Paper:[2204.09564] Cross-view Brain Decoding
一句话概述:跨视角的 Zero-Shot 推理和翻译是可行的。
摘要:大脑如何跨多个视角捕获语义仍然是个谜团,之前的都是单视角:如(1)带目标词标签的图片(WP);(2)使用目标词的句子(S);(3)包含带目标词的词云(WC)以及其他语义相关的词。本文提出跨视图翻译任务,如:图像字幕(IC)、图像标签(IT)、关键字提取(KE)和句子形成(SF),在此基础上研究大脑解码。通过实验证明了跨视角 Zero-Shot 是实用的,pairwise acc 大约为 68%。此外,解码后的表征在翻译任务上的 acc 表现也不错:IC(78%)、IT(83%)、KE(83.7 %)、SF(74.5%)。得出关于大脑的认知结论:(1)高比例的视觉像素参与 IC 和 IT 任务,高比例的语言像素参与 SF 和 KE 任务;(2)在 S 视角上训练并在 WC 视角上测试的 Zero-Shot 精度优于在 WC 视角上训练和测试。
本文 view 均描述为「视角」,其实类似于一种形式或模式;translation 描述为「翻译任务」,其实是从一种 view 到另一种,在本文是不同的刺激到文本。
背景
大脑的不同区域在语义理解上扮演不同的角色,这引发了对大脑编解码的研究。大脑解码的核心目标之一是通过分析神经记录来理解人在思考、看到、感知什么。因此,在语言背景下,研究语言表征和大脑激活之间的映射关系,以及如何从不同刺激中组成语义等都是有意义的。目前的研究主要借助 fMRI(functional magnetic resonance imaging),不过大多都基于单个视角和特征工程。本文使用跨视角解码,提出跨视角翻译任务,并使用了基于 Transformer 的模型,数据采用①中的数据集并人工标注为成对视角关系。
①即 2018 年发表在 Nature 的《oward a universal decoder of linguistic meaning from brain activation》。说来也巧,前不久刚刚写了句子表征综述 | Yam,里面正好涉及到了这篇 Paper。当时也是源于宗成庆老师的《Towards Sentence-Level Brain Decoding with Distributed Representations》。
尽管在语言方面取得了一些进展,仍然有一些不明确的问题,比如
- Zero-Shot 解码设置:如何使用一种视角训练,用另一种推理?
- 跨视角翻译任务:给定某视角刺激的 fMRI 激活,解码其另一个相关视角的准确度如何?
- 大脑网络贡献:不同视角激活的不同大脑区域是什么?大脑的哪些部分参与了跨视角翻译任务?
fMRI 大脑激活(词、句、词云)可以通过 ridge 回归解码成一个语义向量表征。传统的方法通过手工构建特征,问题包括:(1)无法解决词义消歧问题;(2)词汇量有限;(3)无法提取抽象刺激的信号;(4)无法捕获句子的上下文和顺序。所以本文采用深度学习模型,具体而言是基于 Transformer 的预训练语言模型。
实验的关键结论包括:
- 句子视角能提高词云 Zero-Shot 推理。
- 跨所有视角的 Decoder 提供了堪比指定视角的精度。
- IC、IT、KE、SF 任务上的高精度(成对)说明使用 fMRI 进行跨视角翻译任务是可行的。
本文的主要贡献如下:
- 提出多个跨视角解码任务,如 Zero-Shot 跨视角解码和跨视角翻译。
- 基于 Transformer 构建解码模型,并分析单视角和跨视角任务的大脑网络贡献。
- 利用成对的视角关系扩充数据集,用来证明方法的有效性。
方法
数据集
来自上面提到的那篇 Nature 论文,11 个受试,每人读 180 个词(抽象和具体的),分三种不同的范式(或视角),然后获取 fMRI。180 个词包含 128 个名词、22 个动词、29 个形容词副词和 1 个功能词。
- 范式 1:给出概念词和图片,目的是观察参与者使用视觉信息检索相关含义时的大脑激活。
- 范式 2:在句子中呈现概念词,探索与上下文信息和句子语义相关的语言区域中大脑的活动。
- 范式 3:概念词以词云形式呈现,周围是五个语义相似的词。
每个概念词包含 5 张图片、6 个句子(每个都包含了概念词)以及 1 个词云。
为了实验跨视角翻译任务,需要构建成对视角关系:图片-句子,图片-词云,句子-词云和词云-句子。换句话说,对图片视角需要字幕和标签;对句子视角需要关键词;对词云视角需要 3-4 个相关句子。下图展示了四种不同跨视角翻译任务的输入和输出:
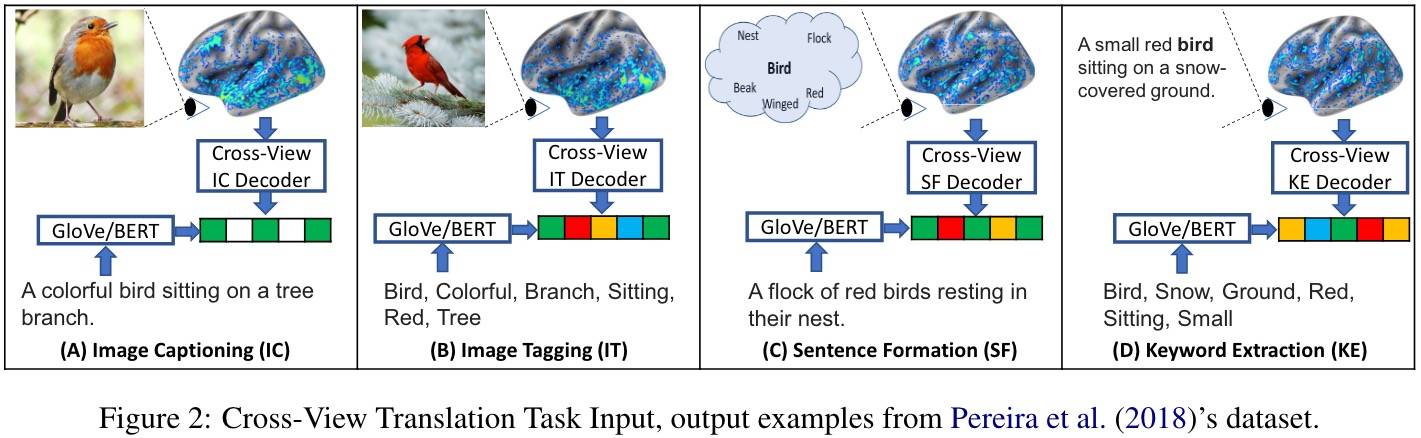
任务描述
解码模型的目标是预测语言刺激的语义向量,输入不同视角(范式):词+图、句子、词云,输出词、句子、词云表征。
跨视角 Zero-Shot 概念解码
对每个受试和每种范式,训练 18 个模型(每个 fold 一个),170 个概念的激活作为训练集,10 个作为测试集来预测向量表征。对 5000 个信息像素,测试集和训练集的一致。测试时,输入可以是任一种范式。
对每个受试,每个 fold,执行:
- 3 个同视角(范式)实验
- 6 个跨视角(范式)实验:训练和测试使用不同的视角。
下图展示了一个例子:
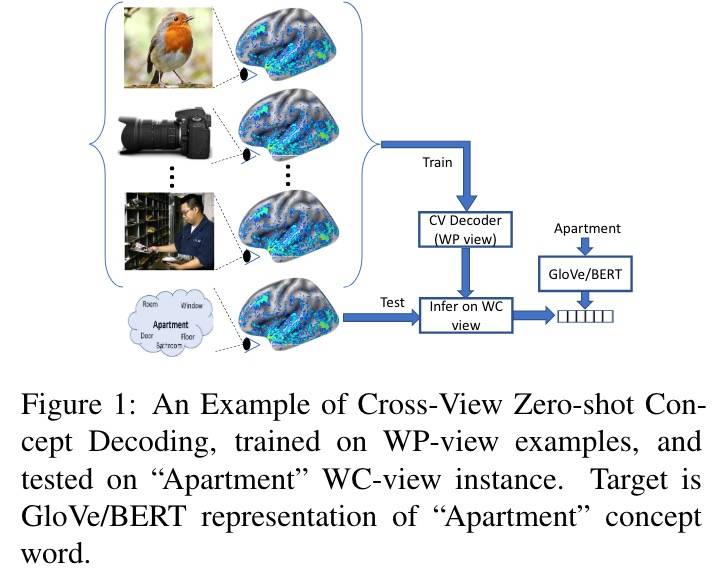
跨视角翻译任务
对每个受试,使用 18 fold 交叉验证本任务。每个任务输入输出如下表所示:
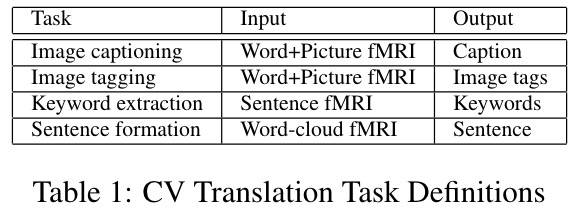
图 2 也给出了每个任务的例子。和之前一样,使用 5000 个信息像素,分别计算每个受试的每个任务。
信息像素选择
对每个像素和它的 26 个邻居训练回归模型,输出语义向量。对每个像素,计算 true 和预测表示之间的平均相关性,并选择前 5000 个作为信息像素。目标语义表征可能是「词向量」(跨视角 Zero-Shot 任务)和「词或句或词云向量」(跨视角翻译任务)。
这里的「像素」可以理解为某种特征。
模型架构
训练了一个基于岭回归的解码模型,用来预测与每种语言刺激的类型(视角)的 fMRI 信息像素相关的语义向量表示。
给定信息像素矩阵 X(N×V)和刺激向量表示 Y(N×D),N 表示训练集数量,V 表示信息像素的数量(5000),D 表示向量的维度。岭回归的目标函数为:
其中,Xi 表示每个视角 i(概念词+图片,概念词+句子,概念词+词云),Yo 表示输出向量矩阵(词、句子、词云)。
评估方法
Pairwise Acc
令 S = [S0, S1, ..., Sn],S' = [S0', S1', ..., Sn'] 分别表示 true(文本向量)和预测的刺激表征。n 表示 n 个测试实例。给定 pair(i, j):corr(Si, Si') + corr(Sj, Sj') > corr(Si, Sj') + corr(Sj, Si') 时为 1,否则为 0。corr 表示皮尔逊相关系数。
Rank Acc
将每个解码的语义向量与所有的 true 语义向量比较,并按相关性排序。正确单词的文本向量的排名 r:
大脑网络选择
关注四种大脑网络:
- DMN(Default Mode Network):与语义处理功能相关。
- Language Network:与语言处理、理解、词义和句子表达等相关。
- Task Positive Network:与注意力、显著性信息相关。
- Visual Network:与视觉对象处理、目标识别相关。
在所有的被试中,像素分布如下:Language(4670),DMN(6490),TP(11630),Visual(8170)。
结果和认知洞察
跨视角 Zero-Shot 概念解码
三个同/跨视角 pairwise 和 rand acc:
像素在四种大脑网络上的分布:

WP 训练视角
即范式 1「词+图片」视角:
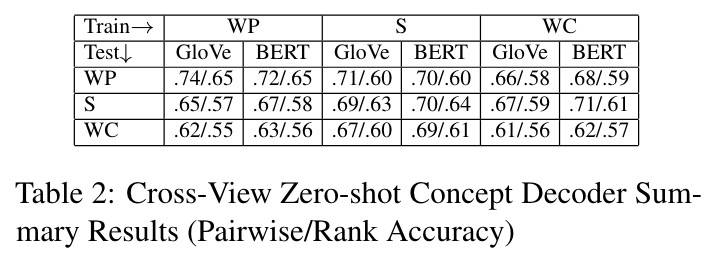
- 看表 2 第 2 列:WP 视角测试,GloVe 比 BERT 高;在 S 和 WC 视角测试,结果相反。
- 看表 3 第 1 列:BERT 在 L 和 D 上得分更高,表示 BERT 更好的理解能力。而 WP 视角训练的 V 占了大部分比例,这也符合预期。
S 训练视角
即范式 2「句子包含关键词」视角:
- 看表 2 第 2 列:WP 测试,GloVe 比 BERT 好(但不显著)。
- 看表 2 表 3 的第 2-3 列:S 训练 + WC 测试要比 WC 训练 + WC 测试好,这与观察到的 S 的 L 和 D 的像素分配比 WC 高匹配。
- 看表 2 第 2-3 列:S 测试和 WC 测试上,BERT 要比 GloVe 略好,但是 S 不显著,WC 是显著的。
- 看表 3 第 2 列:L 和 D 的分布较高,V 的较低,且 BERT 比 GloVe 捕获了更多的像素。
- 看表 3:S 与 WP 相比在 L 和 T 上的分布要明显高,这符合我们的理解,即语言和注意力技能对于理解句子刺激很重要。
WC 训练视角
即范式 3「概念词以词云形式呈现」视角:
- 看表 2 第 3 列:BERT 比 GloVe 好,不过在 WC 上测试不显著。
- 第一条可以通过表 3 第 3 列来解释,BERT 在 D、L 和 V 上都要高于 GloVe。
重叠像素
对三个视角,不同大脑网络的重叠部分进行分析:
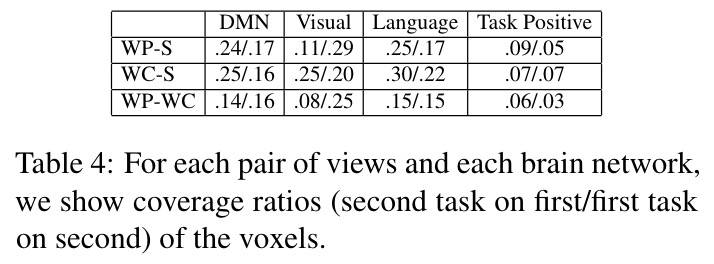
- 第 2 行:WC-S 对,L 的占比超过其他。
- 第 2 列(1、3 行):29% 和 25% V 像素和 WP 的 V 重叠,说明大部分 WP 视角的像素来自 V 网络。
跨视角翻译
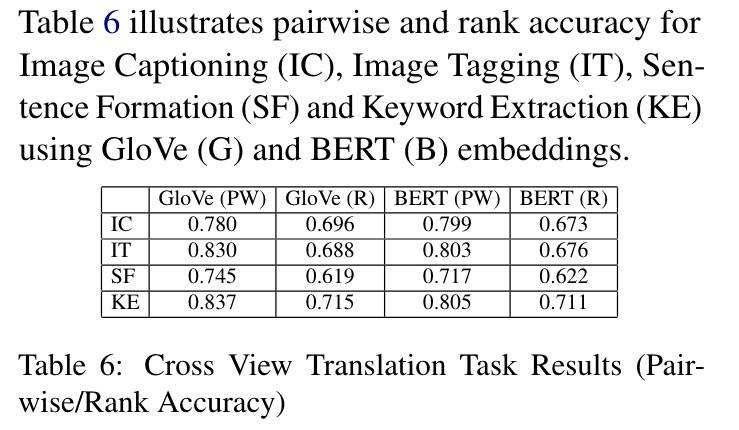
不同跨视角任务的 pairwise 和 rank acc:
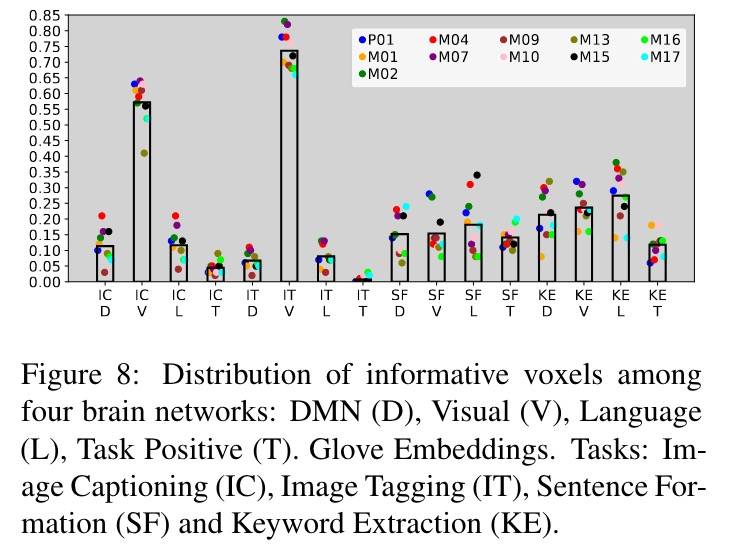
任务中像素在不同大脑网络间的分布:
结果如下:
- 看表 6:pairwise acc 大约 75%,rank acc 大约 70%,说明任务是可行的。
- 看图 8:IC 和 IT 有高比例的 V 像素,SF 和 KE 则有高比例的 L 像素,这与预期一致。
- 看图 3:IC 相比 IT 有比例较高的 L 像素,可能是因为生成字幕比生成一组关键词需要更高级的语言技巧。
- 看表 6:GloVe 几乎在所有情况下都优于 BERT,这可能是因为指标捕获的是相对值,而不是绝对质量。
- IC 和 IT 任务明显激活了与视觉处理和目标识别的大脑区域;KE 和 SF 则是弥散的,包括已知句子语义相关的大脑区域。图片见论文。
- 刺激图没有显示出左半球偏差(与语义相关时很常见),这表明跨视角表征可能依赖一些非抽象的特定领域编码,而不是更高级别的语义概念编码。图片见论文。
重叠像素
下表给出了不同任务大脑网络重叠的比例:、
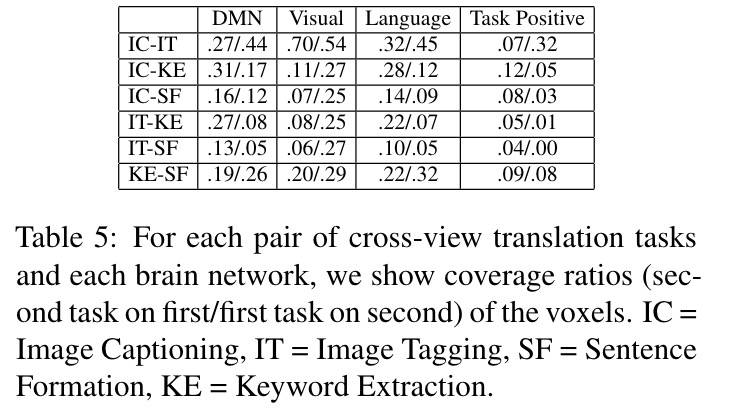
可以看出:
- IC 和 IT 在所有大脑网络类型上彼此都有大量重叠,因为这两个任务非常相关。
- KE 和 SF 在所有大脑网络类型上有较好的重叠,因为它们都是文本性质任务。
小结
本文主要研究了在跨视角任务(Zero-Shot 概念解码和跨视角翻译)上的大脑解码,表明跨视角翻译是可行的。对大脑网络分布的分析也揭示了大脑各个部分对不同任务重要性的洞察见解。总的来说,这是一篇比较有意思的论文,尝试通过大脑在做不同任务时的成像来研究语言表征。
通俗点来讲,第一个任务,训练是拿某种视角的 fMRI 特征,通过回归模型映射到语言向量表征(目标),测试时则拿另一种视角的 fMRI 特征,通过学到的回归模型参数输出对应的刺激表征,然后使用语言模型表征(真实值)进行评测。而第二个任务与第一个相比,输入不变(fMRI),但目标变了,不再是概念词,而是字幕、句子、标签等。不过毕竟一篇 Paper 呈现的东西有限,也没有提供代码,有些细节不得而知。再加上个人水平也有限,上面的理解也不一定准确。