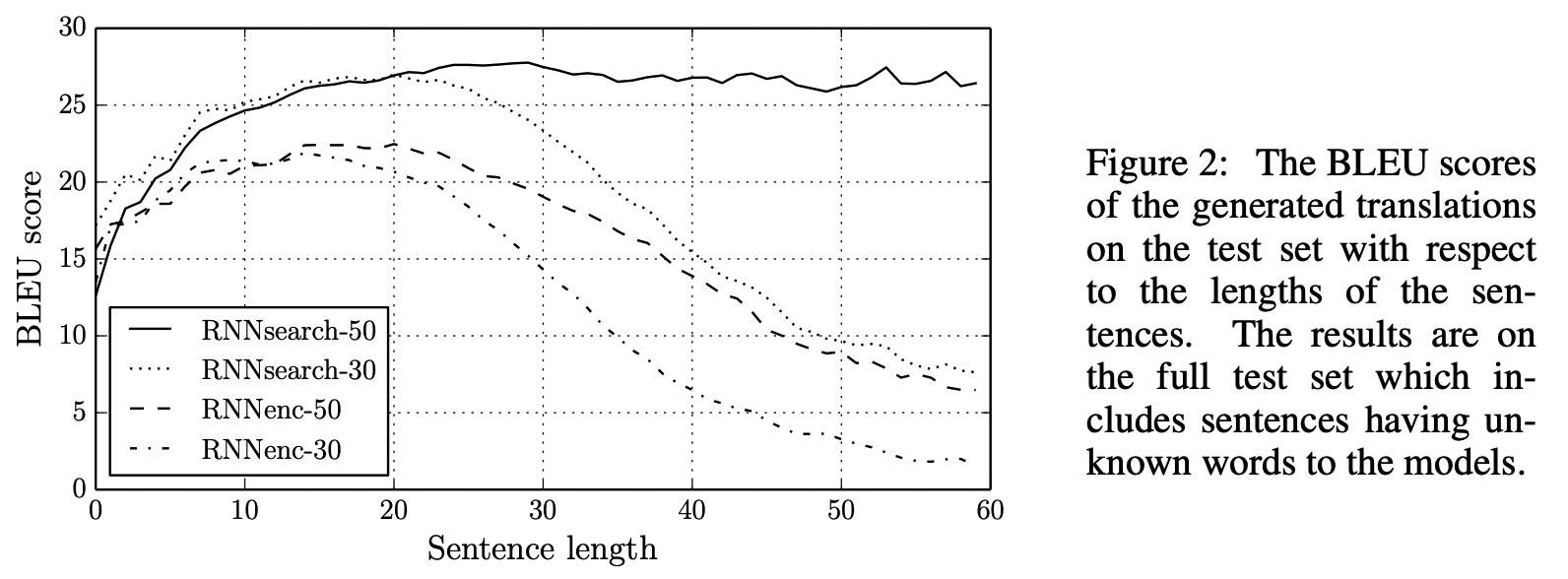
Results
Related Work
LEARNING TO ALIGN
Graves (2013), 手写合成中对齐输入和输出信号。使用对齐模型预测每个Gaussian kernel 的位置、宽度和混合系数。
NEURAL NETWORKS FOR MACHINE TRANSLATION
Bengio (2003) 使用神经网络构建给定固定数量先行词的当前词的条件概率模型,但只用在为已有统计机器翻译系统提供一个单独特征或者重排翻译候选。
- Schwenk (2012) 使用前馈网络计算源语言和目标语言短语对的分数,作为基于短语的统计机器翻译系统的一个特征。
- Kalchbrenner and Blunsom (2013) and Devlin et al. (2014) 使用神经网络作为已有翻译系统的一个组件。
- 神经网络模型作为目标语言测的语言模型被用来重新打分或重排翻译候选。
Conclusion
传统的 Encoder-Decoder 结构将输入编码成固定长度的向量,这在翻译长句子时有问题。本文使用一个模型在生成目标词时 (soft)-search 输入中的词,这不仅解决了之前提到的问题,而且能够使模型只聚焦下一个要生成的目标词相关的信息。结果不仅好于传统模型,而且对源语言句子长度更加鲁棒。剩下的挑战是更好地处理低频词和未登录词。
Code Implementation
Tensorflow 和 PyTorch 官网都给出了很清晰的实现:
- 基于注意力的神经机器翻译 | TensorFlow Core
- NLP From Scratch: Translation with a Sequence to Sequence Network and Attention — PyTorch Tutorials 1.4.0 documentation
两者在计算 score(weights)时略有不同,PyTorch 用 Target 的 hidden state concat Target 的 embedding 计算;Tensorflow 用 Source 的 hidden state 加 Target 的 hidden state 计算。