本文主要介绍推荐系统中的矩阵分解技术。之前在协同过滤 | Yam中分别提到过基于用户和商品的方法,它们分别基于相似用户和相似物品完成推荐。但是协同过滤有个很大的问题就是数据稀疏,以一个电商网站为例,可能大部分的商品都只有很少的用户购买,而热门商品又有很多人购买。这导致的结果就是难以找到相似的用户(基于用户的协同过滤)或头部效应(基于商品的协同过滤)。这一问题是协同过滤算法的天然缺陷,表现出来的其实正是 2-8 定律和马太效应,再往深了想,从客观角度看是因为信息不对称,主观角度看则是因为羊群效应。所以,很自然的想法就是将稀疏表征稠密化。稠密化表示也就意味着特征的多元化,直观来看自然是表征能力和泛化能力更强。矩阵分解正是这样的技术。
基本思想
给定 User-Item 的矩阵,假设大小为 m×n,那么如果将矩阵分解为 User 矩阵 U(m×d)和 Item 矩阵 V(d×n),自然就可以得到用户和商品的表征,用户 Ui 对商品 Vj 的评分则为 Ui 和 Vj 对应向量的点乘。而得到的两个矩阵则称为隐向量矩阵。其中维度 d 每一维表示一个特征,但是我们并不明确知道该特征代表什么意思,这也是 “隐” 的由来。这一工作最初是由 Simon Funk 在 2006 年 Netflix Prize 挑战时首次提出并使用。
下图是一个直观的演示,需要说明的是,一般情况下,维度 d 是比较小的。简单来说,矩阵分解就是将稀疏矩阵映射到低维的稠密矩阵。
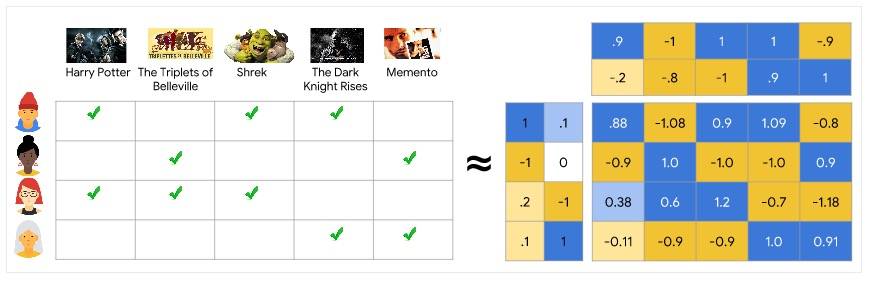
(图片来自:https://developers.google.com/machine-learning/recommendation/collaborative/matrix)
矩阵分解技术
矩阵分解也叫矩阵因子化,就像因式分解一样,是将一个矩阵分解为两个不同的组成部分。常用的矩阵分解方法有两大类:与线性方程组求解相关的分解和特征值相关的分解。
前者的代表有:
- LU 分解:给定方阵 A,A=LU,其中 L 和 U 分别表示下三角和上三角矩阵。
- 秩分解:给定矩阵 A(m×n),秩为 r,A = CF,其中 C 为 m×r 的矩阵,F 为 r×n 的矩阵。
- Cholesky 分解:给定厄米特正定方阵 A,A= LL*,其中 L 表示下三角阵,L* 表示 L 的共轭转置。
- QR 分解:给定矩阵 A(m×n),各列线性无关,A=QR,其中 Q 为 m×m 的单位矩阵,R 为 m×n 的上三角阵。
后者的代表有:
- 特征分解:给定方阵 A,其特征向量线性无关,A=VDV’,其中 D 是对角矩阵,V 是特征向量,V‘ 是 V 的逆矩阵。
- 奇异值分解:给定矩阵 A(m×n),A=UDV*,其中 D 是非负对角矩阵,U 和 V 满足 U*U=I,V*V=1,V* 是V 的共轭转置,I 是单位矩阵。D 的元素也被称为奇异值。
不过我们这里由于 User-Item 矩阵有很多缺失值,而且非常稀疏,如果要直接分解的话,首先填充确实元素这一环节就不太好处理,而且稀疏矩阵求解的结果效果也差,另外计算复杂度也比较高。因此,实际应用时往往不会直接求解,而是通过优化方法来迭代得到最优解。
Funk MF
Funk MF 是 Simon Funk 提出的分解算法,将 User-Item 评分矩阵分解为两个低维矩阵乘积,这种方法其实是类似 SVD 的机器学习模型。预测评分通过下式计算:
R^=UVR^∈Rusers×itemsU∈Rusers×latentfactorsV∈Rlatentfactors×items
用户 Ui 对 物品 Vj 的评分为:
rij^=f=0∑nfactorsUi,fVf,j
可以通过调整因子的数量来调整模型的表达能力,只有一个因子时等价于推荐最流行的情况(没有个性化,只推荐最多交互的),因子数量增加时,模型的个性化推荐能力提高,直到增加到开始过拟合时,推荐质量开始下降。为防止模型过拟合,一般会加入正则化项。Funk MF 的优化目标函数为:
argU,VminR−R^F+α∥U∥+β∥V∥s.t.∣∣⋅∣∣f is frobenius norm
可以进一步整理为:
L=21i,j∑(ri,j−f∑Ui,fVf,j)2+λ∥U∥2+λ∥V∥2
U 和 V 对应元素的梯度为:
∂Ui,f∂L=−ei,jVf,j+λUi,f∂Vf,j∂L=−ei,jUi,f+λVf,js.t.ei,j=ri,j−rij^=ri,j−f=0∑nfactorsUi,fVf,j
接下来就可以用梯度下降法来更新每个参数了。
SVD++
Funk MF 只关注了用户与商品的评分(数值)信息,还有很多非数值信息(如购买、收藏)等并没有考虑。SVD++ 正是将这些信息也纳入考虑。具体做法是加入用户和物品偏置:
r^i,j=μ+bi+bj+f=0∑nfactorsUi,fVf,j
其中 μ 表示所有评分记录的全局平均。不过这种方法并不是基于模型的,也就是说当有新用户时,模型必须重新训练才能为新用户做出推荐。所以,必须考虑将该问题也纳入模型,也就是如何计算新用户的隐向量。一个可能的方法是通过之前用户的交互来评估,如果系统能够收集到新用户的一些交互信息,就可以通过这些交互信息来计算他的隐向量表征。
r^i,j=μ+bi+bj+f=0∑nfactors(k=0∑nitemsri,kVk,fT)Vf,j
此时:
R^=RVTV
其实就相当于用物品矩阵来表征用户。接下来的目标函数和梯度计算与 Funk MF 类似。
目标函数为:
L=21i,j∑(ri,j−μ−bi−bj−f=0∑nfactors(k=0∑nitemsri,kVk,fT)Vf,j)2+λ∥bi∥2+λ∥bj∥2+λ∥V∥2
对应参数的梯度为:
∂Vf,j∂L=−ei,j((k=0∑nitemsri,kVk,fT)+ri,jVf,j)+λVf,j∂bi∂L=−ei,j+λbi∂bj∂L=−ei,j+λbjs.t.ei,j=ri,j−rij^=ri,j−μ−bi−bj−f=0∑nfactors(k=0∑nitemsri,kVk,fT)Vf,j
这里第一个梯度的式子不确定是不是这样,如有错误还请指正。
非对称 SVD
相比 SVD++,非对称的 SVD 就是将对称的 V^T V 替换成非对称,即:
r^i,j=μ+bi+bj+f=0∑nfactors(k=0∑nitemsri,kQk,f)Vf,j
此时:
R^=RQV
特定组 SVD
在许多场景中,组 SVD 是解决冷启动问题的有效方法。该方法根据相似度和依赖信息将用户和商品聚类,当新用户出现时,可以先给他标一个类标签,然后根据组近似计算隐向量。
r^i,j=f=0∑nfactors(Ui,f+Shi,f)(Vf,j+Tf,kj)
hi 和 kj 分别表示用户 i 和 商品 j 的类标签。S 和 T 分别是对应的类矩阵。给定新用户 inew,Ui 未知,此时至少可以确定类标签 Hinew,然后预测评分:
r^inewj=f=0∑nfactorsShinew,f(Vf,j+Tf,kj)
优化方法
优化目标函数有两种方法:
- SGD:即随机梯度下降 Stochastic Gradient Descent,这是通用的方法
- WALS:即加权交错最小二乘法 Weighted Alternating Least Squares,是专门用来优化类似目标函数的方法。具体做法是首先随机初始化 U 和 V 矩阵,然后在以下条件之间交替进行:
两种方法的对比如下:
|
SGD |
WALS |
| 损失函数 |
可以使用其他损失函数 |
只能使用平方损失 |
| 并行化 |
可以并行 |
可以并行 |
| 收敛速度 |
比较慢 |
比较快 |
| 处理未观测实体 |
需要负采样 |
容易处理 |
代码实现
首先是 Funk MF,这个比较简单,我们根据 Loss 的变化额外加了个提前终止:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| def funk_mf(
R: np.array,
nfactors: int,
alpha: float, lamda: float,
steps: int = 100, eps: float = 1e-3
) -> Tuple[np.array, np.array]:
m, n = R.shape
U = np.random.rand(m, nfactors)
V = np.random.rand(nfactors, n)
eprev = np.inf
for _ in range(steps):
for i in range(m):
for j in range(n):
if R[i][j] <= 0:
continue
eij = R[i,j] - np.dot(U[i,:], V[:,j])
for f in range(nfactors):
U[i,f] += alpha * (eij * V[f,j] - lamda * U[i,f])
V[f,j] += alpha * (eij * U[i,f] - lamda * V[f,j])
alpha *= 0.1
e = 0
for i in range(m):
for j in range(n):
if R[i,j] <= 0:
continue
e += (R[i,j] - np.dot(U[i,:], V[:,j])) ** 2
e += np.sum(U ** 2) + np.sum(V ** 2)
if eprev - e < eps:
break
eprev = e
return U, V
R = np.array([
[5,3,4,4,0],
[3,1,2,3,3],
[4,3,4,3,5],
[3,3,1,5,4],
[1,5,5,2,1]
])
u,v = funk_mf(R, 10, 0.1, 0.1)
np.dot(u[0,:], v[:,4])
|
然后是 SVD++,我们先实现基础版本(只增加偏置)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| @dataclass
class SVD:
R: np.array
nfactors: int
alpha: float
lamda: float
steps: int = 100
eps: float = 1e-3
def __post_init__(self):
self.m, self.n = self.R.shape
self.U = np.random.rand(self.m, self.nfactors)
self.V = np.random.rand(self.nfactors, self.n)
self.mu = np.average(self.R)
self.bi = np.zeros(self.m)
self.bj = np.zeros(self.n)
def train(self):
eprev = np.inf
for _ in range(self.steps):
for i in range(self.m):
for j in range(self.n):
if self.R[i][j] <= 0:
continue
eij = self.R[i,j] - self.predict(i,j)
self.bi[i] += self.alpha * (eij - self.lamda * self.bi[i])
self.bj[j] += self.alpha * (eij - self.lamda * self.bj[j])
for f in range(self.nfactors):
self.U[i,f] += self.alpha * (eij * self.V[f,j] - self.lamda * self.U[i,f])
self.V[f,j] += self.alpha * (eij * self.U[i,f] - self.lamda * self.V[f,j])
self.alpha *= 0.1
e = 0
for i in range(self.m):
for j in range(self.n):
if self.R[i,j] <= 0:
continue
e += (R[i,j] - self.predict(i,j)) ** 2
e += np.sum(self.bi ** 2) + np.sum(self.bj ** 2) + np.sum(self.V ** 2) + np.sum(self.U ** 2)
if eprev - e < self.eps:
break
eprev = e
def predict(self, i: int, j: int):
rate = 0.0
for f in range(self.nfactors):
rate += self.U[i,f] * self.V[f,j]
rate += self.mu + self.bi[i] + self.bj[j]
return rate
R = np.array([
[5,3,4,4,0],
[3,1,2,3,3],
[4,3,4,3,5],
[3,3,1,5,4],
[1,5,5,2,1]
])
svd = SVD(R, 10, 0.1, 0.1)
svd.train()
svd.predict(0, 4)
|
最终的版本只需要将参数更新的地方稍微更改一下即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| @dataclass
class SVD:
R: np.array
nfactors: int
alpha: float
lamda: float
steps: int = 100
eps: float = 1e-3
def __post_init__(self):
self.m, self.n = self.R.shape
self.V = np.random.rand(self.nfactors, self.n)
self.mu = np.average(self.R)
self.bi = np.zeros(self.m)
self.bj = np.zeros(self.n)
def train(self):
eprev = np.inf
for _ in range(self.steps):
for i in range(self.m):
for j in range(self.n):
if self.R[i][j] <= 0:
continue
eij = self.R[i,j] - self.predict(i,j)
self.bi[i] += self.alpha * (eij - self.lamda * self.bi[i])
self.bj[j] += self.alpha * (eij - self.lamda * self.bj[j])
for f in range(self.nfactors):
tmp = self.R[i,j] * self.V[f,j]
for k in range(self.n):
tmp += self.R[i,k] * self.V.T[k,f]
self.V[f,j] += self.alpha * (eij * tmp/self.n - self.lamda * self.V[f,j])
self.alpha *= 0.1
e = 0
for i in range(self.m):
for j in range(self.n):
if self.R[i,j] <= 0:
continue
e += (R[i,j] - self.predict(i,j)) ** 2
e += np.sum(self.bi ** 2) + np.sum(self.bj ** 2) + np.sum(self.V ** 2)
if eprev - e < self.eps:
break
eprev = e
def predict(self, i: int, j: int):
rate = 0.0
for f in range(self.nfactors):
tmp = 0.0
for k in range(self.n):
tmp += self.R[i,k] * self.V.T[k,f]
tmp /= self.n
rate += tmp * self.V[f,j]
rate += mu + bi[i] + bj[j]
return rate
R = np.array([
[5,3,4,4,0],
[3,1,2,3,3],
[4,3,4,3,5],
[3,3,1,5,4],
[1,5,5,2,1]
])
svd = SVD(R, 10, 0.1, 0.1)
svd.train()
svd.predict(0, 4)
|
这里在计算梯度时,除了一个 n 做缩放,要不然无法收敛。不确定是否正确,如有错误还请指正。
参考资料