Paper:[2208.03438] DeepGen: Diverse Search Ad Generation and Real-Time Customization
Code:无
一句话概述:端到端广告文本生成方案。
摘要:DeepGen 是一个 Web 部署的用于为 Bing 广告客户自动生成搜索广告的系统。它使用最新的 NLG 模型从广告商的网页生成流畅的广告,并解决一些实际问题(真实性、推理速度)。系统会根据用户的搜索查询实时创建定制化广告,从而根据用户「正在寻找的内容」突出显示同一产品的不同方面。为了实现此目标,系统提前生成各种可选择的小广告片段素材,查询时选择最相关的拼接到完整广告中。通过训练可控 NLG 模型为同一网页生成多个广告,突出不同卖点,从而提高生成的多样性。更进一步,通过首先运行使用不同目标训练的生成模型集合,然后使用多样性采样算法选择不同生成结果子集进行在线选择,进一步横向提升了多样性。实验结果验证了系统设计的有效性,目前已部署生产环境,提供了必应投放的大约 4% 的全球广告。
背景
搜索广告是一个很大的市场,传统方法是广告商人工编写为自己的页面编写广告。但这对微小企业和有数百万商品的大企业来说就不那么友好了。传统生成方法基于抽取的规则(比如关键短语、标题等),不过这种方法在生成很长的广告描述时不太行。本文主要聚焦在两个方面改进广告:真实性(Factuality)和定制化(Customization)。相比基于规则抽取的系统有 13.28% 的 CTR 提升,目前在生产环境提供 Bing 搜索 4% 的全球广告。

广告生成系统
一个端到端的系统,步骤如下:
- 广告商提供域名和页面定位规则(每个规则都有出价),搜索索引爬取所有该域名下匹配目标规则的页面,并执行 DU(Document Understanding)Pipeline 提取文本信息。
- 同时执行多个 NLG 模型,生成广告素材资源或完整的广告文案,后者会被简单切分为广告素材。对每个 URL,将获取到一些生成的标题和描述素材。
Baseline
一个基于抽取的系统
这是 Bing 用了超过十年的线上系统,提取的部分信息如下:
- 页面标题
- 视觉标题
- 顶端/最佳正文片段(基于 Bling【1】)
抽象生成基准
使用直接在广告客户书面广告文案上 Finetuned 的模型(UniLMv2)作为抽象生成(Abstractive generation)方法的基准。此类模型称为 AdCopy 模型,因为它们为每个源文本生成一个广告副本。
生产中会部署多个 AdCopy 模型,一些最佳实践如下:
- 广告客户编写的广告具有非常倾斜的分布,有些广告商有数百万个模板生成的广告。因此,从每个广告客户域名在过去一年中展示最多的 3000 个 URL 中进行抽样,获得 3M-5M 的训练样本。
- 从训练集中随机拆分验证集和测试集效果不佳;应该从不在训练集中的广告商构建,避免过拟合。
一些数据和参数如下:
- 验证集 300-500K,测试集 30-50K,验证集上使用 ROUGE1-F1 来选择最佳的 checkpoint。
- 预测的 Beam Search 大小为 5,并在交叉注意阶段使用 Einsum 算子避免编码器缓存复制(根据 FastSeq【2】)。
真实性改进
评估质量主要靠人工,数据抽样方式如下:对每个域名最多 50 个示例进行抽样,每个人工评估任务抽取 500-1000 个样例。主要评估四个方面:
- 文本质量(Text Quality):语法和风格,分为好、一般、差、不可评分。
- 是否像人类写的(Human Like):是、否。
- 真实性(Factuality):生成的信息是否被页面内容支持,包括是、否。
- 相关性(Relevance):生成的文本是否与广告商的业务相关,包括是、否。
如果一个广告文本文本质量好或一般、像人类写的、真实、相关,那就是「整体上好(Overall Good)」。结果如下:
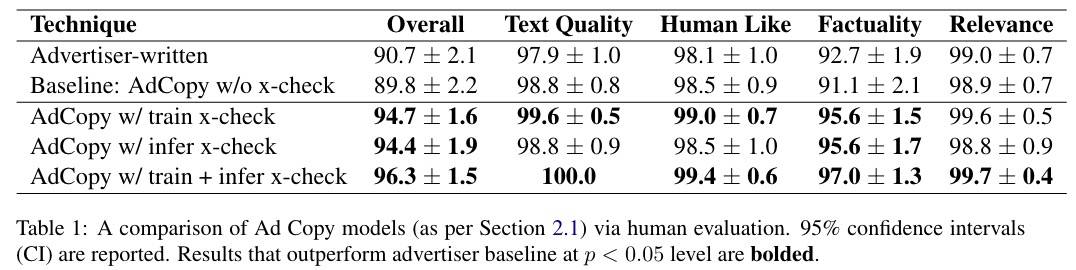
虽然基线模型和广告商编写的广告在质量上没有显著差异,但是总体良好率都因为较低的事实性分数而较低。比如一些打折信息,但是页面里其实并没有。为了缓解这个问题,本文使用了基于短语的交叉检查过滤,类似于基于实体的过滤【3】。
一些交叉检查的例子包括:
- 短语检查:敏感或可能具有误导性的短语列表。
- 品牌检查:从搜索引擎知识图谱获取的品牌列表。
- 域名检查:检查页面 URL 检查「xyc.com」这样的模式。
在两个阶段添加检查规则:
- 在训练前过滤训练数据(train x-check)。
- 在预测后过滤生成的文本(infer x-check)。
素材级别的可控文本生成
为了明确建模多样性,本文构建了一个可控的 NLG 模型来为同一源文本序列生成多个广告素材。具体通过控制代码(CTRL【4】)、代表所需输出属性的分类变量【5】来实现。这类模型被称为 Guided 模型。
假设每个页面可以针对不同的卖点进行 12 个类别的广告(分类),比如产品或服务、广告商名称、品牌、位置等,主要从广告商门户网站说明中借用的。然后人工对大约 6500 条不同的广告商撰写的素材进行分类。使用 BERT-base 做分类任务,达到约 80% 的精度。
接着预测每个广告片段的类别,然后将类别控制代码添加到源文本开始位置,获得一个包含 6M 个广告素材(包括标题和描述)数据集,用于训练 Guided Model。结果如下:
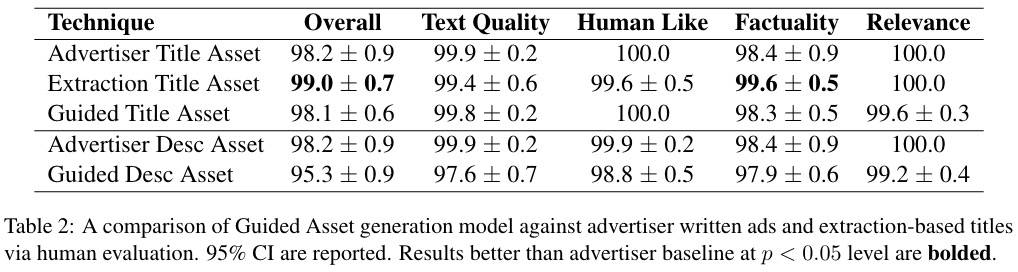
Guided 模型和广告商的质量没有明显区别,抽取式的比它们要好。广告商的描述素材比模型要好,模型的优势在于能够明确地捕获标题和描述的不同广告类别。抽取式无法生成好的广告描述。
服务和定制化
多样性选择
主要是从 T 和标题素材和 D 和描述素材中选择一个语义多样的子集(针对每个 URL),然后给到线上服务组件,目的是减少系统负载,并提高文本多样性。
本文使用了 CDSSM【6】,使用搜索日志训练,将每个素材表征为向量,然后使用 k-DPP 最大后验推理算法【7】对 CDSSM 空间中点的不同子集进行采样。
同时,使用 PairwiseBLEU【8】、SelfBLEU【9】和 Distinct N-gram【10】来评估标题素材在 k-DPP 前后的多样性。从 50 个域名随机采样了 2000 个 URL 进行计算,结果如下:
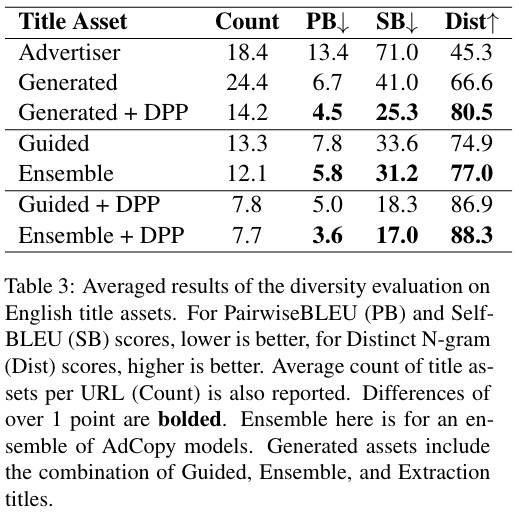
生成的标题素材比广告商提供的更加多样化,k-DPP 可以进一步增加素材多样性。另外,Guided 模型本身可以生成与多个 AdCopy 模型组合生成的标题素材数量相似且多样性相似的标题素材。
实时拼接
在 query 时,将定制的广告文案拼接在一起,优化拍卖中标率(选择最佳的广告文案)。这里使用 LR 对每个素材位置进行打分,特征来自广告拍卖日志,比如素材文本中的字符串哈希、长度、素材的 Ngram 等,同时还将这些与查询文本进行交叉,得到每个位置的稀疏特征(大约 4B),LR 学习赢得给定广告副本拍卖的概率。每天持续使用前一天日志中的约 10B 数据进行训练。
这里还包括一个探索机制,允许向用户添加新的素材并消除模型偏差。由于拼接过程的顺序性,将探索过程建模为一个序列上下文老虎机问题(Sequential Contextual Bandit Problem),在每个素材位置,CB 使用 LR 分数和 LR 特征的梯度和作为试验计数的启发式方法【11】,使用 Thompson 采样策略【12】选择素材。
AB测试
首先是两个关键业务指标:
- Revenue Per Mille(RPM):每千次搜索结果页面浏览量(Search Result Page Views,SRPV)收入。由印象收益(Impression Yield,显示的广告数/SRPV)和点击率(CTR,点击数/显示的广告总数)驱动。
- Quick Back Rate(QBR):用户点击广告后点击返回按钮的比例。
一共有两个实验:
- 实验一:对比 DeepGen 和抽取式系统(对照组),可以看到明显的 RPM 收益,意味着 DeepGen 生成的个性化广告文案更有可能赢得拍卖并被用户点击。
- 实验二:消融实验(针对实时定制),将实时拼接替换为预先计算的拼接作为对照组。具体做法是,建立一个单独的模型离线将素材拼接到多个广告副本中,并仅在查询(在线)期间对预先拼接的广告文本进行排名。RPM 依然明显,因为主要由 IY 驱动而不是 CTR。结果表明,在线拼接比离线拼接覆盖的排列空间更大,更有可能赢得拍卖。但是对于赢得拍卖的广告文本,无论在线还是离线对用户的吸引力都是相似的。

小结
本文提出了一个自动的端到端搜索广告文本生成解决方案,使用 NLG 模型生成广告内容和多样化选择,利用实时 LR 排名器进行内容拼接。生成技术提供了丰富的高质量广告内容来源,比人类表现更加出色。通过语义嵌入进一步应用多样化选择,超越人类的多样性,同时确保系统的可扩展性。最后,使用实时排名来拼接有吸引力、根据用户查询和搜索意图为其真正定制的广告。这种自动广告生成方案展示了比抽取系统基线显著的 CTR 增益。
总而言之,是一篇很不错的工业论文,里面涉及到多个组件和多个模型,整体构成了一整套解决方案和线上系统,非常值得参考。
参考论文
- 【1】Open Domain Web Keyphrase Extraction Beyond Language Modeling - Microsoft Research
- 【2】FastSeq: Make Sequence Generation Faster - ACL Anthology
- 【3】Entity-level Factual Consistency of Abstractive Text Summarization - ACL Anthology
- 【4】[1909.05858] CTRL: A Conditional Transformer Language Model for Controllable Generation
- 【5】[1707.02633] Controlling Linguistic Style Aspects in Neural Language Generation
- 【6】A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval | Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management
- 【7】[1709.05135] Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity
- 【8】[1902.07816] Mixture Models for Diverse Machine Translation: Tricks of the Trade
- 【9】[1802.01886] Texygen: A Benchmarking Platform for Text Generation Models
- 【10】Diversity-Promoting GAN: A Cross-Entropy Based Generative Adversarial Network for Diversified Text Generation - ACL Anthology
- 【11】Ad click prediction | Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining
- 【12】Near-Optimal Regret Bounds for Thompson Sampling | Journal of the ACM