OpenAI终于开源了,无论如何,他们的一举一动总是会受人关注的。第一时间阅读了技术报告,乍一看好像没什么,而且好像有大量安全方面的内容。不过仔细阅读后,还是发现有一些不一样的细节。
- Blog:Introducing gpt-oss | OpenAI[1]
- GitHub:openai/gpt-oss: gpt-oss-120b and gpt-oss-20b are two open-weight language models by OpenAI[2]
- 技术报告:oai_gpt-oss_model_card.pdf[3]
- HuggingFace:gpt-oss - a openai Collection[4]
- Demo:gpt-oss[5]
模型架构
总体来看是MoE,不过在配置上有所不同,主要聊下面两点吧。
Bias
首先是Bias,记得貌似Attention和FFN去掉bias好像已经有一段时间了,没想到在gpt-oss里居然又看到了。关于bias的作用,一般的说法是打破对称性、提升表达能力,更加灵活、容易学习之类。之前看过苏神Bias项的神奇作用:RoPE + Bias = 更好的长度外推性 - 科学空间|Scientific Spaces[6]的介绍,又有了新的认识,其主要观点是:“Bias项确实不怎么影响训练效果(512长度),但却在长度外推性上面明显拉开了差距。”当然,更多的研究还没看过,纵观各开源模型,bias神出鬼没,有时有,有时又没。大概都是实际实验结果相差不大,可有可无,所以就导致了这种情况。尤其是模型越来越大,都是在学分布,wx也不是不能替代wx+b。不过我记得在经济学中bias还是很重要的。有机会可以深挖一下这个点。
除了这两个地方,每个注意力头在 softmax 的分母中也有一个可学习的bias,类似于 off-by-one attention 和 attention sinks 的机制。这种设计使得注意力机制可以实现“对所有 token 都不关注”的效果。关于这个有两篇参考文献:
- Attention Is Off By One – Evan Miller[7]
- Efficient Streaming Language Models with Attention Sinks[8]
这是个很有意思的现象。第一个文献主要是说原始 softmax 函数强制每个注意力头参与加权,即使该头没有实际有用信息要贡献。也就是说,softmax让Attention必须做出选择,即使有时候其实不需要选择或者说没有选择,这导致许多无意义的噪声出现。修复方案是在softmax的分母上加1,这样当所有的x都非常小时,整个输出可以趋向于0,从而允许注意力“保持沉默”,不贡献任何无意义的信息。当然,正常情况下和原始的softmax差不多。
第二个文献说的是Attention Sink现象:模型将极大比例的注意力权重集中在序列的第一个 token(通常是 <bos> 开始 token),即使它对下文语义并不重要。其原因当然也和softmax有关,即使当前 token 与前面的其他 token 并无关联,模型仍需要分配“冗余”的注意力分数。此时,最容易被“牺牲”的位置就是第一个 token,因为它对所有后续 token 都可见,容易被训练为 attention sink。关于这点,相信只要大家做过Attention分析就应该深有体会,无论哪一层,attention分数最大的几乎都是首Token(正好前几天刚分析过一个Case)。
现在说回gpt-oss里的这个bias了,它就是在每个attention head上学习一个标量偏置项b,和前面的加1是类似的,只不过是可学习的,而不是固定不变。从Attention Sink的角度看,这个bias为 head 提供了另一种“逃逸”路径,即如果不想关注这些 sink token,也可以将注意力分散成零,而不是被迫向 sink token 投注注意力。
目测这个可能应该会成为标配。
head_dim和hidden_size
关于head_dim=64和hidden_size=intermediate_size的说法可以参考这篇知乎文章[9],基本上说的比较清楚,这里再补充一点点。
一个是关于Sparse Attention(来自OpenAI,Generating Long Sequences with Sparse Transformers[10],GPT-3用了类似结构),模型中每一层的 attention pattern 在“局部窗口注意力”和“全连接注意力”之间交替进行,gpt-sso里这个窗口大小为128。代码如下:
1 | self.sliding_window = config.sliding_window if layer_idx % 2 == 0 else 0 |
sliding_window=0时就是没有局部(滑动)窗口。
注意,这里指的不是SWA(Sliding Window Attention,来自Mistral[11])。SWA的主要原理是逐层扩展Attention,突破单层注意力窗口大小W的限制,从而获得更远距离的信息。具体来说,第k层的第i个位置上的隐藏状态,只会关注上一层中从i-W到i的那些位置的隐藏状态,通过递归堆叠多层(每一层都看 W 个前面的 token),第k层的某个位置最多可以访问输入序列中距离当前位置最多 W×k 个token之前的信息。也就是说,没往上多一层,注意力跨度就多了W个token。
其实,关于Attention还有很多有意思的设计,比如DeepSeek的NSA、月之暗面的MoBA、YoloV12的Area Attention(A2),后面专门来一篇吧。
另一个是FFN先扩大维度再压缩回来。这里先不谈扩大的比例(比如GPT的4、LLaMA的8/3),简单谈一下为啥要先扩大再缩小。一般的说法是增加模型容量和非线性表示能力,因为激活函数是非线性的,而且很多是稀疏的,如果不升维,很多中间表示在非线性后变成了0,导致信息损失。升维等于为网络提供更多“通道”去编码和处理不同的语义/模式。而且FFN不像Attention那样token之间有信息交互,它必须尽可能在 token 内部增加维度来增加表达能力。升维后,线性层能创建更丰富的 feature 组合。其实,从数学拟合角度看也类似,模型变宽意味着更多的变量(只增加层数对FFN没太多意义),从而可以逼近更复杂的函数。感兴趣的读者可以阅读《AI 小课堂:Activation Function | Yam[12]》。这个的思想和机器学习算法里的核方法类似。
这个点感觉也有很多有意思的话题,以后看情况聊吧。
harmony format
讲真,这算是一个重大变化了。前几天才刚写了《重识LLM法则:上下文工程与数据进化 | Yam[13]》,我觉得这个某种意义上也可以算是一种“上下文工程”。相关文献如下:
- OpenAI Harmony Response Format[14]
- openai/harmony: Renderer for the harmony response format to be used with gpt-oss[15]
角色
首先是多了一个大家之前没见过的develop角色(其实就是原来的system),具体如下表所示。
| Role | 作用 |
|---|---|
system |
用于指定推理努力的程度,提供元信息(如知识截止时间、内置工具等) |
developer |
用于向模型提供指令相关信息(通常被视为“系统提示”)以及可用的函数工具 |
user |
模型的输入 |
assistant |
模型输出的内容,可能是函数调用,也可能是文本消息。输出还可以带一个“频道”以标识消息的意图 |
tool |
工具调用的输出,消息中使用具体的工具名作为角色 |
存在指令冲突时模型遵循的信息优先级为:System > Developer > User > Assistant > Tool。
频道
Assistant消息可以输出到三个不同的“频道(channels)”,用于区分面向用户的响应和内部推理内容。
analysis:用于展示 CoT(思维链)token,analysis 频道中的消息不遵守与 final 相同的安全标准,应避免展示给用户。commentary:用于函数调用过程中的注释信息,通常函数工具调用会在该频道触发。内置工具一般在 analysis 频道触发,但有时也会输出到 commentary。此外,该频道也可能用于模型在调用多个函数前生成“前言”内容(告知用户它即将调用的工具)。final:表示展示给用户的最终答案。
特殊Token
如果使用 tiktoken,这些Token将采用 o200k_harmony 编码。
| Special token | 作用 | Token ID |
|---|---|---|
| `< | start | >` |
| `< | end | >` |
| `< | message | >` |
| `< | channel | >` |
| `< | constrain | >` |
| `< | return | >` |
| `< | call | >` |
消息示例
均来自OpenAI Harmony Response Format[14],稍微简化了一下。
Chat Conversation
输入:
1 | <|start|>user<|message|>What is 2 + 2?<|end|> |
输出:
1 | <|channel|>analysis<|message|>User asks: "What is 2 + 2?" Simple arithmetic. Provide answer.<|end|> |
System Message
使用系统消息来定义以下内容:
- 模型身份 — 应始终保持为 “You are ChatGPT, a large language model trained by OpenAI.”。如果想更改模型身份,请使用
developer消息中的指令。 - 元数据 — 具体包括知识截止日期(Knowledge cutoff)和当前日期(Current date)。
- 推理努力程度 — 按照
high、medium、low等级别进行指定。 - 可用频道 — 为了获得最佳性能,应映射到
analysis、commentary和final三个频道。 - 内置工具 — 模型已训练支持
python和browser。 - 函数定义 — 如果定义了函数,还应注明所有函数工具调用必须发送到
commentary频道。
1 | <|start|>system<|message|>You are ChatGPT, a large language model trained by OpenAI. |
另外把developer message的示例也放在这里,它其实就是之前我们认识的system message。
1 | <|start|>developer<|message|># Instructions |
Reasoning
gpt-oss的模型是推理模型,默认是 medium 级别。执行推理任务时建议改成 high。
模型会将原始的思路(CoT)作为辅助信息输出到analysis channel,而最终的响应将作为最终结果输出。
1 | <|channel|>analysis<|message|>User asks: "What is 2 + 2?" Simple arithmetic. Provide answer.<|end|> |
一般来说,如果assistant的回答以发送到final channel的消息结束,那么在后续采样时应丢弃之前的任何链式思考(CoT)内容。也就是说,多轮时,之前消息的CoT部分不要。
1 | <|start|>user<|message|>What is 2 + 2?<|end|> |
例外的情况是工具/函数调用。模型能够将工具调用作为其思路链的一部分,因此,应该将之前的思路链作为后续采样的输入传递回去。
Function Calling
定义可用工具
所有模型可用的函数都应在 developer 消息中的专门 Tool 部分定义。
定义函数时,使用类似 TypeScript 的类型语法,并将函数包裹在专门的 functions 命名空间中。严格遵守此格式对于提高函数调用的准确性非常重要。
以下是一些通用的格式规范:
- 如果函数不接收任何参数,定义为
type {function_name} = () => any。 - 对于带参数的函数,参数命名为
_,并将类型定义内联写出。 - 在字段定义上一行添加注释,作为描述。
- 返回类型始终使用
any。 - 每个函数定义后保留一个空行。
- 将所有函数包裹在一个命名空间内,通常使用
functions作为命名空间名称,以避免与模型可能训练过的其他工具冲突。
示例如下:
1 | <|start|>system<|message|>You are ChatGPT, a large language model trained by OpenAI. |
接收工具调用
如果模型决定调用一个工具,它会在消息头部使用 to={name} 的格式定义一个 recipient(接收者),并按照规定将频道设置为 commentary。
模型还可能使用 <|constrain|> 标记来指示工具调用输入的类型。在这种情况下,由于传入的是 JSON,<|constrain|> 会被设置为 json。
1 | <|channel|>analysis<|message|>Need to use function get_weather.<|end|><|start|>assistant<|channel|>commentary to=functions.get_weather <|constrain|>json<|message|>{"location":"San Francisco"}<|call|> |
处理工具调用
处理完函数调用后,需要通过在调用消息后指定一个包含输出的新工具消息,将输出返回给模型。
工具消息示例如下:
1 | <|start|>{toolname} to=assistant<|channel|>commentary<|message|>{output}<|end|> |
结果如下:
1 | <|start|>functions.get_weather to=assistant<|channel|>commentary<|message|>{"sunny": true, "temperature": 20}<|end|> |
一旦收集了工具调用的输出,就可以使用完整内容运行推理:
1 | <|start|>system<|message|>You are ChatGPT, a large language model trained by OpenAI. |
序言
模型可能会选择生成“序言”,告知用户即将调用的工具。例如,当它计划调用多个工具时。在这种情况下,它会在 commentary 频道上生成一条辅助消息,与思路链不同,这条消息旨在向最终用户显示。
1 | <|channel|>analysis<|message|>{long chain of thought}<|end|><|start|>assistant<|channel|>commentary<|message|>**Action plan**: |
Structured output
为了控制模型的输出行为,可以在developer消息的末尾定义一个响应格式,其结构如下:
1 | # Response Formats |
示例如下:
1 | <|start|>developer<|message|># Instructions |
Built-in Tools
包括 python 和 browser,这些工具应该在 system 消息中定义而非 developer 消息,具体做法是添加一个 # Tool 部分。
Browser Tool
1 | <|start|>system<|message|>You are ChatGPT, a large language model trained by OpenAI. |
如果模型决定在浏览器中调用操作,它将使用与 Function Call 相同的格式,但有两个例外:
- 请求将发送到
analysis通道。 - 接收方分别为
browser.search、browser.open和browser.find。
Python Tool
1 | <|start|>system<|message|>You are ChatGPT, a large language model trained by OpenAI. |
如果模型决定执行Python代码,它将使用与 Function Call 相同的格式,但也有两个例外:
- 请求将发送到
analysis通道。 - 接收方永远是
python。
其他
安全
这里指的并非传统意义上的安全对齐,而是报告最后一部分的《Preparedness Framework[16]》。
“前沿能力防范框架”是 OpenAI 用于追踪和应对可能带来重大风险的前沿模型能力的方法。该框架承诺将持续追踪并减轻严重危害的风险,包括通过实施足够有效的安全措施,以降低高能力模型带来的风险。
也就是说,不光要模型安全,还要模型“放出去也安全”。感觉还挺有意思的,后面专门聊吧。
量化
主要是对MoE权重使用 MXFP4 格式进行量化,每个参数被量化为 4.25 比特。MoE 权重占据了模型总参数量的 90% 以上,量化后,120b模型能够在单块 80GB 的 GPU 上运行,而20b模型则可以在仅有 16GB 内存的系统上运行。
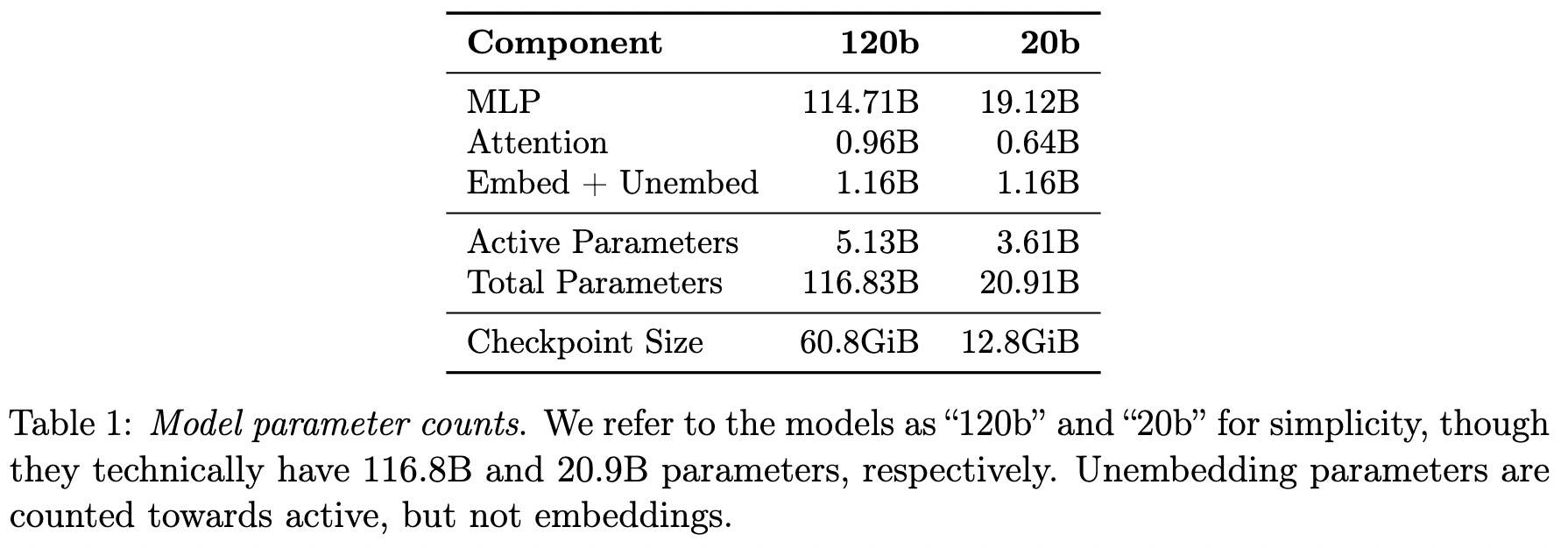
小结
本文主要介绍了gpt-oss的一些“不一样”的地方,我们可以深刻感受到OpenAI在“各个方向”上的规划。要做好一个LLM越来越不容易了,涉及到方方面面的设计。我们当然无法知晓GPT-4或GPT-5内部到底是怎么做的,但至少开源出来的模型还是有不少值得借鉴的地方。另外值得一提的是,开源的不只是模型,还有一整套配套。总之,不管怎么说,OpenAI的open总归是业界幸事吧(大家说close-ai应该也是调侃,毕竟商业公司close也是正常选择)。
References
[1] Introducing gpt-oss | OpenAI: https://openai.com/index/introducing-gpt-oss/
[2] openai/gpt-oss: gpt-oss-120b and gpt-oss-20b are two open-weight language models by OpenAI: https://github.com/openai/gpt-oss/tree/main
[3] oai_gpt-oss_model_card.pdf: https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
[4] gpt-oss - a openai Collection: https://huggingface.co/collections/openai/gpt-oss-68911959590a1634ba11c7a4
[5] gpt-oss: https://gpt-oss.com/
[6] Bias项的神奇作用:RoPE + Bias = 更好的长度外推性 - 科学空间|Scientific Spaces: https://spaces.ac.cn/archives/9577
[7] Attention Is Off By One – Evan Miller: https://www.evanmiller.org/attention-is-off-by-one.html
[8] Efficient Streaming Language Models with Attention Sinks: https://arxiv.org/abs/2309.17453
[9] 这篇知乎文章: https://zhuanlan.zhihu.com/p/1934722616544954132
[10] Generating Long Sequences with Sparse Transformers: https://arxiv.org/abs/1904.10509
[11] Mistral: https://arxiv.org/abs/2310.06825
[12] AI 小课堂:Activation Function | Yam: https://yam.gift/2020/07/05/AI/2020-07-05-BK-Activation/
[13] 重识LLM法则:上下文工程与数据进化 | Yam: https://yam.gift/2025/07/27/NLP/LLM-Context/2025-07-27-Context-Engineering-and-Data/
[14] OpenAI Harmony Response Format: https://cookbook.openai.com/articles/openai-harmony
[15] openai/harmony: Renderer for the harmony response format to be used with gpt-oss: https://github.com/openai/harmony
[16] Preparedness Framework: https://cdn.openai.com/pdf/18a02b5d-6b67-4cec-ab64-68cdfbddebcd/preparedness-framework-v2.pdf