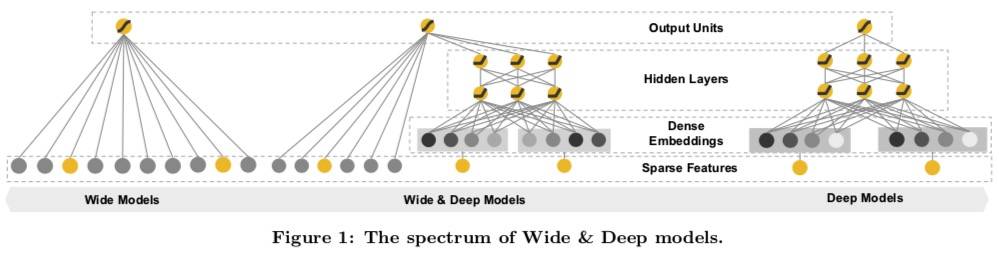
推荐系统可以看作是一个搜索排序系统,其中 input 是一组用户和上下文信息,output 是排好序的商品列表。推荐系统的一个挑战就是同时达到 memorization(记忆化)和 generalization(泛化)。
memorization:
大致可定义为学习特征或商品的频繁共现关系并探索相关性
与用户已经执行操作的商品直接相关
可以通过使用稀疏特征上的交叉乘积变换(cross-product transformation)有效地实现,如 AND(installed_app=netfix, impression_app=pandora)
generalization:
基于相关性的传递性探索之前很少出现或没出现过的新特征组合
倾向于提高推荐结果的多样性
可以通过使用不太精细的特征增加泛化,如 AND(installed_category=video, impression_category=music),一般需要人工进行特征处理
Cross-product transformation 的一个局限是不能泛化到训练数据中没有的特征对,而基于 Embedding 的模型(如 FM,DNN)可以通过学习每个 query 和 item 特征的低维稠密 Embedding 向量来泛化到之前没见过的 query-item (特征)对,并且不需要人工处理。但是在数据稀疏时难以有效学习,此时大多数 query-item 对之前应该没有交互,但稠密的 Embedding 却得到非零的预测值,这显然是过度泛化,导致推荐内容不相关。另一方面来看,带有特征交叉乘积变换的线性模型可以用更少的参数来记住这些 “例外规则”(并不需要 Embedding)。
模型
本文提出的模型通过联合训练一个线性模型组件和一个神经网络组件,实现在一个模型下,既保证了记忆性又兼顾了泛化性。
Wide 组件
交叉乘积变换定义为:
ϕ k ( x ) = ∏ i = 1 d x i c k i c k i ∈ { 0 , 1 } \phi_k(\mathrm{x}) = \prod_{i=1}^d x_i^{c_{ki}} \quad c_{ki} \in \{0,1\}
ϕ k ( x ) = i = 1 ∏ d x i c k i c k i ∈ { 0 , 1 }
c_ki 为 1 时表示第 i 个特征是第 k 个变换 φk 的一部分。
该变换可以捕捉到二元特征的交互并且为线性模型增加了非线性。
Deep 组件
一个前馈网络,每个稀疏、高维的类别特征都会首先被转换为一个低维的稠密实向量(Embedding),维度一般是 10-100。
联合训练
P ( Y = 1 ∣ X ) = σ ( w w i d e T [ x , ϕ ( x ) ] + w d e e p T a l f + b ) P(Y=1|X) = \sigma(\mathrm{w}^T_{wide} [\mathrm{x}, \phi(\mathrm{x})] + \mathrm{w}^T_{deep} a^{l_f} + b)
P ( Y = 1∣ X ) = σ ( w w i d e T [ x , ϕ ( x )] + w d ee p T a l f + b )
φ(x) 表示特征 x 的交叉乘积转换,Wdeep 是最后一层激活的参数。
训练使用 mini-batch 随机梯度下降,Wide 部分采用 Follow-the-regularized-leader(FTRL)算法 + L1 正则,Deep 部分采用 AdaGrad。
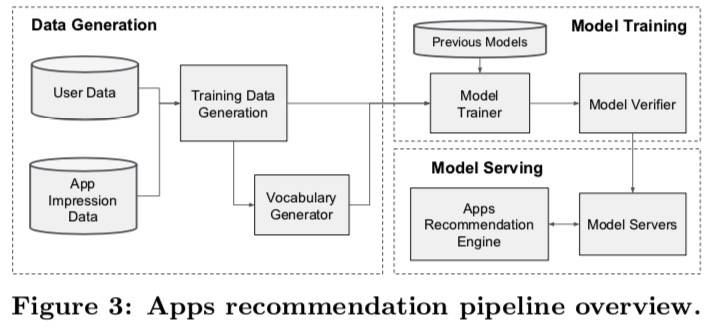
应用
共分为三步:数据生成、模型训练、模型部署。
数据生成
类别特征使用一个阈值筛选,只使用出现次数超过一定值的特征。
连续特征将使用分割成 nq 分位的累积分布函数归一化到 0-1,归一化值为 (i-1)/(nq-1)。具体来说,就是先将数据按 nq 个分位分组,然后使用每个分位的累积百分比作为分组的 Value,进而用来表示组内数据的 Value。这其实是根据一定范围内的频率来表征的。
1 2 3 4 5 6 import pandas as pdpd.qcut([1 ,1 ,1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,8 ,8 ], 4 )
模型训练
实验结果显示线上收益比只使用 Deep Model 提高 1%。
总的来说,记忆性和泛化性对于推荐系统都很重要。 宽线性模型可以使用特征交叉乘积变换有效地记住稀疏特征交互,而深度神经网络可以通过低维嵌入将其推广到以前没见过的特征交互。
代码
Tensorflow 已经集成了 API ,使用非常简单:
1 2 3 4 5 6 7 linear_model = LinearModel() dnn_model = keras.Sequential([keras.layers.Dense(units=64 ), keras.layers.Dense(units=1 )]) combined_model = WideDeepModel(linear_model, dnn_model) combined_model.compile (optimizer=['sgd' , 'adam' ], loss='mse' , metrics=['mse' ]) combined_model.fit([linear_inputs, dnn_inputs], y, epochs)
源代码的主体部分也不复杂:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class WideDeepModel (keras_training.Model): def __init__ (self, linear_model, dnn_model, activation=None , **kwargs ): super (WideDeepModel, self ).__init__(**kwargs) base_layer._keras_model_gauge.get_cell('WideDeep' ).set (True ) self .linear_model = linear_model self .dnn_model = dnn_model self .activation = activations.get(activation) def call (self, inputs, training=None ): if not isinstance (inputs, (tuple , list )) or len (inputs) != 2 : linear_inputs = dnn_inputs = inputs else : linear_inputs, dnn_inputs = inputs linear_output = self .linear_model(linear_inputs) if self .dnn_model._expects_training_arg: if training is None : training = K.learning_phase() dnn_output = self .dnn_model(dnn_inputs, training=training) else : dnn_output = self .dnn_model(dnn_inputs) output = nest.map_structure(lambda x, y: (x + y), linear_output, dnn_output) if self .activation: return nest.map_structure(self .activation, output) return output
可以看出,其实就是将 Wide 和 Deep 的结果合并然后输出。另外,Tensorflow 还有一个专门的推荐系统库:tensorflow/recommenders: TensorFlow Recommenders is a library for building recommender system models using TensorFlow.
实例
我们 UCI Machine Learning Repository: Census Income Data Set 数据集为例,数据集各列如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import tensorflow as tffrom tensorflow.keras.layers.experimental import preprocessingimport pandas as pdfrom collections import CounterCOLUMNS = ["age" , "workclass" , "fnlwgt" , "education" , "education_num" , "marital_status" , "occupation" , "relationship" , "race" , "gender" , "capital_gain" , "capital_loss" , "hours_per_week" , "native_country" , "income_bracket" ] LABEL_COLUMN = 'label' CATEGORICAL_COLUMNS = ["workclass" , "education" , "marital_status" , "occupation" , "relationship" , "race" , "gender" , "native_country" ] CONTINUOUS_COLUMNS = ["education_num" , "capital_gain" , "capital_loss" , "hours_per_week" ] CATEGORICAL_NUM_COLUMNS = ["age" , "fnlwgt" ] train_file = "/path/to/adult.data" test_file = "/path/to/adult.test" df_train = pd.read_csv(train_file, names=COLUMNS, skipinitialspace=True ) df_test = pd.read_csv(test_file, names=COLUMNS, skipinitialspace=True , skiprows=1 ) df_train[LABEL_COLUMN] = (df_train['income_bracket' ].apply( lambda x: '>50K' in x)).astype(int ) df_test[LABEL_COLUMN] = (df_test['income_bracket' ].apply( lambda x: '>50K' in x)).astype(int )
然后简单观测一下特征基本情况:
1 2 df_train[CATEGORICAL_COLUMNS].describe() df_train[CONTINUOUS_COLUMNS].nunique()
接下来需要按论文中提到的数据处理方式来处理连续数值:
1 2 3 4 5 6 7 8 9 10 11 def get_qage (x, dct ): for item in dct: if item.left < x <= item.right: return dct.get(item) for col in CATEGORICAL_NUM_COLUMNS: nq = 10 df_train["Q" +col] = pd.qcut(df_train[col], nq) dct = dict (zip (df_train["Q" +col].values.categories, [i/(nq-1 ) for i in range (nq)])) df_train["Q" +col] = df_train["Q" +col].apply(lambda x: dct[x]) df_test["Q" +col] = df_test[col].apply(lambda x: get_qage(x, dct))
接下来就可以得到需要的训练数据了:
1 2 3 CONTINUOUS_COLUMNS = CONTINUOUS_COLUMNS + ["Q" + col for col in CATEGORICAL_NUM_COLUMNS] df_train = df_train[CONTINUOUS_COLUMNS + CATEGORICAL_COLUMNS + [LABEL_COLUMN]] df_test = df_test[CONTINUOUS_COLUMNS + CATEGORICAL_COLUMNS + [LABEL_COLUMN]]
然后是一些归一化、类别编码的函数,代码来自官方文档:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 def df_to_dataset (dataframe, shuffle=True , batch_size=32 ): dataframe = dataframe.copy() labels = dataframe.pop(LABEL_COLUMN) ds = tf.data.Dataset.from_tensor_slices((dict (dataframe), labels)) if shuffle: ds = ds.shuffle(buffer_size=len (dataframe)) ds = ds.batch(batch_size) ds = ds.prefetch(batch_size) return ds def get_normalization_layer (name, dataset ): normalizer = preprocessing.Normalization() feature_ds = dataset.map (lambda x, y: x[name]) normalizer.adapt(feature_ds) return normalizer def get_category_encoding_layer (name, dataset, dtype, max_tokens=None ): if dtype == 'string' : index = preprocessing.StringLookup(max_tokens=max_tokens) else : index = preprocessing.IntegerLookup(max_values=max_tokens) feature_ds = dataset.map (lambda x, y: x[name]) index.adapt(feature_ds) encoder = preprocessing.CategoryEncoding(max_tokens=index.vocab_size()) feature_ds = feature_ds.map (index) encoder.adapt(feature_ds) return lambda feature: encoder(index(feature))
这里 StringLookup 和 IntegerLookup 分别针对字符串类型和数值类型。
然后是对特征进行组装:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 MIN_NUM = 5 batch_size = 256 train_ds = df_to_dataset(df_train, batch_size=batch_size) test_ds = df_to_dataset(df_test, shuffle=False , batch_size=batch_size) all_inputs = [] encoded_features = [] for header in CONTINUOUS_COLUMNS: numeric_col = tf.keras.Input(shape=(1 ,), name=header) normalization_layer = get_normalization_layer(header, train_ds) encoded_numeric_col = normalization_layer(numeric_col) all_inputs.append(numeric_col) encoded_features.append(encoded_numeric_col) for header in CATEGORICAL_COLUMNS: max_tokens = len ([i for i in Counter(df_train[header]).values() if i > MIN_NUM]) + 2 categorical_col = tf.keras.Input(shape=(1 ,), name=header, dtype='string' ) encoding_layer = get_category_encoding_layer(header, train_ds, dtype='string' , max_tokens=max_tokens) encoded_categorical_col = encoding_layer(categorical_col) all_inputs.append(categorical_col) encoded_features.append(encoded_categorical_col)
接下来是建模编译,我们这里用的是 Functional API:
1 2 3 4 5 6 7 8 9 10 all_features = tf.keras.layers.concatenate(encoded_features) x = tf.keras.layers.Dense(32 , activation="relu" )(all_features) x = tf.keras.layers.Dropout(0.5 )(x) output = tf.keras.layers.Dense(1 )(x) model = tf.keras.Model(all_inputs, output) model.compile (optimizer='adam' , loss=tf.keras.losses.BinaryCrossentropy(from_logits=True ), metrics=["accuracy" ]) tf.keras.utils.plot_model(model, show_shapes=True , rankdir="LR" )
最后训练并测试:
1 2 3 model.fit(train_ds, epochs=10 ) loss, accuracy = model.evaluate(test_ds) print ("Accuracy" , accuracy)
参考资料