论文:Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
代码:jaywalnut310/vits: VITS: Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
一个并行的端到端TTS模型。
Introduction
核心:
- 变分推断+归一化Flow增强近似分布表达能力,对抗训练优化推断模型质量。
- 提出随机时长预测器,用于从输入文本合成具有多样化节奏的语音。
传统两阶段方法:
- 阶段1:生成表示(Mel或语言学)
- 阶段2:基于表示生成wav
自回归的TTS虽然能生成真实的语音,但序列特性导致无法利用多核,所以要探索非自回归方法。非自回归方法2阶段的需要分阶段微调,端到端的效果又不太好。
目标损失
Variational Inference
VITS 可以表示为一种条件变分自编码器(conditional VAE),其目标是最大化数据不可解边际对数似然 的变分下界(也称为证据下界,ELBO)①。
c是文本,p(z|c)是给定条件c时隐变量z的先验分布,p(x|z)是数据x的似然函数,q(z|x)是近似后验分布。
- 重建损失:使用Mel,L1,因为Mel更接近人听觉响应。仅在训练阶段使用。这里假设数据分布是拉普拉斯分布(Laplace distribution)②,并忽略了其中的常数项。
- KL散度:
- 为了为后验编码器提供更高分辨率的信息,KL散度的x被定义为linear-scale spectrogram(在整个频率范围内均匀采样,保留了语音信号的完整频率细节。这种表示方式包含了高频部分的详细信息,可以为模型提供更高的频率分辨率),而不是mel-spectrogram(基于人耳听觉特性进行非均匀采样,低频区域高分辨率,高频区域低分辨率。这种方式更注重感知质量,但会丢失高频部分的细节信息)。
- 先验编码器的输入条件c 由以下两部分组成:从文本中提取的音素序列c_text和音素与潜变量之间的对齐矩阵 A。对齐矩阵是一种硬单调注意力矩阵,维度为|c_text|×|z|,表示每个输入音素在时间上扩展的长度,以与目标语音对齐。由于对齐关系没有真实标签,因此需要在每次训练迭代中对其进行估计。
- 文章发现,增加先验分布的表达能力对生成真实的样本非常重要。因此,在因式分解的正态先验分布上应用了归一化流(f) ,它允许将一个简单的分布通过可逆变换转换为一个更复杂的分布。
Alignment Estimation
使用Monotonic Alignment Search (MAS)来评估输入文本text和目标Speech的对齐矩阵A。
其中候选对齐被限制为单调和非跳跃,因为人类按顺序阅读文本而不跳过任何单词。
直接应用 MAS 是困难的,因为目标是 ELBO而不是精确的对数似然。因此重新定义 MAS,以找到一个最大化 ELBO 的对齐方式,这归结为找到一个最大化潜在变量z对数似然的对齐方式:
然后就可以直接使用原始的MAS:
1 | def monotonic_alignment_search(value): |
看代码和Viterbi很像,其实MAS是Viterbi的一种变种,增加了单调性约束,限制了路径搜索空间,使得每个元素的对齐只能向前进行。
为了生成更像人类的语音节奏,本文设计了一个随机持续时间预测器,它是一个基于流的生成模型,通常通过最大似然估计训练。但最大似然估计的直接应用比较困难,因为每个输入音素的持续时间 1) 是一个离散整数,使用连续的归一化流时需要去量化,2) 是一个标量,这限制了高维变换。
本文采用变分去量化和变分数据增强,具体来说,引入两个随机变量u和v,它们的时间分辨率和维度与持续时间序列 d 相同。将 u 的支持限制在 [0, 1) 范围内,使得差值 d−u 成为一个正实数序列,并且将 ν 和 d 按通道拼接,形成一个更高维的潜在表示。通过近似后验分布 对这两个变量进行采样。
最后的训练目标是音素持续时间的对数似然的变分下限:
训练损失 Ldur 是负的变分下界。另外对输入条件应用停止梯度操作符。采样过程相对简单;音素持续时间从随机持续时间预测器的逆变换(得到随机噪声)中采样,然后将其转换为整数。
SoftVITS 引入了软持续时间预测(soft duration prediction),使用一个连续的、概率性的方式来预测音素的持续时间,这样可以避免硬性对齐的限制,并允许模型在生成过程中有更多的灵活性。
Adversarial Training
两个Loss:
- least-squares loss
- feature matching loss
值得注意的是,feature matching loss可以被视为一种重构损失,其度量是在判别器的隐藏层中完成的,被提出作为替代VAEs逐元素重构损失的方法。
Final Loss
模型架构
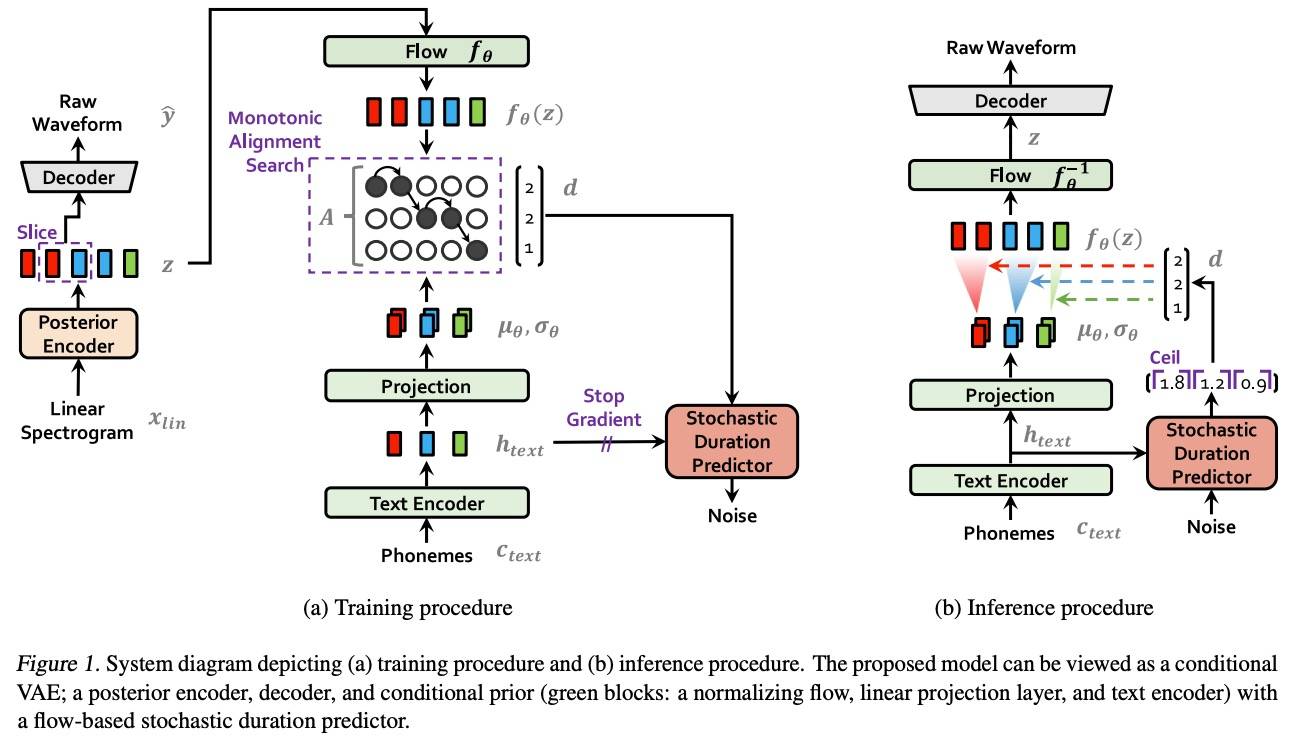
- Posterior encoder:非自回归WaveNet残差块,block由带有门控激活单元和跳跃连接的扩张卷积④层组成。
- Prior encoder:由一个文本编码器和一个归一化流(normalizing flow)组成,文本编码器处理输入的音素 ctext,而归一化流 fθ则提高了先验分布的灵活性。前者是一个使用相对位置编码的Transformer Encoder,归一化流由一堆仿射耦合层组成,其中包括一系列 WaveNet 残差块。
- Decoder:HiFi-GAN V1 generator。
- Discriminator:MPD。
- Stochastic duration predictor:通过条件输入 h_text 估计音素持续时间的分布。包括带有扩张卷积和深度可分卷积层⑤的残差块,并应用了神经样条流⑥。
窗口生成器训练方法:传统的训练方法是将整个潜在表示(即整个输入数据)输入到网络中进行处理和解码,可能会导致内存和计算资源的消耗非常大,尤其是处理长时间序列或大型数据时。而窗口生成器训练方法通过仅生成部分波形的片段来解决这个问题,避免了处理整个数据。
解释说明
解释①:ELBO
变分下界(ELBO)是用来近似计算数据的对数似然(log-likelihood)的一种策略。边际对数似然 通常难以直接计算,因为需要积分掉潜在变量:
这个积分通常是高维且无法解析解,因此直接优化这个目标非常困难。
为了解决上述问题,VAE 使用变分推断,引入一个近似分布来对潜在变量的真实分布进行近似,并通过优化ELBO来间接最大化。ELBO公式为:
包括两项:
- 数据重构损失:似然损失。
- 潜在变量分布约束:KL散度衡量近似分布q与先验分布p(z|c)的差异。
解释②:拉普拉斯分布
形状类似于正态分布,但其中心的尖峰更突出,尾部更厚。对极端值(异常值)的敏感性较高。最大化拉普拉斯分布的似然等价于最小化绝对误差(L1损失),这与正态分布对应的L2损失(平方误差)不同。
- 正态分布假设误差是均匀分布在数据周围的对称“钟形”曲线,偏离均值越远,误差的惩罚越大(平方增长)。L2损失强调对大误差的惩罚,因而对异常值较敏感。适合数据服从“高斯分布”且无明显异常值的情况。
- 拉普拉斯分布假设误差是分布在均值附近的尖峰分布,尾部较厚。其对误差的惩罚是线性增长的,较小的增长速度使得模型对异常值更鲁棒。适合数据中存在异常值或需要稀疏解的情况。
解释③:MAS
是为了解决语音合成、机器翻译等任务中的对齐问题而提出的。MAS通常用于确保序列中的元素按照时间顺序对齐(单调性),例如,确保语音和文本之间的对齐保持一致,不会出现跳跃或逆序现象。
MAS 强调“单调性”,即它要求对齐过程必须是单调的,这意味着每个输入的元素(如文本中的音素)会与输出中的某个元素(如语音帧)进行对齐,而且这种对齐不能倒退或跳跃。
MAS的目标是最大化ELBO(证据下界),并在这个过程中进行对齐。它不直接最大化对数似然(这是Viterbi的优化目标),而是寻找一个在训练时最大化ELBO的对齐方式。ELBO是变分推断中的目标,它是通过最小化变分下界来逼近真实的后验分布。
解释④:膨胀卷积
主要用于在保持计算效率的同时增加感受野,通过在卷积核中插入空洞(dilations)来实现。
解释⑤:深度可分卷积
深度可分卷积将卷积操作分解成两个独立的操作:
- 深度卷积(Depthwise Convolution):每个输入通道单独使用一个卷积核进行卷积(而不是所有通道共享同一个卷积核;标准卷积中,每个卷积核都涉及到多个输入通道之间的加权求和)。因此卷积操作是"深度"的,独立于其他通道。
- 逐点卷积(Pointwise Convolution):这个操作是一个 1×1 卷积,负责将深度卷积的输出通道映射到最终的输出通道。它的作用是将每个深度卷积生成的特征映射到最终的 Cout 个输出通道。
计算效率高、参数少,适用于嵌入式和移动设备。
解释④:神经样条流
通过单调有理二次样条进行的可逆非线性变换。简单来说,它通过特定的数学函数对数据进行变换,使模型能捕捉到更复杂的关系。相比于传统的仿射耦合层(affine coupling layers),神经样条流提供了更强的变换能力,同时使用的参数量差不多。
总结
非常轻量的端到端方案,算法设计比较复杂。特点包括:结合标准的VAE框架利用正则化流来增强先验分布的表达能力;不需要显式的对齐信息(如音素对时序的对齐),而是通过变分推理和潜变量进行隐式对齐;使用随机持续时间预测器估计每个音素的持续时间,以实现更自然的语音节奏等。