并不是所有的Next Token都有用,RHO-1选择那些最有用的Next Token,提升了小模型的继续训练效率。
背景
NTP?语料中的Token在训练中并不是同样重要,RHO-1并不是预测下一个Token,而是选择性地训练“有用”的Token。这需要一个参考模型对Token进行打分,然后选择那些更高损失的Token。
初衷:
- 数据质量很重要,但即便过滤依然可能有噪声Token,去掉这些Token有可能改变语义。
- 而且严格的过滤还可能同时去掉一些有用的Token。
- 另外,网络爬取的语料也和下游应用场景的理想分布不一致。比如各种有害Token,它们和有用的Token应用同样的损失不仅浪费资源,也限制LLM的智能潜力。
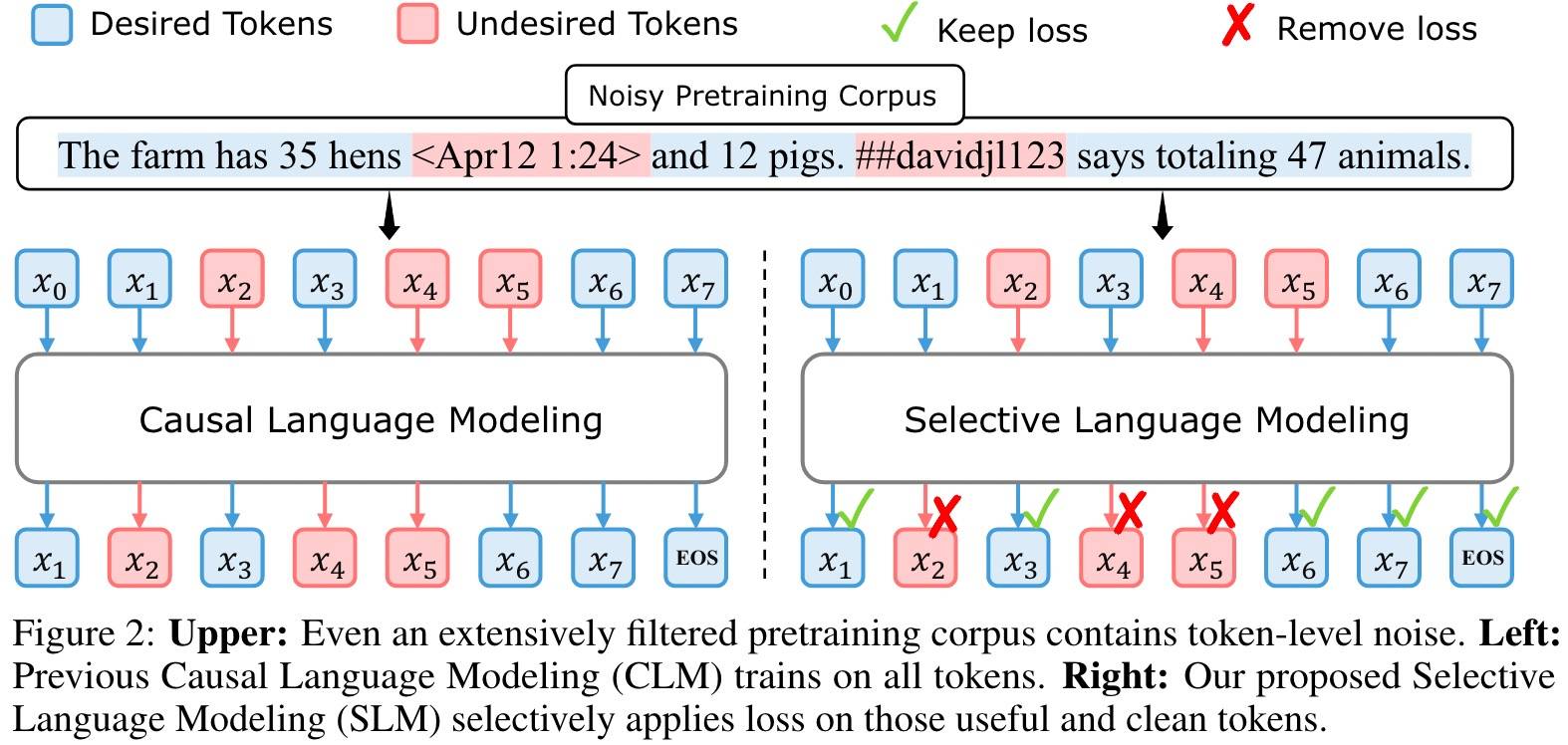
Token级别学习
结论:并不是所有Token都同样重要。显著的损失减少仅限于一组Token,许多Token是已经学习到的“简单Token”。而有些是“Hard Token”,具体表现是波动的损失且不收敛,这些Token可能导致无效的梯度更新。
做法:在15B的Token(OpenWebMath)上继续训练TinyLLaMA-1B,每1B的Token保存一次,然后验证这些间隔Token级别的损失。

**发现1:**如上图a所示,Token轨迹表现出四类,如下所示。
- H→H:11%,可能由于高度的不确定性。
- L→H:12%,……
- H→L:26%,显著的损失降低,是继续训练学到的。
- L→L:51%,损失没有变化,都很低,是此前已经学到了的(简单Token)。
**发现2:**如上图b和c所示,L→L和H→H中,一些Token损失表现出持续的波动,且不收敛。结果发现这些Token大部分都是噪音。如下图所示。

小结:在训练期间,与每个Token相关的损失不会像总体损失那样平稳下降;相反,不同的Token之间存在复杂的动态变化。如果在训练期间能够为模型选择适当的Token,就可能稳定模型的训练轨迹并提高效率。
SLM
受文档级别过滤用的参考模型启发,本文提出Token级别的数据选择。
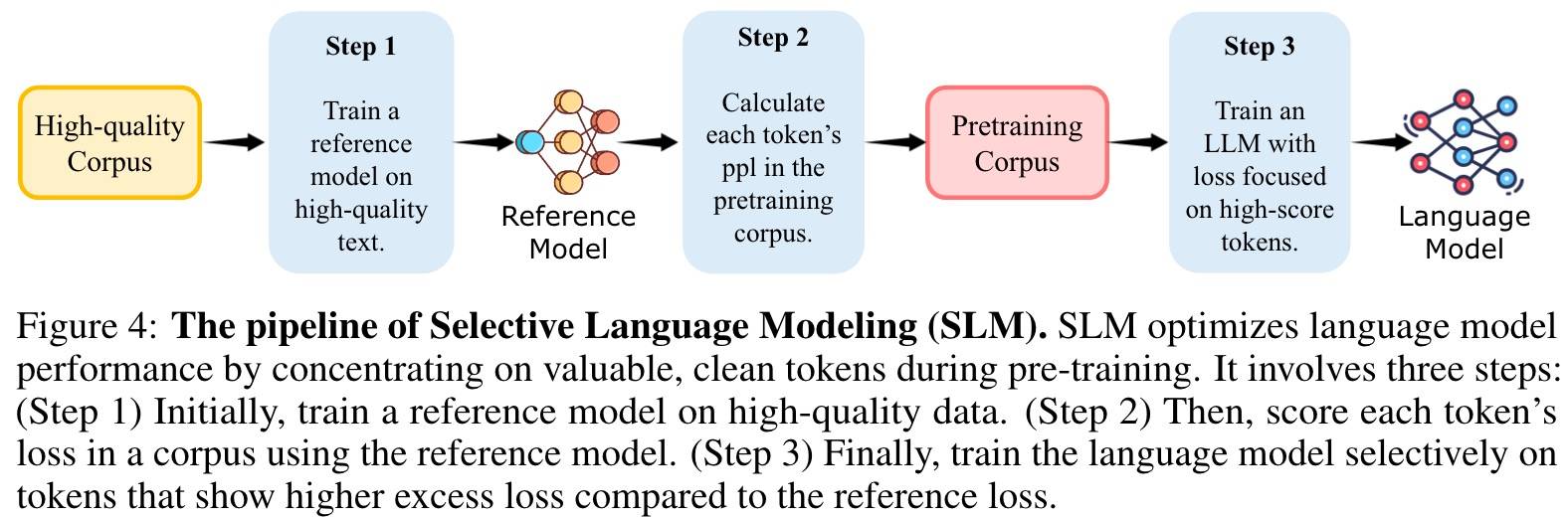
这里的直觉是,高超额损失的Token更易学习,更符合预期分布,且自然排除了无关或低质量的Token。
Reference Modeling
式(1)用来计算Token的分数。
Selective Pretraining
式(2)计算语言模型的损失。
式(3)表示Token xi的超额损失(excess loss)。
式(4)为最终的损失,这里的k%(Top k%)表示Token选择(基于超额损失)的比率。如果xi在top k%中,,否则,即不计算这些Token的损失。这确保了损失只应用于被认为对语言模型学习最有益的Token。
实验设置
RM:
- 语料
- 数学:0.5B(Token)数学相关高质量数据集
- 通用:1.9B(Token)高质量数据集
- 3Epoch
- LR:5e-5 (1B), 1e-5 (7B), cosine decay schedule
- MaxLen: 2048 (1B), 4096 (7B)
- RM和CTM(继续训练模型)从同样的base模型初始化
预训练
- 语料
- 数学:OpenWebMath,14B Token
- 通用:SlimPajama:StarCoderData:OpenWebMath = 6:3:1
- base
- 数学:TinyLLaMA-1.1B+LR8e-5和Mistral-7B+LR2e-5
- 通用:TinyLLaMA-1.1B+LR1e-4和Mistral-7B+LR2e-5
- BatchSize=1M Tokens
- Token选择比率:TinyLLaMA 60%,Mistral-7B 70%
实验结果
数学
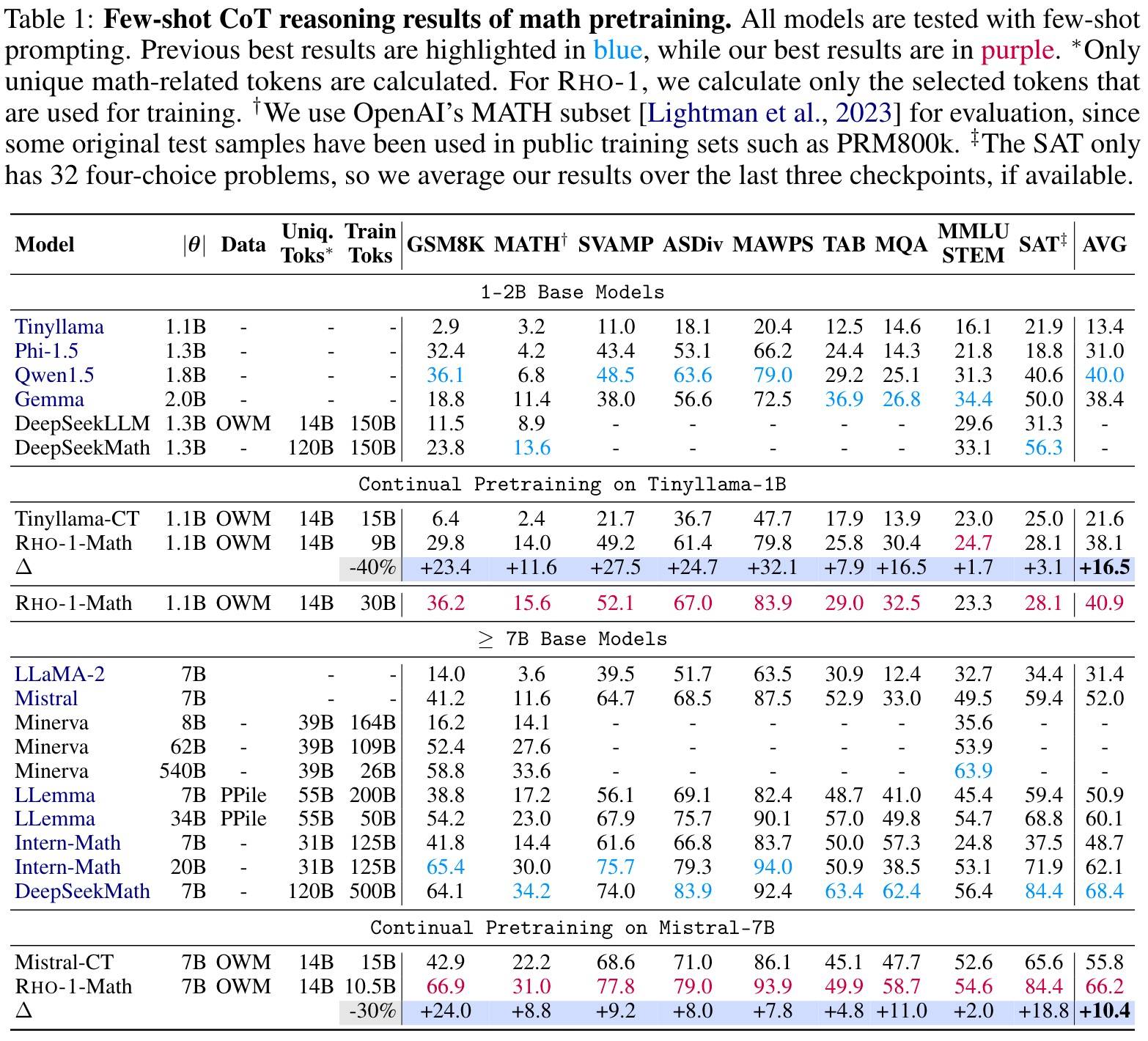
1B模型的提升远大于7B。
通用
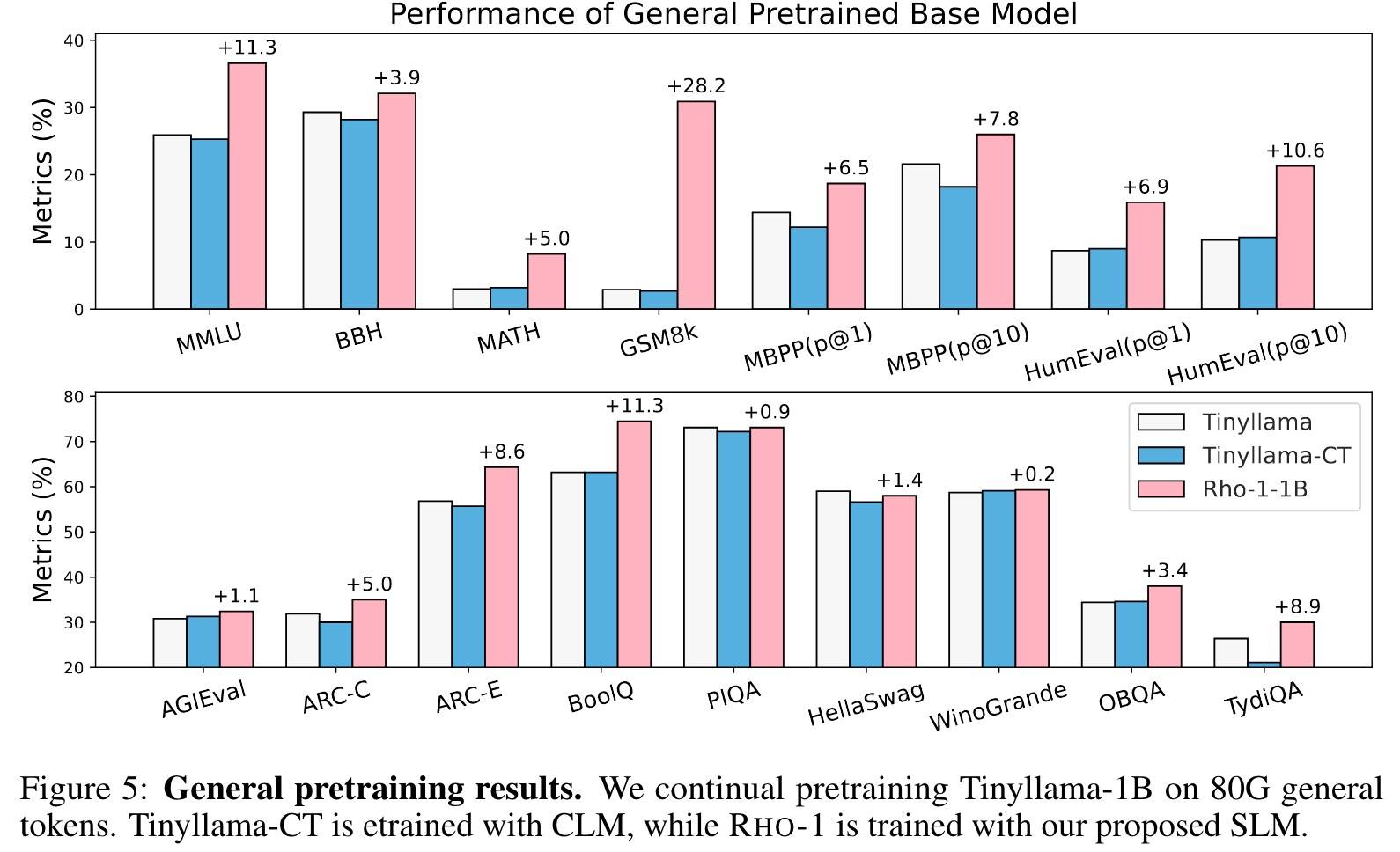
为啥没有横向的对比?也没有7B的结果。
分析
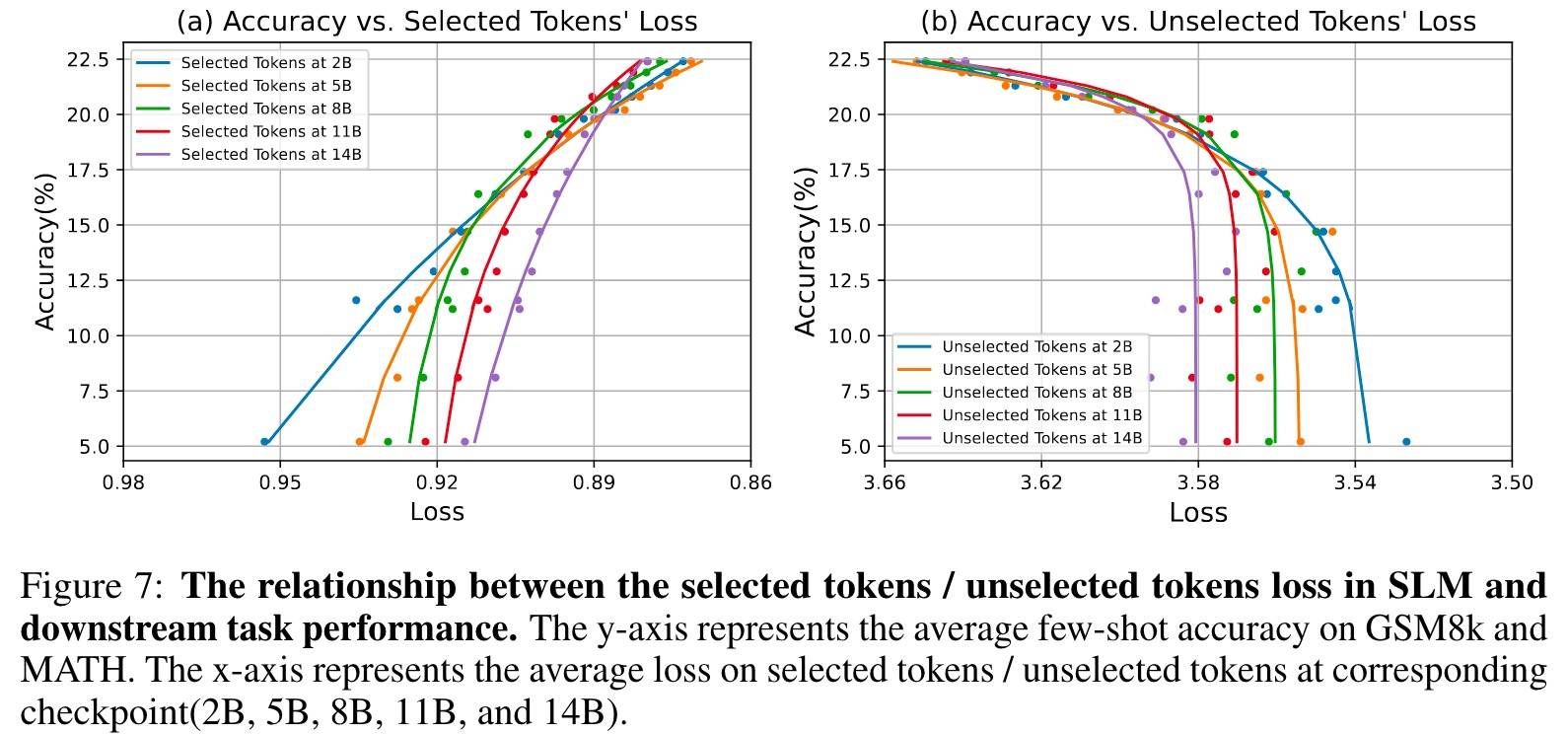
选择的Token的损失和下游性能表现更一致
这种表现呈现出二次幂关系
选择了哪些Token?

都是选择的数学相关的Token。
而且,后面ckpt选择的Token在训练后期具有更高的PPL,如Figure8所示,这表明模型可能首先优化了具有更大可学习空间的Token,从而提高了学习效率。
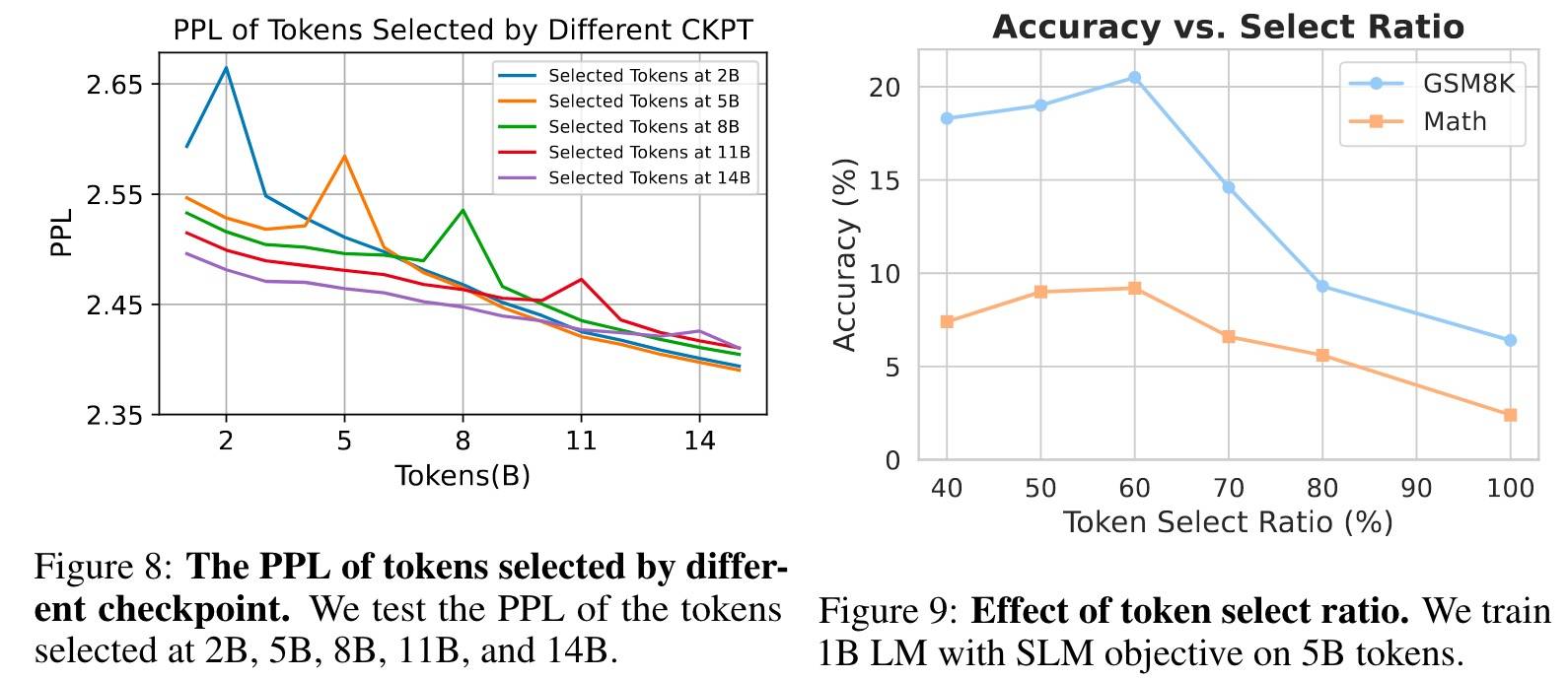
不同Token选择率的效果
如Figure9所示,60%时效果最佳。
Weak-to-Strong泛化

TinyLLaMA-1.1B为RM+LLaMA2-7B继续训练,依然可以受益。但是感觉收益明显不多。
考虑到前面的实验结果,看起来模型规模越大,这种Trick的收益越小。
讨论
泛化
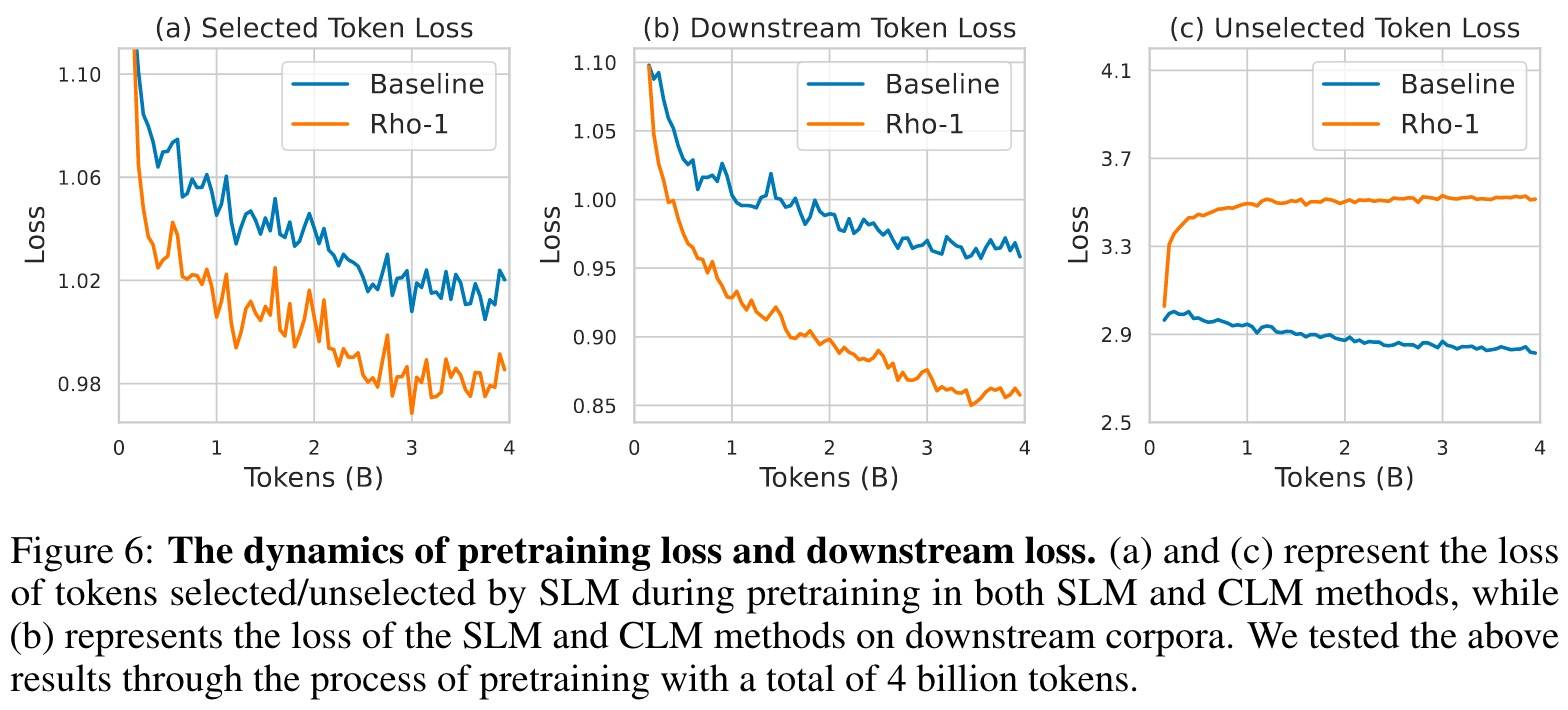
如Figure6所示,SLM会快速收敛到关注的领域(未选定Token的损失增加),这会不会导致过拟合?
稳定性
只实验了小模型(<=7B)和小数据集(<100B),小模型上消除不相关Token的损失能够受益。但在更大模型和语料上可能会自然而然地产生这种归纳偏差来压缩有用的数据。
是否有必要训练一个RM?
可以选择高质量数据训练的模型,也可以使用效果好的开源模型,甚至是API。
如何改进SLM?
包括:重新赋权Token而不是选择;使用参考模型作为奖励模型来引导使用强化学习进行预训练;使用多个参考模型减少过拟合;设计Token级别的学习和迭代策略等。
扩展SLM
SLM 可以扩展到监督微调,以解决许多SFT数据集中的噪声和分布不匹配问题。另一个潜在的应用是对齐,例如,通过训练一个参考模型来强调有用性、真实性和无害性,我们可以获得一个在预训练阶段原生对齐的基础模型。
总结
整体看下来是一个针对小模型、领域数据继续训练的高效方案。通过选择对下游任务“有用”的Token快速在给定数据集上收敛。
不过,很显然,随着模型规模的增加,边际收益在不断下降,甚至还可能有负面作用(过拟合)。果然是一力降十会啊,再高超的技巧在绝对的实力面前都显得那么苍白。