Given a linked list, swap every two adjacent nodes and return its head.
You may not modify the values in the list’s nodes, only nodes itself may be changed.
1 | Given 1->2->3->4, you should return the list as 2->1->4->3. |
Given a linked list, swap every two adjacent nodes and return its head.
You may not modify the values in the list’s nodes, only nodes itself may be changed.
1 | Given 1->2->3->4, you should return the list as 2->1->4->3. |
SVM 是机器学习在神经网络兴起前最经典、有效的算法。它的思想主要是用一个超平面对数据集进行划分,但是能够分开数据集的超平面一般都有无数个,支持向量机的做法是 “间隔最大化”,也就是选择 “支持向量” 到分割平面距离之和最大的,进而将问题转换为一个凸优化问题。
支持向量机根据数据集可分程度的不同分为:
SVM 是一套完整的数据处理算法,核方法的引入使得它具有了对非线性数据的处理能力。具体的方式是将低维数据映射到高维,这样原来不可分的数据自然就可分了。比如假设两类数据点完全是均匀随机分布的,此时如果在平面内无论使用直线还是曲线都无法将它们分开,但假设我们有能力让某一类数据点全部脱离二维进入三维(此处可以想象桌子上散乱着小米和钢珠,你猛地用双手拍桌子,小米会跳起来进入第三维),那它们之间任意的平面都可以轻易将它们隔开。事实上,神经网络使用了类似的方法,感知机的中间隐层做的也是类似的事情。
本部分只介绍线性可分支持向量机和线性支持向量机。
Given n pairs of parentheses, write a function to generate all combinations of well-formed parentheses.
For example, given n = 3, a solution set is:
1 | [ |
激活函数在深度学习中的作用就跟神经元中 “细胞体” 的功能类似:确定输出中哪些要被激活。我们都知道 SVM 通过核方法对非线性可分的数据进行分类,这其实是一种提升的方法(机器学习中很多问题都是类似的降个维度或升个维度)。为啥提升维度就能够让原本线性不可分的数据可分呢?我们以下图为例:
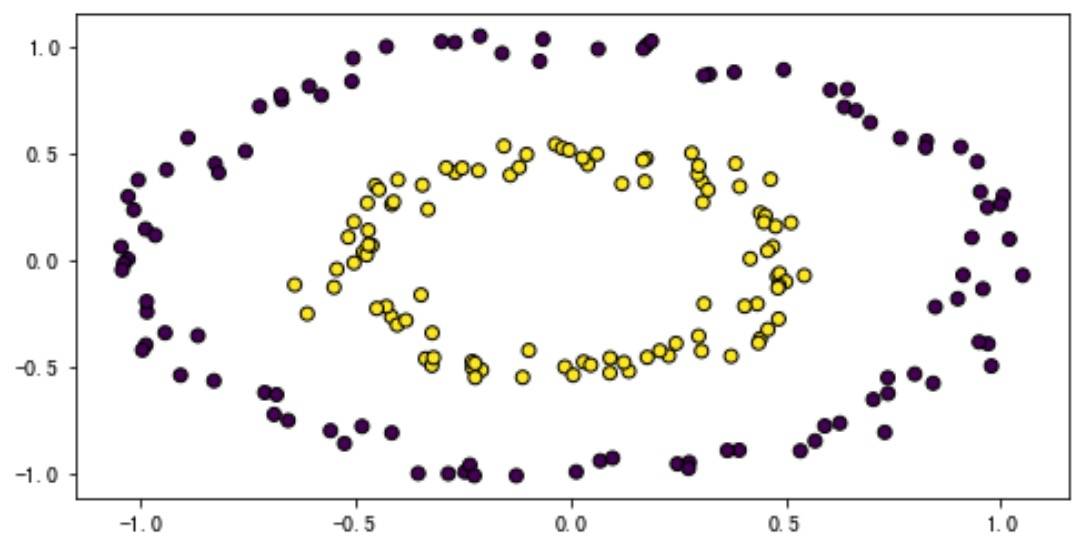
两组不同标签的数据构成一个近似的同心圆。要想将两种不同的点分开,靠二维的一条直线肯定是没办法了,此时我们可以把数据映射到三维空间,我们可以想象让同心圆之间再插入一个圆,然后让这个圆以内的整块都凸起来,也就是让它脱离原来的维度。这时候我们只要在两个平面中间任意选择一个平面就可以将数据集分开了。那这和我们的激活函数有啥关系呢?其实激活函数所提供的 “非线性” 变换正是类似的方式。也就是说,只要有非线性的激活函数,三层(输入、1 个隐层、输出层)的神经网络理论上可以逼近任意函数。
说明:仅用于学习和技术交流,不提供任何投资建议。
量化在金融分析中有两种主要的用途:选择标的,确定时机。一个完整的流程大概如下:
Paper:[2006.03654] DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Code:microsoft/DeBERTa: The implementation of DeBERTa
核心思想:增加位置-内容与内容-位置的自注意力增强位置和内容之间的依赖,用 EMD 缓解 BERT 预训练和精调因为 MASK 造成的不匹配问题。
Paper:[1907.11692] RoBERTa: A Robustly Optimized BERT Pretraining Approach
Code:fairseq/examples/roberta at master · pytorch/fairseq
核心思想:
对 BERT 几个小点(主要是动态 Mask 和不使用 NSP)进行优化取得了比较好的实践结果。
Paper:https://arxiv.org/pdf/1910.13461.pdf
Code:https://github.com/pytorch/fairseq
核心思想:基于 Transformer Seq2Seq 架构适应各种不同的输入噪声。
世界上这么多语言,如果直接从外观来看,大概有两种:一种是字符中间用空格隔开的,另一种是所有字符连在一起的。前者如英文、德语、俄语、法语等等,后者如中文、日文等,这类语言词与词之间没有用明显的标志分开。因此,分词就是想方设法将给定文本按一定方式隔开,便于计算机更好地处理。
Paper:1909.11942.pdf
Code:google-research/albert: ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
核心思想:基于 Bert 的改进版本:分解 Embedding 参数、层间参数共享、SOP 替代 NSP。