论文:High-Fidelity Audio Compression with Improved RVQGAN
代码:descriptinc/descript-audio-codec: State-of-the-art audio codec with 90x compression factor. Supports 44.1kHz, 24kHz, and 16kHz mono/stereo audio.
Introduction
两种方案:
- 2阶段:基于Condition生成中间表示,基于中间表示生成mel。VAE、Flow。
- 自回归:VQ-VAE,离散Token方便与LLM融合。
离散化本质是压缩,应满足:
- 高保真重建。
- 高压缩率。
- 处理各种类型、采样率、格式的音频。
已有模型(SoundStream、EnCodec)的问题:
- 失真:音调失真、音高失真、周期性失真。
- 对高频建模不完整。
- 难以对通用声音建模。
本文工作重点:
- codebook collapse:优化现有模型由于码本坍缩(一部分码本未使用)未充分利用带宽的问题。
- quantizer dropout:优化该技术(允许单个模型支持可变比特率的技术)导致的音频质量损失问题。
- 引入周期性归纳偏置、多尺度 STFT(Short-Time Fourier Transform,①)判别器、多尺度 Mel 损失等方法,对现有Codec方案进行改进。
相关工作:
- MelGAN:MSD(multi-scale waveform discriminator)、Feature Matching Loss
- HifiGAN:MPD(multi-period waveform discriminator)、Mel-reconstruction Loss
- UnivNet:MRSD(multi-resolution spectrogram discriminator)
- BigVGAN:Snake、MRSD
- SoundStream:VQ-GAN、Feature Matching Loss、MS Spectral-reconstruction Loss
- Encodec:MS-STFT(multi-scale STFT discriminator)、MS Spectral-reconstruction Loss、Loss balancer
本文:
- MB-STFT、MS-STFT、MS Mel-reconstruction Loss
- Snake;码本映射到低维空间、使用对抗性和感知损失设计的最佳实践获得固定损失权重。
Improved RVQGAN
基于VQ-GAN。
Periodic activation function
音频一般具有周期性,当前非自回归能够生成高保真音频,但经常表现不和谐的音高和周期性失真。另外,常见的激活函数难以推断周期信号,并且音频合成的分布外泛化效果较差。
本文用 Snake 替换 Leaky ReLU,可显著提高音频保真度。
Improved residual vector quantization
原始VQ-VAE(因为初始化不佳)码本利用率低。最近的方法使用 kmeans 聚类来初始化,并在某些码本几个batch未使用时手动采用随机重启。但依然存在该问题。
本文的两个优化方法:factorized codes 和L2-normalized codes。
- Code分解:在低维空间执行Embedding Lookup,Code的Embedding依然在高维空间。可以理解为仅使用 input 向量的主成分查找,这些主成分可以最大程度地解释数据中的方差。
- Code归一:将欧几里得距离转换为余弦相似度,有助于稳定性和质量。
这两个技巧提高了比特率效率和重建质量,同时更易于实现。
Quantizer dropout rate
SoundStream引入的,实现单一压缩模型在可变比特率下的训练。世纪汇降低音频重建质量,调整为以一定概率p(0.5时低比特率下与基线重建质量接近,同时缩小与不用dropou在质量上t的差距)对输入样本应用quantizer dropout。
同时发现:每增加一个量化器从学习“最重要”信息逐步过渡到学习“最不重要”信息。每个新增的码本都会逐步增加更多的细节。
Discriminator design③
MSD+MPD,高频段有失真;UnivNet的MRSD能解决,但会丢弃相位信息(可被判别器用于惩罚相位建模误差)。
本文采用了复数STFT(multiple time-scales ),另外将 STFT 分解为子带可以稍微改善高频预测,并缓解失真。这是因为判别器可以学习特定子带的判别特征,从而为生成器提供更强的梯度信号。
Loss functions
- Frequency domain reconstruction loss:mel-reconstruction loss、multi-scale spectral loss,hop length为8时,可以更好地建模非常快速的瞬态信号(音乐领域尤其常见)。
- Adversarial loss:MSD、MPD、MB-MS STFT(multi-band multi-scale STFT)、L1 Feature Matching Loss。
- Codebook learning:Codebook loss、commitment loss,在停止梯度的情况下,使用直通估计器(straight-through estimator)通过码本查找反向传播梯度②。
- Loss weighting:
- 15.0 multi-scale mel loss
- 2.0 feature matching loss
- 1.0 adversarial loss
- 1.0 codebook
- 0.25 commitment losses
实验配置
batch_size = 72
0.38s 片段
400k steps
lr = 1e-4,每一步下降,γ=0。999996
平衡数据采样:以不同的采样率训练模型时,模型通常不会重建高于特定频率的数据。这个阈值频率对应数据集的平均真实采样率。
- 将数据集拆分为已知是全呆的数据源以及无法保证最大频率的数据来源。
- 采样批次时,确保至少采样到一个全带样本。
- 确保每个批次中,来自每个领域(语音、音乐和环境声音)的样本数量相等。
评价指标
- ViSQOL:一种侵入式感知质量度量,通过与真实信号的频谱相似度来估计平均意见评分(MOS)。
- Mel距离:重建波形和真实波形的对数Mel频谱之间的距离。
- STFT距离:重建波形和真实波形的对数幅度频谱之间的距离。使用的窗口长度为[2048, 512]。与Mel距离相比,这个度量更好地捕捉了高频部分的保真度。
- 尺度不变源到失真比(SI-SDR):波形之间的距离,类似于信噪比,经过修改后使其对尺度差异不敏感。与谱度量一起考虑时,SI-SDR 表示音频的相位重建质量。
- 比特率效率:通过计算在大规模测试集上应用每个码本的熵(以比特为单位)的总和,并除以所有码本的比特总数,来计算比特率效率。
实验结果
消融结果:
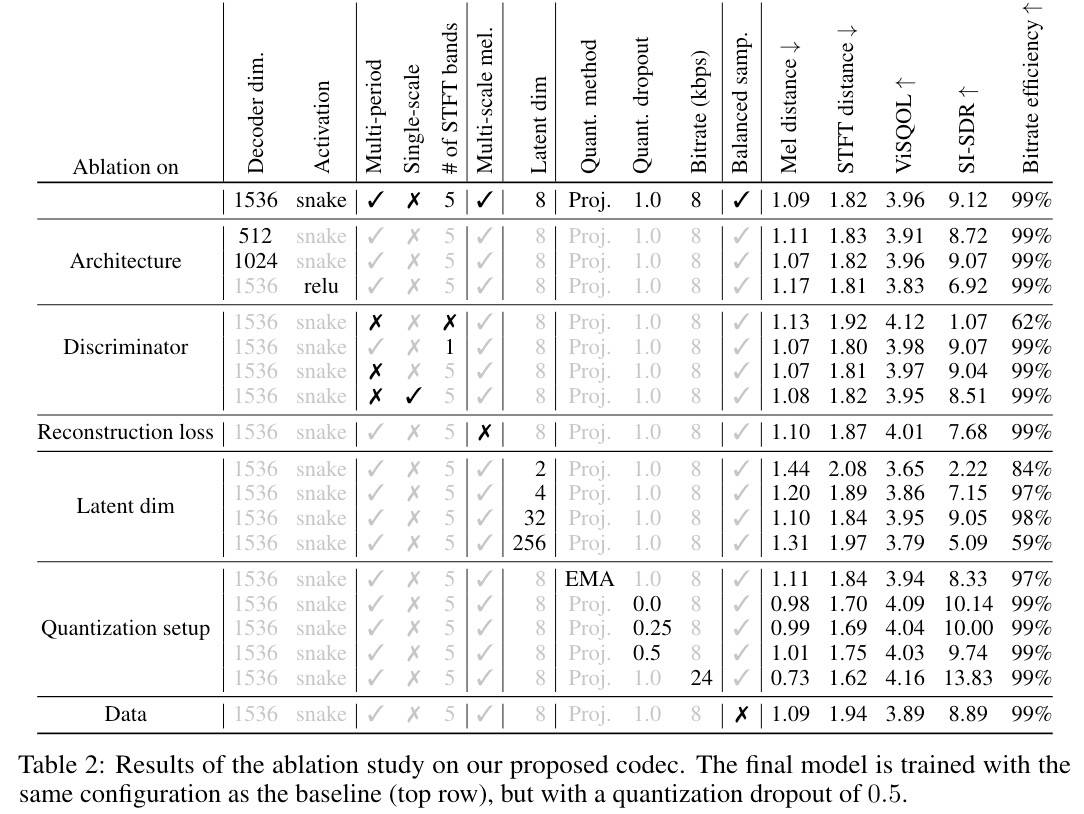
- 架构:1024与基线相当,snake很关键。
- 判别器:MB STFT改善了SI-SDR,减轻了高频的混叠;对抗损失对于输出音频的质量和比特率效率都至关重要;MPD换成Single-Scale,SI-SDR会变差。
- low-hop reconstruction loss:对于波形loss以及快速瞬变和高频的建模都至关重要。
- Latent dimension of codebook:码本latent维度对比特率效率和重建质量有重大影响,8最佳。
- Quantization setup:使用指数移动平均线作为码簿学习方法,如 EnCodec,会导致更差的指标,尤其是SI-SDR,还会导致码本利用率降低;dropout为0时,在少量(n_codebooks)码本上重建不佳,折中选择0.5;最大比特率越大效果越好。
- Balanced data sampling:在没有平衡数据采样的情况下效果变差,实际生成的最大频率为18kHz。这对应于 MPEG 等各种音频压缩算法保留的最大频率,绝大多数数据集在这个频率。
解释说明
①STFT
STFT是一种将信号从时域转换到频域的技术,用于分析信号的频率成分随时间的变化。
STFT 通过以下步骤完成时频分析:
- 窗口分割:将信号划分为多个短时片段(通常称为“窗口”),每个窗口内的信号可以认为是平稳的。
- 傅里叶变换:对每个窗口应用傅里叶变换,计算该时刻信号的频谱。
- 频谱拼接:将每个窗口对应的频谱拼接起来,形成一个二维的时频表示。
缺点:
-
时间-频率分辨率限制:窗口宽度的选择需要权衡时间分辨率和频率分辨率,宽窗口更适合频率分辨率,窄窗口更适合时间分辨率。
-
固定分辨率:STFT 对所有频率使用相同的时间分辨率,无法适应低频需要更高频率分辨率、高频需要更高时间分辨率的需求。
改进:
- CWT(Continuous Wavelet Transform,连续小波变换):使用可变的窗口宽度,更灵活地分析不同频率。
- 复数STFT:不仅包含幅度信息,还保留相位信息,用于更精确的信号重构和分析。
②通过码本查找反向梯度
在训练过程中,模型需要根据输入数据通过查找码本(codebook)来获取编码器的输出。由于VQ-VAE模型中的离散操作(码本查找)在数学上并不是连续的,为了解决这个问题,使用了“直通估计器”(straight-through estimator)。它的工作原理是,在前向传播过程中执行离散的查找操作,而在反向传播时,直接通过这个操作传递梯度,就像它是一个可导的操作一样。例如,假设我们要计算码本查找的梯度时,可以假设查找操作的梯度就等于输入的梯度,尽管它本身是离散的。这样就可以使用链式法则来传递梯度,计算出模型中其他参数的更新。
③Discriminators
- MSD(Multi-Scale Discriminator):对生成的音频在不同时间或空间尺度上进行判别。可使用不同采样率、不同长度窗口。
- MPD(Multi-Period Discriminator):专注于音频信号周期性特征的判别。可定义一系列具有不同时间长度的窗口,提取相应的子序列。
- MRD(Multi-Resolution Discriminator):通过不同分辨率的声谱图来对生成音频进行判别。可计算不同窗口长度和跳步长度的STFT,得到多种频谱分辨率。
- CSD( Complex STFT Discriminator):MRD的改进版本,不仅关注频谱的幅度信息,还引入了相位信息进行判别。
- MBD(Multi-Band Discriminator):通过分离音频的不同频带进行独立判别。可使用滤波器组或STFT分离音频子带。
总结
实验非常扎实,迄今(2024年12月底)效果最好的Codec,没有之一(包括在之后出现的)。