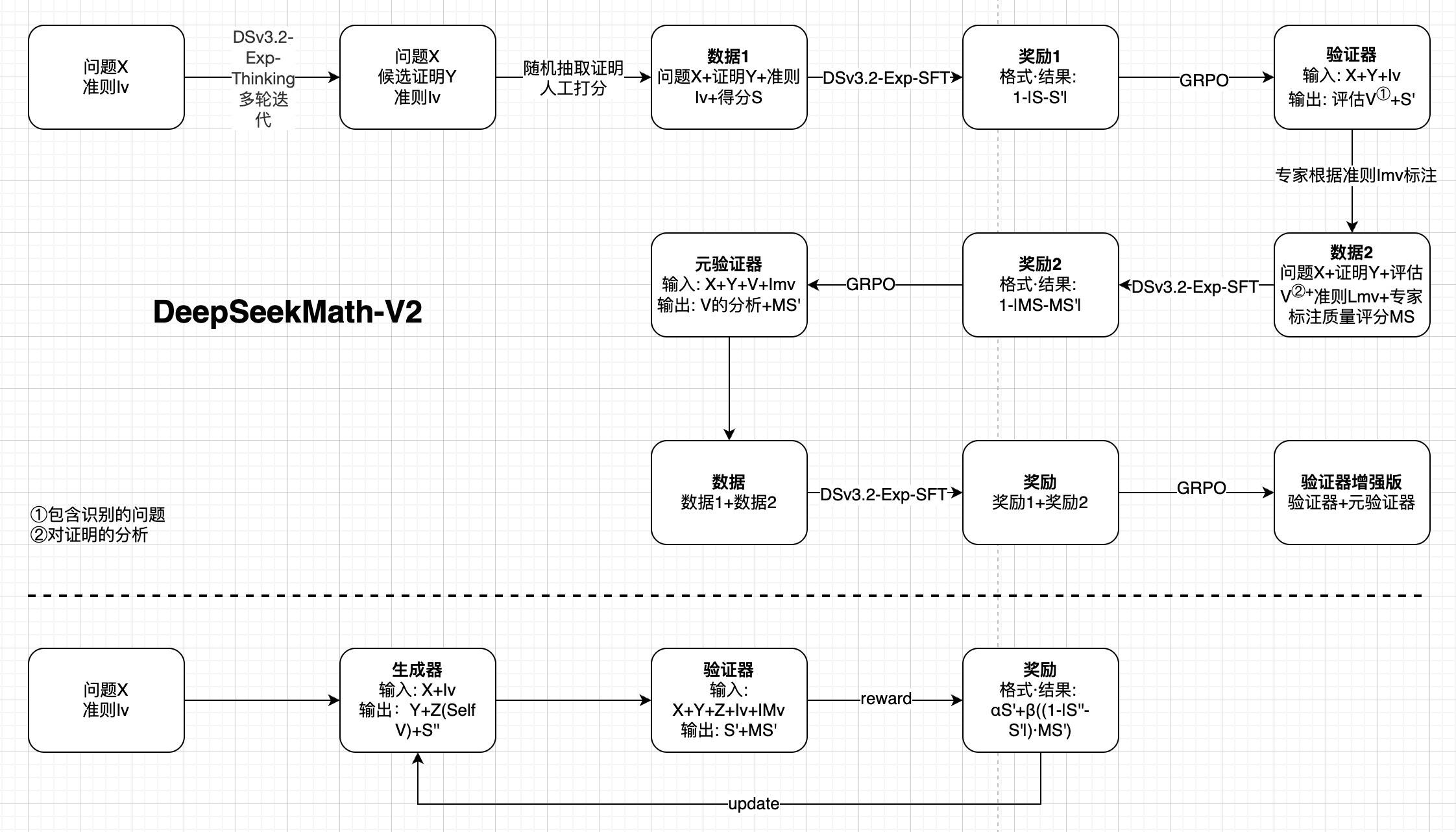
在开放性问题上,仅靠生成答案很容易出错。如何让模型不仅能写出证明,还能识别自身错误,从而形成闭环优化?答案是——自我验证。来看一下 DeepSeek 最新的论文:DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning[1],看自我验证如何让 LLM 生成与评估协同来提升数学定理证明能力。
TL; DR
- 训练验证器:验证器不仅打分,还识别证明中的问题。
- 引入元验证:通过二次评分机制防止验证器虚构问题,使验证分析更可靠。
- 训练生成器:生成器在生成证明后进行自我分析,并根据验证器和元验证器的反馈优化输出。
- 验证生成协同:生成器与验证器形成闭环,生成新的证明挑战验证器能力,同时扩大自动标注数据,提高整体系统可靠性。
核心启示是:奖励模型不仅要给分数,更要建模评估分析过程,让生成与验证形成协同闭环,显著提升开放性问题的推理能力。