2014 年,Facebook 在论文 practical-lessons-from-predicting-clicks-on-ads-at-facebook 中提出了一个将决策树算法和逻辑回归整合起来的模型,大致做法就是将输入的实数特征通过决策树转换为一个二进制的向量,该模型比其他方法在整体性能上提高超过 3 个百分点。
背景
论文主要是针对广告推荐的,毕竟这个领域直接关系着收入,绝对算是核心业务。论文在开始的时候有一些基本的配置,简述如下:
与搜索广告与 query 相关的推荐不同的是,Facebook 的广告与 query 无关,而是与指定受众特征和兴趣定位有关。 因此,可以显示的广告量要大于 query 的广告量。
只关注最后一步点击预测,即模型只为最终的候选广告集生成预测。
除了模型的选择使用提升树+逻辑回归外,关于特征,文章认为用户或广告的历史信息明显比其他特征重要。有了正确的特征和模型,其他因素其实起的作用非常微小。新鲜数据、学习率模式和数据采样能够略微提升模型效果。
实验配置
使用 2013 年四季度某个星期的离线训练数据,为了在不同条件下保持相同的训练和测试数据,离线训练数据与在线观察的数据相似。
评估方法采用 Normalized Entropy(NE)和 calibration。NE 是 background CTR 的熵归一化的预测 Log 损失。background CTR 是训练数据集的平均 CTR。
N E = − 1 N ∑ i = 1 n ( 1 + y i 2 log ( p i ) + 1 − y i 2 log ( 1 − p i ) ) − ( p ∗ log ( p ) + ( 1 − p ) ∗ log ( 1 − p ) ) N E=\frac{-\frac{1}{N} \sum_{i=1}^{n}\left(\frac{1+y_{i}}{2} \log \left(p_{i}\right)+\frac{1-y_{i}}{2} \log \left(1-p_{i}\right)\right)}{-(p * \log (p)+(1-p) * \log (1-p))}
N E = − ( p ∗ log ( p ) + ( 1 − p ) ∗ log ( 1 − p )) − N 1 ∑ i = 1 n ( 2 1 + y i log ( p i ) + 2 1 − y i log ( 1 − p i ) )
其中,pi 表示点击的概率,N 为训练样本个数,p 就是平均 CTR。NE 的本质是计算相对信息增益 RIG,RIG = 1 - NE,NE 值越小表示模型越好。
Calibration 是平均估计 CTR 与观测 CTR 的比率,换句话说,就是期望点击的数量和实际观测点击数量之比。越接近 1 说明模型效果越好。
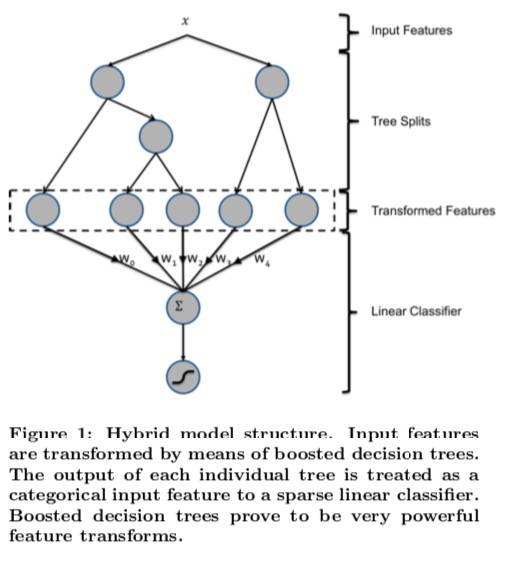
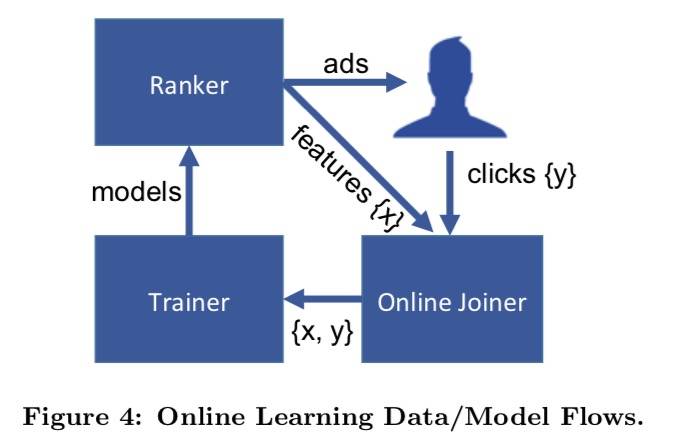
模型结构
结构如图所示:
决策树被用作输入特征的转换器,经过特征转换后得到向量:
x = ( e i 1 , . . . , e i n ) \mathrm{x} = (e_{i1}, ..., e_{in})
x = ( e i 1 , ... , e in )
其中 ei 表示第 i 个单位向量,ij 表示第 j 个输入的类别特征。给定标记数据 (x,y),线性组合可以表示为:
s ( y , x , w ) = y ⋅ w T x = y ∑ j = 1 n w j , i j s(y, \boldsymbol{x}, \boldsymbol{w})=y \cdot \boldsymbol{w}^{\mathrm{T}} \boldsymbol{x}=y \sum_{j=1}^{n} w_{j, i_{j}}
s ( y , x , w ) = y ⋅ w T x = y j = 1 ∑ n w j , i j
在概率回归的贝叶斯在线学习(BOPR)模式下,似然和先验如下:
p ( y ∣ x , w ) = Φ ( s ( y , x , w ) β ) p ( w ) = ∏ k = 1 N N ( w k ; μ k , σ k 2 ) p(y \mid \boldsymbol{x}, \boldsymbol{w})=\Phi\left(\frac{s(y, \boldsymbol{x}, \boldsymbol{w})}{\beta}\right) \\
p(w) = \prod_{k=1}^N N(w_k; \mu_k, \sigma_k^2)
p ( y ∣ x , w ) = Φ ( β s ( y , x , w ) ) p ( w ) = k = 1 ∏ N N ( w k ; μ k , σ k 2 )
其中 Φ(t) 是标准正态分布的累积密度函数,而 N(t) 是标准正态分布的密度函数。 在线训练是通过期望传播和矩匹配实现的。
基于 SGD 的 LR 似然函数为:
p ( y ∣ x , w ) = s i g m o i d ( s ( y , x , w ) ) p(y|x,w) = \mathrm{sigmoid} (s(y,x,w))
p ( y ∣ x , w ) = sigmoid ( s ( y , x , w ))
关于梯度更新可以查看原始论文(以及 BOPR 的参考文献)。
决策树特征转换
一般情况下有两种简单方法可以对输入特征进行转换:
对连续特征,学习非线性转换的一个简单的 trick 就是分桶,每个桶作为类型特征。
构建 tuple 输入特征。对类型特征,蛮力法可以直接用笛卡尔积,即创建新的分类特征,该新分类特征将原始特征的所有可能值作为值,对没用的特征剪枝处理。对连续特征,可以使用如 k-d 树之类的方法联合分桶。
但其实提升树正是做了类似的事情,每棵树可以看成一个类别特征,以实例最终落入的叶子索引作为值,可以使用 1-of-K 编码这一类型特征。比如结构图中所示的,特征有两棵子树,分别有 3 个和 2 个叶子,如果实例以第一个子树的叶子 2 和第二个子树的叶子 1 结尾,那么 LR 的输入可以用二进制向量 [0,1,0,1,0] 表示。
基于提升树的转换可以理解为一种将实值向量转换为紧凑型二进制值向量的有监督特征编码。从根节点到叶节点的路径表示某些特征的规则 。
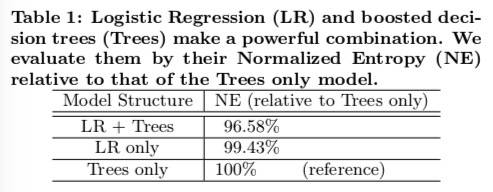
实验结果如下:
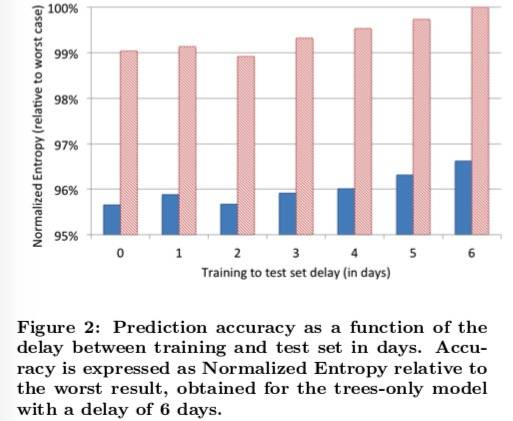
数据新鲜度
实验结果如下:
结果表明,按天再训练模型是有效果的。
在线分类器
为了最大化新数据,其中一个选择是在线训练线性分类器(提升树每天或没两天训练一次)。这部分主要评估几种不同的设置学习率的方法。
Per-coordinate learning rate:对 t 步迭代,特征 i 的学习率设置为
η t , i = α β + ∑ j = 1 t ∇ j , i 2 \eta_{t, i}=\frac{\alpha}{\beta+\sqrt{\sum_{j=1}^{t} \nabla_{j, i}^{2}}}
η t , i = β + ∑ j = 1 t ∇ j , i 2 α
Per-weight square root learning rate
η t , i = α n t , i \eta_{t,i} = \frac{\alpha}{\sqrt{n_{t,i}}}
η t , i = n t , i α
其中,nti 为到 t 步迭代所有具有训练特征 i 的训练数据数。
Per-weight learning rate
η t , i = α n t , i \eta_{t,i} = \frac{\alpha}{n_{t,i}}
η t , i = n t , i α
Global learning rate
η t , i = α t \eta_{t,i} = \frac{\alpha}{\sqrt{t}}
η t , i = t α
Constant learning rate
η t , i = α \eta_{t,i} = \alpha
η t , i = α
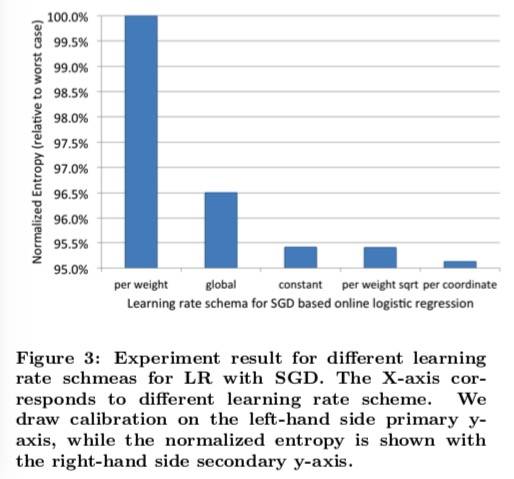
最终实验结果如下:
其中,Per-coordinate 取得最好的预测精准度。而且使用该学习率策略 BOPR 和 LR-SGD 表现非常接近。
LR 相比 BOPR 的一个优势是模型大小只有一半,因为 LR 只有一个与稀疏特征值相关的权重,而不是一个均值和方差。模型小意味着容易缓存且能更快查找。另外,在预测时,LR 只需要一个向量内积(权重向量和特征向量)就可以了,BOPR 却需要两个(方差、均值与特征向量)。
BOPR 相比 LR 的一个优势是作为贝叶斯公式,它可以提供有关点击概率的完整分布预测。
实时数据
由于 Label 只有 “点击” 而没有一个 “不点击”,所以,一般认为如果用户在看到广告后固定的一段时间内没有点击就是负样本。这个等待时间窗口需要仔细调整,太长会延迟实时训练数据,而且增加在等待点击信号时缓冲区(标记数据)的内存分配;太短会导致有些点击丢失,因为相关的标记数据可能还没来得及点就被标记成了 “不点击”。这是点击覆盖和新数据之间的一个权衡。另外一个重要的考虑是需要建立保护机制,以防止可能破坏在线学习系统的异常情况。此时,需要异常检测机制。实时系统结构如图所示:
内存和延迟
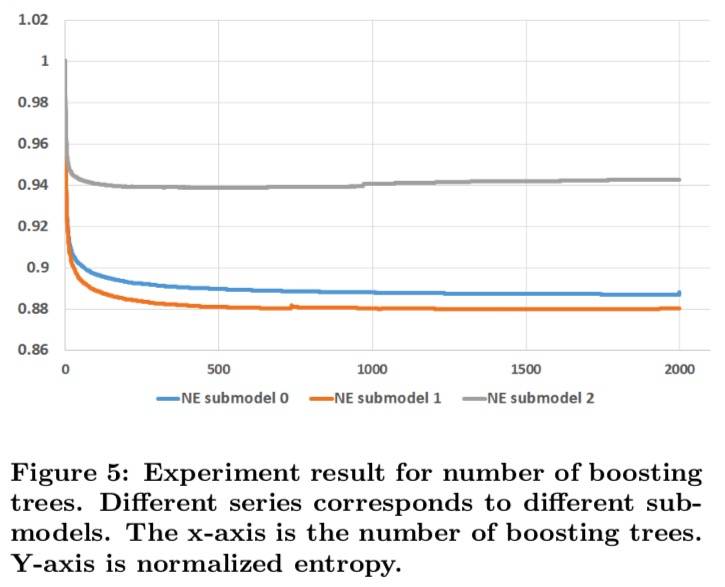
提升树的数量
树的数量越多,预测需要的时间越久,具体实验结果如下(每棵树的叶子数限制为不超过 12):
结果显示,几乎所有的性能都来自前 500 棵树。
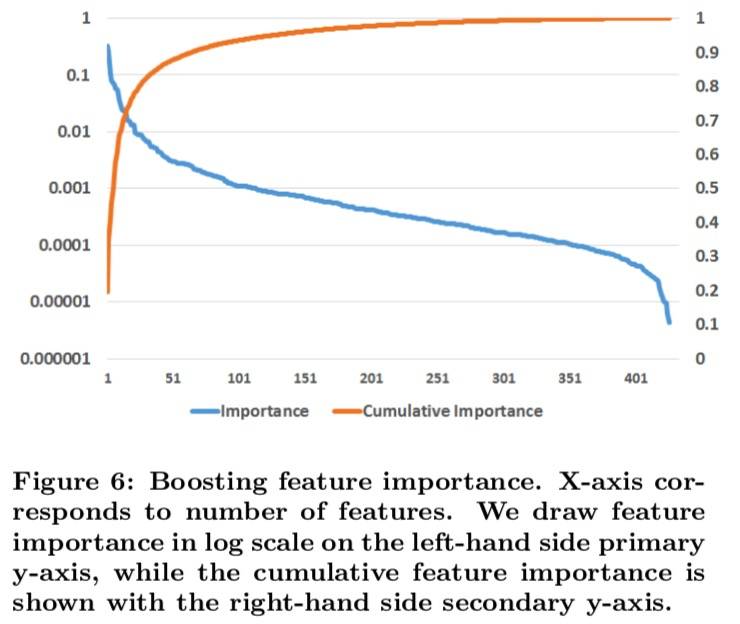
Boosting 特征重要性
在每个树节点构造中,通过选择并拆分最佳特征以最大程度地减少平方误差。 由于特征可以在多棵树中使用,因此每个特征的(Boosting 特征重要性)是通过将所有树上特定特征的总(平方误差)减少量相加来确定的。实验结果如下图所示:
结果显示,top10 的特征几乎占了一半的重要性。
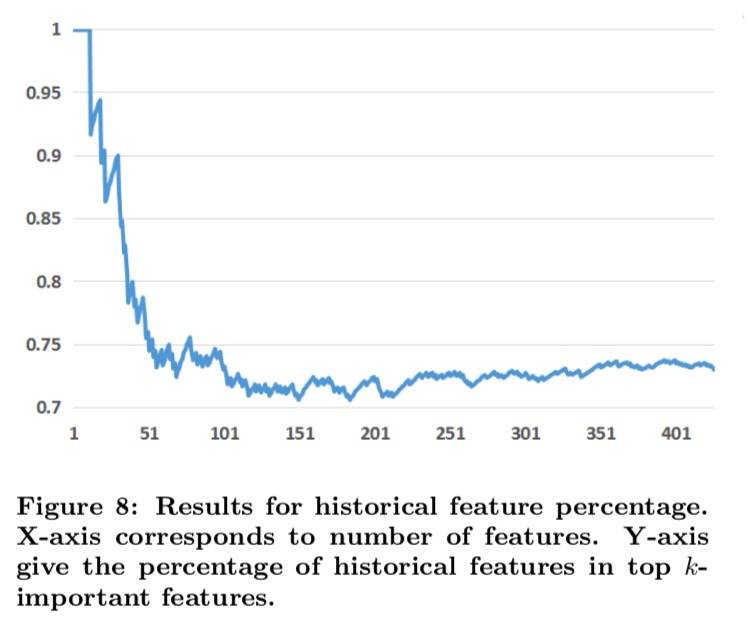
历史特征
Boosting 模型中的特征可以分为两大类:上下文特征和历史特征。上下文特征依赖关于显示广告上下文的当前信息,比如用户使用的设备或者当前页面;历史特征取决于广告或用户之前的互动情况,例如,上周广告的点击率或用户的平均点击率。实验结果如下图所示:
结果显示,top10 的按重要性排序的特征全部是历史信息。top20 里也只有 2 个上下文特征。实验表明,只有上下文特征相比只有历史特征,整体性能会下降 4.5 个百分点。不过上下文特征在解决冷启动问题时非常重要。另外一个实验表明,具有上下文特征的模型比历史特征更依赖于数据的新鲜度,这与我们的直觉是一致的,因为历史特征描述了长期累积的用户行为,这比上下文特征要稳定得多。
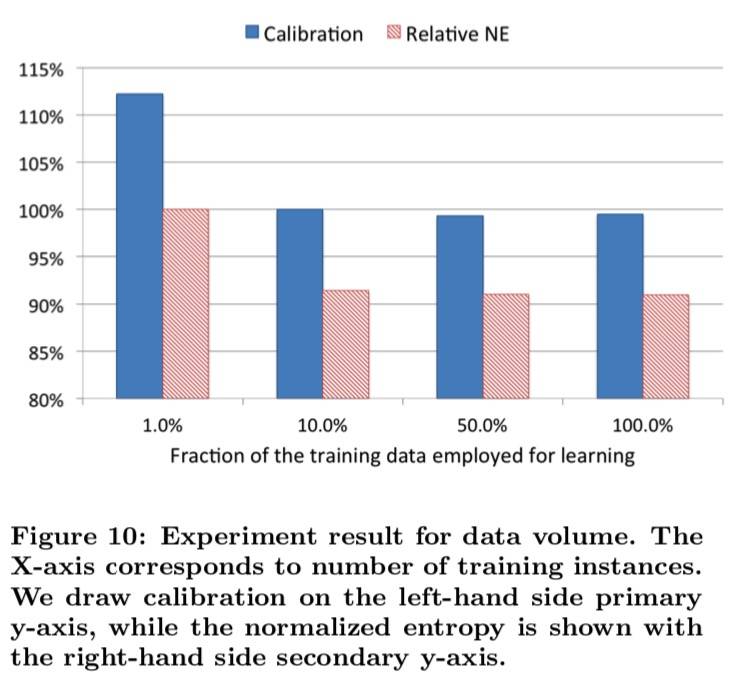
大规模数据
因为数据规模太大,所以需要减少数据量,一般采用下采样,这里介绍了两种采样方式:uniform subsampling 和 negative down sampling。
Uniform subsampling 实验结果如下图所示:
结果显示:
更多的数据带来更好的表现
10% 的数据比所有数据性能(NE)只减少了 1%
Negative down sampling 主要解决类别不均衡问题,实验结果显示,当采样率为 0.025 时达到最好性能。
这里有个需要注意的是,如果模型在 negative downsampling 的数据集上训练的话,同时也在下采样空间对预测进行了校准,所以对模型进行再校准:
q = p p + ( 1 − p ) / w q = \frac{p}{p+(1-p)/w}
q = p + ( 1 − p ) / w p
其中 p 是在下采样空间的预测情况,w 是采样率。
这里不太理解。
小结
实践心得:
新数据:值得每天训练。
用提升树将实值输入特征转换后显著提升了线性分类器的预测准确度。
LR + per-coordinate learning rate 表现最好。
大规模机器学习中保持内存和延迟的 Trick:
树的数量可以小一点。
特征重要性可以用来筛选特征。
历史数据比上下文特征重要的多。
代码
关于 LR 和 GBDT 的原理可以参考机器学习相关知识,不再赘述。这里直接看实践部分,GBDT 一般采用 XGBoost 或 LightGBM。数据集依然以 UCI Machine Learning Repository: Census Income Data Set 为例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import log_lossimport lightgbm as lgbCOLUMNS = ["age" , "workclass" , "fnlwgt" , "education" , "education_num" , "marital_status" , "occupation" , "relationship" , "race" , "gender" , "capital_gain" , "capital_loss" , "hours_per_week" , "native_country" , "income_bracket" ] LABEL_COLUMN = 'label' CATEGORICAL_COLUMNS = ["workclass" , "education" , "marital_status" , "occupation" , "relationship" , "race" , "gender" , "native_country" ] CONTINUOUS_COLUMNS = ["age" , "fnlwgt" , "education_num" , "capital_gain" , "capital_loss" , "hours_per_week" ] train_file = "/Users/HaoShaochun/Downloads/adult.data" test_file = "/Users/HaoShaochun/Downloads/adult.test" df_train = pd.read_csv(train_file, names=COLUMNS, skipinitialspace=True ) df_test = pd.read_csv(test_file, names=COLUMNS, skipinitialspace=True , skiprows=1 ) df_train[LABEL_COLUMN] = (df_train['income_bracket' ].apply(lambda x: '>50K' in x)).astype(int ) df_test[LABEL_COLUMN] = (df_test['income_bracket' ].apply(lambda x: '>50K' in x)).astype(int ) for col in CATEGORICAL_COLUMNS: dct = dict (zip (set (df_train[col].values.tolist()), range (df_train[col].nunique()))) df_train[col] = df_train[col].apply(lambda x: dct[x]) df_test[col] = df_test[col].apply(lambda x: dct[x]) X = df_train[CATEGORICAL_COLUMNS + CONTINUOUS_COLUMNS] X_test = df_test[CATEGORICAL_COLUMNS + CONTINUOUS_COLUMNS] y = df_train[LABEL_COLUMN] y_test = df_test[LABEL_COLUMN] X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.33 , random_state=42 ) X_train = X_train.reset_index(drop=True ) y_train = y_train.reset_index(drop=True ) gbm = lgb.LGBMRegressor(objective='binary' , num_leaves=12 ) gbm.fit(X_train, y_train, eval_set = [(X_train, y_train), (X_val, y_val)], eval_names = ['train' , 'val' ], eval_metric = 'binary_logloss' ) model = gbm.booster_ gbdt_feats_train = model.predict(X_train, pred_leaf = True ) gbdt_feats_test = model.predict(X_test, pred_leaf = True ) gbdt_feats_name = ['gbdt_leaf_' + str (i) for i in range (gbdt_feats_train.shape[1 ])] df_train_gbdt_feats = pd.DataFrame(gbdt_feats_train, columns = gbdt_feats_name) df_test_gbdt_feats = pd.DataFrame(gbdt_feats_test, columns = gbdt_feats_name) train = pd.concat([X_train, df_train_gbdt_feats], axis = 1 ) test = pd.concat([X_test, df_test_gbdt_feats], axis = 1 ) train_len = X_train.shape[0 ] data = pd.concat([train, test]) for col in gbdt_feats_name: onehot_feats = pd.get_dummies(data[col], prefix = col) data.drop([col], axis = 1 , inplace = True ) data = pd.concat([data, onehot_feats], axis = 1 ) train = data[: train_len] test = data[train_len:] X_train_new, X_val_new, y_train_new, y_val_new = train_test_split( train, y_train, test_size = 0.3 , random_state = 42 ) lr = LogisticRegression() lr.fit(X_train_new, y_train_new) tr_logloss = log_loss(y_train_new, lr.predict_proba(X_train_new)[:, 1 ]) print ('tr-logloss: ' , tr_logloss)val_logloss = log_loss(y_val_new, lr.predict_proba(X_val_new)[:, 1 ]) print ('val-logloss: ' , val_logloss)y_pred = lr.predict_proba(test)[:, 1 ] np.sum (1 *(y_pred >= 0.5 ) == y_test) / len (y_pred)
参考资料