国外的一个项目,看了一下比较简单,于是也拿过来玩儿一下。由于原项目没支持中文,就简单支持了一下,顺便简单地重构了一下代码。
- 代码地址(Fork):https://github.com/hscspring/llm-colosseum
- 项目原地址:https://github.com/OpenGenerativeAI/llm-colosseum
设计
项目的整体逻辑非常简单,直接使用LLM生成对应的Action,其他都交给diambra了。核心逻辑就下面这几行代码。
1 | while True: |
LLM根据当前位置和奖励情况输出下一步的Action。示例如下:
1 | 你是世界上最好、最具侵略性的街头霸王 III 3rd Strike 玩家。 |
这个Prompt每一轮都会更新,然后LLM会输出对应的Action,比如:
1 | - Move Closer |
由于使用同一个角色,同样的提示词,所以结果还是有一定参考意义的。
运行
启动非常简单,根据原网站安装好后,先启动引擎,然后启动执行脚本。如下所示:
1 | # 先启动engine |
这里的LAN可以指定语言,可选为zh和en,LOG可以指定日志级别,debug会输出每一次的Prompt,info则只输出玩家动作。最后两个是模型对应的名称,默认有下面一些。
1 | MODELS = { |
如果不提供两个名称(PK的对象),则随机从上面的模型里选择两个。
因为都是通过API进行调用的,所以需要提供千问和智谱的Key,写在.env里,source .env即可。如果需要使用本地LLM或其他API,修改agent/llm.py即可。注意让LLM的输出为字符串。
结果
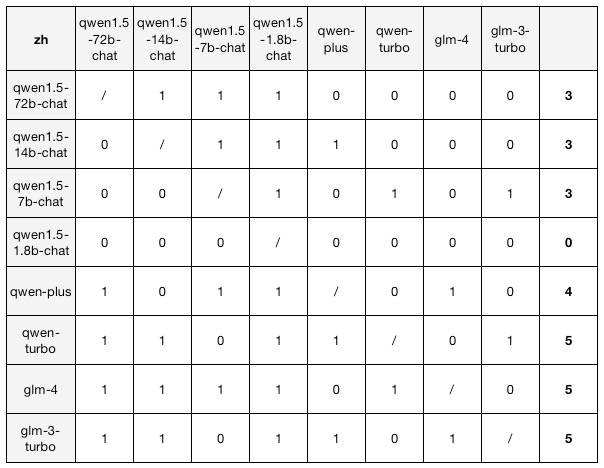
主要测了千问和智谱系列,测试结果仅供参考;)。以“行”为基准查看,1表示该模型胜过了列上的模型,0则相反。
中文结果:
英文结果:
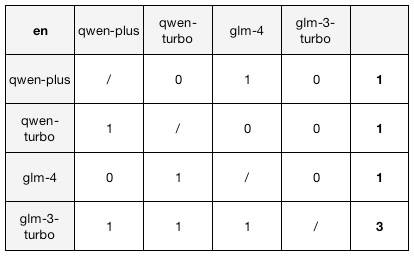
其实相差不太大,关注中文结果,我们发现,qwen-turbo、glm-turbo、glm-4不相上下。专门对qwen-turbo和glm-turbo进行了PK,结果也不是稳定的,双方互有输赢。感兴趣的朋友可以进一步探索,比如使用其他模型、调试提示词、更换角色、更换游戏等。值得一提的是,如果更换角色,相应的动作列表、基本配置可能需要修改;如果更换游戏,则需要改更多的配置。
最后
LLM的测评是个非常有意思的话题,迄今为止主流做法还是各种数据集榜单,肯定不是最好的方法,但简单、直观,起码可以做个参考。有Paper在训练LLM的同时训练一个评测的LLM——即用LLM评测LLM。还有放在竞技场上的评测,给定输入,随机选择2个模型输出,由用户投票“好”的输出,最终统计所有模型的得分。当然还有很多非常规的评测方法,不过本项目又给我们提供了一个新的好玩儿的思路。其实这种思路就是“放在实际场景”评测的特殊版本,这种评测显然看起来更加合理些。