Paper: https://arxiv.org/pdf/1810.04805.pdf
Code: https://github.com/google-research/bert
Bert 的核心思想:MaskLM 利用双向语境 + MultiTask。
Abstract
BERT 通过联合训练所有层中的上下文来获取文本的深度双向表示。
Introduction
两种应用 pre-trained model 到下有任务的方法:
- feature-based:比如 ELMo,将 pre-trained 表示作为额外的特征
- fine-tuning:比如 OpenAI GPT,引入少量特定任务参数,在下游任务中 fine-tuning 所有的参数
现在的技术有个限制,就是只能采用从左到右的单向机制,这对有些任务是不适合的,比如问答。
Bert 通过 “masked language model” 缓和了这个限制,即随机 mask 输入中的一些 token,目标是只根据上下文(左边和右边)预测 mask 掉的原始 vocabulary id。
同时,还联合训练了一个 “next sentence prediction” 的任务用来表示文本对。
Related Work
Unsupervised Feature-based Approaches
-
Word Embedding:
- 从左到右的语言模型(Mnih and Hinton,2009)
- 从上下文中区分出正确的中心词(Mikolov,2013)
-
Sentence Embedding:
- 对候选的一组下一句进行排序(Jernite, 2017; Logeswaran and Lee, 2018)
- 给定句子从左到右生成下一句的词(Kiors, 2015)
- 去噪自动编码(Hill, 2016)
ELMo 使用从左到右和从右到左两个语言模型,每个 token 的上下文表示都与两个语言模型关联。
Melamud (2016) 通过一个从左右上下文预测一个单独的词的任务(使用 LSTMs)学习上下文表示。
Unsupervised Fine-tuning Approaches
- 直接从语料中训练 embedding(Collobert and Weston, 2018)
- 从文本中训练上下文表示,在下游任务中 fine-tuning(Dai and Le, 2015; Howard and Ruder, 2018; Radford, 2018)
- OpenAI GPT (Radford, 2018)
Transfer Learning from Supervised Data
一些有效的迁移学习:
- 自然语言推理
- 机器翻译
BERT
两步:
- pre-training:基于多任务
- fine-tuning:用 pre-trained 参数初始化,然后在有监督任务上精调
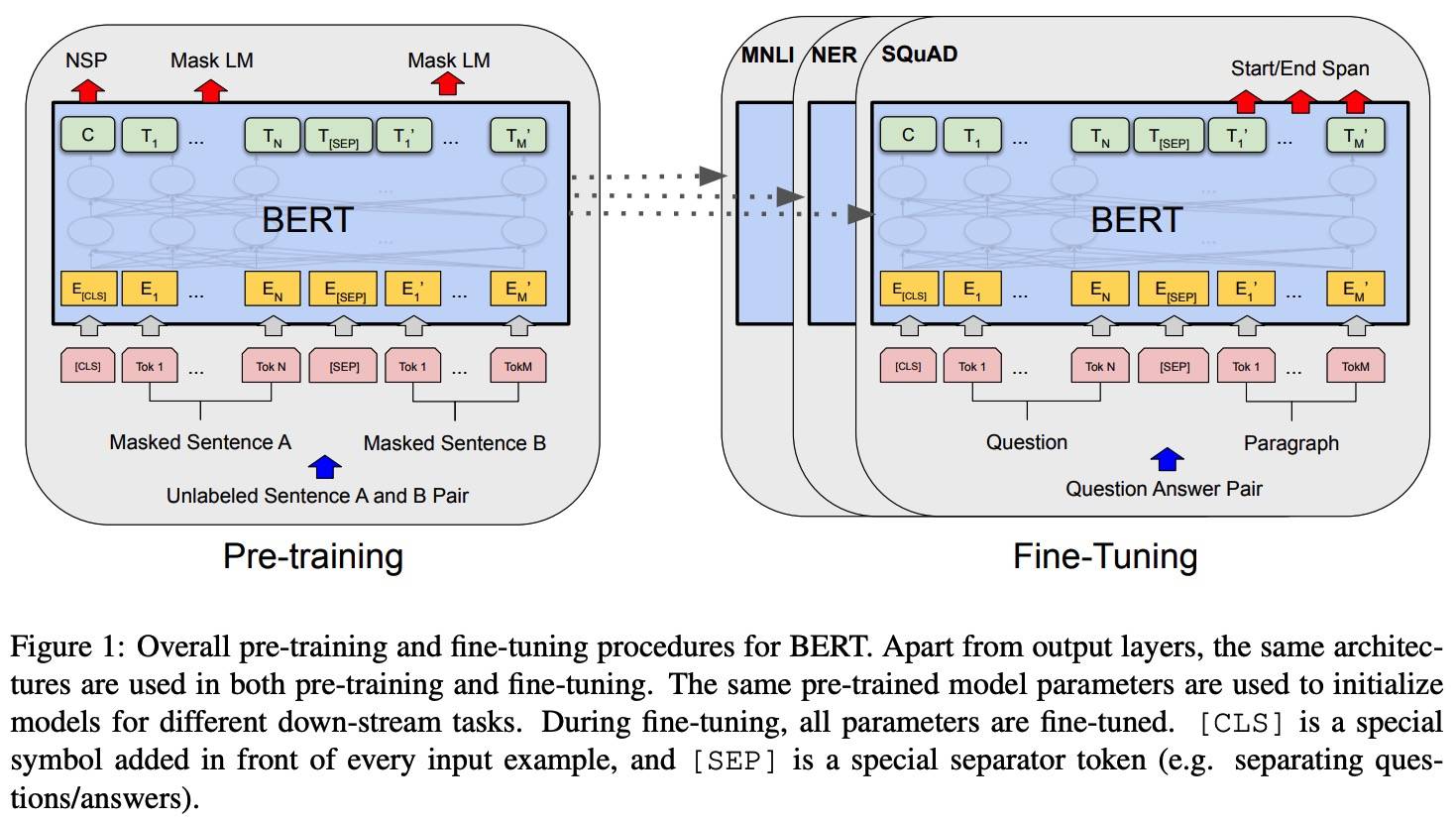
Model Architecture
- 多层双向 Transformer encoder
- Layer number (Transformer blocks): L (Base 12, Large 24)
- hidden size: H (Base 768, Large 1024)
- number of self-attention heads: A (Base 12, Large 16)
Input/Output Representations
- 输入句子对(比如 《问题,答案》)作为一组 token 序列,“一句” 是指相邻的文本,而不是实际中的 “一句”
- 使用 WordPiece Embedding (Wu, 2016)
- 最后一个隐层的状态作为序列的表示
- 两种方法将句子对被处理成一个句子:用特殊标记(SEP)分开;或用一个新的 Embedding 标记每个 token 属于哪一句
- 每一个 token 的输入表示由 token + segment + position 的 Embedding 组成

Pre-training BERT
没有使用自左向右或相反方向的语言模型,而是使用了两个无监督任务。
Task #1: Masked LM (MLM)
随机 mask 输入中一定比例(15%)的 token,然后预测这些 token,最后的隐层向量将喂给 softmax。
只预测 mask 掉的 token,而不是重建整个输入。
但有个问题是 fine-tuning 的时候没有 mask,所以并不是简单地直接把 mask 的 token 替换成 [MASK]:
- 80% 替换为
[MASK] - 10% 选择一个随机 token
- 10% 依然使用原来的 token
Task #2: Next Sentence Prediction (NSP)
所有的句子对中,50% 是上下句关系,50% 是随机的下一句。
Pre-training data
使用文档级别的 corpus 而不是随机化的句子级别的 corpus。
Fine-tuning BERT
pre-training 中的句子 A 和 B 在不同任务中相当于:
- 释义:句子对
- 蕴涵:假设-前提对
- 问答:问题-段落对
- 文本分类、序列标记:文本-空对
Experiments
- GLUE: 一组自然语言理解任务。
- SQuAD v1.1: 问答任务。
- SQuAD v2.0: 无短答案的问答任务。
- SWAG: 常识推理任务。
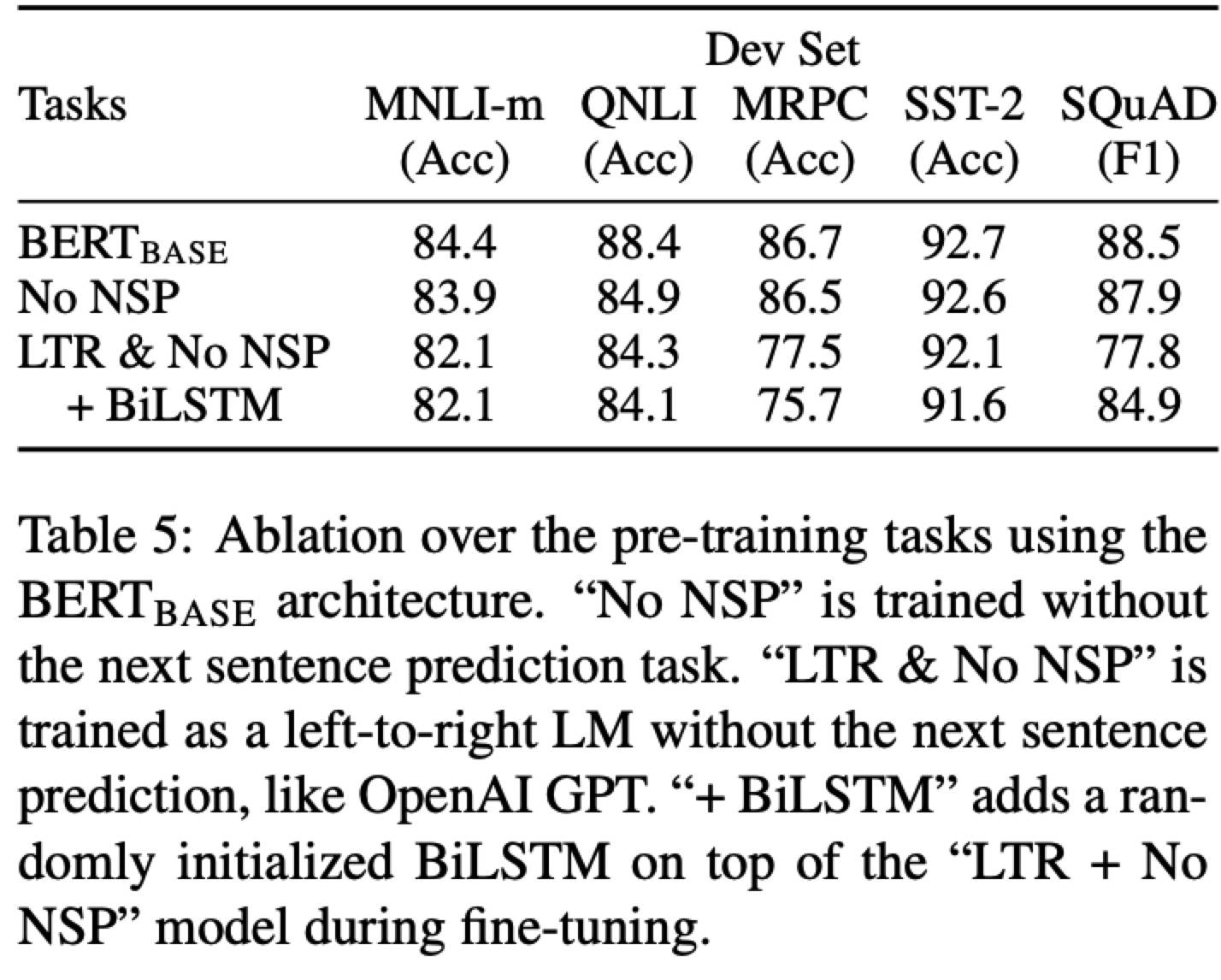
Ablation Studies
Effect of Pre-training Tasks
Effect of Model Size
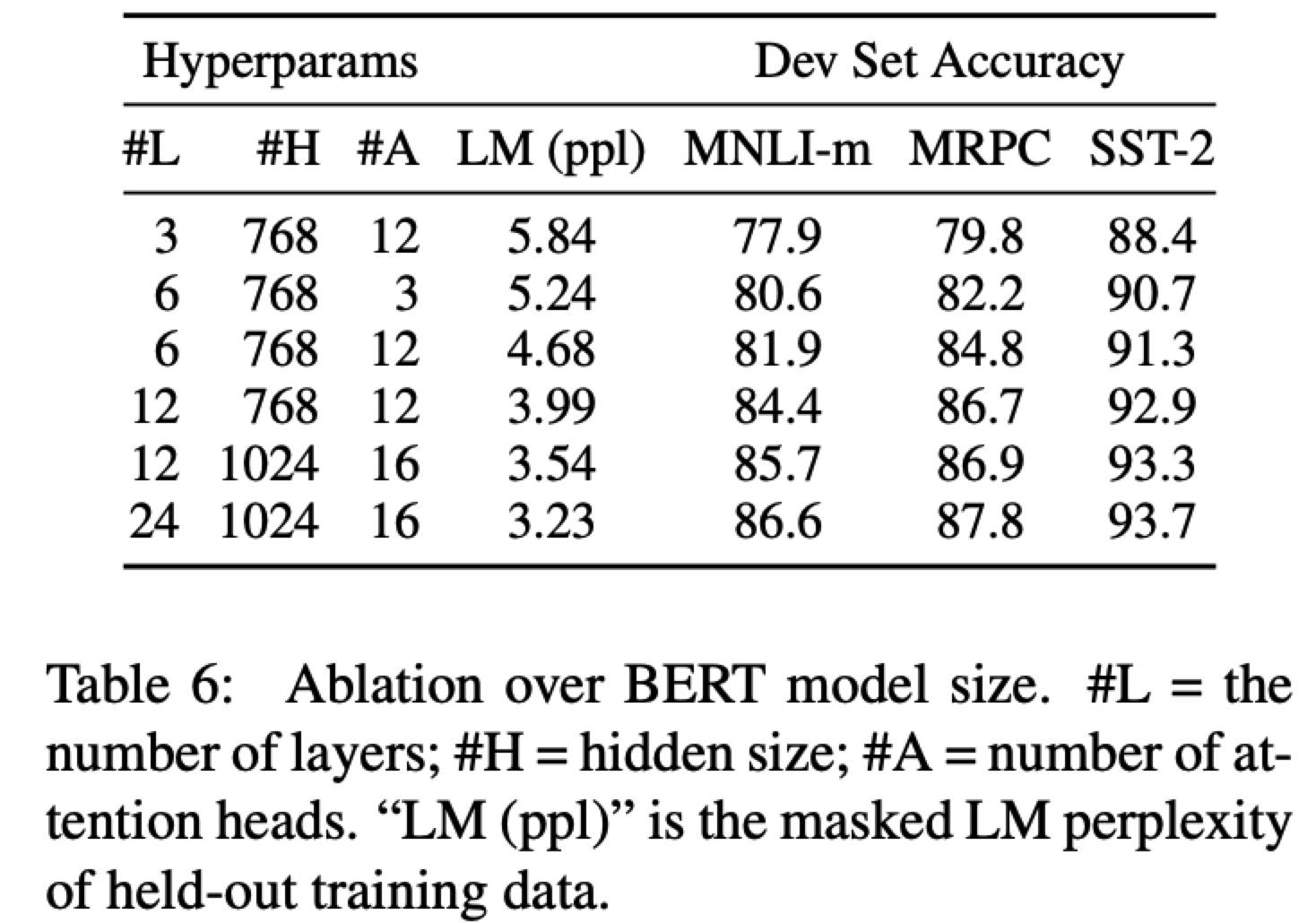
Feature-based Approach with BERT