zihangdai/xlnet: XLNet: Generalized Autoregressive Pretraining for Language Understanding
XLNet 的核心思想:PermutationLM 使用双向上下文 + Transformer-XL 对架构进行改进。
Abstract
BERT 忽略了屏蔽位置之间的依赖关系,会有预训练和 Fine-tuning 效果的差异。
XLNet:
- 通过最大化因式分解顺序所有可能排列的对数似然,学习双向语境信息。
- 依靠自回归克服了 BERT 的缺点。
此外,XLNet 还将最先进的自回归模型 Transformer-XL 的思想整合到预训练中。
Introduction
两大成功使用的预训练模型:
- autoregressive (AR) language modeling,给定序列 X = (x1, …, xT),基于前向或后向语境建模:
- 前向:$$p(x) = \prod_{t=1}^T p(x_t|\mathbb {x}_{< t})$$
- 后向:$$p(x) = \prod_{t=1}^T p(x_t|\mathbb {x}_{> t})$$
- autoencoding (AE),不明确地进行密度估计,而是尝试从损坏的输入中重建原始数据。
- 比如 BERT 的 MASK,因为密度估计不是目标的一部分,所以可以进行双向语境建模。
- BERT 人为制造的 MASK 出现在预训练环节,但却没有在 Fine-tuning 环节,因此造成差异。
- 此外,由于输入中预测的 token 也被 MASK,因此 BERT 不能像 AR 中那样使用乘积法则对联合概率进行建模。也就是说,要预测的 token 在给定未 MASK 的 token 下被假设为彼此独立,这过度简化为自然语言中普遍存在的高阶、长期依赖关系。
XLNet 既结合了两者的优势又避免了局限性:
- 首先,不使用 AR 中固定的前向或后向,而是最大化序列因式分解顺序所有可能排列的期望对数似然,每个位置都可以学习利用所有位置的语境(上下文)信息。
- 其次,不依赖损坏数据,所以也不会有 BERT 的预训练与 Fine-tuning 效果差异;同时,利用 AR 中的乘积法则分解预测 token 的联合概率,消除了 BERT 的独立性假设。
除此之外,还改进了预训练的架构设计:
- 将 Transformer-XL 的 segment recurrence mechanism 和 relative encoding scheme 整合到预训练中,改进了性能,尤其是长文本序列任务。
- 对 Transformer-XL 的参数进行修改,移除因式分解顺序任意导致的训练目标模糊性。
Proposed Method
Background
AR language modeling:
hθ 是上下文的表征,一般来自 DNN,RNN 或 Transformer。
BERT:
随机选择一定比例(15%)的 token 当做 MASK,从 x^ 重新构建出训练数据 $$\overline x$$
mt=1 表示 xt 是 MASK,Hθ 是一个将文本序列 X 映射为 hidden vector 序列的 Transformer。
两者将从以下几个方面对比:
- 独立性假设:BERT 假设所有 MASK 的 token 是独立分别重建的(也就是 MASK 的 token 之间是相互独立的);AR 使用乘积法则,并没有这样的假设。
- 输入噪音:BERT 包括了真实任务中没有的人为 MASK,AR 没有。
- 上下文独立性:AR 只考虑了前面的 token,BERT 则考虑了双向的上下文。
Objective: Permutation Language Modeling
本文通过考虑给定序列所有可能的顺序(序列长度的阶乘种可能)来达到使用双向的上下文信息的目的,其直觉是:如果模型的参数在所有的顺序中共享,模型自然而然能够学习从所有位置(当然包括双向上下文)收集信息。
问题:能否使用双向 AR
需要说明的是,这里并不会调整序列的顺序,而是使用对应于原始位置的位置编码,并依赖 Transformer 中适当的 Attention Mask。
Architecture: Two-Stream Self-Attention for Target-Aware Representations
直接使用标准的 Transformer 并不能 work,因为没有考虑到位置信息,因此需要对下一个 token 的分布重新参数化(zt 为 Input 中的 position):
那么,如何计算 gθ 呢?这里使用了两组 hidden representation (Two-Stream Self-Attention):
- content representation: encodes context and
x_zt - query representation: encodes context and position (zt) 而不是内容

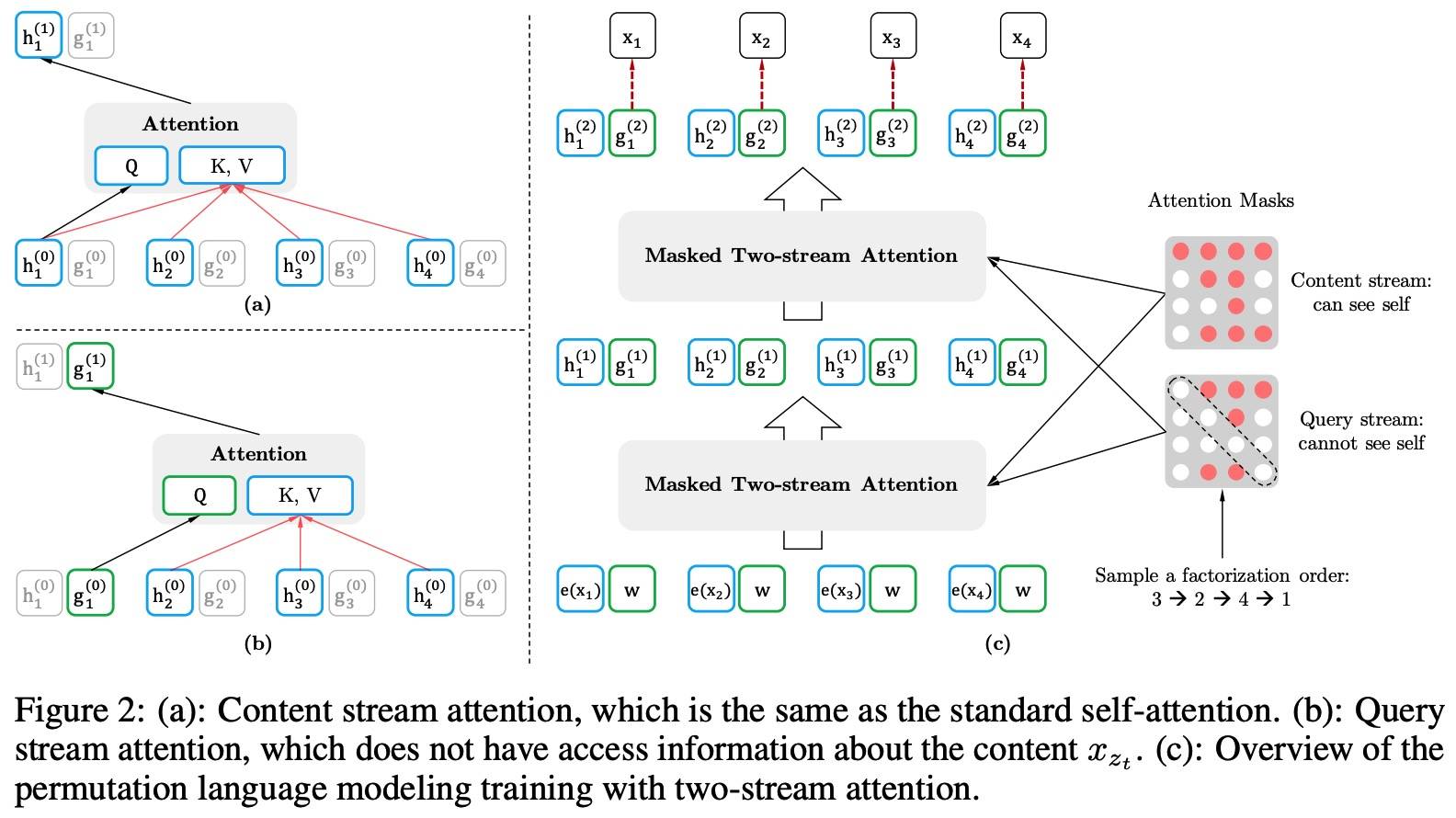
在 finetuning 时可以丢掉 query representation,使用 content representation 作为标准 Transformer。
由于不同排列导致的 Language Modeling 优化问题,这里只选择预测最后一个 token,具体是将 z 分为目标和非目标两部分 (Partial Prediction):
z > c 为 target,超参数 K 表示 1/K 的 tokens 被选中用来预测,|z| / (|z| − c) ≈ K,对于未选中的 tokens,query representation 不需要计算。
Incorporating Ideas from Transformer-X
Transformer-XL 的两个重要技术被融合:
- relative positional encoding scheme
- segment recurrence mechanism
上面已经讨论了第一个技术,接下来讨论第二个如何能够让模型从先前的分割中复用 hidden states。假设有一个长序列的两个分割:x˜ = s_{1:T} 和 x = s_{T+1:2T},z˜ 和 z 分别是对应的两个排列,然后基于排列 z˜,我们处理第一个分割,然后将每个 layer m 的 content representation h˜(m) 存起来。那么对于分割 x:
因为位置编码只依赖原始序列的实际位置,所以此 Attention 的更新在获得 h˜(m) 后与 z˜ 独立,这允许在不知道上一个分割的序列顺序的情况下重复使用 memory。query stream 也可以用同样的方法。
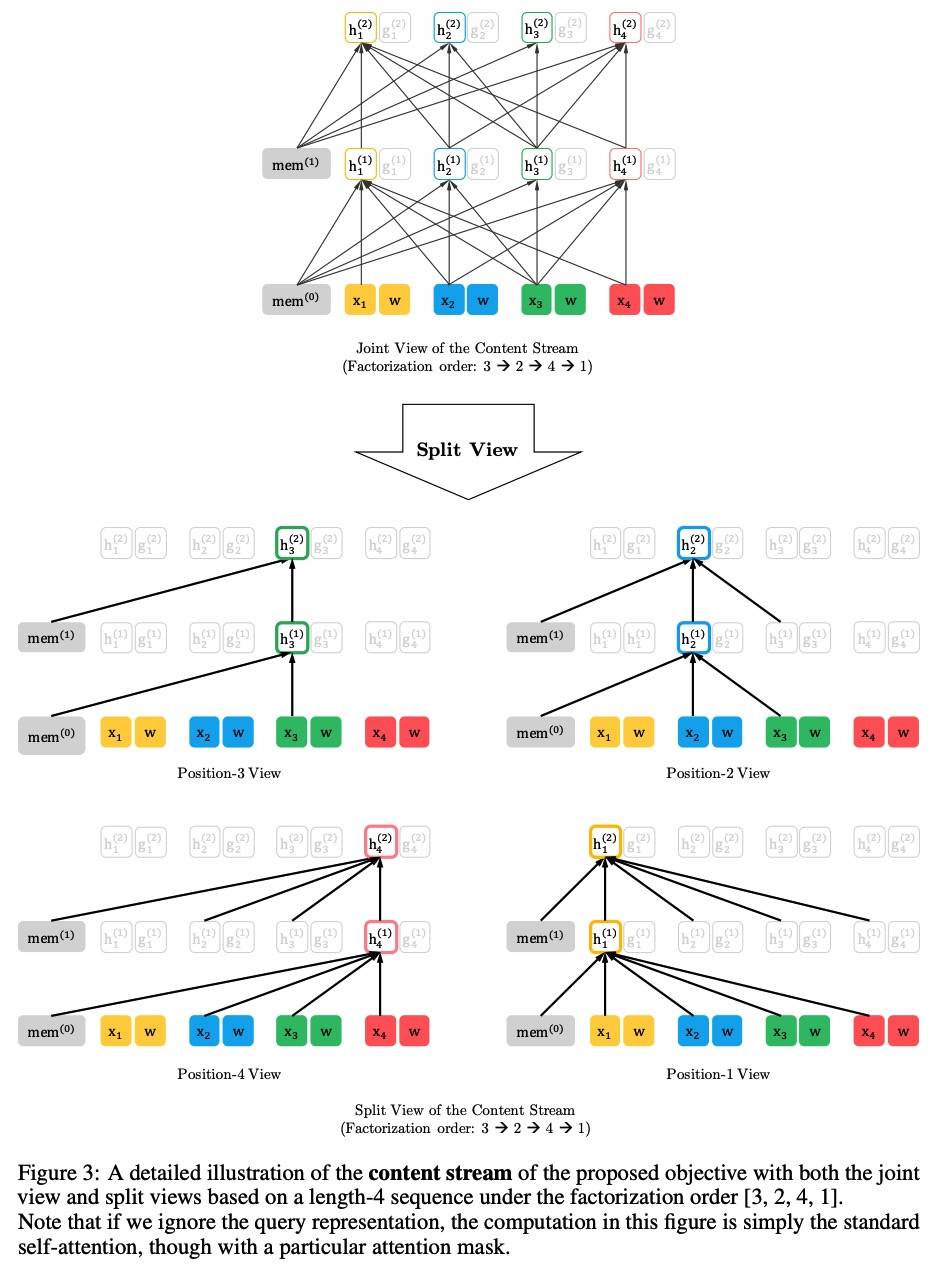
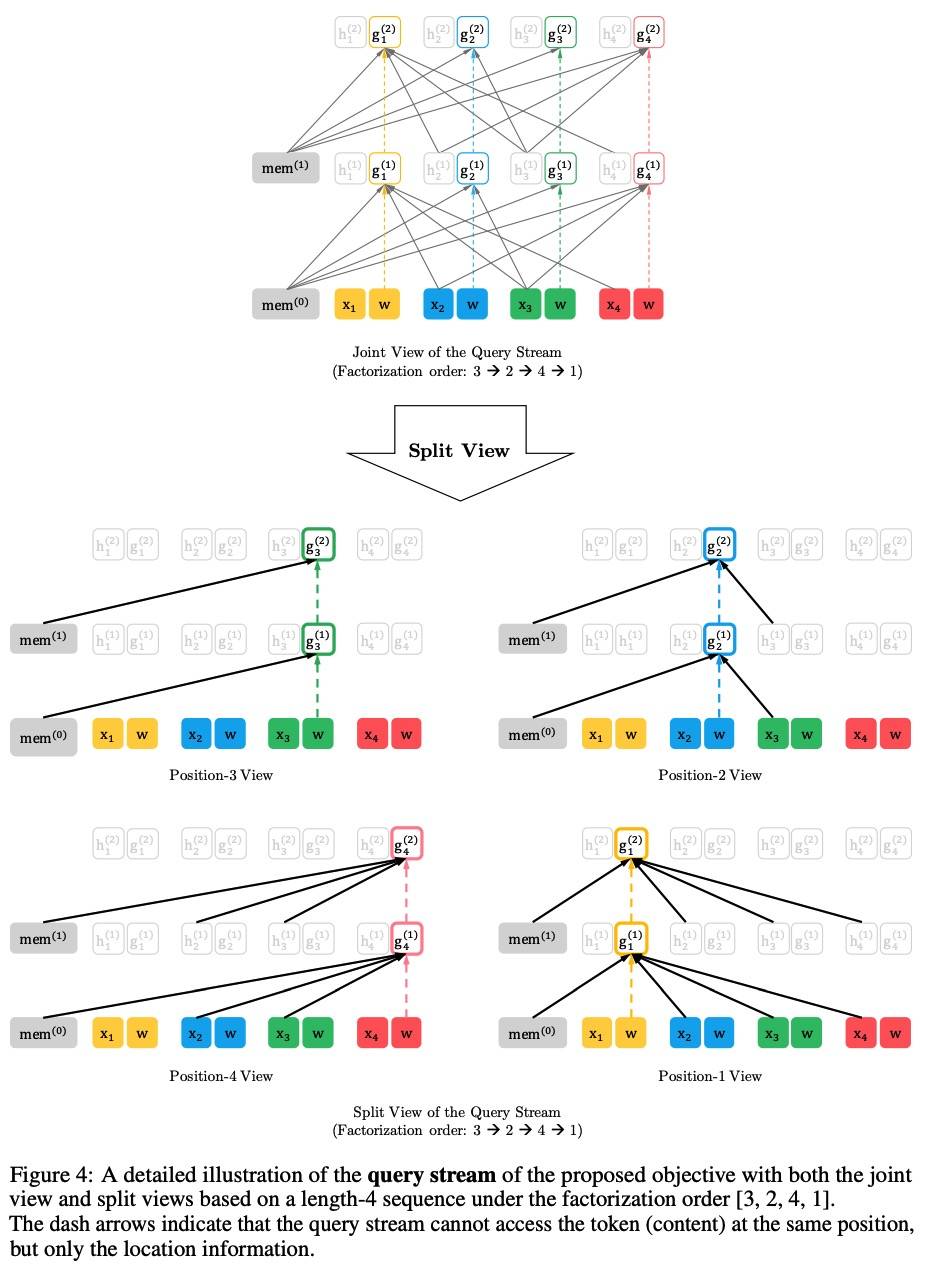
Modeling Multiple Segments
使用 Relative Segment Encodings,只关注两个位置是否来自同一个分割,这与相对编码的核心思想一致(只关注位置之间的关系),有两个好处:
- 改善了泛化
- 提供了两个以上分割 finetuning 的可能性
Discussion and Analysis
Comparison with BERT
都使用了 partial prediction,降低优化难度。例子:[New, York, is, a, city],假设 BERT 和 XLNet 都选择了 [New, York] 作为预测目标,最大化 log p(New York | is a city),假设 XLNet 采样的顺序是 [is, a, city, New, York]:
更加形式化的,给定序列:X = [x1, · · · , xT ],给定一组目标 tokens T 和非目标 tokens N=X\T,两个模型都需要最大化 log p(T | N):
T<x 表示 T 中 tokens 顺序先于 x 的排列。两个事实:
- 如果 U ⊆ N,(x, U) 能够被两个模型 cover
- 如果 U ⊆ N ∪ T<x 且 U ∩ T<x ≠ ∅,则只有 XLNet 能 cover
Comparison with Language Model
AR LM 顺序只能从前到后,XLNet 可以 cover 所有顺序,更正式的,考虑一个上下文-目标对 (x, U):
- 如果 U ∩ T<x ≠ ∅,AR 不能 cover 这种情况
- XLNet 可以 cover
Experiments
Pretraining and Implementation
2.78B, 1.09B, 4.75B, 4.30B, and 19.97B subword pieces for Wikipedia, BooksCorpus, Giga5, ClueWeb, and Common Crawl, 共 32.89B
Sequence 和 Memory 的长度分别为 512 和 384
500k steps,Adam optimizer, linear learning rate decay, batch size of 2048
bidirectional data input pipeline, partial prediction constant K as 6
span-based prediction when finetuning
RACE Dataset
从中国中学生英文考试中选出的约 100k 个问题的数据集,答案由人工专家给出。
SQuAD Dataset
包含两个任务的大规模阅读理解数据集,SQuAD1.1 的问题在原文中有答案,SQuAD2.0 包括了不可回答的问题。
Text Classification
benchmarks: IMDB, Yelp-2, Yelp-5, DBpedia, AG, Amazon-2, and Amazon-5
GLUE Dataset
包含 9 个自然语言理解的任务:MNLI, QNLI, QQP, RTE, SST-2, MRPC, CoLA, STS-B, WNLI
ClueWeb09-B Dataset
用来评估文档排序。
Ablation Study
Important Design:
- memory caching mechanism
- span-based prediction
- bidirectional input pipeline
Conclusions
XLNet 使用了 permutation 语言模型来联合 AR 和 AE 模型的优点,融合了 Transformer-XL 的思想,提出了 two-stream attention mechanism(核心),并在几乎所有任务中达到了 sota 的结果。