基本思想
激活函数在深度学习中的作用就跟神经元中 “细胞体” 的功能类似:确定输出中哪些要被激活。我们都知道 SVM 通过核方法对非线性可分的数据进行分类,这其实是一种提升的方法(机器学习中很多问题都是类似的降个维度或升个维度)。为啥提升维度就能够让原本线性不可分的数据可分呢?我们以下图为例:
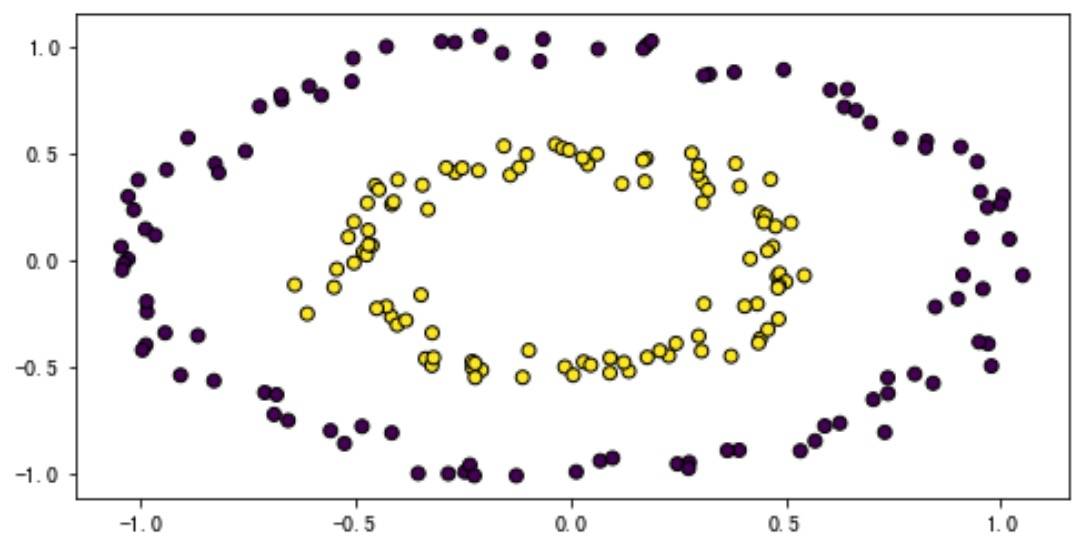
两组不同标签的数据构成一个近似的同心圆。要想将两种不同的点分开,靠二维的一条直线肯定是没办法了,此时我们可以把数据映射到三维空间,我们可以想象让同心圆之间再插入一个圆,然后让这个圆以内的整块都凸起来,也就是让它脱离原来的维度。这时候我们只要在两个平面中间任意选择一个平面就可以将数据集分开了。那这和我们的激活函数有啥关系呢?其实激活函数所提供的 “非线性” 变换正是类似的方式。也就是说,只要有非线性的激活函数,三层(输入、1 个隐层、输出层)的神经网络理论上可以逼近任意函数。
常用函数
目前深度学习领域中间层常用的激活函数主要是 ReLU,GeLU 和刚开始常用的 TanH 以及它们的变种,输出层常用的激活函数主要是 Sigmoid 和 Softmax,前者用于二分类,后者用于多分类。
ReLU(Rectified Linear Unit)很简单,就是对小于 0 的直接取 0:
它有几个变种:
- LeakyReLU:对 ReLU 的负值乘一个参数(比如 TF 中 alpha=0.2)让其不为零。
- ParametricReLU:算是 LeakLU 的变种,当 x<0 时,在 ReLU 的基础上乘了一个参数,这个参数是神经网络自动学习到的,而不是 LeakLU 那样事先指定的。
- ELU:x<0 时,与 LeakyReLU 的斜线不同,ELU 使用 log 曲线:
alpha * (exp(x) - 1),alpha 是超参数(TF 中 alpha=1.0), ELU 减少了梯度消失的影响。 - SELU:在 ELU 的基础上增加了一个缩放值,
SELU = scale * ELU,scale > 1,和 alpha 一样是超参数,它确保正输入的斜率大于 1。
GeLU(Gaussian Error Linear Unit)比较复杂:
当然,它有一个快速计算的版本:
1 | # from transformers |
TanH 在 ReLU 没出来之前比较普遍:
Sigmoid:相当于 2元素的 Softmax,其中第二个元素假设为 0。
Hard-Sigmoid 是 其分段线性逼近:
x < -2.5 ==> 0x > 2.5 ==> 1-2.5 <= x <= 2.5 ==> 0.2 * x + 0.5
Softmax:0-1 和为 1 的概率分布,一般用在分类模型的最后一层。
Softplus:
Softsign:
Swish:一个平滑的、非单调的函数,在深度网络上始终相当或优于 ReLU,无上界,有下界。
除此之外,还有很多其他的激活函数,可以参考维基百科:Activation function - Wikipedia
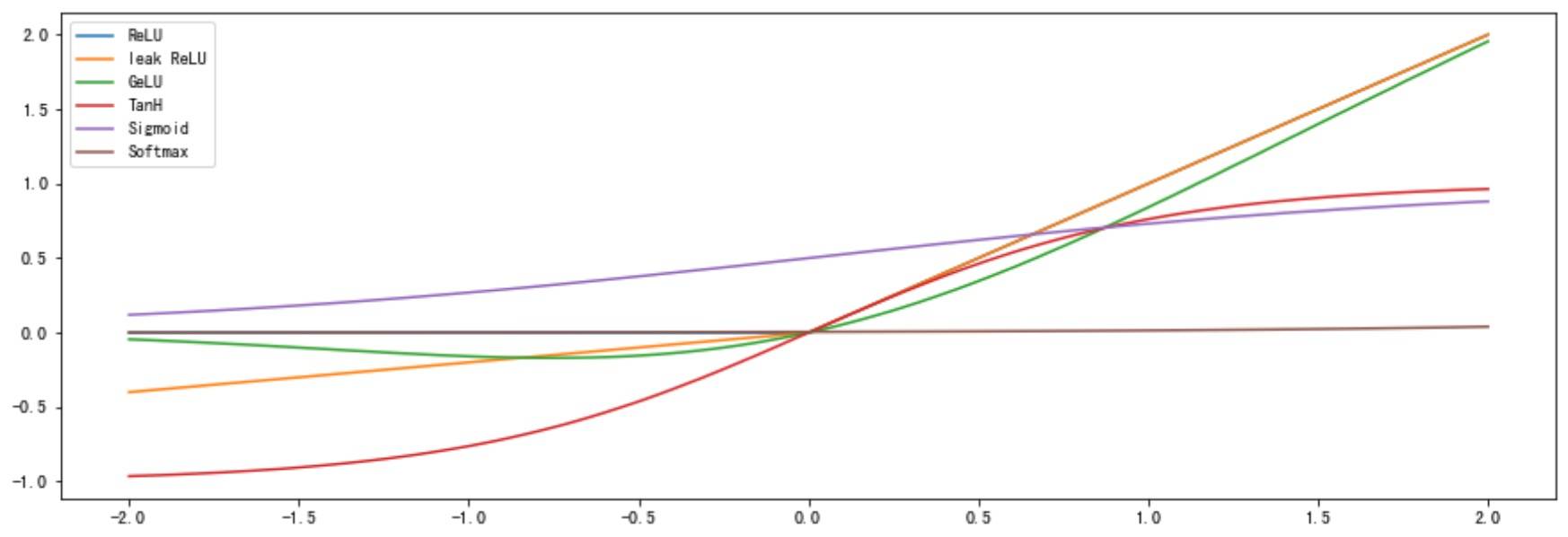
上面部分函数的的计算举例如下:
1 | x = np.array([-2.0, -1.0, 0.0, 2.0, 3.0, 5.0], dtype=np.float16) |
对应的图像如下:
具体应用
以上面的数据分类为例,构建一个单隐层的 DNN 模型:
1 | import tensorflow as tf |
最终分类结果如下(测试集上准确率 98%):
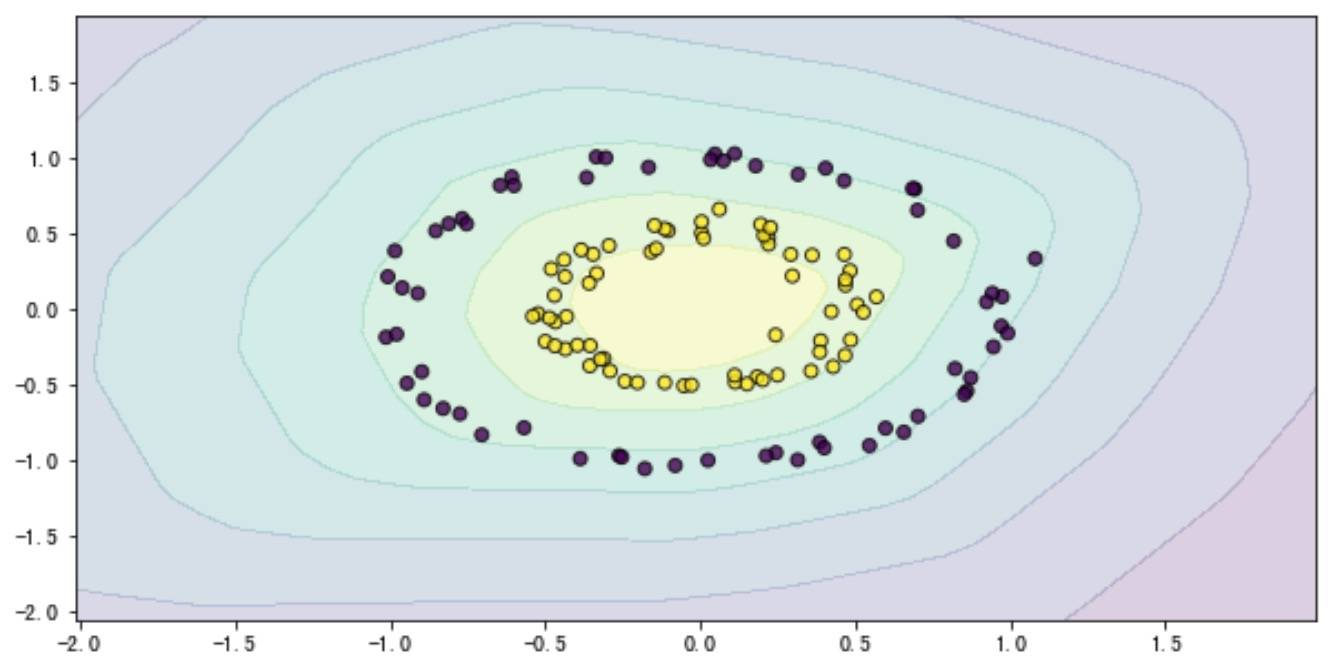
当然,不同的激活函数效果并不相同,但经过堆叠隐层,调整节点数,最终都能够正确分类。那这里就有新的问题了:节点数和层数对结果影响怎样?我们以同一个激活函数分别固定节点数和层数进行分析。
固定层数(单隐层),调整隐层节点数:
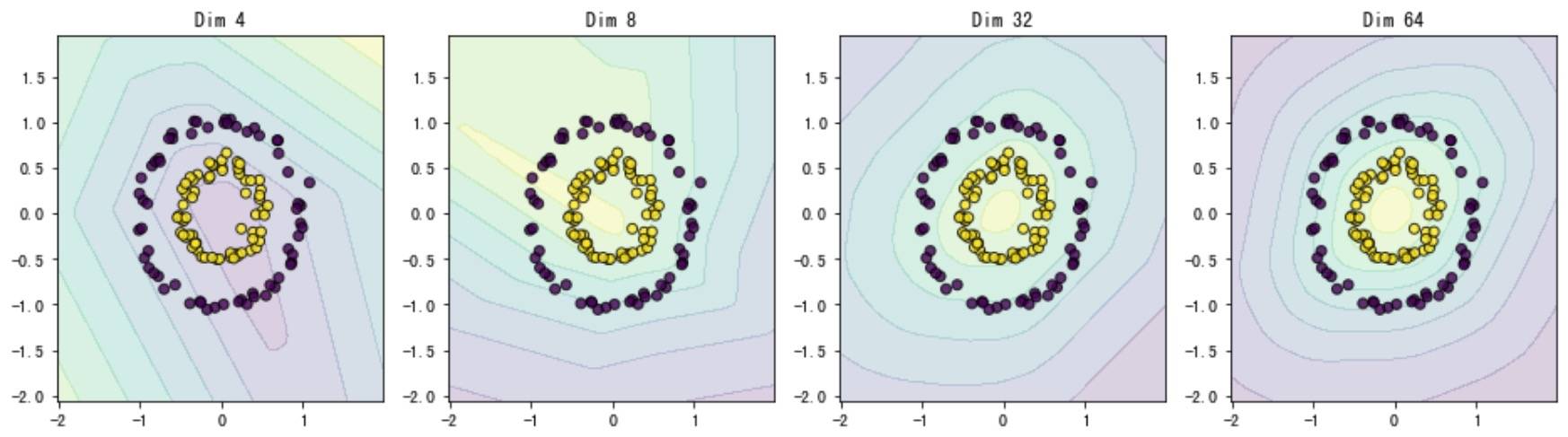
在测试集上的准确率分别为:35%、58%、88% 和 100%。可以发现,节点数影响弯曲程度,节点越多,分割界面越平滑。
固定节点数(8个),调整隐层数:
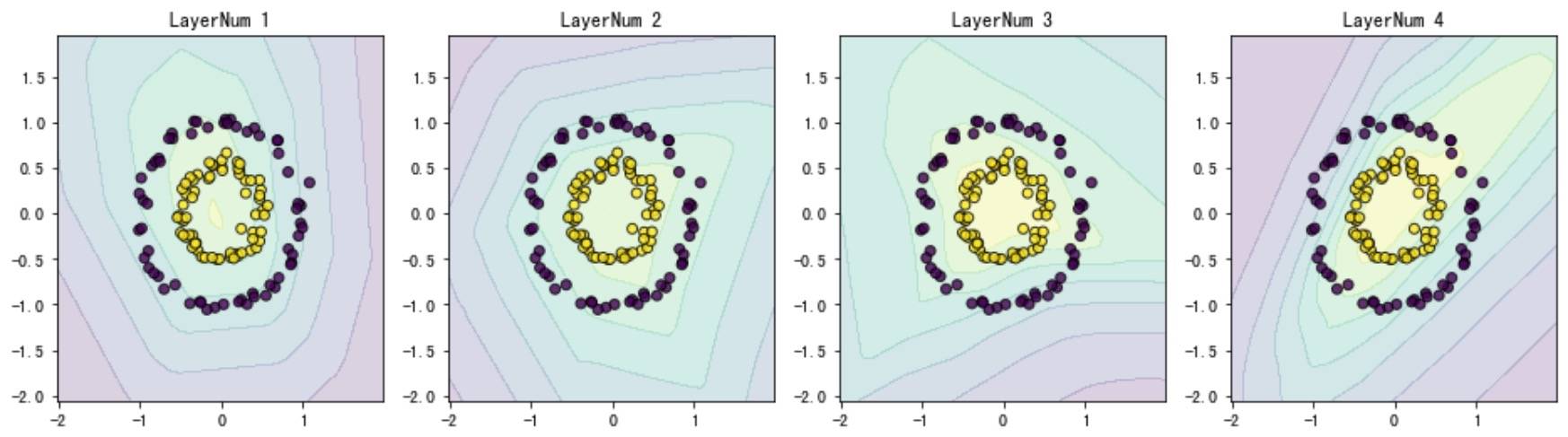
在测试集上的准确率分别为:70%、73%、85% 和 70%。而且可以发现层数增加而不改变节点并不一定会取得好的效果。事实上神经网络的架构设计一般都是随着层数的增加,节点数先增加后减少。
比如我们可以这样设计架构:
1 | # 注意:输入的 Feature 是二维的,即 dim=2 |
这次我们设置不同的 epoch 数量:
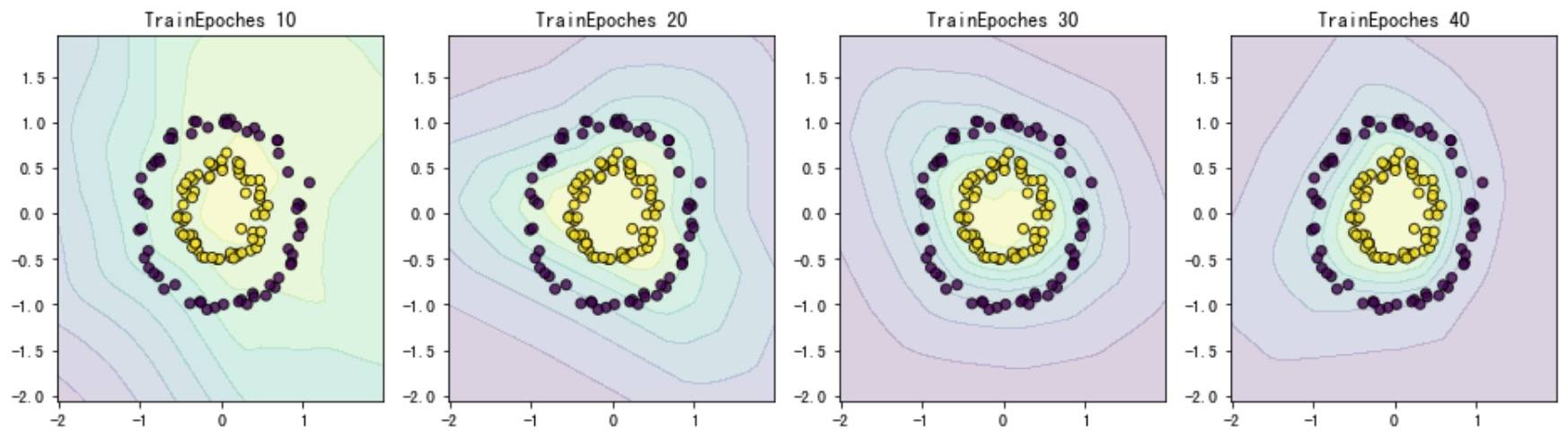
在测试集上的准确率分别为:65%、88%、100% 和 100%。当然,如果我们这里同时也调整了节点数,如果节点数最高为 8 ,无论怎么调整架构准确率也不会太高。
文中涉及所有代码可参见 JupyterNotebook:All4NLP/activations.ipynb at master · hscspring/All4NLP