上一章提到了数据结构的重要性,这章开始我们就逐步深入理解一下数据结构相关的内容。最常用也是最常见的数据结构都是线性结构,线性结构简单来说就是一条序列,中间有若干元素,“线性” 也是和后面要说的树、图相比而言的。
需要注意的是,数据在计算机中有两种物理存储方式,分别是链式存储和顺序存储,顺序存储是利用计算机中连续一块内存进行存储,链式存储利用指针指向不同的地址进行存储;而上面列出的这些数据结构都是逻辑结构,存储方式不同数据结构的实现方法和复杂度也不同,但效果是可以完全相同的。
存储方式和结构之间没有关系,任何一种结构都可以使用顺序或链式存储实现,要看具体的场景和目的。
另外,在对数据结构的分析中,我们将重点关注两个方面:
- 该结构的特点是什么
- 该结构基本操作的详细实现思路
- 这里指的是类似伪代码的做法,侧重分析算法过程,具体实现可以直接看附的代码
- 基本操作是指抽象数据类型的操作集
什么是抽象数据类型?简称 ADT,在计算机科学中,抽象数据类型(ADT)是数据类型的数学模型,其中数据类型由其行为(语义)从数据用户的角度定义,特别是在可能的取值、 对此类数据的可能操作以及这些操作的行为等方面。详见:Abstract data type - Wikipedia
当然,也会对实际代码(C 语言为例)中的一些需要注意的点进行分析。
强烈建议结合给出的 code 看。
线性表
线性表是由同一类型的数据元素构成的有序序列线性结构。主要特点是:数据类型相同。基本操作包括:
- 初始化一个空表 L
- 根据位序 k 返回相应元素
- 查找元素 X 出现的第一次的位置
- 在位序 i 前插入一个新元素 X
- 删除指定位序 i 的元素
- 返回线性表 L 的长度
实际中,利用链式存储和顺序存储的线性表分别叫做链表和顺序表。链表是一种最基础的数据结构,由一组元素以一种特定的顺序组合或链接在一起。包括:单链表、循环链表、双向链表。顺序表是指在内存中用地址连续的一块存储空间顺序存放数据元素的表。这两种是最基础的数据结构,可以用来实现各种数据结构,尤其是链表的应用极为广泛,而且链式存储在插入和删除后不需要移动数据元素(只需要修改链)。选择不同的存储方式过程会不太相同,我们这里主要考虑基于链表的实现,分析侧重基本操作的详细实现思路。
关于结点的结构体定义:
- 对顺序表来说,定义一个结构,包括整个线性表的数据和最后一个元素的位置;
- 对链表来说,定义一个数据元素和指向下个元素的指针即可。
1 | // 一般 typedef 和 最后一个单词中间的就是原来的数据结构 |
结构这里稍微啰嗦了点,不过如果这个理解到位了,我觉得可能对理解代码的操作非常有帮助,而且无论哪种形式的写法一看基本就懂了,不至于变个形式一脸懵逼。相关代码在这里。
单链表
-
创建:主要有三种方式,分别是:头部插入、尾部插入和带头结点的尾部插入。
- 头部插入:
- 首先我们需要定义一个空的结点(链表的初始状态)和临时结点,均为之前定义好的结构体;然后读取数据并给临时结点分配空间;接下来将临时结点的 data 指向读入的数,Next 指向链表(第一次为空,即指向 NULL);然后把临时结点赋给链表;重复上面两步,最后返回链表。
- 这里面有个需要注意的地方:Next 第一轮指向链表时,链表为 NULL,即临时结点指向 NULL,然后把临时结点赋给链表时,链表最后的指向也是 NULL;之后轮中,临时结点每次都会首先指向上一轮创建的链表,这一步其实就是插入结点,是整个流程的核心步骤。
- 尾部插入:
- 头部插入因为是往前面插,所以遍历时元素正好是逆序的,当然这也并没有什么问题,不过我们习惯上还是按照插入的顺序输出。于是就有了尾部插入。思路和前者类似,有一个变化是需要增加一个尾部指针。
- 基本步骤如下:首先定义一个空结点(链表的初始状态)、一个空的尾部结点和一个临时结点,类型均为之前定义的结构体;然后读取数据并给临时结点分配空间;接下来将临时结点的 data 指向读入的数,这里需要注意,第一轮时,链表为 NULL,需要把临时结点赋给 Head,临时结点赋给尾部结点;然后之后轮中,尾部结点的 Next 指向临时结点完成插入,再把临时结点赋给尾部结点;最后如果尾部结点的 Next 没指向 NULL,就将其指向 NULL。
- 这种方式是通过利用一个尾部结点+临时结点的方式不断插入数据,特别要注意的是头结点,只需要第一轮处理一次即可,因为链表我们只需要知道头就可以了。还有个需要注意的是每一轮都需要把临时结点赋给尾结点,以便尾结点在下一轮插入前始终指向最后一个结点。
- 带头结点尾部插入:
- 尾部插入中,第一个结点没有直接前驱结点(加入时链表为空),所以第一个结点的地址就是整个链表的指针,需要放在链表的头指针变量中。其他结点都有直接前驱结点,地址放入直接前驱结点的指针域。因为第一个结点的特殊性,为了方便操作,一般会在链表头部加入一个 “头结点”,标识链表的头指针变量(Head)中存放该结点的地址,这样所有的结点处理方式就变得一致。头结点数据域无定义,指针域存放第一个数据结点的地址,空表时该指针域为空。
- 基本步骤如下:首先定义头结点(链表的初始状态)、滑动(尾部)结点和临时结点,类型均为之前定义的结构体;然后为头结点分配空间,并将头结点的 Next 指向 NULL(空表指针域为空);接下来是比较重要的一步:让滑动(尾部)节点等于头结点(目的是在接下来读入数据时,由滑动结点不停后移实现插入);然后读入数据并给临时结点分配空间,将临时结点的 data 指向读入的数;再将滑动(尾部)结点(第一轮就是 Head 结点)的 Next 指向临时结点完成插入;然后将临时结点赋给滑动(尾部)节点(以后轮就是刚插入的结点),这样尾部节点不断后移生成链表;最后将滑动(尾部)节点 Next 指向 NULL。
- 通过对比,我们发现这三种方法插入数据的思路差不多,最大的不同在头结点的处理。另外,尾部结点我觉得用滑块来称呼可能更容易理解,比如带头结点尾部插入算法中,刚开始滑动结点就在头结点上,然后加入进来新的结点后就把滑动结点的 Next 指向这个结点,然后再让滑动结点等于这个新结点。这样其实滑动结点把整个链条给走了一遍,理解起来非常简单。这里如果理解了的话,整个线性表就都不难了。
- 头部插入:
-
插入和删除:这两个有点类似,可以放一块说。插入是在某一个结点前面插入,删除是删除某一个结点,先简单分析一下思路。
- 插入时,我们有一个结点的数据和待插入的位置,首先找到这个位置的前驱结点,然后将前驱结点的 Next 指向要插入的结点,同时将结点 data 指向数据;接下来将插入结点的 Next 指向代插入位置;
- 删除时,我们只有待删除的位置,首先也是要找到这个位置的前驱结点,然后将前驱结点的 Next 指向待删除结点的 Next 即可。
- 还需要注意的是边界的判断。另外不难发现,链表最重要的是理解它指针指向的变化,尤其是滑动结点(尾部结点)的指针。
-
查找和求表长:查找包括按位置查找和按元素查找。遍历整个链表即可,稍微需要注意的是,每遍历一个元素,要让链表等于下个结点(即 链表=链表->Next)。另外带头结点的长度会加 1。
循环链表和双向链表
带头结点的单链表最后一个结点的指针域是空指针,也就是没有指向任何地方,如果将该指针域指向链表头(就是那个无定义的数据域),就构成了单循环链表。操作基本与单链表相同,只是原来判断指针是否为 NULL 变为是否指向头指针。对于单循环链表,可以从表中任意结点开始遍历整个链表,而且由于链表常用的操作是在表尾、表头进行的,通过尾指针可以提高一些操作效率。比如连接两个单循环链表,如果用头指针则需要找到第一个链表的尾结点,时间复杂度为 O(N),但用尾指针时间复杂度为 O(1)。
1 | // R1, R2 为尾指针 |
单链表没有保存前驱结点,所以每次寻找前驱结点的复杂度都为 O(N),如果为每个结点添加一个前驱结点,就变成了双向链表,如果首尾相连,则为循环双向链表。双向链表满足:p-Pre->Next = p = p-Next->Pre,在一些插入和删除操作中非常方便。
1 | // 插入:p 为某结点,在 p 前插入 s |
有关链表相关的基本操作和例子代码实现可以参考这里。
串
串是由零个或多个任意字符组成的字符序列。
- 串中任意连续字符组成的子序列为该串的子串。
- 子串第一个字符在主串中的序号为子串在主串中的位置。
- 两个串长度相等且每一个对应字符都相等,则串相等。
基本操作:
- 求串长、串赋值、串插入、串删除
- 串连接、求子串、串比较、串定位
由于串的特殊性质,我们采用顺序存储的方式,顺序存储可以事先固定长度,也可以动态分配内存,实际中一般采用后者,这种方式也叫堆分配存储。存储结构如下:
1 | typedef struct SNode *String; |
我们主要讨论串连接、求子串、串比较和串定位,其他操作和顺序表基本相同。
- 串连接:给定两个串,依次把每个串的元素赋给新建的串即可。需要注意的是,如果是用非动态分配内存的方式,要先判断位置够不够放两个要连接的串。
- 求子串:给定串、位置 i 和长度 len,返回从 i 开始,长度为 len 的子串。需要注意两个地方:
- 条件判断:
i<0, len>S->len, i>len, len<0这些是最基本的不满足条件,也可以len>S->Len-i保证一定能取到 len 长度的子串。 - 初始化:结构初始化(不初始化会收到警告,建议初始化)。如果是动态扩充子串,则需要初始化结构中指向元素的指针(数组),然后每增加一个元素扩充一次空间;如果是一次性指派大小,直接指派 len 大小的空间即可。
- 条件判断:
- 串比较:比较两个字符串,不相等时,给出的是第一个不相等位置元素的差值,比如
'abc' - 'abc ' = -32,就是空格的 ASCII。需要注意的是,两个数组不能用 a==b 来比较,因为他们的地址不可能一样,所以结果永远为 False,可以使用string.h中的 strcmp。 - 串定位:在给定串中寻找所有的子串,并返回子串的开始位置。
- 需要注意的是,给定串中已经比较过的字符是否可以继续使用会影响结果,比如给定串
abbabbabbabbaacc和子串abba,如果给定串中已经比较过的字符不能继续使用,则结果为 0 6,否则为 0 3 6 9。 - 程序本身需要注意的一个地方是 index 的修正,当比较的字符不相等时,需要把子串的 index 设置为 0 (即重新开始匹配),给定串的 index 设置为
i-j+1(i 和 j 分别为给定串和子串的 index,即要保证 i 不断在向前移动)。 - 另外,C 语言不能返回数组,一般是返回指针,这个指针指向数组的第一个元素的位置。
- 需要注意的是,给定串中已经比较过的字符是否可以继续使用会影响结果,比如给定串
相关代码实现在这里。另外,string.h 里面有很多字符串的操作已经实现。关于字符串的一些笔记也可参考:浙大翁恺老师《程序设计入门 ——C 语言》笔记 | Yam
数组
数组的元素可以是某种具有相同结构的数据,可看作线性表的扩充。一维数组可以看成一个线性表,二维数组可以看成数据元素是一维数组的一维数组。由于数组具有固定的格式和元素数量,因此在数组上一般不做插入、删除元素的操作,对数组的操作通常包括:取值、赋值操作。容易看出,数组采用顺序存储较为合适。一维数组比较简单,我们主要讨论二维数组。
二维数组一般有两种存储方式:以行序为主或以列序为主。以行序为例,Loc(Aij) = Loc(A00) + (i × n + j) × L,其中 n 为每行元素个数,L 为每个元素占据的地址单元。
如果二维数组中的元素均为数字,这时候该二维数组又叫矩阵,在机器学习中经常会遇到稀疏矩阵,即大多数的元素都是零,此时如果依然按照顺序存储将会浪费大量空间,所以对于稀疏矩阵一般只存储非零元素,即将每一个非零元素存储为 (i, j, v) 的三元组,i 和 j 表示位置,v 表示非零元素。
1 |
|
我们分别将元素和矩阵定义为两个指向结构体的指针,关于 struct 的定义可以参考:浙大翁恺老师《C 语言程序设计进阶》笔记 | Yam。
我们接下来重点讨论一下矩阵(稀疏矩阵)的转置。由于稀疏矩阵的存储采用上面定义的方式,转置会稍微麻烦一些,我们可以把原矩阵 data 中存储的每一个 elem 的 i 和 j 分别赋给新矩阵的 j 和 i,但这样有个问题:新的矩阵不一定和原始矩阵一个顺序(事实上基本不可能一个顺序)。举个例子:
1 | // 原矩阵 data |
我们当然可以依次按照列(转置后的行)从 0 到列数扫描一遍 data 的每个元素,按照顺序放到位置上(比如这里的实现):
1 | for (col=0; col<Matrix->col; col++) |
但这样的时间复杂度为:O(col × vnum),如果非零元素个数比较多时(假设所有元素非零),时间复杂度将达到 O(col × col × row),还不如按普通的存储方法存储。
仔细分析一下刚刚的算法,不难发现同一个非零元素重复了 col 次,这是完全没必要的,是否能够对其进行优化将时间复杂度降低一个数量级?我们发现,如果能直接确定矩阵中每个三元组在转置矩阵中的位置,那只要扫描一次矩阵即可。因为矩阵第一列的第一个非零元素一定存储在转置矩阵 data 的第一个元素,那么第二列的第一个非零元素就存储在转置矩阵 data 的第一个元素加原矩阵第一列非零的元素个数。
我们需要额外的两个数组,一个存储原矩阵每列非零元素的个数,定义为 num[];一个存储原矩阵每列第一个非零元素在转置矩阵 data 中的位置,定义为 cpo[]。分别满足:
cpo[0] = 0;原矩阵第 0 列第一个非零元素必定是转置矩阵 data 的第 0 个元素cpo[i] = cpo[i-1] + num[i-1];原矩阵第 i 列第一个非零元素就是转置矩阵第 i-1 个非零元素的位置加上原矩阵第 i-1 列非零元素的个数
举个例子,给定一个 2 x 3 的矩阵 A(转置矩阵为 TA):
1 | // A |
其时间复杂度为 O(col+vnum)。具体实现可以参考这里的代码。
堆栈
堆栈是具有一定操作约束的线性表(只在一端,即栈顶做)。基本操作包括:
-
栈初始化
-
判断是否为空栈或栈满
-
插入数据:入栈
-
删除数据:出栈并返回栈顶元素
堆栈的特点是后进先出(Last In First Out,LIFO),可以采用顺序存储或链式存储。
-
顺序存储:通常由一个一维数组和一个记录栈顶元素位置的变量组成。
1
2
3
4
5
6
7
8
9
10
11
12typedef struct Node *Stack;
struct Node {
int *data;
int Top;
int MaxSize;
}
// or
typedef struct Node *Stack;
struct Node {
int data[MAXSIZE];
int Top;
}- 初始化:通常将 0 下标设为栈底,空栈时
S→Top == -1,栈满时S→top == S→MAXSIZE-1; - 入栈:
S→data[++(S→Top)] = element; - 出栈:
return S→data[(S→Top)--]
- 初始化:通常将 0 下标设为栈底,空栈时
-
链式存储:实际是一个单链表,插入和删除只能在链栈的栈顶进行。
1
2
3
4
5typedef struct Node *Stack;
struct Node {
int data;
Stack Next;
}- 初始化:
S→Next = NULL,为空时一样; - 入栈:
Cell→data = element, Cell→Next = S→Next(NULL), S→Next = Cell; - 出栈:
Cell = S→Next, element = Cell→data, S→Next = Cell→Next;
- 初始化:
几种不同的堆栈实现可以参照这里的代码。
堆栈最常见的应用之一就是表达式求值了(如 3*2^(4+2*2-1*3)-5),这种我们日常使用的表达式叫 “中缀表达式”,即运算符在数字的中间;相对应地,还有后缀表达式和前缀表达式。其中后缀表达式非常方便计算机处理,基本步骤如下:
- 依次弹出后缀表达式栈中元素
- 如果是数字则直接压入新栈
- 如果是运算符则从新栈中弹出两个元素进行运算,然后将得到的结果压入新栈
- 弹出新栈最后一个元素即为计算结果
举个例子,比如表达式:2*3+4/2 对应的后缀表达式为:23*42/+:
- 新栈压入 2 3,遇见 × 号,弹出 3 2,计算得 6 压入新栈,此时新栈中元素为 6
- 新栈继续压入 4 2,遇见 ÷ 号,弹出 2 4,计算得 2 压入新栈,此时新栈中元素为 6 2
- 遇到 + 号,弹出 2 6,计算得 8,压入新栈
- 弹出新栈元素 8 为计算结果
那么,接下来的问题就是如何将中缀表达式转化为后缀表达式。这个稍微有一点复杂,其基本策略是:从头到尾读取中缀表达式的每个对象,对不同对象按不同情况处理:
- 运算数:直接输出
- 左括号:压入堆栈
- 右括号:将栈顶运算符弹出并输出,直到遇到左括号(出栈,不输出)
- 运算符:
- 若优先级大于栈顶运算符,则把它压入栈(要继续等待后面的结果)
- 若优先级小于等于栈顶运算符,将栈顶元素弹出并输出;再比较新的栈顶运算符,直到该运算符优先级大于栈顶运算符为止,然后将该运算符压入栈
- 若各对象处理完毕,则把堆栈中存留的运算符一并输出
代码实现在这里,由于使用 getchar 每次获取一个 char,因此目前只能计算每个数字是正的一位数的四则混合运算。具体实现时,有两点需要特别注意:
- 左括号运算符的优先级在栈内和栈外不同:栈外优先级最高,栈内最低
- 由于既有运算符又有数字,所以无论栈的类型是 char int 还是 float,都需要注意类型转换
队列
队列也是具有一定操作约束的线性表,只能在一端插入,另一端删除。基本操作包括:
- 生成空队列(初始化)
- 判断队列是否为空或满
- 将元素插入队列
- 将队头元素从队列中删除并返回
队列的特点是先进先出(First In First Out,FIFO),可以采用顺序存储或链式存储。
-
顺序存储:通常由一个一维数组和记录队列头、队列尾位置的变量组成
1
2
3
4
5
6
7
8
9
10
11
12
13typedef struct Node *Queue;
struct Node {
int data[MAXSIZE];
int rear, front;
int num;
}
// or 我们偏好(指针)使用的定义
typedef struct Node *Queue;
struct Node {
int * data;
int rear, front;
int MaxSize;
}队列在入队时,队尾指针加 1;出队时,队头指针加 1。这样有个问题是当元素不断出队时,data 会留出一大块空的空间(“假溢出” 现象):
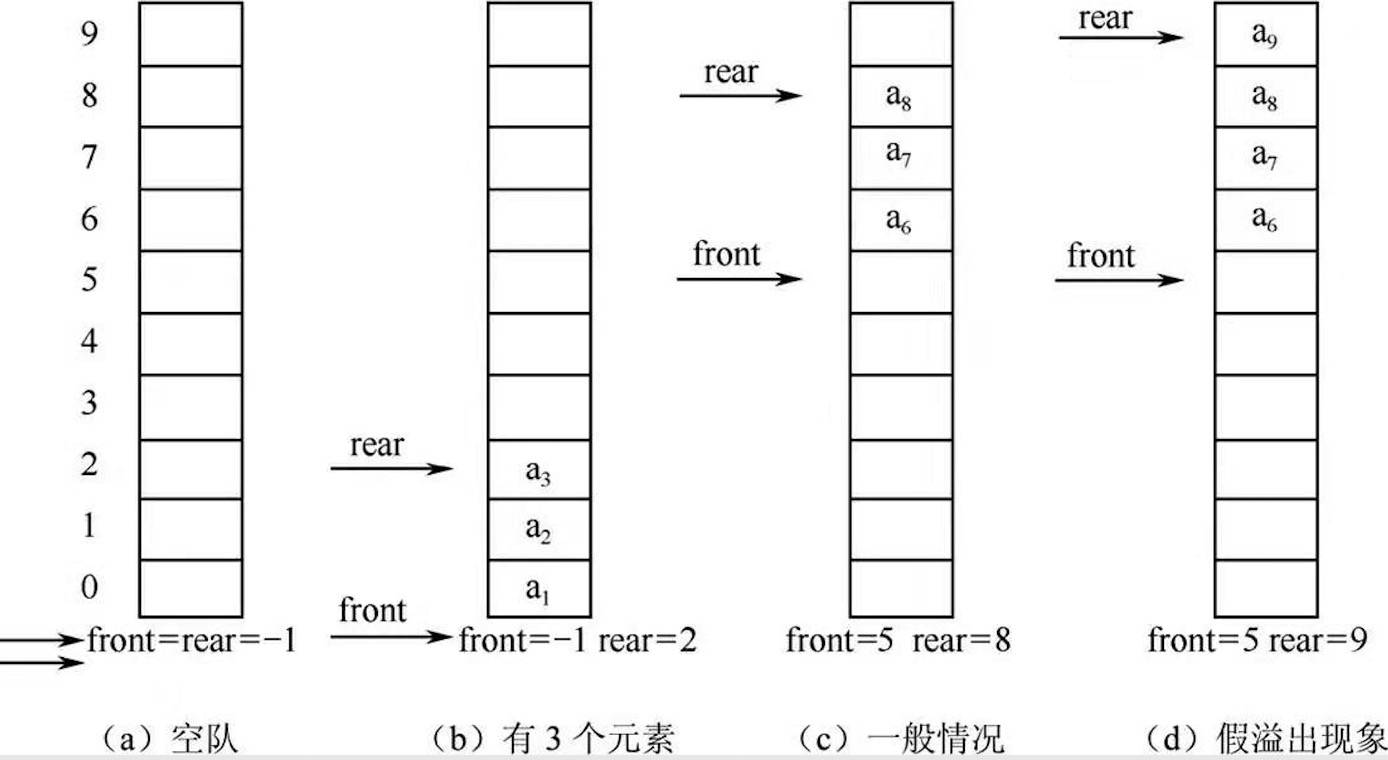
(图来自《数据结构(C 语言版)》邓文华)
解决方法之一就是使用循环结构(循环队列),此时入队或出队时,指针不能简单加 1,而是需要对 MAXSIZE 取余。原因是是循环结构,所以出队后空出来的位置可以入队新的元素。
另外还有个问题是 “队满” 和 “队空” 的条件是相同的:首尾指针指向同一个位置。有两个方法可以解决这个问题:
- 设置一个存储元素个数的变量,为 0 时队空;为 MAXSIZE 时队满;
- 留一个位置,队头指向该位置,队尾指向该位置的后一个位置,此时
(rear + 1) % MAXSIZE == front,表示队满;队头队尾指针指向同一个位置时队空。
接下来就是基本操作了(我们使用第二种方法):
- 初始化:
Q->front = Q->rear = 0; - 入队:
Q->rear = (Q->rear+1) % MaxSize; Q->data[Q->rear] = x; - 出队:
Q->front = (Q->front+1) % MaxSize; x = Q->data[Q->front]; - 是否空:
Q->front == Q->rear; - 是否满:
(Q->rear+1) % MaxSize == Q->front;
-
链式存储:可以用一个单链表实现,插入和删除分别在两头进行
1
2
3
4
5
6
7
8
9
10// 队列中的结点
struct Node {
int data;
struct Node *Next;
}
struct QNode {
struct Node *rear, *front; // 队列的头尾指针
int MaxSize; // 队列的最大容量
}
typedef struct QNode *Queue;基本操作如下:
- 初始化:
Pd->Next = NULL; Q->front = Pd; Q->rear = Pd; - 入队:
P->data = x; P->Next = NULL; Q->rear->Next = P; Q->rear = P; - 出队:
P = Q->front->Next; Q->front->Next = P->Next; x = P->data;如果出队后队列为空,要移动 rear 指针:if (Q->front->Next == NULL) Q->rear = Q->front; - 是否为空:
Q->rear == Q->front;
因为是链表实现,所以不存在 “满” 这种情况。下面的图例(带头结点的链队列)看起来非常清晰:
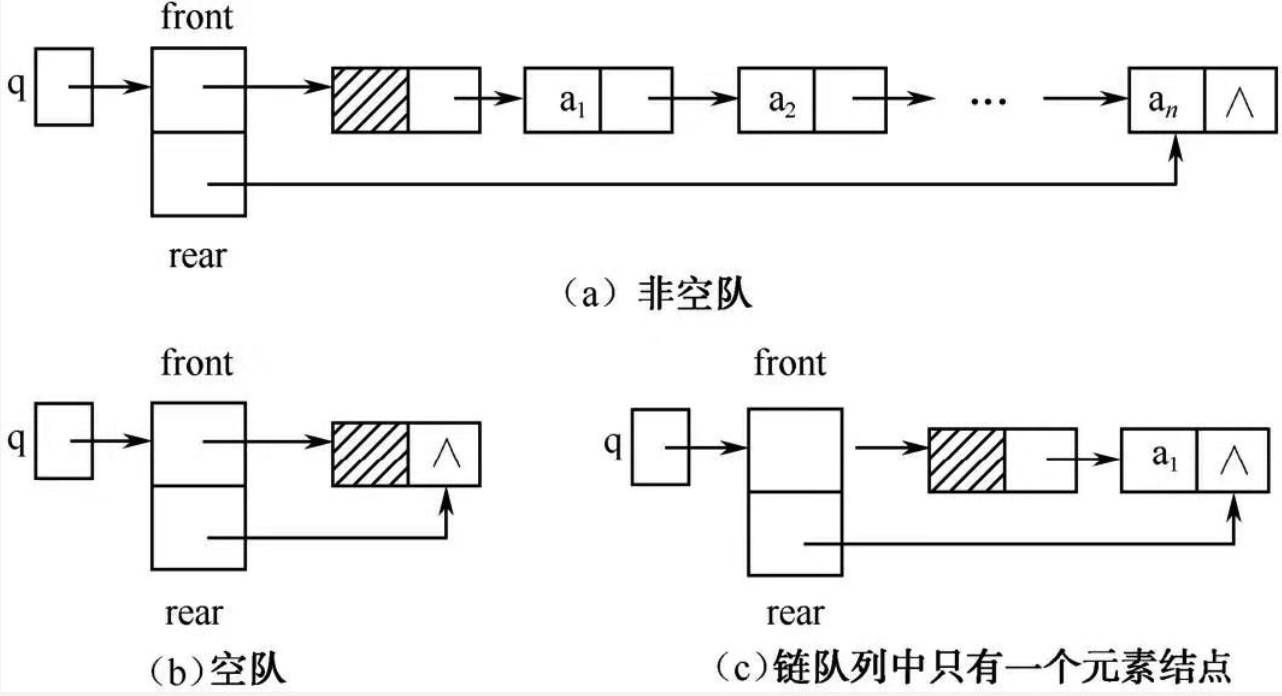
(图来自《数据结构(C 语言版)》邓文华)
- 初始化:
通过两种存储方式的对比可以明显感觉到彼此不同的特点,个人偏好链式存储,因为它看起来比较优雅。几种不同的队列实现可以参照这里的代码。
小结
线性结构的本质在于 “线性”,也就是说无论具体哪种结构,数据看起来都是像一条条 “线” 一样。对应于数据在计算机中物理存储的方式不同,又分为顺序和链式两种实现方式;具体采用哪种方式主要取决于目的,二者各有特色,并没有绝对的好坏。顺序存储利用了位置固定不变的信息,index 就很方便,但对应的插入和删除就比较麻烦;而链式存储就正好相反。当然,需要注意的是,不光是本章的线性结构,之后的树和图也同样如此。
线性结构是最基本的数据结构,本章涉及到的只是其中最基础(相对来说也是最简单)的部分,如果想更进一步了解,可以参考 Kyle Loudon 的《算法精解:C 语言描述》,该书最大的特色是讲解了各种数据结构在实际中的应用情况。