论文:[2104.08821] SimCSE: Simple Contrastive Learning of Sentence Embeddings
Code:princeton-nlp/SimCSE: SimCSE: Simple Contrastive Learning of Sentence Embeddings
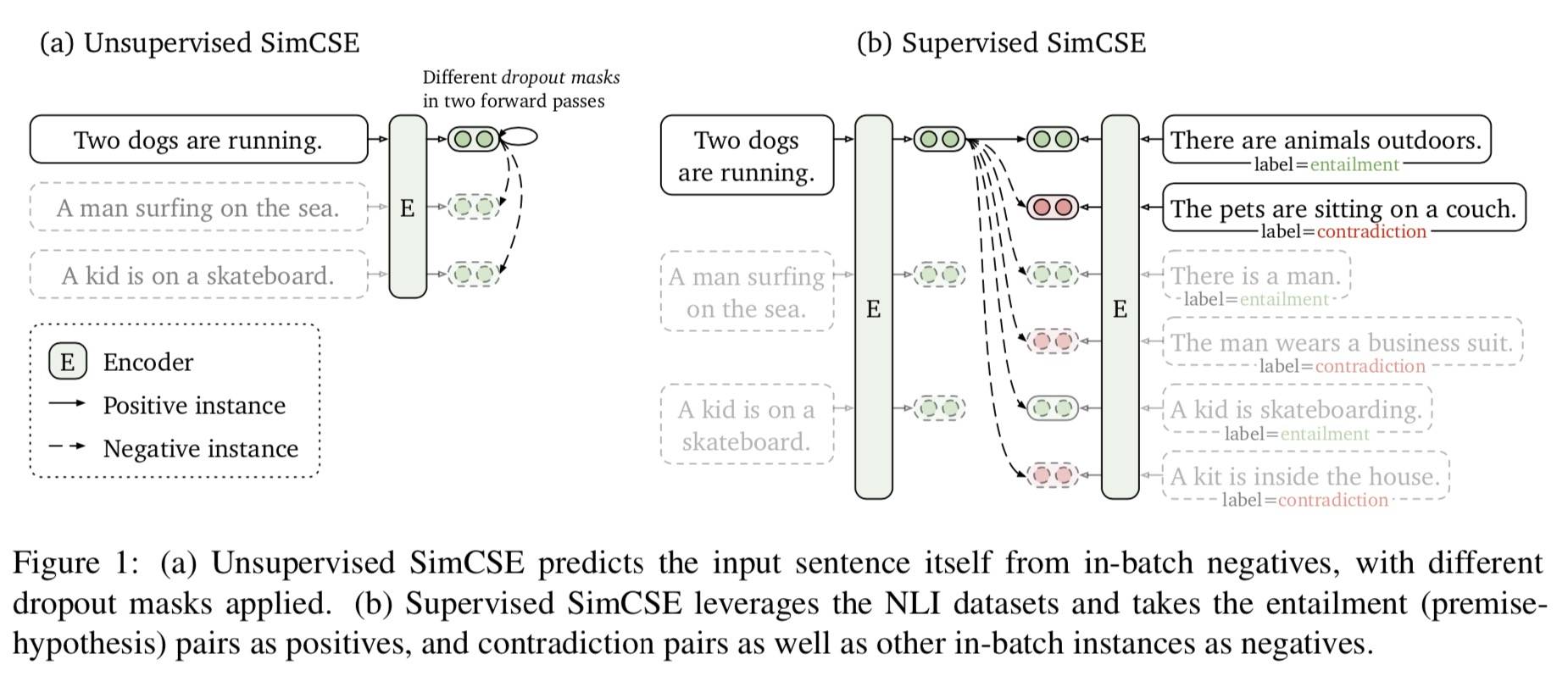
一句话概述:Dropout 增益句子 Embedding。
摘要:本文提出一个简单的对比学习框架,极大地提高了句子的表征能力。首先是无监督的方法,使用一个输入句子,在对比目标中预测自己,这里仅使用标准的 dropout 作为噪声。接下来将 NLI 数据集中的标注对合并到对比学习中,“蕴涵”对作为正例,“矛盾”对作为负例。最后,论文还发现对比学习在理论上能够将预训练 Embedding 的各向异性空间正则化,使其更加均匀,而且有监督信号可用时,可以更好地对齐正例对。
背景
对比学习旨在通过将语义上接近的邻居拉到一起并推开非邻居来学习有效的表示。假设一组样例对,每队样例在语义上相关,使用 in-batch 负采样的交叉熵目标:
τ 是超参数,值越大分布的概率越平滑,sim 是余弦距离,h 是预训练模型输出的句子表征。
如何构建正例对
- 图像领域的随机变换,NLP 领域的词删除、重排序和替换。不过由于自然语言的离散特性导致数据增强比较困难。
- 不同的上下文。正例对来自标注数据集,比如 mention-entity,question-passage 对等。因为根据定义的不同性质,这些方法总是使用双编码器框架。
对齐和均匀
与对比学习的两个关键属性,给定正例对的一个分布,「对齐」计算正例对 Embedding(归一化)的期望距离:
「均匀」计算两个 Embedding 分布的均匀性:
Pdata 是数据分布。
这两个指标与对比学习的目标非常一致:正实例应该保持紧密,随机实例的 Embedding 应该分散在超球面上。
相关工作
- 无监督
- 句子 Embedding 的早期工作建立在分布假设的基础上,通过预测给定句子的周围句子
- 通过对同样的句子输出不同的视角在无监督数据上使用对比目标
- 有监督
- 在 NLI 上微调一个孪生网络
- 双语和回译语料提供相似语义的标签
- 对 Embedding 进行正则化以缓解表征衰退问题
无监督 SimCSE
对任一句子,让 x+=x,这其中的关键就是对同一个句子使用独立的 dropout mask 采样。目标函数:
其中 z 就是 Transformer 的标准 mask,就很简单地将同样的输入进 Encoder 两次。
这样的话,正例对几乎是同样的句子,它们的 Embedding 只有 dropout 不一样,结果表明:
- 常规的数据增强技术(词删除、替换啥的)都不如基本的 dropout 噪声
- STS-B 验证集(句子相似度)的皮尔逊相关系数要好于 next-sentence 目标
为什么有效?说实话我也很好奇……先看一张表:
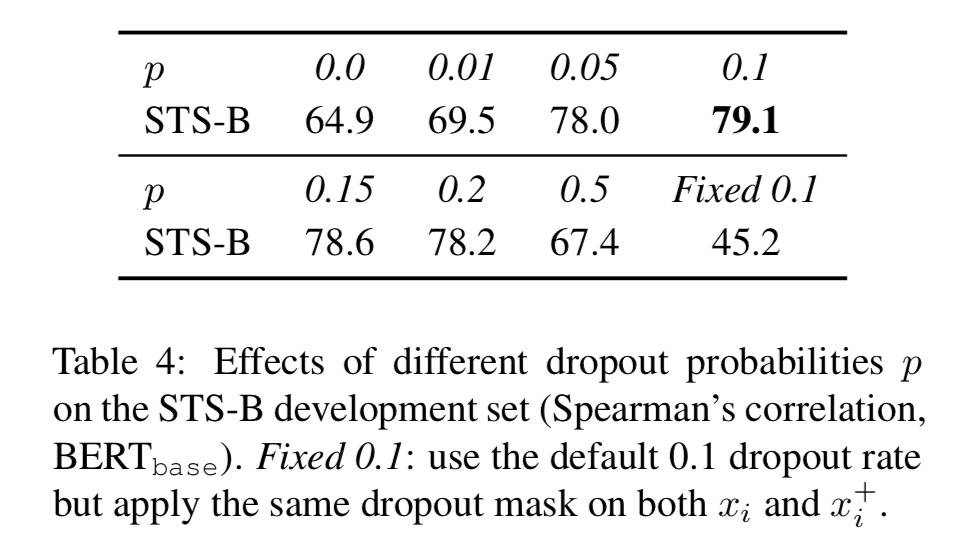
有个神奇的地方:当不使用 dropout(p=0)或固定 dropout(dropout mask 也一致)时,Embedding 几乎一致,此时表现会急剧下降。换句话说,p=0.1 的随机 dropout 就是全部的魔法。Surprise,Unbelievable。
再来看另一个图:
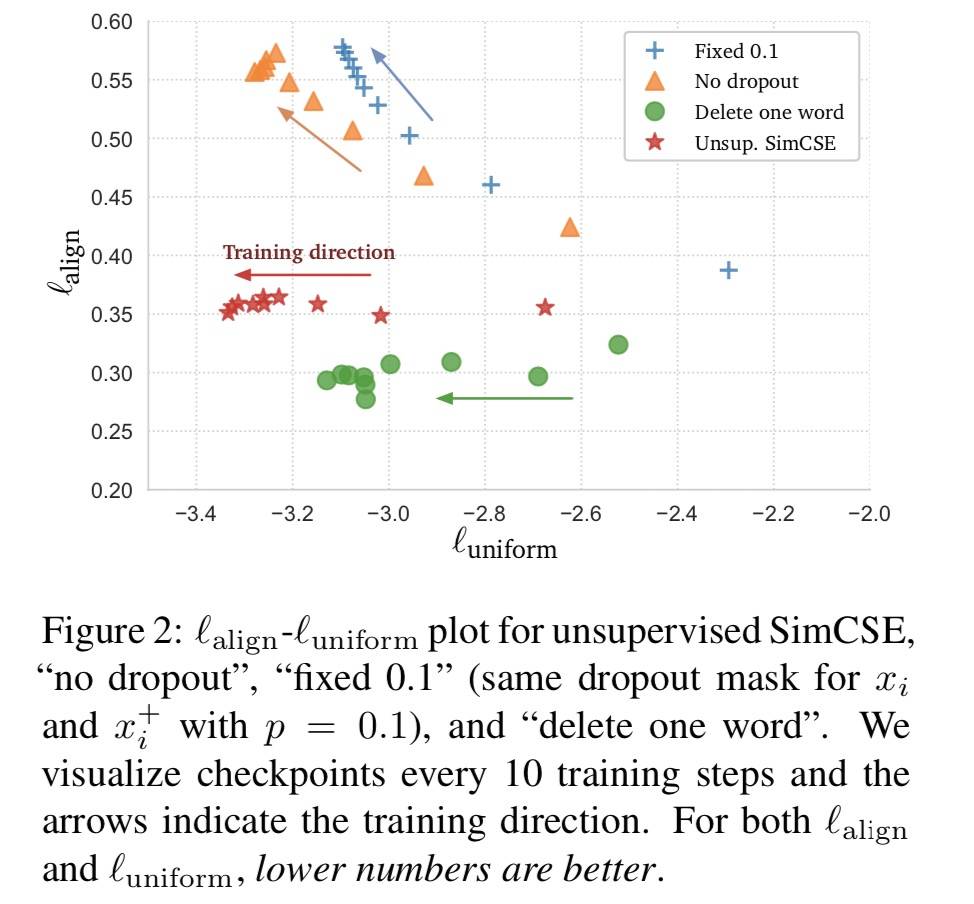
uniform 上比较接近,但是 align 上 No dropout 和 Fixed 0.1 就不太行了。对于 Delete one word,虽然在 align 上略有胜出,但是在 uniform 上差距有点大,整体还是不如 SimCSE。牛逼——完事了。
有监督 SimCSE
探索数据集
大多数使用了有监督数据的模型效果要好于无监督:
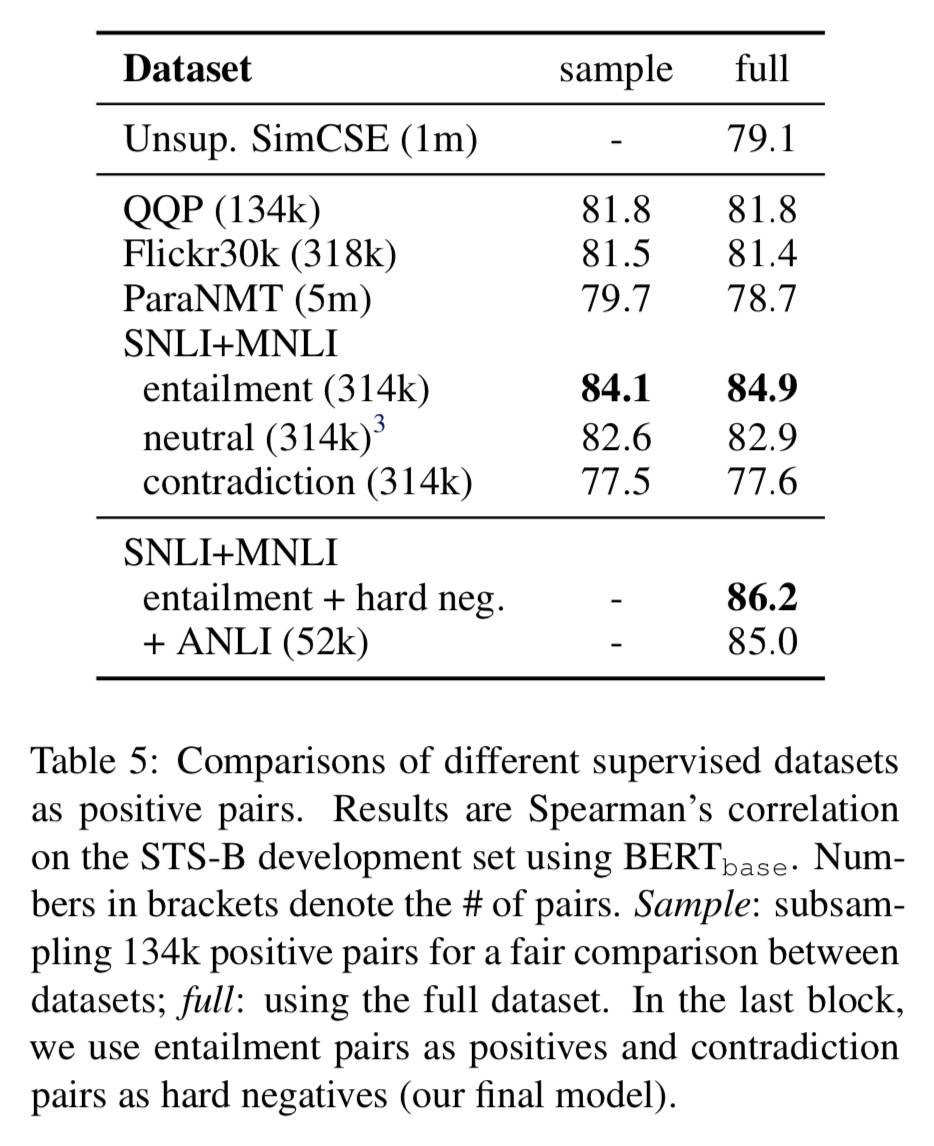
sample 是为了对比公平,采样了同样数量的正例对。
矛盾作为负例
x 为前提,x+ 是蕴涵,x- 是矛盾,Loss 函数:
可以进一步提升性能,见上图(84.9→86.2)。不过添加 ANLI 数据集并没有带来太多提升(85.0)。
与各向异性的关联
语言表示的各向异性问题:即学习到的 Embedding 在向量空间中占据了一个狭窄的锥体,这在很大程度上限制了它们的表达能力。使用绑定的输入/输出 Embedding 训练的语言模型会导致各向异性。
缓解该问题的一个简单方法是后处理,要么消除主要的主成,要么将 Embedding 映射到各向同性分布。或者,可以在训练期间添加正则化。本文的研究表明,对比目标可以内在地 “扁平化” 句子 Embedding 矩阵的奇异值分布。
当负实例的数量接近无穷大时(f(x) 已经归一化),对比学习目标的渐近性可以用以下等式表示:
第一项保持正例相似,第二项将负例对分开。当 Pdata 在有限样例上均匀分布时,根据 hi = f(xi),我们可以用 Jensen 不等式从第二项推导出以下公式:
令 W 为句子 Embedding 矩阵,第 i 行为 hi,忽略常数项,优化第二项本质上最小化了 WW^T 所有元素和的上界。由于已经是归一化的 hi,所有对角线元素为 1,然后是 tr(WW^T),即特征值的和是一个常数。根据 Merikoski(1984),如果 WW^T 的所有元素是正数(大多数情况如此),Sum(WW^T) 是 WW^T 最大特征值的一个上界。因此,当最小化第二项时,其实在减小 WW^T 最大的特征值,固有地 ”扁平“ 了 Embedding 空间的奇异普。因此,对比学习能够潜在地解决表示退化问题并提高均匀性。
实验报告
实验设置
7 个标准的 STS 任务和 7 个迁移学习任务,使用 SentEval 工具包评估。
从预训练 BERT/RoBERTa checkpoint 开始,在 CLS 之上增加一个 MLP 层作为句子 Embedding。
引入一个可选增加一个 MLM 目标作为(1)的一个补充 Loss:
这有助于 SimCSE 避免灾难性地忘记 Token 级知识。
实验结果
语义文本相似度
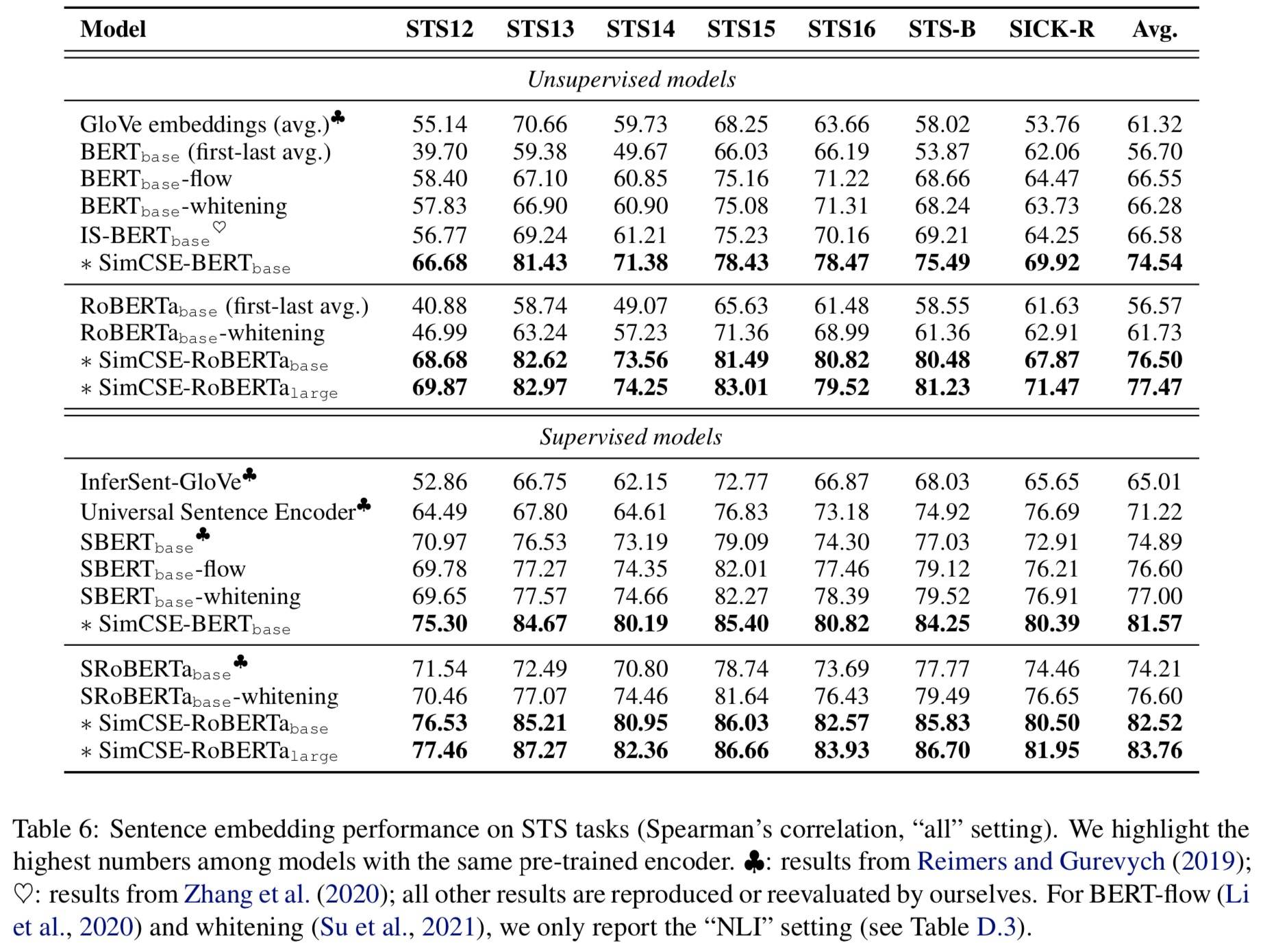
迁移任务
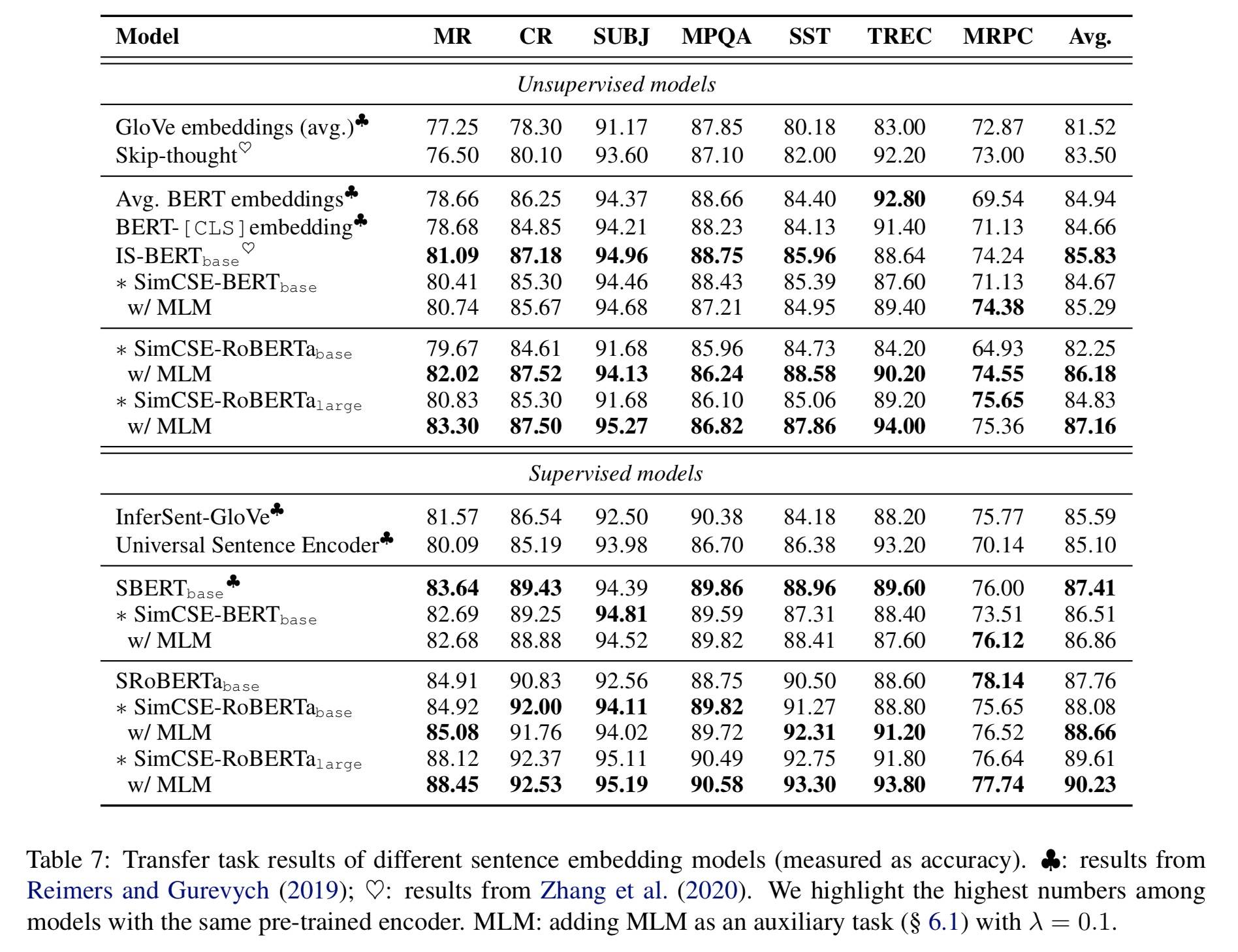
- 有监督的 SimCSE 表现与之前的方法相当或更好,无监督模型趋势不清晰
- MLM 能提升表现,确认了之前的直觉——句子级别目标可能不会直接有益于转移任务
- 研究了后处理方法(BERT-flow/whitening),发现均性能有损;表明良好的表征均匀性不能导致更好的迁移学习 Embedding。
- 迁移任务并不是句子 Embedding 的主要目标,因此把 STS 的结果用于主要比较。
消融实验
- BatchSize:N 增加效果变好,但 512 后不再变好,可能和训练数据量太小有关。
- Pooling 方法:First-Last 平均和 CLS 效果差别不大
- MLM 任务:Token 级 MLM 目标适度提高了转移任务的平均性能,但它带来了语义文本相似任务的一致下降(各种配置下)。
分析
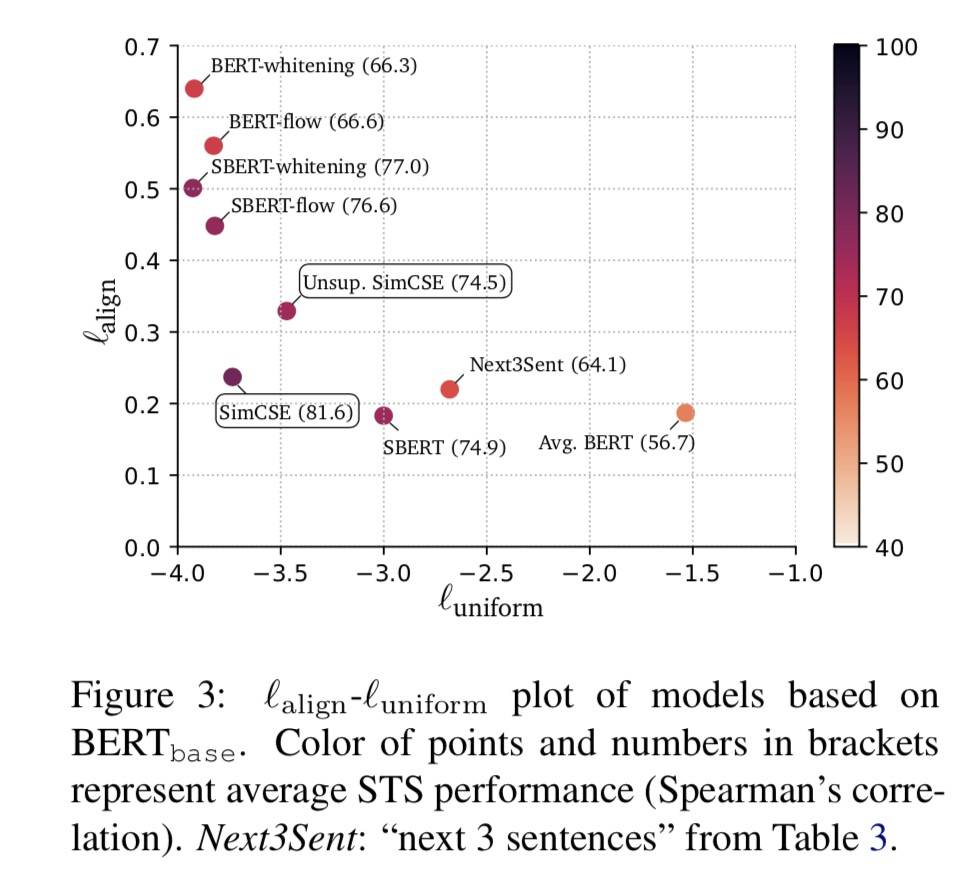
对齐和均匀
- 预训练 Embedding 有好的对齐差的均匀
- 后处理方法改善了均匀但降低了对齐
- 无监督 SimCSE 改善了无监督的均匀同时保持良好的对齐
- 在 SimCSE 中加入监督数据进一步修正了对齐
- SimCSE 可以有效地「扁平化」预训练嵌入的奇异值分布
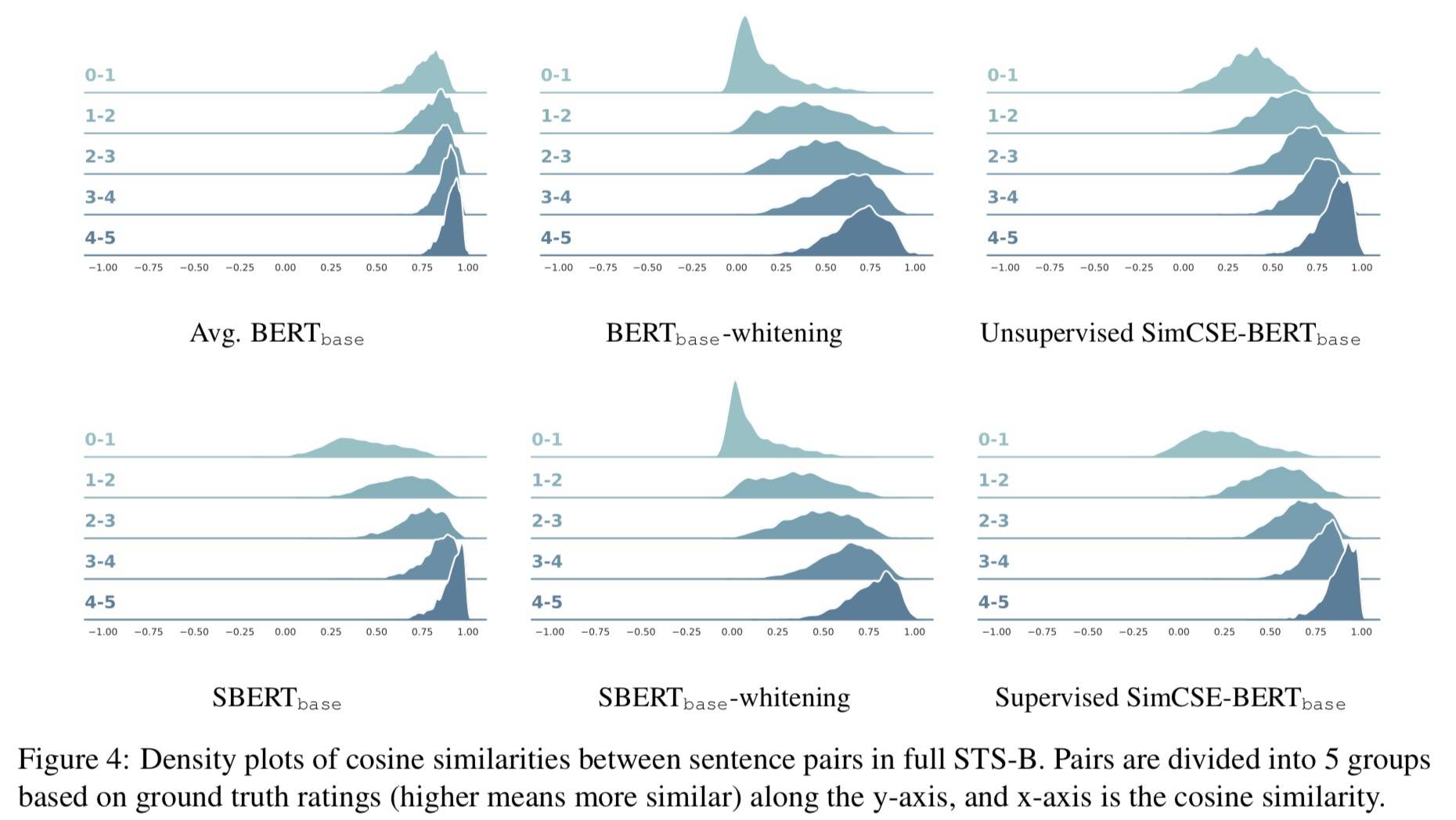
相似度分布
- 所有基线模型相比,无监督和有监督的 SimCSE 都能更好地区分具有不同相似度的句子对,从而在 STS 任务上获得更好的性能。
- SimCSE 通常显示出比 BERT 或 SBERT 更分散的分布,但与白化分布相比,在语义相似的句子对上也保持较低的方差。进一步验证了 SimCSE 可以实现更好的对齐-均匀性平衡。
定性比较
使用 SBERTbase 和 SimCSE-BERTbase 在一个小规模的召回检索实验上进行比较,使用来自 Flickr30k 数据集的 150k 字幕,并以任何随机句子作为查询来检索相似的句子(基于余弦相似度)。结果表明 SimCSE 召回的实例质量更高:

结论
- 提出简单的对比学习框架极大地提升了句子 Embedding 在语义文本相似任务上的表现。
- 使用无监督方法,使用 dropout 噪声预测输入句子本身,以及一种利用 NLI 数据集的监督方法。
- 通过分析 Sim-CSE 与其他基线模型的对齐和均匀性来证明内部运作是合理的。
感想
论文虽说方法简单,但实验还是比较严谨细致的,是篇蛮不错的 Paper;)