TL;DR
本文深度解析了 FlashAttention 核心机制——Online Softmax 的数学原理,并由此发散展开,揭示了高性能计算中的通用模式:Streaming Reduction。
- 只要算子具备“可结合的累积结构”与“平移/缩放不变性”(能拆分、可压缩和能修正、可补偿),就能通过动态维护“参考系”和“代数补偿”,将原本依赖全局数据的算子改造为流式、可分块的并行实现。
- 统一了 Softmax、LayerNorm/RMSNorm 、Adam/RMSProp 优化器及分布式 AllReduce 的底层逻辑——它们本质上都是在维护一套 O(1) 复杂度的状态迁移。
- 判断算子能否分块化:重写归约形式、检查结合律与坐标系补偿、构造 Merge 函数。
一直没有时间仔细看 Flash-Attention,只是大概知道原理,前几天大概瞄了一眼论文,一下被其中的 Online Softmax 吸引,然后就引出了一系列的思考。本文记录一下这个过程,有些地方不一定对,请读者不吝指正。
Online Softmax
我们知道,Flash-Attention 的核心思想就是把 Attention 的计算分块(Tiling),把 Attention 的计算全部挪到 SRAM:
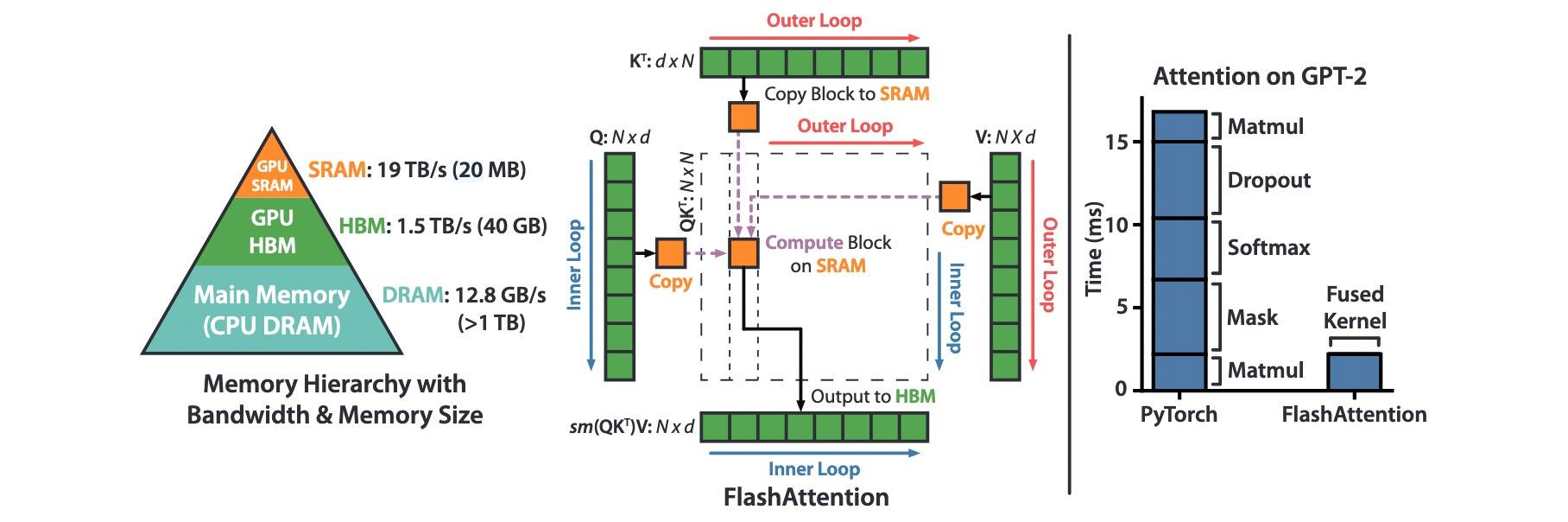
但是 Attention 是 N 平方的复杂度,N 太大的话就放不下了。Flash-Attention 把 Softmax 计算变成流式(看起来是来自《1805 Online normalizer calculation for softmax》),不需要一次性看到全部元素。
Softmax 公式如下(来自原论文):
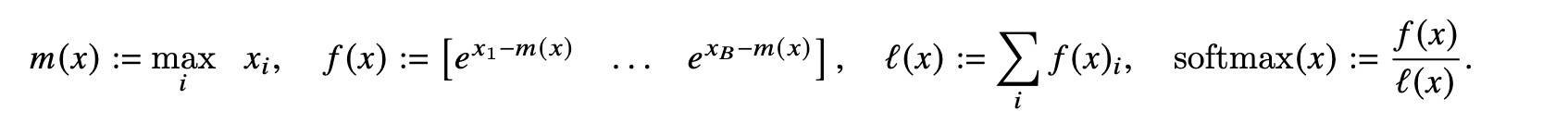
注意,计算时减 max 是为了数值计算稳定(不改变结果),避免指数溢出。
Online Softmax 过程如下(来自原论文):
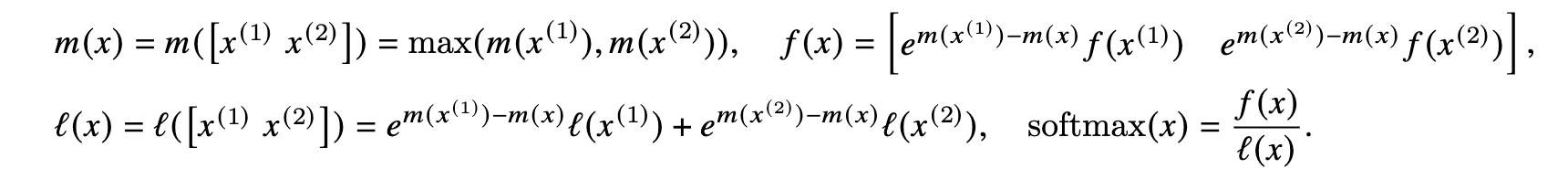
虽然从 Softmax 公式看,我们需要知道所有值,以及 max 值,但 Online Softmax 告诉我们,这个过程是可以拆分的。我当时看到这里也是觉得很新奇,有点反直觉——明明是一个全局归一化操作,怎么可能边算边改 max,还能和一次性算完全一样?
公式推导
先用数学语言看一下这个过程。简单但不失一般性,我们考虑两个 block,假设已经处理的集合为 A,新来一个 block B,我们维护了两个状态。
最大值 m:
和 sum l(小写的L):
现在来了 B,新的最大值变为:
新的归一化分母则变为:
注意看,这一步不需要知道未来的元素,只需要当前 block 就可以一直更新 Softmax 的值。如果同时要带上 V,计算过程也是类似的,维护一个额外的 o_A 即可。
一个例子
有朋友可能还是觉得不直观,没关系,我们来看一个例子。
假设一行 score:[1, -2, 4, 0],直接算 Softmax 的分母 Z:
现在我们将其分成两个 block:[1, -2] 和 [4, 0],然后按更新公式来计算。
此时,我们假装 block A 就是全部数据,用的是以 mA=1 为 reference 的坐标系。
现在 block B 来了,新的最大值为 max(1, 4)=4,用式(4)的第一项把旧的 block 的贡献先对齐到新的坐标系:
然后再计算新的 block 贡献:
两项合并后得到的 Z 和整行直接结算是一模一样的。
背后原理
作为一个正常人类,我们肯定想继续追问:这是为什么呀?背后到底有什么原理?是不是有某种统一的模式?嘿嘿,我当时也是这个想法,我当时的问题是:为什么 softmax 这种看似“全局”的运算,能被改写为严格等价的流式算法?这种等价性在数学上到底依赖什么?会不会在某些极端情况下失效?其实我最关心的是最后一个问题。
首先,Softmax 有一个非常关键的特性:平移不变性——对“整体平移”不敏感,只有“相对差值”才有意义。
因为定义就是如此,多出来的常数 c 在分子分母上都有,可以约掉。
而 Online Softmax 在干什么?它在不同阶段选择不同的平移常数 c,并对历史贡献做一次精确的代数补偿。当新的 block 最大值变化时,它把参考坐标系从原最大值移到新的最大值,所有旧值会被统一乘上一个新旧坐标系差值的补偿值,这是一个严格的数学变换。
这一切归根结底是 Z 是一个“可结合的变量”:
Online softmax 并不是在“逼近” batch softmax,而是在不断切换参考系来精确构造值。
其实减 max 是一种数值稳定化手段,并不是数学定义的一部分。所以选 max 其实是在选一个参考坐标系,坐标系可以移动,只要对历史贡献作相应的补偿即可。
平移不变性+可结合性让我们可以逐步计算,并在新参考系下给出历史贡献的等价表示,这个过程中信息是完备的(忽略浮点误差)。所以结果在数学书必然是等价的。
于是,我们得到一个通用的工程-数学模式:当一个算法看起来是“全局依赖”的,只要它的核心量满足
- 平移/缩放不变性
- 可结合的累积结构
那么就极有可能存在一个严格等价的 streaming / tiling / online 实现。
Stream Pattern
现在我们把视线转到这一类可 stream 的 pattern 上。仔细想想,我们发现这种模式其实之前就反复遇到过,来看几个例子。
LayerNorm/RMSNorm
来看 LayerNorm,RMSNorm 类似(只是分子和分母都移除了均值)。
均值和标准差依赖整层,好像必须一次性算完。
但其实只需要在计算时,为每一个 block 维护三个值即可。
- n:元素个数
- μ:当前均值
- M2:每一项元素与均值差的平方和(用来计算方差)
假设已有两个 block:
- A:nA, μA, M2A
- B:nB, μB, M2B
现在要合并成 C=A∪B。
首先,更新计数和均值,这一步比较简单:
μB-μA 就是均值漂移量。注意,新的均值一定在两个均值之间。
第二步是更新 M2,做方差补偿。
后面那项就是补偿项,衡量了两个 block 均值之间的“距离”。
直观来看,当合并两个 block 时,补偿项其实就是两个 block 分别向新中心对齐时,多出来的两部分“能量”之和:
- Block A 的额外贡献:
nA · (μC - μA)^2 - Block B 的额外贡献:
nB · (μC - μB)^2
把这两项加起来(利用 μC 的定义 nA μA + nB μB/nA + nB)化简后,就变成了式(14)最后那个简洁的补偿项。
上面的式子大家可以用前面的例子 [1, -2, 4, 0] 或者自己随便设计一个例子验证一下。这个其实就是著名的 Welford 算法,它的核心就是是解决当均值发生漂移时,如何补偿方差。实际中,Welford 不仅是 streaming 的,也是可并行的(合并满足结合律)。
Adam/RMSProp
与前面 Softmax 和 LayerNorm 的“静态合并,目标是得到全局一致的结果”不同的是,Adam/RMSProp 处理的是动态的时间序列,目标是得到历史加权的结果。不过本质上,它们都是在维护某个“动量”。
Adam/RMSProp 这类优化器维护的是一种带时间衰减的统计量,可以通过这种方式扩展为“全局视图”(保证训练稳定)。以 Adam 为例(RMSProp 类似,只是少了一阶矩),维护一阶矩和二阶炬:
β1和β2是超参数,通常取 0.9 和 0.999。为了简化讨论,下面计算不考虑 Adam 本身的偏差修正项。
它们看似递推公式,其实是一个加权求和的在线归约器!我们以一阶矩为例,
注意,通常令初始状态 m0=0,v0=0。可以看到,它本质上就是对所有历史梯度做一次指数加权和!这个结构和前面的 Softmax、LayerNorm 没有本质的区别,只是系数(权重)不同。
继续考虑两个 block,假设时间维度被切分为两段:
- A:0, …, s
- B:s+1, …, t
Δ=t−s,即 B 的长度。
只看 A,在s 时刻有(β1简写为β):
只看 B,把它当作从 0 开始的新流,有:
我们可以把全局直接计算的结果拆分为两项,即对式(16)进行拆分:
现在考虑合并 A 和 B,合并时需进行相应补偿。
先看第一项:
再看第二项,令 j=i-(s+1):
合并后:
回顾 Softmax 的:
以及 LayerNorm 的:
Adam 的只是对历史乘了一个时间衰减项。它们的结构完全一致:
大数据和分布式中的 Stream Pattern
前面提到的 Softmax、LayerNorm、Adam 看起来好像和模型有关,属于模型层面的技巧。但其实,这种 streaming / 分块合并的模式是很普遍存在的,甚至可以说是数据工程和分布式系统的默认工作方式。很多看似“必须一次性全量计算”的统计量,在现实工程里都只能以流式方式完成。
比如我们要在数亿样本或 TB 级数据下计算某个统计指标(比如协方差、均值等),显然不可能把所有数据都读进内存,真实的做法基本都是 streaming / 分块统计,最后再合并。
以协方差矩阵为例,
这和前面的方差完全同构,只是从标量变成了矩阵。计算时,同样只需维护:
- n:元素个数
- μ:当前均值
- Σ:二阶矩阵统计量
合并时做一次均值偏移补偿:
式(27)和式(14)没有本质区别,只是从一维扩展到多维。
我们继续把尺度放大,其实分布式系统,比如分布式训练中,我们整天都在做梯度合并(即 AllReduce),只要运算满足结合律和交换律,就有可能使用这种分块、合并模式。
Reduction
Pattern对比
到了这里,相信大家不难发现,上面不同的 streaming 的例子其实都是同一种计算模式,不同的是 streaming 的轴在变化。我们将它们统一罗列成表格。
| 场景 / 算法 | Streaming 维度 | 维护状态(State) | 参考系/基准的变化 | 合并/补偿方式 | 本质类型 |
|---|---|---|---|---|---|
| Online Softmax | token 维(序列长度) | (m, l) = (max, sum exp) |
最大值 m 动态更新 | exp 差值补偿 | 数值稳定 reduction |
| LayerNorm/RMSNorm | feature 维(通道数) | (n, μ, M2) |
均值 μ 漂移 | 漂移补偿 | 二阶统计 reduction |
| Adam/RMSProp | time 维(step) | (m, v, t) |
时间步 t 递增 | 时间衰减补偿 | 指数加权 reduction |
| Covariance | sample 维(数据量) | (n, μ, Σ) |
均值向量移动 | 外积补偿 | 矩阵统计 reduction |
| AllReduce | device 维(机器数) | 局部梯度 g |
无参考系(纯累加) | 直接加法(associative) | 代数 reduction |
AI 整理的,感觉不错,我做了一点点细微调整。
其实,从另一个角度看,可以分成算子级、数据级和系统级,它们可以用一个简单的公式表示:
意思是,如果存在有限维 state s,使得 state(A ∪ B) = merge(state(A), state(B)) 且 |state| 与数据规模无关,则该算子存在 streaming 实现。
Streaming维度
通过前面的介绍,我们知道:streaming 本质是“沿 axis 分块”,它不是一种优化技巧,而是一种暴露 reduction 结构的方式。对应到具体实例,其实是 streaming 被允许、被需要、被暴露在哪一个维度上。从这个角度看,我们又可以将 streaming 分成下面几种情况:
- 语义禁止跨样本 streaming。比如 LN 在 hidden_dim 上,禁止 batch/token/step,因为要求每个 token 各自归一化。
- 再比如 Adam 在时间上,禁止参数之间。
- 语义允许 streaming,但规模不迫使这么做。比如 LN,短序列的 attention,虽然支持 online,但一般一次计算就解决了,也就不需要 streaming。streaming 只是实现方式。
- 语义允许,规模/性能迫使 streaming。比如一些大规模统计指标、AllReduce、还有咱们的主角 Flash-Attention。
关注算子:如何系统化挖掘 Streaming / Reduction 结构?
其实,数据和系统层面是比较直观的,我们最应该关注的是算子级别,也就是“主动”去利用这种 reduction 结构。如果遇到一个算子存在性能瓶颈,如何系统地判断它是否可以改写为 streaming / tiled / online 版本?
Step 1:将算子重写为 Reduction 形式
尝试将算子强制写成式(28)的形式,即是否存在某种局部贡献 φ 可以通过某种可合并算子 ⊕。典型的信号包括:
- sum / mean / variance
- exp-sum(log-sum-exp)
- 加权和
- 二阶矩 / 外积
- max / min
- prefix-scan
Step 2:检查代数性质(核心判据)
关注三个问题:
- 是否可结合?无法结合律的可能无法分块。比如排序、带聚合/加权统计的 Top-K等。
- 是否存在“参考系不变性”?也就是历史结果可以通过一个 closed-form 变换映射到新坐标系。
- 状态是否是 O(1)?状态的大小必须与轴无关。
说到这里顺便说一下分布式 Top-K 问题。每个 worker 先算 local Top-K,再 all-reduce 合并后取 Top-K,这是一个非常自然的工程设计,但它在理论上和全局 Top-K 是不等价的。
出问题的就是“加和/聚合”场景(即带聚合的 Top-K),考虑如下场景:寻找出现次数最多的单词。
- 机器 1:
{"Apple": 10, "Banana": 9}-> Local Top-1 是 Apple。 - 机器 2:
{"Banana": 9, "Apple": 1}-> Local Top-1 是 Banana。
如果只看 Local Top-1,就会选出 Apple,但其实是 Banana。
Step 3:显式构造「State + Merge」
也就是想办法搞出式(25),
只要能写出 merge,就可以分块。
Step 4:考虑硬件与访存
最后考虑真正的“优化”,考虑:
- 能否放进 SRAM?
- 能否减少 HBM 读写?
Flash-Attention 本质上不是 attention 优化,而是 reduction 结构 + tiling 的一次极致工程实现。
小结
本文从 Flash-Attention 的 Online Softmax 出发,发现 Softmax、LayerNorm、Adam、协方差统计乃至分布式 AllReduce 在结构上都遵循同一种模式:它们都可以被改写为有限状态的 Reduction / 可合并统计量。只要一个算子满足:可分解为局部贡献、存在有限维 state、state 可合并或具备参考系不变性与补偿变换,它几乎一定可以被实现为 streaming / tiling / online 版本。
Flash-Attention 并不是一个特例,而是这种 reduction 结构在硬件层面的极致利用:通过重排计算顺序,把 memory-bound 的 attention 变成 compute-bound。从这个角度看,streaming 不是优化技巧,而是一种暴露算子代数结构的方式。
最后,感谢 AI 助力,虽然文字大部分都是手打的(用了 AI 的地方一般会有标记),但整个梳理过程还是少不了他的协助。