OMNI相关论文。
202505 LLaMA-Omni 2 ICT/CAS
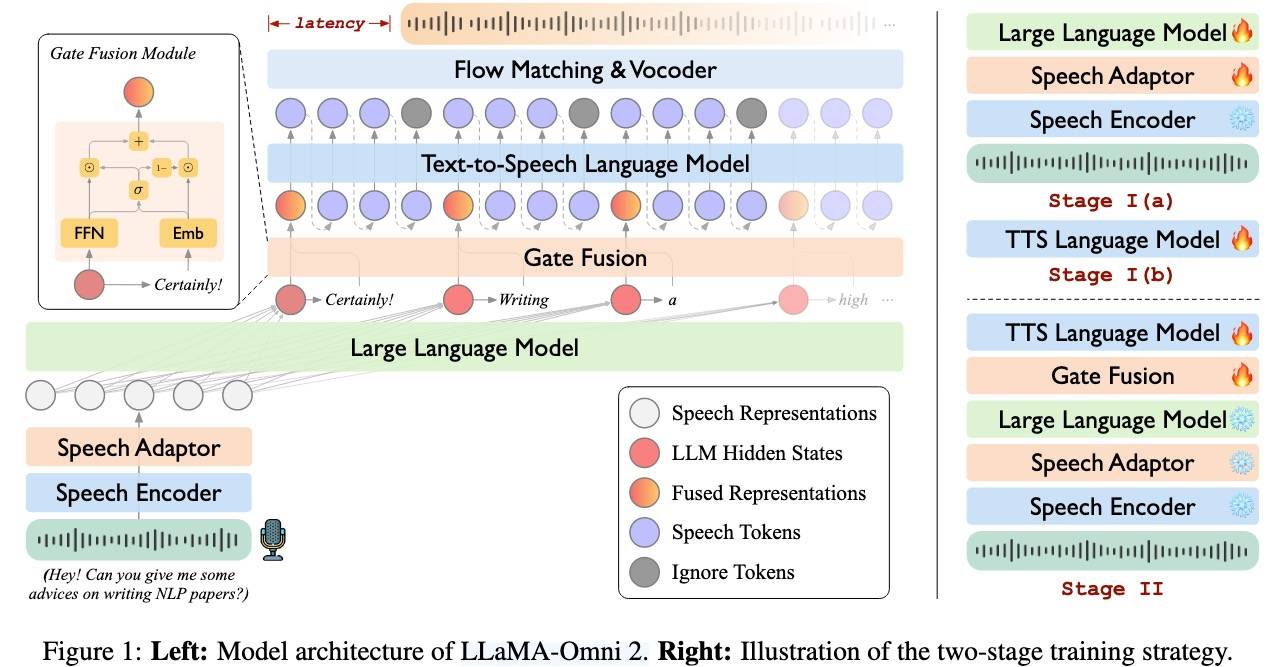
基于Qwen2.5 + CosyVoice2 + Whisper。
- Speech Tokenizer:单码本、25Hz、6561大小,来自Cosyvoice2。
- Text-to-Speech Language Model:
- LLM的输出(Token+hidden_states)给M_TTS。
- 两层FFN将hidden_states(上下文信息)映射到给TTS的Embedding,同时根据Token得到Text Embedding(TTS的Embedding Layer)。
- 使用gate fusion融合两个Embedding,然后传给M_TTS。
- 流式:每读取 R 个融合表示就生成W个语音Token。当所有融合表示读取完毕后,模型会继续生成剩余的语音Token,直到完成为止。
- Flow Matching Model:来自CosyVoice 2。
数据:200K 多轮speech-to-speech数据。
- 根据InstructS2S-200K,使用InstructS2S-200K生成多轮(1-5轮)文本。
- 使用fish1.5生成随机音色,然后用CosyVoice2 ZeroShot合成对应的Instruction Speech(输入音色多样化)。输出1个固定音色。
两阶段训练:
- Stage1:分开训练S2T、T2S。gate fusion不训练,只有Text Embedding输入到M_TTS.。
- speech-to-text:固定speech encoder训练speech adapter 和LLM。
- text-to-speech:训LLM。
- Stage2:训speech-tospeech多轮对话。固定speech encoder、speech adapter和LLM,只训练gate fusion module 和M_TTS。
推理:
- 基于语音Instruction生成文本。
- 生成的Text Token和hidden_states进入gate fusion module 和M_TTS,生成Speech Token。
- Speech Token传给flow matching和vocoder生成音频。
202503 Phi-4-Mini Microsoft ☆
3.8B+高质量数据+模态级Lora达到SLM的SOTA。
模型架构
值得注意的是 25% 的注意力头维度不受 RoPE 影响(Fractional RoPE )。
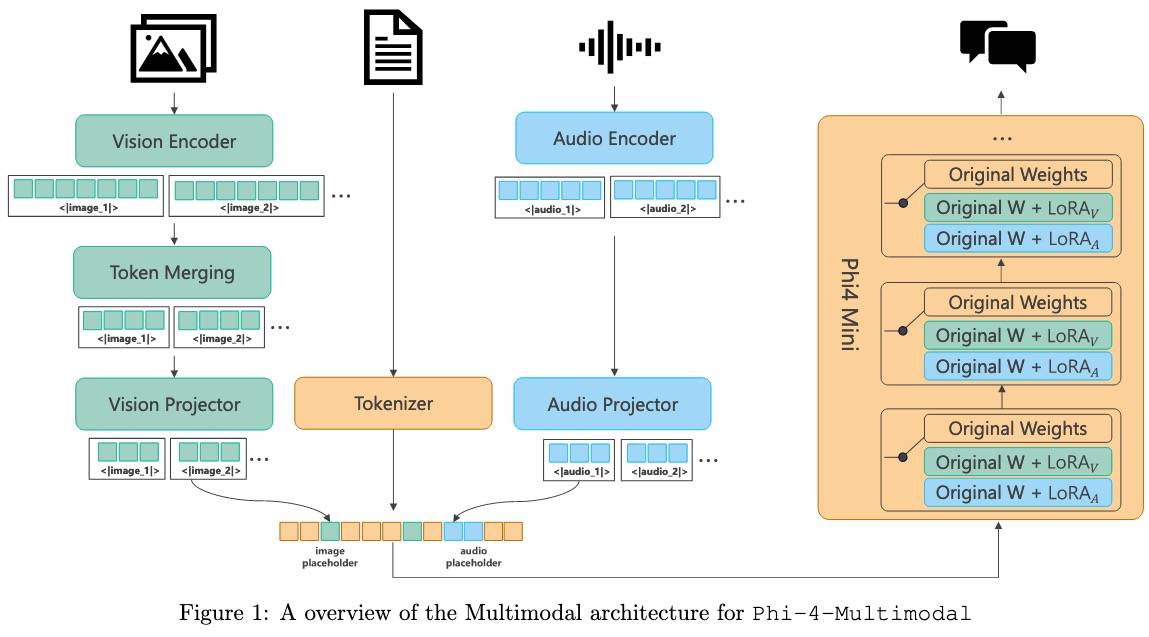
特征处理
为了使模型能够有效和高效地处理不同分辨率的图像,提出动态多裁剪策略:
- 首先,原始尺寸除以裁剪尺寸计算每边的裁剪数量。
- 如果总裁剪数在最大数字范围内(预训练16,SFT36),稍微调整图像大小使其符合计算图像裁剪所给出的尺寸。
- 否则,通过匹配最佳纵横比来找到裁剪数。
音频:80 维对数 Mel 滤波器组特征,帧率为 10 毫秒(每 10 毫秒提取一个特征帧)。
多模态训练过程
- Vision Training(4阶段)
- Projector Alignment:projector,对齐文本。
- Joint Vision Training:projector+encoder联合训练,encoder是SigLIP-400M。
- Generative VisionLanguage Training:LoRA+projector+encoder,Single-Frame SFT。
- Multi-Frame Training:SFT,encoder冻结,长度扩到64k。
- Speech and Audio Training(2阶段)
- pre-training:ASR数据,projector+encoder,对齐到文本空间,encoder从一个ASR模型初始化。
- post-training:encoder冻结,不同长度(30min 22.5k token、30s 375 token),多任务SFT。
- Vision-speech Joint Training(2阶段)
- 冻结audio encoder、audio projector,微调visual projector、visual encoder和LoRA visual。
- vision-speech SFT data。
- Reasoning Training(3阶段)
- 60B CoT Token继续训练
- 高质量SFT
- DPO
数据
- Language
- Pre-training:5Trillion,更好的过滤、更好的数学和代码数据、更好的合成数据、混合更多推理类数据。
- Post-training:更多样化的Function Call和摘要数据。合成大量指令遵循数据,代码增加完形填空任务。
- Reasoning training:从大推理模型合成大量CoT数据,覆盖不同领域和难度。采样时使用规则+模型拒绝方法丢弃不正确的生成,然后放回。正确和错误的回答对构成DPO数据。
- Vision-language
- Pre-training:0.5T图像-文本文档、图像-文本对、图像锚定数据、来自 PDF 和真实图像 OCR 的合成数据集,以及用于图表理解的合成数据集。这个阶段只考虑文本Token损失,不考虑图像Token的损失。
- SFT:0.3T文本 SFT 数据集、公开的多模态指令微调数据集和大规模内部多模态指令微调数据集的组合。覆盖不同主题和任务,包括对通用自然图像的理解、图表、表格和示意图的解析与推理、PowerPoint分析、OCR、多图对比、视频摘要以及模型安全性。
- Vision-speech
- 多样化的合成数据(将vision-language的SFT数据用TTS将用户query从文本转为音频),覆盖单帧和多帧。
- 合成音频用ASR模型识别后计算WER,用来过滤,保证质量。
- Speech and Audio
- Pre-training:200万小时、8种语言音频+ASR文本。
- Post-training:多种任务,包括自动语音识别 (ASR) 、自动语音翻译 (AST) 、语音问答 (SQA) 、语音查询问答 (SQQA) 、语音摘要 (SSUM) 和音频理解 (AU) 。格式:
<∣user∣><audio>{task prompt}<∣end∣><∣assistant∣>{label}<∣end∣>。- ASR:40k小时,28M样本。
- AST:30k小时,28M样本。
- SQA+SQAQA:26M样本。
- SSUM:1M样本,仅英文,每个最长30分。
- AU:Speech+Music,17M样本。