机器学习的数据集一般被划分为训练集和测试集,训练集用于训练模型,测试集则用于评估模型。针对不同的机器学习问题(分类、排序、回归、序列预测等),评估指标的选择也有所不同。本文主要介绍机器学习中常用的模型评估指标。
PEGASUS 论文笔记
Paper:[1912.08777] PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
核心思想:基于 GSG 的 Transformer 在文本摘要上的应用。
核方法 和 SMO
Find First and Last Position of Element in Sorted Array (LeetCode 34)
Given an array of integers nums sorted in ascending order, find the starting and ending position of a given target value.
Your algorithm’s runtime complexity must be in the order of O(log n).
If the target is not found in the array, return [-1, -1].
Example 1:
1 | Input: nums = [5,7,7,8,8,10], target = 8 |
Example 2:
1 | Input: nums = [5,7,7,8,8,10], target = 6 |
Constraints:
0 <= nums.length <= 10^5-10^9 <= nums[i] <= 10^9numsis a non decreasing array.-10^9 <= target <= 10^9
Search in Rotated Sorted Array (LeetCode 33, 81, 153)
Given an integer array nums sorted in ascending order, and an integer target.
Suppose that nums is rotated at some pivot unknown to you beforehand (i.e., [0,1,2,4,5,6,7] might become [4,5,6,7,0,1,2]).
You should search for target in nums and if you found return its index, otherwise return -1.
Example 1:
1 | Input: nums = [4,5,6,7,0,1,2], target = 0 |
Example 2:
1 | Input: nums = [4,5,6,7,0,1,2], target = 3 |
Example 3:
1 | Input: nums = [1], target = 0 |
Constraints:
1 <= nums.length <= 5000-10^4 <= nums[i] <= 10^4- All values of
numsare unique. numsis guranteed to be rotated at some pivot.-10^4 <= target <= 10^4
Swap Nodes in Paris (LeetCode 24)
Given a linked list, swap every two adjacent nodes and return its head.
You may not modify the values in the list’s nodes, only nodes itself may be changed.
1 | Given 1->2->3->4, you should return the list as 2->1->4->3. |
Hard-SVM, Soft-SVM 和 KKT
SVM 是机器学习在神经网络兴起前最经典、有效的算法。它的思想主要是用一个超平面对数据集进行划分,但是能够分开数据集的超平面一般都有无数个,支持向量机的做法是 “间隔最大化”,也就是选择 “支持向量” 到分割平面距离之和最大的,进而将问题转换为一个凸优化问题。
支持向量机根据数据集可分程度的不同分为:
- 线性可分支持向量机:数据线性可分,硬间隔支持向量机
- 线性(不可分)支持向量机:数据近似线性可分,软间隔支持向量机
- 非线性支持向量机:数据线性不可分,核技巧 + 软间隔最大化
SVM 是一套完整的数据处理算法,核方法的引入使得它具有了对非线性数据的处理能力。具体的方式是将低维数据映射到高维,这样原来不可分的数据自然就可分了。比如假设两类数据点完全是均匀随机分布的,此时如果在平面内无论使用直线还是曲线都无法将它们分开,但假设我们有能力让某一类数据点全部脱离二维进入三维(此处可以想象桌子上散乱着小米和钢珠,你猛地用双手拍桌子,小米会跳起来进入第三维),那它们之间任意的平面都可以轻易将它们隔开。事实上,神经网络使用了类似的方法,感知机的中间隐层做的也是类似的事情。
本部分只介绍线性可分支持向量机和线性支持向量机。
Generate Parentheses (LeetCode 22)
Given n pairs of parentheses, write a function to generate all combinations of well-formed parentheses.
For example, given n = 3, a solution set is:
1 | [ |
AI 小课堂:Activation Function
基本思想
激活函数在深度学习中的作用就跟神经元中 “细胞体” 的功能类似:确定输出中哪些要被激活。我们都知道 SVM 通过核方法对非线性可分的数据进行分类,这其实是一种提升的方法(机器学习中很多问题都是类似的降个维度或升个维度)。为啥提升维度就能够让原本线性不可分的数据可分呢?我们以下图为例:
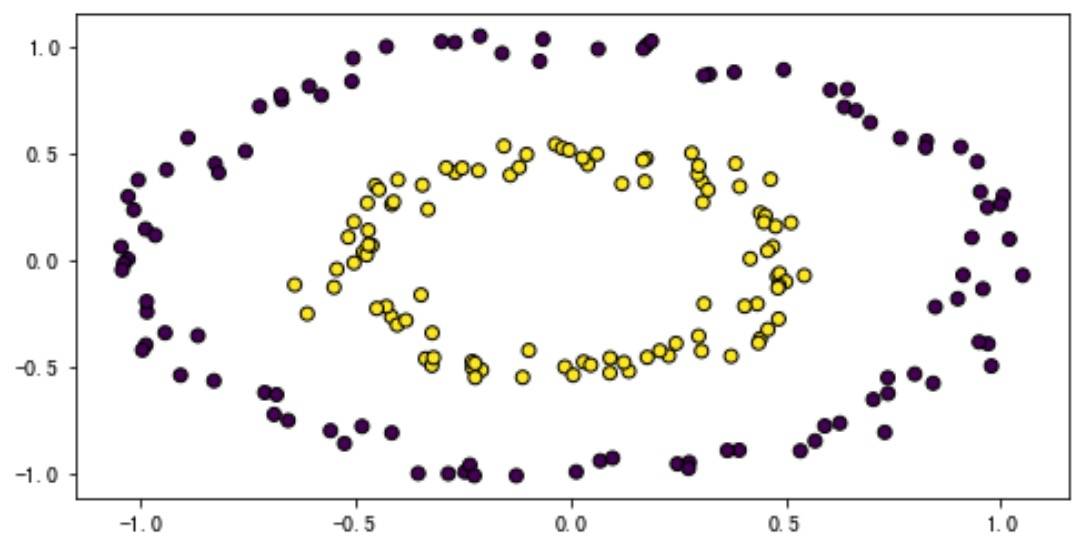
两组不同标签的数据构成一个近似的同心圆。要想将两种不同的点分开,靠二维的一条直线肯定是没办法了,此时我们可以把数据映射到三维空间,我们可以想象让同心圆之间再插入一个圆,然后让这个圆以内的整块都凸起来,也就是让它脱离原来的维度。这时候我们只要在两个平面中间任意选择一个平面就可以将数据集分开了。那这和我们的激活函数有啥关系呢?其实激活函数所提供的 “非线性” 变换正是类似的方式。也就是说,只要有非线性的激活函数,三层(输入、1 个隐层、输出层)的神经网络理论上可以逼近任意函数。
QA 小课堂:Introduction
说明:仅用于学习和技术交流,不提供任何投资建议。
基本流程
量化在金融分析中有两种主要的用途:选择标的,确定时机。一个完整的流程大概如下:
- 先有一个想法
- 将想法变成策略
- 将策略变成模型
- 验证优化