关于重要性采样系数,之前已经介绍过不少了,不过主要方案还是 clip,比如《GRPO“又一背锅侠”:Clip的各种拉扯 | 长琴[1]》中介绍的一系列文章,更进一步的优化是《GRPO优化在继续——CISPO和熵 | 长琴[2]》的 sg 和 特定 token mask,Minimax 后续模型也都用了自家的 CISPO,但是依然没有脱离 clip 和超参数设置。
Clip 有助于训练稳定,这没问题,但它最大的问题是会抑制来自高偏差策略样本的梯度,从而丢失有价值的学习信号。本文我们介绍的 SIS(Selective Importance Sampling)来自论文 Turning Off-Policy Tokens On-Policy: A Plug-in Approach for Improving LLM Alignment (arxiv:2607.04728)[3](文章图片、公式均来自此论文),在这个方向上再进一步。他们的出发点很简单——将那些 off-policy 的 token 转为 on-policy,自然就不需要 IS 了。具体怎么做的呢?他们将旧策略作为建议分布,执行 token 级别的拒绝测试:被接受的 token 自然就可以看作 on-policy 的,被拒绝的那就保持原来的 IS。
SIS 是即插即用的,仅修改重要性采样系数,而且它还有个正的外部性——提升训练的稳定性。关于稳定性我们在《GRPO“第一背锅侠”Token Level X:DAPO/DrGRPO与GSPO/GMPO的殊途同归 | 长琴[4]》提过,后面又专门写了两篇相关文章:《稳定压倒一切:MoE RL 训推不一致问题及解决策略 | 长琴[5]》、《MoE RL 训练不稳定性再思考:训推不一致,还是采样噪声? | 长琴[6]》,感兴趣的同学可以进一步阅读。
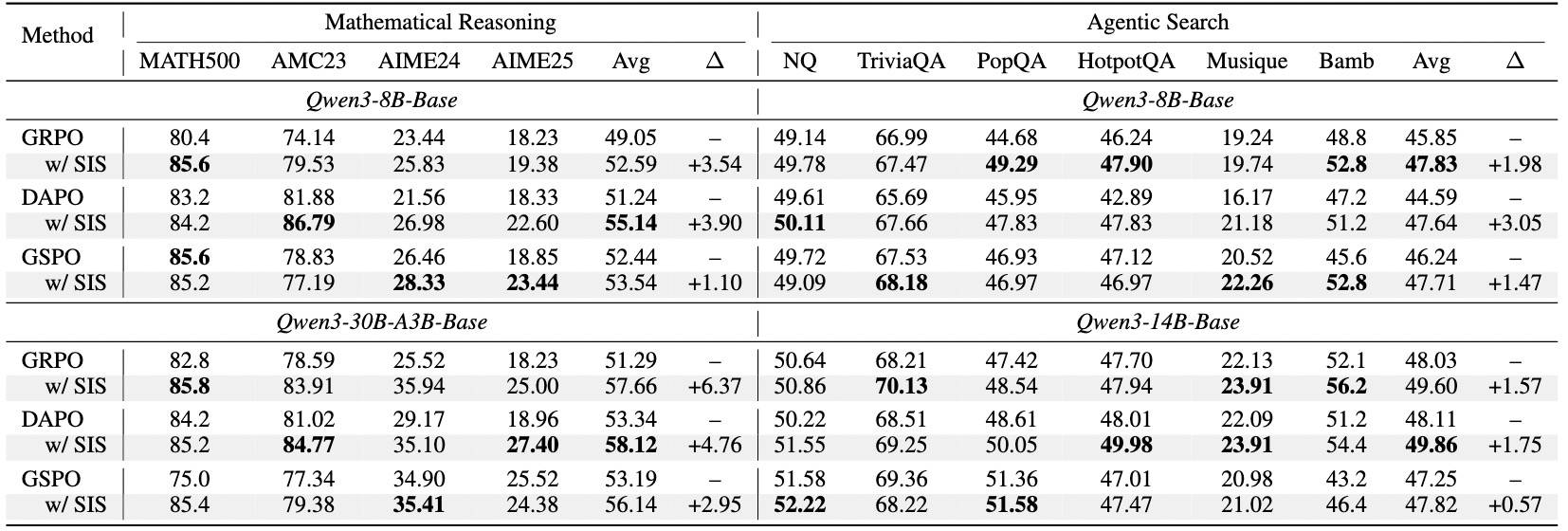
这里的问题或麻烦可能在于引入一个拒绝测试,不过论文给出了一个近似做法,使整个计算保持较低计算成本。效果和稳定性双全(见下表),值得一试。