Paper:[2112.10070] Unified Named Entity Recognition as Word-Word Relation Classification
一句话概述:基于词-词关系分类、可同时解决平铺、重叠和不连续 NER 的统一框架。
摘要:NER 任务主要有三种类型:Flat(平铺)、overlapped(重叠或嵌套)、discontinuous(不连续),越来越多的研究致力于将它们统一起来。当前的 STOA 主要包括基于 Span 和 Seq2Seq 模型,不过它们很少关注边界,可能会导致后续的偏移。本文提出的统一方法(W2NER)是将其视为词词关系分类,为此引入两种词词关系:NNW(Next-Neighboring-Word)和 THW-*(Tail-Head-Word-*)。具体而言,构造一个 2D 的词词关系网格,然后使用多粒度 2D 卷积,以更好地细化网格表示。最后,使用一个共同预测器来推理词-词关系。效果自然是最新的 STOA。
关于本文代码部分,可参考:W2NER 代码。
NER 任务是除序列分类外的另一种自然语言处理基础任务,有着非常重要的地位。我们首先介绍在此之前的三种常用方法,然后再过渡到本文提到的方法。
背景
针对多类型 NER,之前的工作主要可以概括为四种类型:
- 序列标注
- 基于图的方法
- Seq2Seq 方法
- 基于 Span 的方法
序列标注
序列标注方法是比较常用的方法,给每一个 Token 一个标签(BIO)。输入序列会使用已有的表征框架(如 CNN、LSTM、Transformer 等)表征成序列特征,之后 CRF 层经常会会引入以解决标签间关系特征。对于多类型 NER,可以将「多分类」改为「多标签分类」或将多标签拼成一个标签。前者不容易学习,而且预测出来的 BI 可能都不是一个类型的;而后者则容易导致标签增加,且很稀疏。虽有不少研究,比如《A Neural Layered Model for Nested Named Entity Recognition》提到的动态堆叠平铺 NER 层来识别嵌套实体;《Recognizing Continuous and Discontinuous Adverse Drug Reaction Mentions from Social Media Using LSTM-CRF》的 BIOHD 标注范式(H 表示多个实体共享的部分,D 表示不连续实体中不被其他实体共享的部分),注意 H 和 D 都是实体的 Label,标注时会和 BI 结合使用,如 DB,DI,HB,HI。但总的来说较难设计一个不错的标注 Scheme。

注:图片来自原始论文。
Span
基于 Span 的方法将 NER 问题转为 Span 级别的分类问题,具体方法包括:
- 枚举所有可能的 Span,然后判断他们是否是有效的 Mention。
- 使用 Biaffine Attention 来判断一个 Span 是 Mention 的概率。
- 将 NER 问题转为 MRC 任务,提取实体作为答案 Span。
- 两阶段方法:使用一个过滤器和回归器生成 Span 的建议,然后进行分类。
- 将不连续的 NER 转为从基于 Span 的实体片段图中找到完整的子图。
本方法由于全枚举的性质,受到最大跨度长度和相当大的模型复杂度的影响,尤其是对于长跨度实体。
超图
基于超图的方法首次在《Joint Mention Extraction and Classification with Mention Hypergraphs》中提出,用于解决重叠 NER 问题(指数表示可能的 Mention),后续也被用于不连续实体。但本方法在推理时容易被虚假结构和结构歧义问题影响。
Seq2Seq
Seq2Seq 方法是生成方法,在《Multilingual Language Processing From Bytes》中被首次提出,输入句子,输出所有实体的开始位置、Span 长度和标签。其他后续应用包括:
- 使用增强的 BILOU 范式解决重叠 NER 问题。
- 基于 BART 通过 Seq2Seq+指针网络生成所有可能的实体开始-结束位置和类型序列。
本方法存在解码效率和架构固有的暴露偏差问题。
exposure bias 问题是指训练时使用上一时间步的真实值作为输入;而预测时,由于没有标签值,只能使用上一时间步的预测作为输入。由于模型都是把上一时间步正确的值作为输入,所以模型不具备对上一时间步的纠错能力。如果某一时间步出现误差,则这个误差会一直向后传播。
From:https://blog.csdn.net/MrR1ght/article/details/106549797
总的来说,简单的 NER 任务目前一般使用序列标注就可以解决,多类型 NER 效果较好的还是基于 Span 的方法,具体可参见 JayJay 这篇:刷爆 3 路榜单,信息抽取冠军方案分享:嵌套 NER + 关系抽取 + 实体标准化 - 知乎。
初衷
大多数现有的 NER 工作主要考虑更准确的实体边界识别,不过在仔细重新思考了三种不同类型 NER 的共同特征后,作者发现统一 NER 的瓶颈更多在于实体词之间相邻关系的建模。这种邻接相关性本质上描述了部分文本片段之间的语义连通性,尤其对于重叠和不连续的部分起着关键作用。如下图 a 所示:

因此,本文提出了一种词-词关系分类的架构——W2NER,有效地对实体边界和实体词之间相邻关系进行建模。具体来说,预测两种类型的关系,如上图 b 所示。
NNW:解决实体词识别,指示两个 Token 在一个实体中是否相邻。THW-*:解决实体边界和类型检测,指示两个 Token 是否是尾部和头部*标签实体的边界。
NER → 词词关系分类
如下图所示:
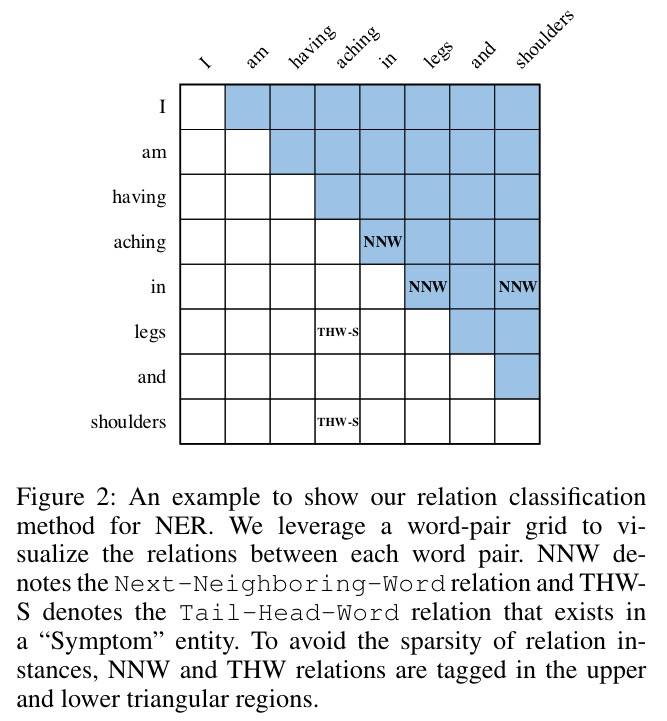
关系包括以下几种类型:
NONE:表示词对没有任何关系;NNW:词对属于一个实体 Mention,网格中行的 Token 在列中有一个连续的 Token;THW-*:THW 关系表示网格中行的 Token 是一个实体 Mention 的尾部,网格中列的 Token 是一个实体 Mention 的头部,*表示实体类型。
上图的例子中包含两个实体:aching in legs 和 aching in shoulders,可以通过 NNW 关系(aching→in)、(in→legs)和(in→shoulders)和 THW 关系(legs→aching,Symptom)和(shoulders→aching,Symptom)解码得出。
而且 NNW 和 THW 关系还暗示 NER 的其他影响,比如 NNW 关系将同一不连续的实体片段关联起来(如 aching in 和 shoulders),也有利于识别实体词(相邻的)和非实体词(不相邻的)。THW 关系有助于识别实体的边界。
模型架构
整体的网络架构如下图所示:
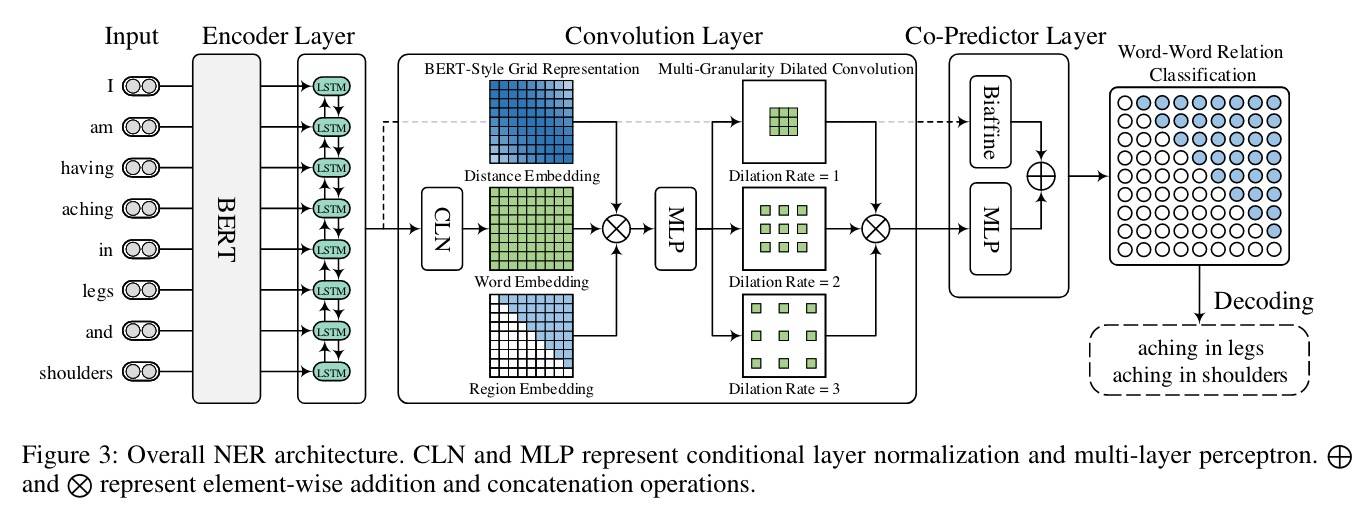
总的来看,首先 BERT 和 LSTM 提供上下文特征,然后一个词-词关系的 2D 网格被构建,接下来是一个多粒度 2D 卷积用来精调词对表示,有效捕获相邻或不相邻词对的交互。最后一个联合预测器对词-词关系进行推理并产生所有可能的实体 Mention,其中 Biaffine 和 MLP 被联合使用以获得互补好处。
Encoder Layer
将 Token 或词转为子词后喂入模型,子词表征通过 MaxPooling 得到词表征,同时额外的 Bi-LSTM 也被用来生成最终的词表征。也就是说输入的字符粒度 Token 需要转为词再送入后续模型(主要针对英文的子词)。
Convolution Layer
然后是卷积层,因为它能很好地处理二维关系,具体又包括三个模块:
- 一个包含归一化的 condition layer,用来生成词对表示;
- 一个 BERT 风格的网格表示来丰富词对表示;
- 一个多粒度扩张卷积来捕获远近词之间的交互;
卷积层归一就是上图的 CLN 部分:
Vij 表示词对(xi,xj)的表示,可以看作 xi 和 xj 词表征(hi 和 hj)的组合,也意味着 xi 是 xj 的条件。hi 是获取层归一化参数 γ 和 λ 的条件,μ 和 σ 是 hj 的均值和标准差。
来自 Paper《Modulating Language Models with Emotions》
代码(均来自官方代码,做了一定简化,后续不再重复说明)如下:
1 | class LayerNorm(nn.Module): |
网格表示主要引入三个张量分别表示:词信息(CLN)、每对词的相对位置信息和用于区分网格上下三角的区域信息。三个张量拼接后丢给后面的层进行降维和混合信息,以此得到网格「位置-区域敏感的表示」。然后是接一个多粒度卷积(粒度=1,2,3),用以捕获不同距离词的交互。最后将三组结果拼起来就是最终的词对网格表示。
Co-Predictor Layer
这一步除了 MLP 外,还有一个 Biaffine Predictor,所以会分别得到两个结果,然后合并后作为最后输出。
MLP 与 Biaffine Predictor 协作可增强关系分类,来自论文:《MRN: A Locally and Globally Mention-Based Reasoning Network for Document-Level Relation Extraction》
s 和 o 分别表示主语和宾语。s 和 o 的输入就是前面的词表征(而不是卷积),卷积这部分特征被丢给了 Biaffine。代码如下:
1 | class CoPredictor(nn.Module): |
Decoding
模型预测的是词和它们的关系,可以看作有向图,解码目标是使用 NNW 关系在图中查找从一个单词到另一个单词的某些路径。每个路径对应于一个实体 Mention。除了 NER 的类型和边界标识外,THW 关系还可以用作消除歧义的辅助信息。

如上图所示几个例子:
- a:两个路径对应平铺的实体,THW 关系表示边界和类型。
- b:如果没有 THW 关系,则只能找到一条路径(ABC),借助 THW 可以找到嵌套的 BC。
- c:包含两条路径:ABC 和 ABD,NNW 关系有助于连接不连续的跨度 AB 和 D。
- d:如果只使用 THW 关系,将会识别到 ABCD 和 BCDE,如果只使用 NNW 则会找到四条路径,结合起来才能识别到正确的实体:ACD 和 BCE。
目标函数
如下式所示:
N 表示句子中词数,y^ 是二元向量表示词对的真实关系 Label,y 是预测的概率,r 表示预先定义的关系集合中的第 r 个关系。可以看出,整个就是个词对分类问题。
实验报告
共 14 个数据集,包括平铺的、重叠的和不连续的。Baseline 包括常用的几种方法(前文介绍过)。
平铺NER
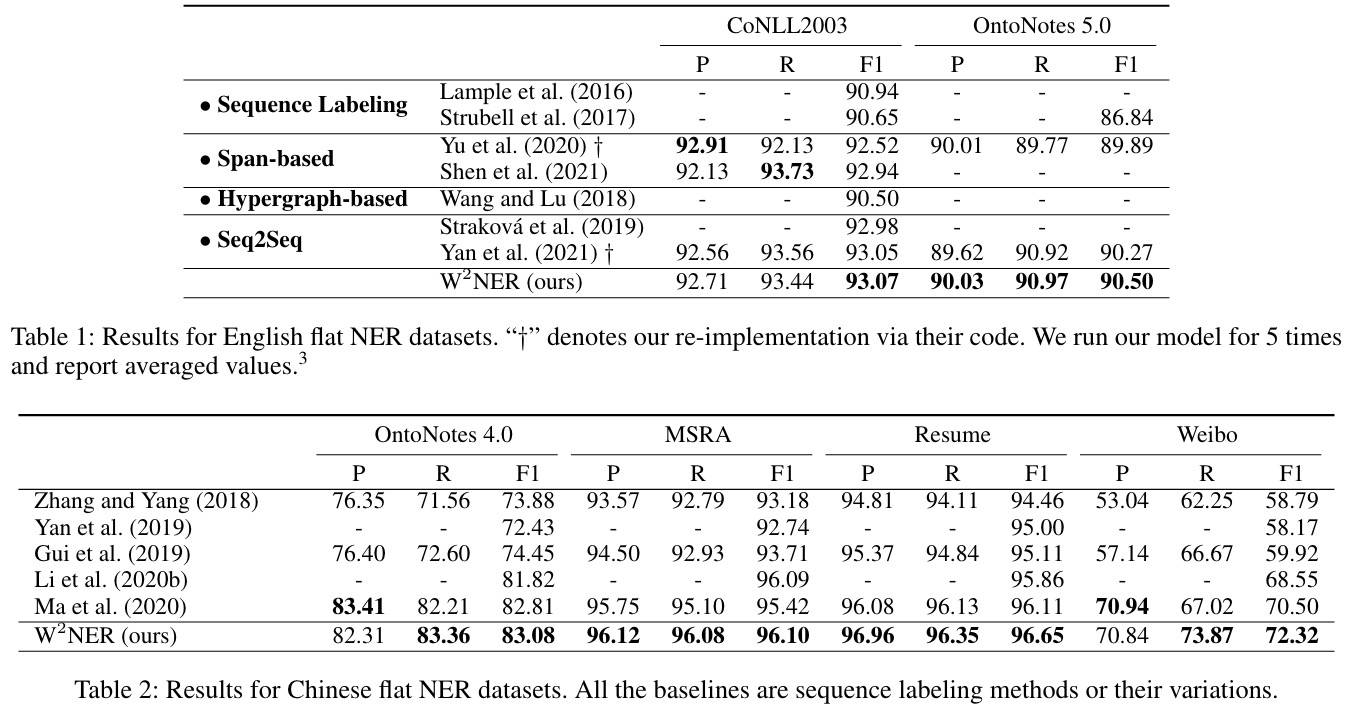
在中英文数据集均取得不错的效果。
重叠NER
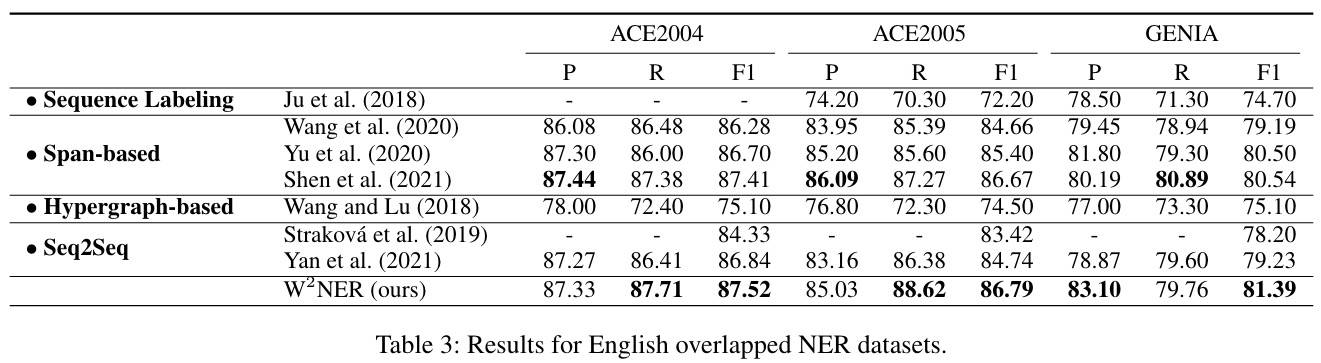
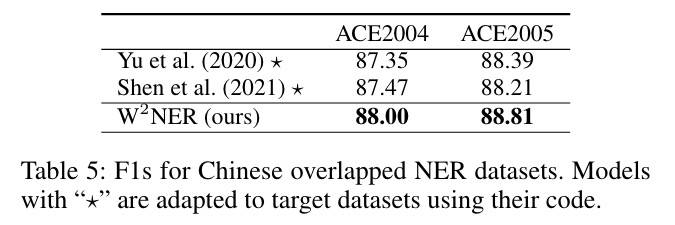
通过上面的结果可以发现,除了本文的方法,其实基于 Span 的方法也是效果不错的。
不连续NER
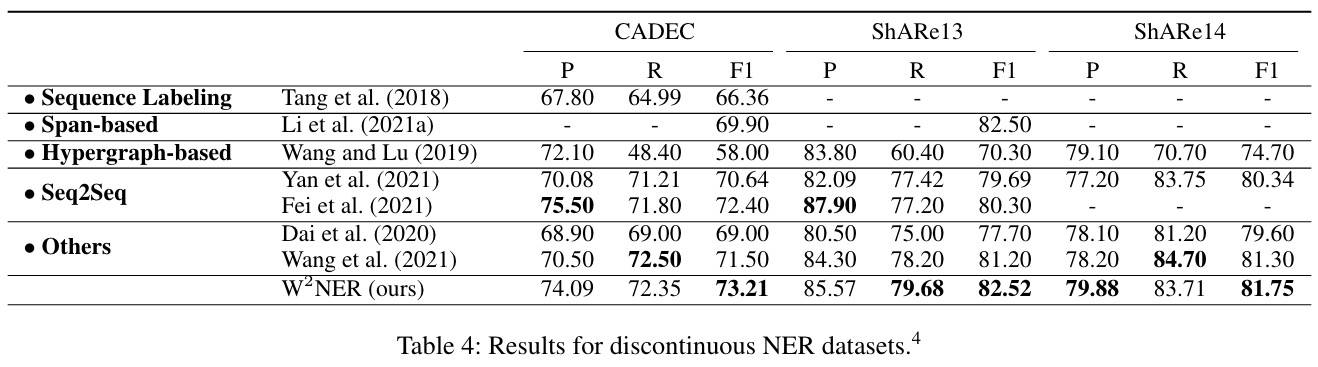
此外,考虑到后面两种情况中也包含了平铺 NER,所以,也评估了只有重叠和不连续 NER 的效果:

这下效果明显了,尤其是不连续 NER,效果好出一大截。
消融
结果如下图所示:
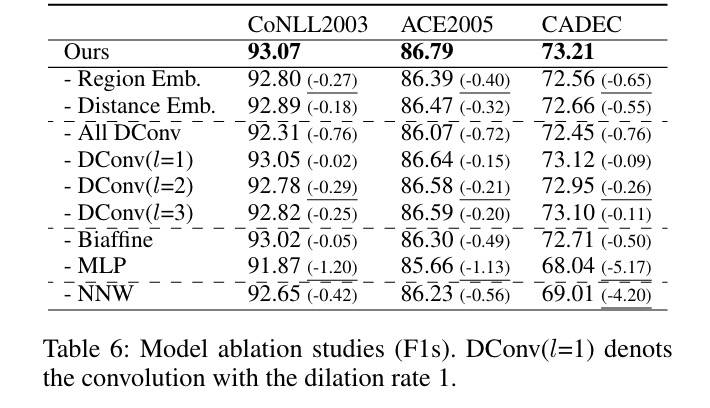
列出比较重要的因素:
- NNW:尤其对不连续 NER 效果明显(CADEC 数据集)
- MLP:主导作用
- DConv(L=2)
- Region Emb
小结
本文基于词-词关系分类,提出一个统一的实体框架 W2NER,关系包括 NNW 和 THW。框架在面对各种不同的 NER 时非常有效。另外,通过消融实验,发现以卷积为中心的模型表现良好,其他几个模块(网格表示和共同预测器)也是有效的。总的来说,本文更加关注边界词和内部词之间的关系,另外 2D 网格标记方法也可以大大避免 Span 和序列标注模型中的缺点。