Paper:[2208.03054] Global Pointer: Novel Efficient Span-based Approach for Named Entity Recognition
Code:https://github.com/bojone/bert4keras
一句话概述:全局指针识别 NER,Span 预测得到 NER 类型。
摘要:NER 任务是从一段文本中识别出预先定义的语义实体类型。SOTA 方案通常会因为捕获底层文本的细粒度语义信息而受到影响。基于 Span 的方法克服了这种缺陷,但性能是个问题。本文提出基于 Span 的 NER 框架——全局指针(GP),通过乘法注意力机制利用相对位置,目标是考虑开始和结束位置的全局视图来预测实体。除了设计了两个模块(Token 表征和 Span 预测)来识别实体外,还引入了一种新的损失函数来解决标签不均衡问题,另外还引入了一种简单有效的近似方法减少参数。实验表明 GP 胜过现有方案,此外损失函数也表现出有效性。
核心方法
整体结构图如下:

简单来说,就是对每个 Label 都预测一个矩阵(也叫多头),除了正常的实体,还可以解决嵌套实体和多类型实体。
Token 的表征使用 PLM(上图为 BERT),接下来是 Span 预测,文中使用两个前馈层,它们依赖 Span 的开始和结束位置。
qi,α=Wq,αhi+bq,αki,α=Wk,αhi+bk,α
q 和 k 是用来识别实体类型 α 的 Token 向量,分数(注意力)为:
sα(i,j)=qi,αTkj,α
为了利用边界信息,使用 ROPE【1】将位置信息显式地注入模型。打分函数变为:
sα(i,j)=(Riqi,α)⊤(Rjkj,α)=qi,α⊤Ri⊤Rjkj,α=qi,α⊤Rj−ikj,α
减少参数
考虑到每一个实体类型都有一个参数矩阵,当实体类型增加时参数会增加。因此,本文提出了 Efficient GP,核心思想是共享打分矩阵参数。具体而言,将 NER 任务分为两个子任务:提取和分类,即先提取实体,再判断类别。此时,提取等价于 NER 任务只有一种实体。新的打分函数为:
sα(i,j)=(Wqhi)⊤(Wkhj)+wα⊤[hi;hj]
前面是共享部分,后面是 Span 起始和结束位置向量的拼接。当新增一个实体类型时,参数只增加 2v(v 是 PLM Token 向量的大小)。
为了进一步减少参数,可以将 hi 替换为 [qi;ki],最终打分函数为:
sα(i,j)=qi⊤kj+wα⊤[qi;ki;qj;kj]
[qi;ki;qj;kj] 就是 Span 的表征。此时,新增一个实体类型新增的参数为 4d(d 是最终 Token 向量大小)。
不均衡标签损失
单标签分类的交叉熵损失函数为:
log∑i=1nesiest=−log∑i=1nesi−st1=log1+i=1,i=t∑nesi−st
考虑多标签分类,损失函数为:
log1+i∈Ωneg∑esij∈Ωpos∑e−sj
目标是使目标类分数不低于非目标类分数。由于标签数量不确定,引入一个额外的类型 TH 作为阈值,期望目标类分数大于阈值,非目标类分数小于阈值。损失函数变为:
log1+i∈Ωneg,j∈Ωpos∑esi−sj+i∈Ωneg∑esi−sTH+j∈Ωpos∑esTH−sj=logesTH+i∈Ωneg∑esi+loge−sTH+j∈Ωpos∑e−sj
令阈值=0,最终的损失函数为:
log1+i∈Ωneg∑esi+log1+j∈Ωpos∑e−sj
推理时,只要 Sα > 0,就表示对应的实体类型为 α。
实验结果
在几个数据集上效果如下:

一些参数如下:dropout 0.1,30 epochs,2e-5 LR,batch size 32,用 BERT-base 初始化 GP,Adam 优化器。
性能对比如下:

关于相对位置和不均衡标签损失函数的实验结果如下:

相对位置非常关键!
关于 Efficient GP 的实验:

精心设计的减少参数的机制还能提升性能。
最后是实体长度和密度的实验:
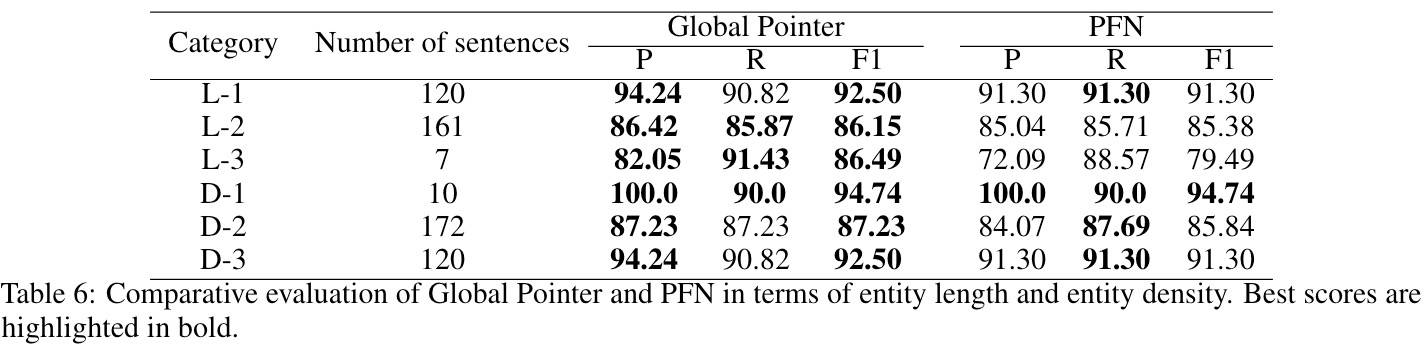
分类如下:
- L1:Length<3
- L2:3<=Length<6
- L3:L>=6
- D1:Dense<=0.1
- D2:0.1<Dense<=0.3
- D3:Dense>0.3
这个结果很有意思:密度和长度中等的效果都不好。
小结
GP 的两个模块拆分和新的 Loss 都非常值得借鉴。另外,苏神的公式推导真的很精彩,这篇 Paper 算是之前好几篇博文的一个总结输出了,推荐去作者个人网站阅读原始博文,理解思路成型过程。
参考文献
【1】[2104.09864] RoFormer: Enhanced Transformer with Rotary Position Embedding