论文:XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model
代码:coqui-ai/TTS: 🐸💬 - a deep learning toolkit for Text-to-Speech, battle-tested in research and production
基于Tortoise的改进,自回归。本文主要关心架构。
模型
架构如下图所示:
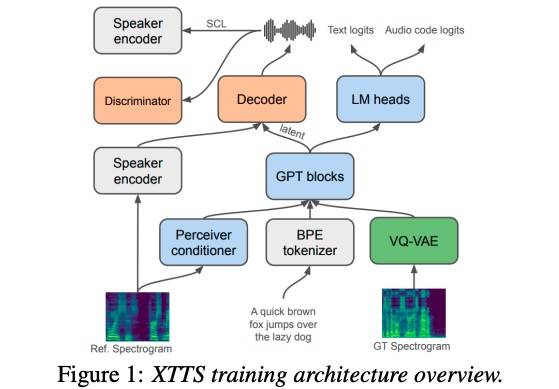
包括以下模块:
- VQ-VAE:13M,输入mel-spectrogram,单码本,codebook大小8192(训练后仅保留前1024个),21.53Hz。实验表明,过滤低频code能够改善模型表现。
- Encoder:
- 443M,输入文本(6681 Token的BPE),预测VQ-VAE音频code。
- 条件Encoder(6个16Heads的Attention+Perceiver Resampler):输入mel-spectrogram,输出32个1024维的向量(长度无关)。实验表明,没有Perceiver Resampler会降低模型Zero-Shot能力。
- Decoder:26M,魔改的HiFi-GAN,输入GPT-2 Encoder的latent向量。因为直接从VQ-VAE重建音频会导致发音问题和失真,所以用了隐向量。同时还支持输入speaker embedding,为了保证相似,还增加了Speaker Consistency Loss。
代码
关键输入gpt_cond_latent
根据参考音频计算得到的特征:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
def get_style_emb(mel):
conds = conditioning_encoder(mel)
conds = conditioning_perceiver(conds.permute(0, 2, 1)).transpose(1, 2)
return conds
class ConditioningEncoder(nn.Module):
attn = []
self.init = nn.Conv1d(spec_dim, embedding_dim, kernel_size=1)
for a in range(attn_blocks):
attn.append(AttentionBlock(embedding_dim, num_attn_heads))
self.attn = nn.Sequential(*attn)
class PerceiverResampler(nn.Module):
self.proj_context = nn.Linear(dim_context, dim)
self.latents = nn.Parameter(torch.randn(num_latents, dim))
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(
nn.ModuleList(
[
Attention(
dim=dim,
dim_head=dim_head,
heads=heads,
use_flash=use_flash_attn,
cross_attn_include_queries=True,
),
FeedForward(dim=dim, mult=ff_mult),
]
)
)
self.norm = RMSNorm(dim)
gpt_cond_latent = get_cond_latent(mel)
|
推理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
gpt_codes = gpt.generate(
cond_latents=gpt_cond_latent,
text_inputs=text_tokens,
input_tokens=None,
do_sample=do_sample,
top_p=top_p,
top_k=top_k,
temperature=temperature,
num_return_sequences=self.gpt_batch_size,
num_beams=num_beams,
length_penalty=length_penalty,
repetition_penalty=repetition_penalty,
output_attentions=False,
**hf_generate_kwargs,
)
gpt_latents = gpt(
text_tokens,
text_len,
gpt_codes,
expected_output_len,
cond_latents=gpt_cond_latent,
return_attentions=False,
return_latent=True,
)
wav = hifigan_decoder(gpt_latents, g=speaker_embedding)
|
训练
此时,gpt_codes使用dvae根据训练音频直接得到:
1
2
3
|
dvae_mel_spec = self.torch_mel_spectrogram_dvae(dvae_wav)
codes = self.dvae.get_codebook_indices(dvae_mel_spec)
|
另外gpt模型的输出不是gpt_latents,而是logits:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
text_emb = self.text_embedding(text_inputs) + self.text_pos_embedding(text_inputs)
mel_emb = self.mel_embedding(audio_codes) + self.mel_pos_embedding(audio_codes)
gpt_cond_latents = self.get_style_emb(cond_mels).transpose(1, 2)
emb = torch.cat([gpt_cond_latents, text_emb, mel_emb], dim=1)
text_logits, mel_logits = self.gpt(
inputs_embeds=emb,
return_dict=True,
output_attentions=get_attns,
attention_mask=attn_mask,
)
loss_text = F.cross_entropy(text_logits, text_targets)
loss_mel = F.cross_entropy(mel_logits, mel_targets)
|
这里targets就是输入的text token(text_inputs)或音频code token(audio_codes)的下一个。
XTTS2支持PyTorch和Accelerate后端,均支持混合精度。两者训练速度差不多,并没有明显差别。
总结
虽然Introduction里介绍了很多其他TTS系统,包括Deep Voice 3、Tacotron 2、SC-GlowTTS、VALL-E、StyleTTS 2、 P-Flow、HierSpeech++、YourTTS、Mega-TTS 2等,但要么没开源,要么实际效果(英文)不如XTTS2。
其实XTTS2的模型和代码老早就公布了,但是论文一直拖到了24年6月,写的也是非常简陋,可能是因为组织coqui已经倒闭了吧。