Code:reddragon/efficient-dl-survey-paper: Efficient Deep Learning Survey Paper
一句话概述:一份实用的模型训练和部署「优化」指南。
本文主要关注模型效率问题,包括模型技术、基础设施和硬件等,并提供一个基于实验的优化和开发向导。
背景介绍
自从 AlexNet 在 ImageNet 上大放异彩后,图像就进入了预训练时代,随后 VGGNet,Inception,ResNet 不断取得新的 SOTA,不过同时模型也越来越大。自然语言领域要从 Transformer 架构开始,该架构采用自注意力机制,其设计上的可并行性以及强大的表征能力首次让大规模预训练语言模型成为可能。BERT 和 GPT 成为自然语言理解和自然语言生成的代表,无法避免地,效果越好,模型越大——大到成本普通公司连想都不敢想。
此时,对一个深度学习的研究者或一个应用场景的开发者,一系列挑战接踵而来:
- 可持续的服务端伸缩:训练可能是一次性的,推理却是持续性的,且需要大量资源
- 端部署:IoT、智能设备等
- 隐私和数据敏感性:当用户数据可能敏感时,能够使用尽可能少的数据进行训练至关重要
- 新应用:某些新应用程序提供了现有现成模型可能无法解决的新约束
- 模型爆炸:同一基础设施(托管)上为不同的应用程序训练和/或部署多个模型可能最终会耗尽可用资源
高效深度学习主要围绕两个方面:
- 推理高效
- 训练高效
无论优化目标是什么,我们都希望实现帕累托最优。因此,本文建议转向一组算法、技术、工具和基础设施,它们可以协同工作,以允许用户训练和部署关于模型质量和空间占用的帕累托最优模型。
帕累托最优:指资源分配的一种理想状态,假定固有的一群人和可分配的资源,从一种分配状态到另一种状态的变化中,在没有使任何人境况变坏的前提下,使得至少一个人变得更好,这就是帕累托改进或帕累托最优化。——《百度百科》
心智模型
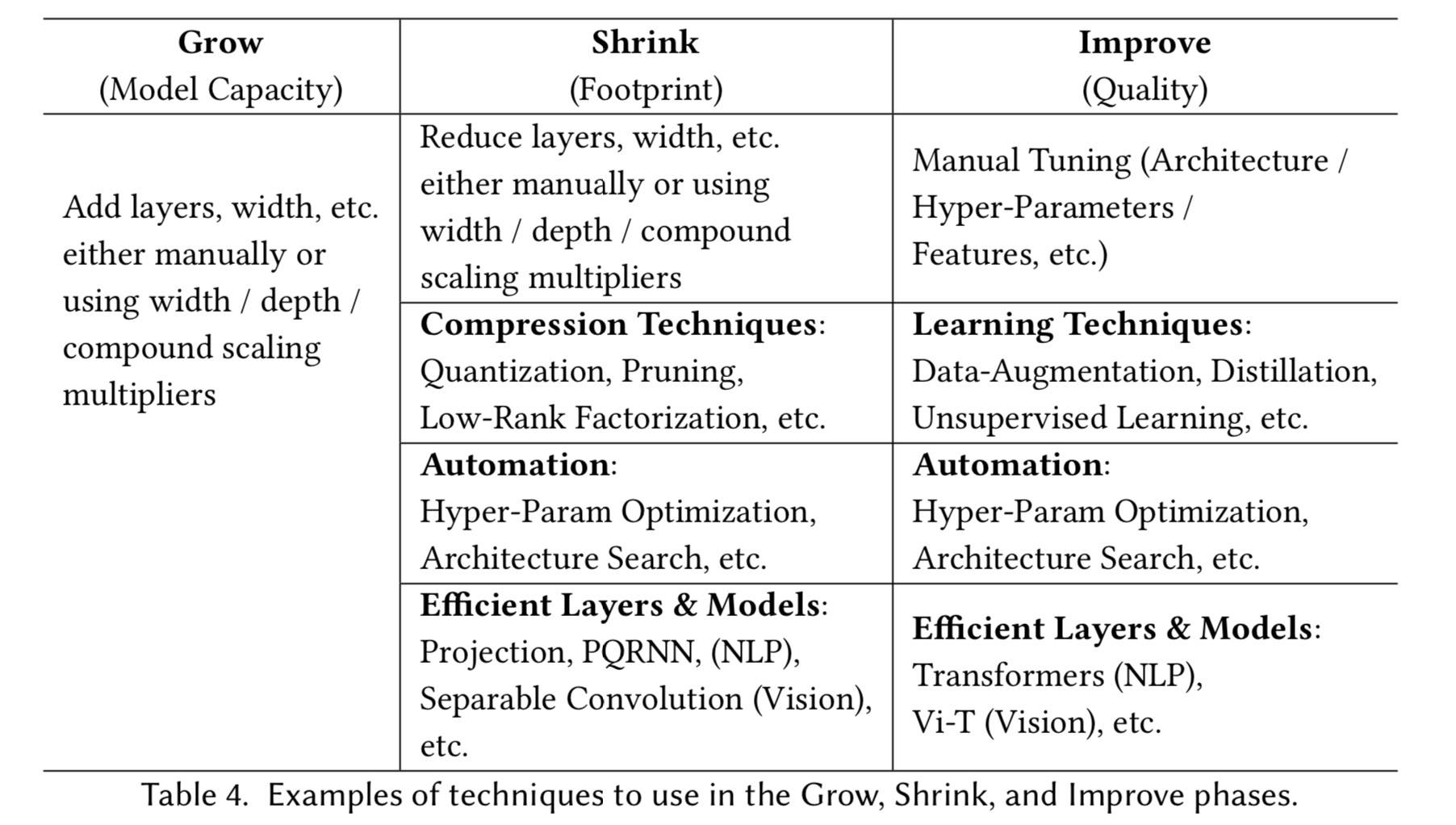
包括五个主要方面,前四个关于建模,后一个关于基础结构和工具。
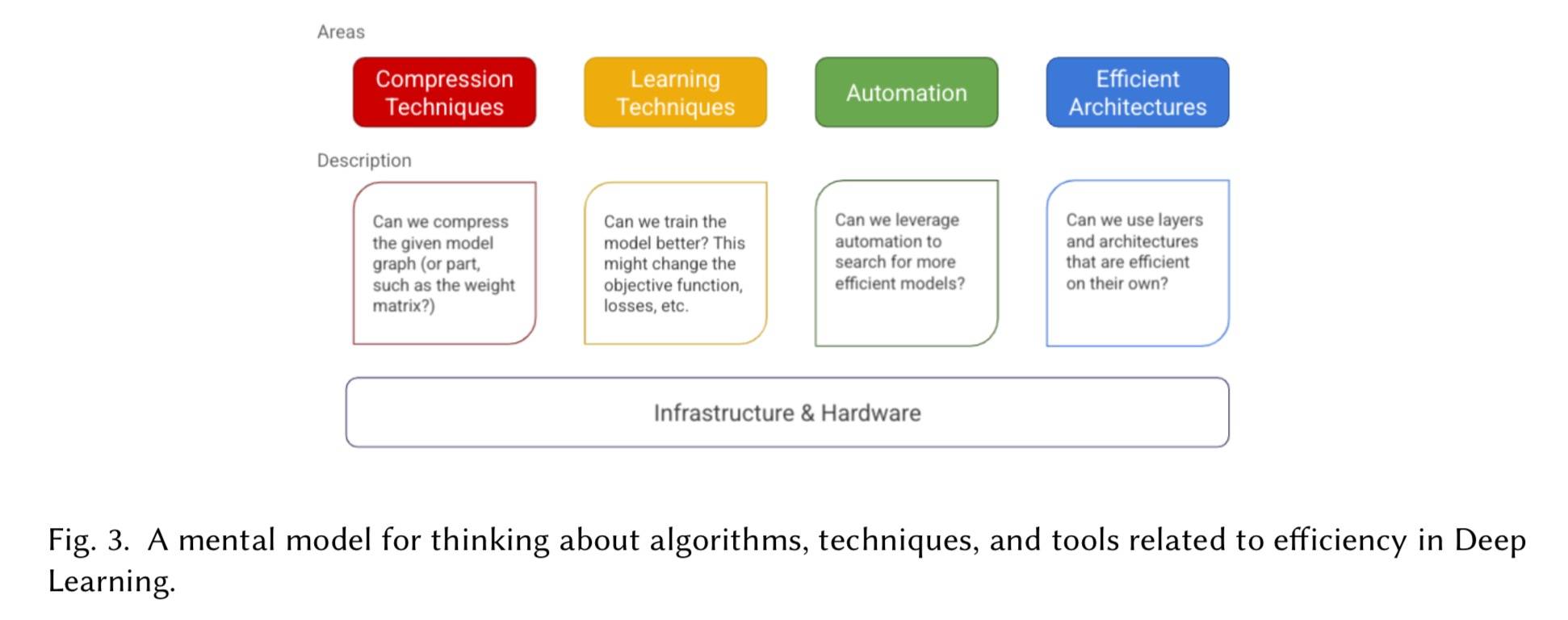
- 压缩技术:如量化
- 学习技术:如蒸馏
- 自动化:如HPO(超参数优化)方法中超参数变成参数数量;架构搜索
- 高效架构:如卷积层、注意力层
- 基础设施:如 Tensorflow、PyTorch 等
高效深度学习
压缩技术
剪枝
剪枝是将部分参数裁剪或变成0,并保证质量在预期的水平。剪枝后的网络也可以说变稀疏。
经典工作 OBD (Optimal Brain Damage,LeCun,Hassibi):先把网络预训练到适度的质量然后迭代地修剪掉「显著性」分数最低的参数。通用算法流程如下:

OBD 使用损失函数对候选移除参数的二阶导来近似显著性分数,其直觉是,给定参数的这个值越高,如果剪掉它后损失函数的梯度变化越大。为加速二阶导计算,OBD 忽略了偏导,直接计算 Hessian 矩阵的对角线元素。LeCun 的研究表明,剪枝可以将参数减少 8x 而不降低分类准确率。
无论哪种剪枝策略,核心算法都是相似的,包括:
- 显著性:二阶导或更简单量级的剪枝,或基于动量的剪枝来决定显著性分数
- 结构或非结构化:
- 非结构(随机)是最灵活的剪枝方法,所有参数都平等对待;可以看作 block size=1 的结构化剪枝
- 结构化剪枝方法,参数在 block 中剪枝(例如在权重矩阵中逐行修剪,或在卷积滤波器中逐通道修剪)
- 分配策略:
- 关于如何分配稀疏预算(要修剪的参数数量),可以通过汇集来自网络的所有参数然后决定要修剪哪些参数,或者通过巧妙地在每层分别选择要修剪的参数
- 一些架构,如 MobileNetV2、EfficientNet 的第一层很薄,这些层对参数的数量没有显著影响,修剪它们会导致精度下降而没有太多增益
- 直觉上,在每层的基础上分配稀疏性是有帮助的
- 调度安排:
- 要剪枝多少?什么时候?
- 每一轮剪掉相等的参数,还是先来个大比例然后逐渐下降?
- 重新增长:
- 重新增长修剪过的连接以通过「修剪 - 重新分配 - 再生长」的恒定循环保持相同水平的稀疏性
- 然而在 CPU、GPU 和其他硬件上实现稀疏操作方面存在差距
超越模型优化
Frankle 等人假设在每个大型网络中都有一个较小的网络,可以通过其参数的原始初始化来提取该网络,并自行重新训练以匹配或超过较大网络的性能。Liu 等人则证明具有随机初始化的剪枝架构并不比具有训练权重的剪枝架构差。
讨论
- 一大部分是无结构剪枝,但还不清楚这些改进如何导致指标下降
- 另一方面,具有有意义的块大小的结构化修剪有利于延迟改进(Elsen 等人的研究)。他们通过将 NHWC(channels-last)标准稠密表征转化为一个特殊的 NCHW(channels-first)「Block Compressed Sparse Row」(BCSR)表征。总体而言,这是使用剪枝网络实际提高指标迈出的有前途的一步。
量化
降低权重和激活的精度(经常是 8-bit 定点整数——VS. 32-bit):更小的模型 size 和更低的推理延迟。
权重量化
给定 32 位浮点数参数矩阵,将最小的权重值设为 0,最大的设为 2**b - 1,b 是精度的位数,然后就可以将所有的值变成一个整数(0 到 2**b - 1):
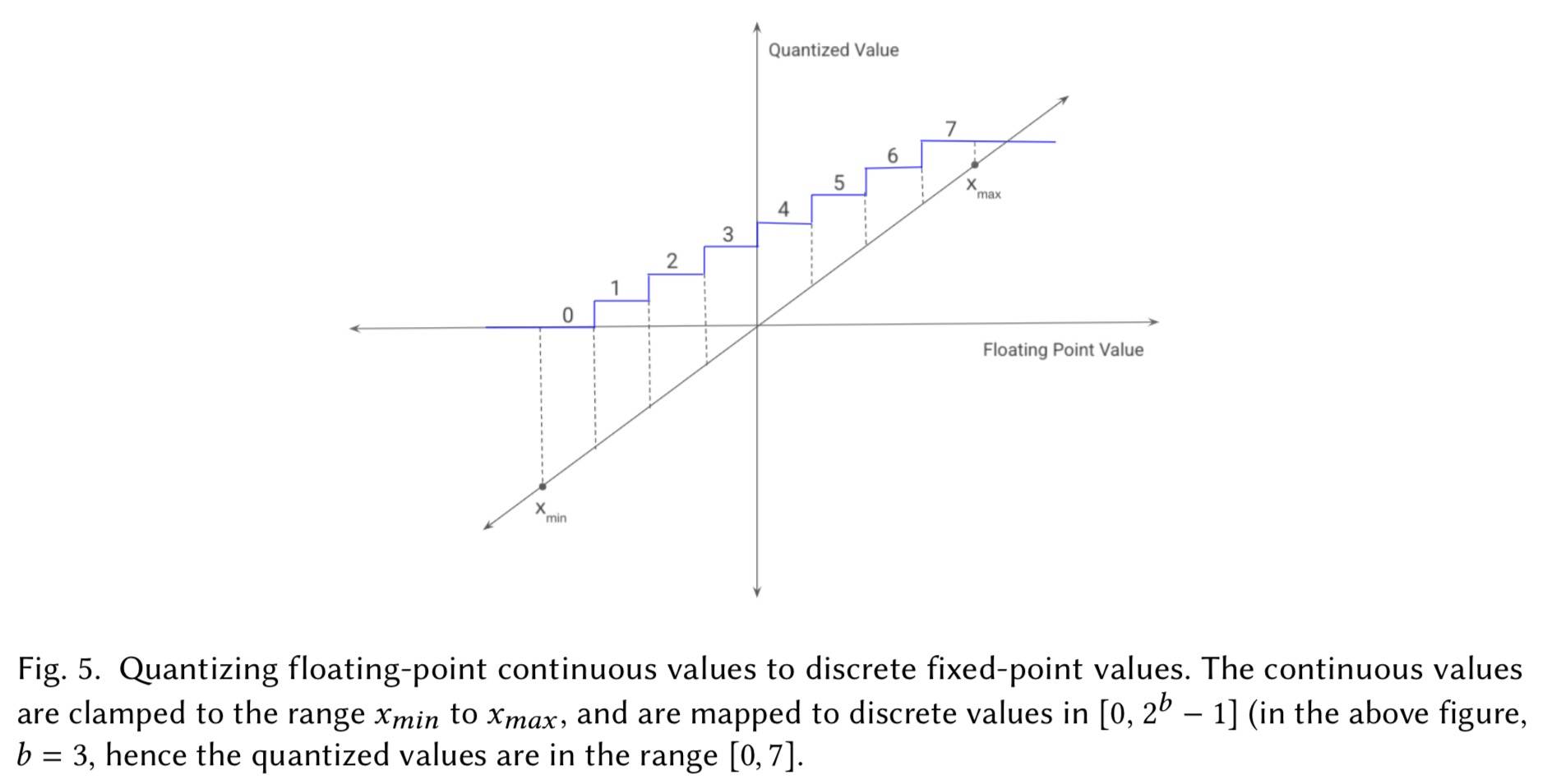
这种方法也可以处理负数,范围是 -2**b - 1 到 2**b - 1。在推理阶段,正好是相反的过程。
量化方案的两个约束:
- 量化方案应该是线性的(仿射变换),这样精度位是线性分布的
- 0.0 应该映射到一个定点值 𝑥𝑞0,去量化 𝑥𝑞0 时返回 0.0,这是一个实现约束,因为 0 也用于填充来表示张量中缺失的元素,如果去量化 𝑥𝑞0 导致非零值,那么它可能会被错误地解释为该索引处的有效元素
量化过程如下:
s 是浮点刻度值,z 是一个整数零点值,它是分配给 x = 0.0 的量化值。
精度有损的去量化过程:
算法过程如下:

量化预训练模型的权重以减小尺寸在文献中被称为训练后量化。
其他变体:
- XNOR-Net,Binarized Neural Networks 使用 b=1,量化函数就是简单的 sign 函数
- 一个信息量更大的任务是在较小的网络上演示极端量化
- 此外,二进制量化(以及其他量化方案,如三元、基于位移的网络 等)有望实现标准运算的延迟高效实现,其中乘法和除法被更开销更低的的运算(如加法、减法)替换。不过这些方案还是理论的,实现需要硬件支持。
- 所以更公平的方案是使用 b=8 的标准量化,乘法和除法开销低,硬件通过 SIMD 得到支持,这些指令还允许低级数据并行。
激活量化
为了能够通过量化网络获得延迟改进,数学运算也必须在定点表示中完成。这意味着所有中间层的输入和输出也是定点的,并且不需要对权重矩阵进行反量化,因为它们可以直接与输入一起使用。权重的量化与与训练后量化类似,不过所有层的输入(第一层除外)和激活都是定点的。
量化感知训练
即 Quantization-Aware Training (QAT)。随着网络变得更加复杂,训练后量化可能会导致推理过程中的质量损失。其原因是:
- 异常权重使整个输入范围的量化值的计算偏向异常值,导致分配给大部分范围的比特数减少
- 权重矩阵内权重的不同分布,例如在卷积层中,每个过滤器之间的权重分布可能不同,但量化方式相同
为此,Wang 等人尝试保留训练后量化,但使用新的启发式方法以学习的方式分配精度位。 TFLite Converter 等工具使用用户提供的代表性数据集来增强训练后量化,通过比较量化和未量化图的激活之间的误差来主动纠正模型中不同点的误差。
Jacob 等人提出一种量化感知的训练机制。在此设置中,训练以浮点形式进行,但前向传递模拟推理期间的量化行为。权重和激活都通过一个模拟这种量化行为的函数传递。假设 X 是要进行伪量化的张量,他们建议在训练图中添加特殊的量化节点,以收集与要量化的权重和激活相关的统计信息。如下图所示:
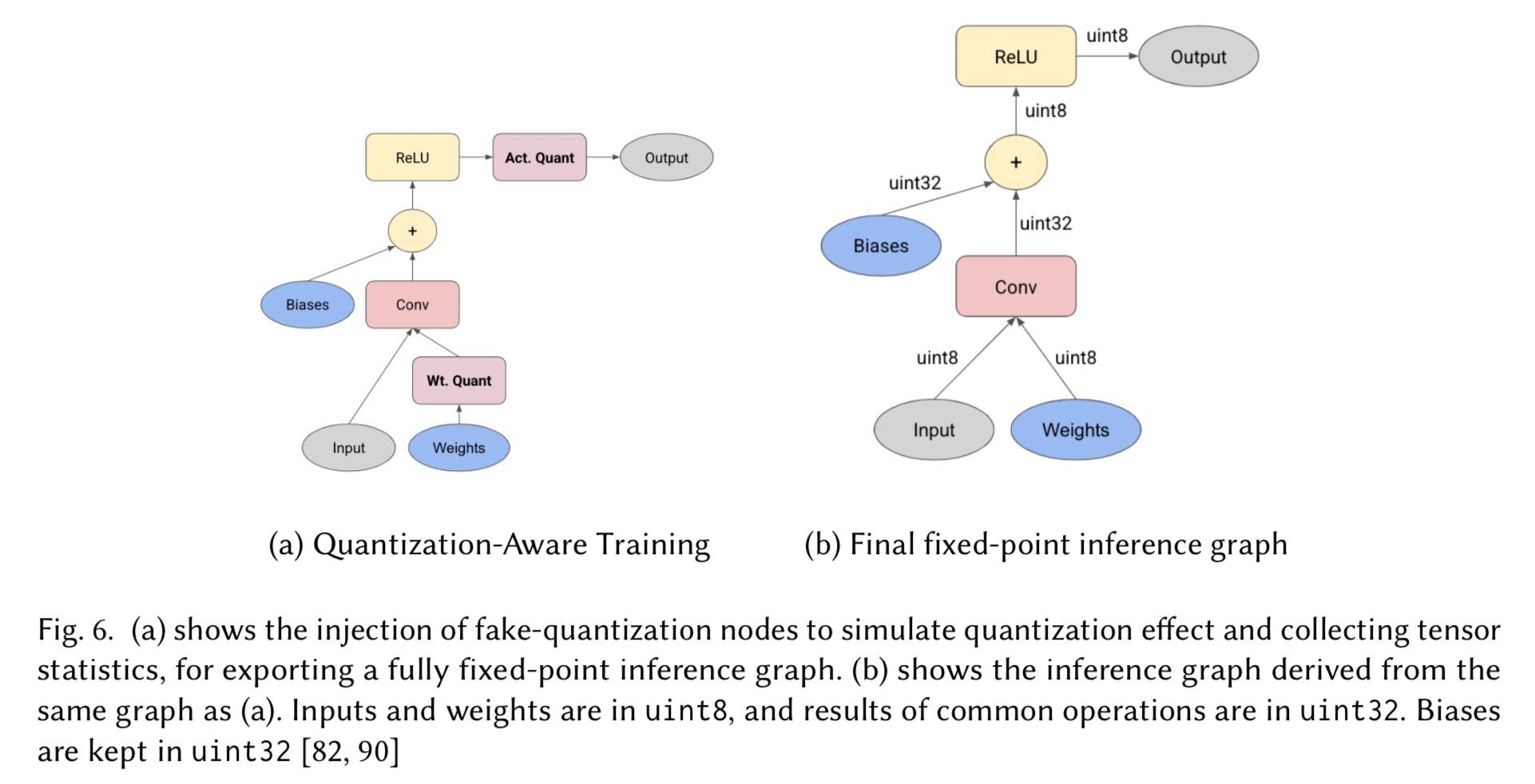
一旦有了相关统计信息就可以利用公式(1)和(2)为每个 X 计算 X’:
QAT 使网络能够适应推理期间由固定(clamp)和舍入行为引入的噪声。
其他显著工作
- Polino 等人通过学习量化点向量 𝑝 允许精度的非均匀分布,同时使用蒸馏来进一步减少精度损失。
- Fan 等人证明了在标准 QAT 基础上提高了 𝑏 < 8 的精度。他们假设,如果不将伪量化同时应用于完整张量以允许无偏梯度流动,则网络将学习得更好(而不是 STE 近似)。相反,他们在给定的张量上以块方式随机应用伪量化操作。他们还在 4 位量化 Transformer 和 EfficientNet 网络上展示了对 QAT 的改进。
结果
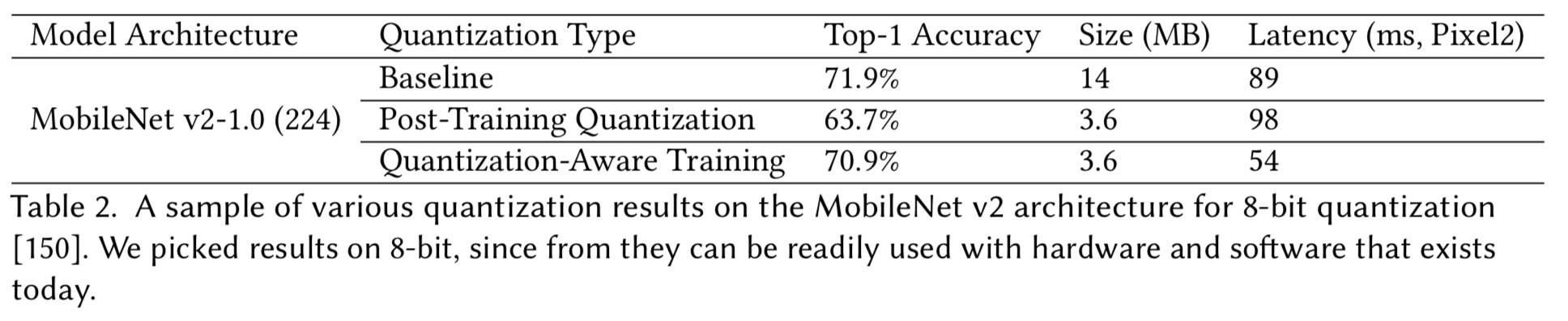
讨论
- 量化能够有效降低模型大小和推理延时
- 尤其要考虑激活量化,它既可以降低延迟,同时降低模型中间计算的内存占用
- 如果可能,应使用量化感知训练
- 然而 TF-Lite 这样的工具让训练后量化变得容易
- 最好考虑遵循典型层常见操作,如 Batch-Norm,Activation 等
其他压缩技术
- Low-Rank Matrix Factorization
- K-Means Clustering
- Weight-Sharing
学习技术
尝试以不同的方式训练模型,一个很好的特点是仅用于训练,不影响推理。
知识蒸馏
三个臭皮匠顶个诸葛亮,集成有助于泛化。标准方法包括:bagging、boosting、averaging 等。有研究发现单个神经网络能够模拟大的集成,同时体积更小速度更快。
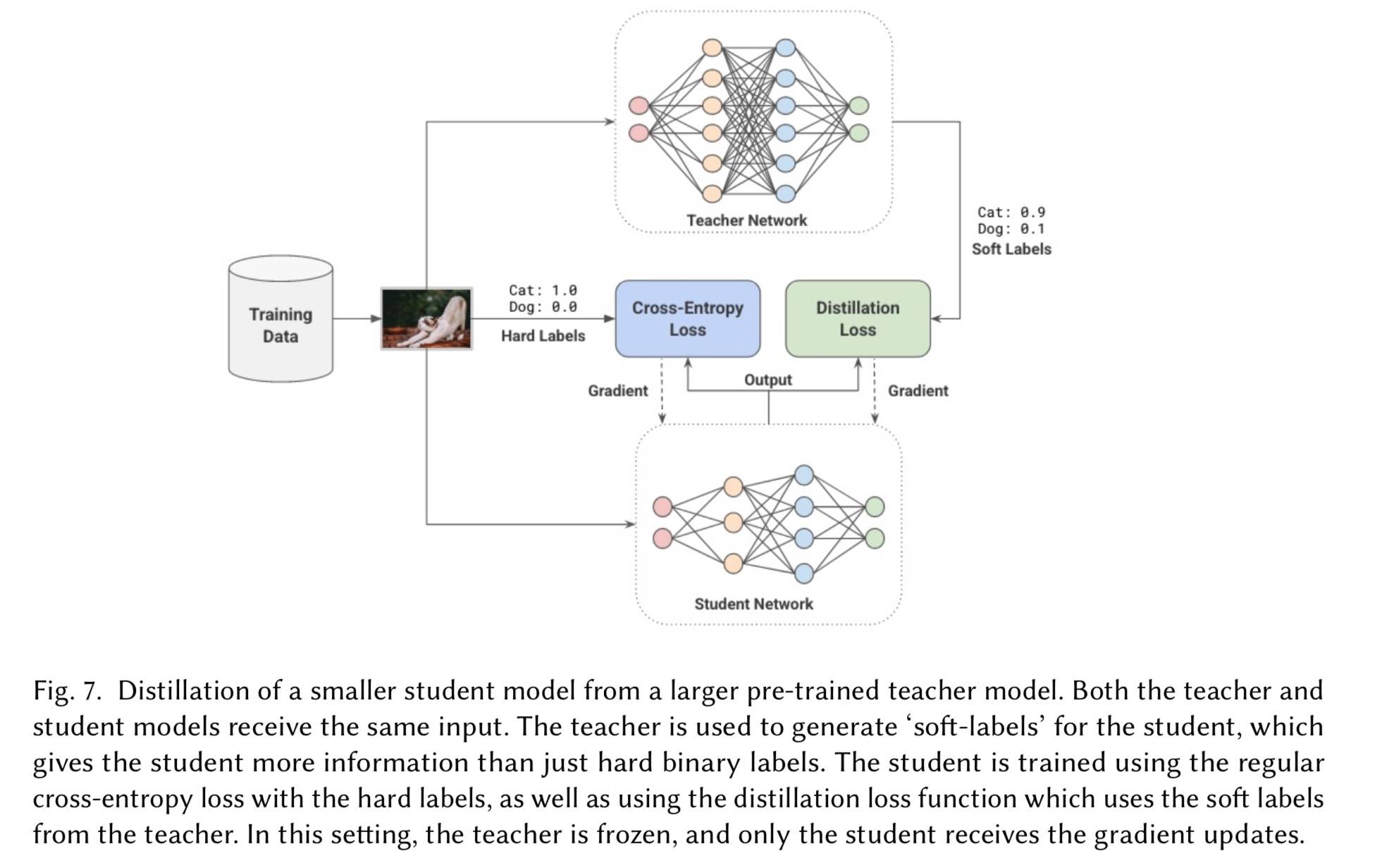
Hinton 等人的研究发现,学生网络以一种略微不同的方式从教师模型(大模型、集成模型等)中抽取知识,它使用大模型在现有标记数据上生成软标签(logits),而不是硬的二分类。这里有个直觉,软标签捕获了不同类之间的关系,这是大模型所没有的。
学生模型在软标签和硬标签上最小化交叉熵损失,错误分类的概率被软化,可能非常小,T ≥ 1.0 是缩放值:
T 越大,不同分类的相对不同减小。这是因为原始的 softmax 会让较大的值有较大的下降,有了 T 后,T 增加时,分布变得更加【软化】。看起来大概就是这样:
1 | import numpy as np |
损失函数为:
第一个交叉熵是和真实标签的,第二个是和教师软标签的。
一些研究
- 蒸馏输出
- Hinton:1个蒸馏模型顶10个集成模型
- Urban:浅层网络如单隐层MLP效果显著
- Sanh:DistilBERT
- 蒸馏中间结果
- Zagoruyko:蒸馏教师 attention map 到学生卷积网络
- MobileBERT:逐层分阶段蒸馏
- 标注未标注数据
- 监督模型标注无标注数据
- 用教师模型对大规模无标注数据进行标注,提升学生模型质量
讨论
- 对训练改动很小,即使不能用于推理,离线收集预测结果也可以作为标签来源
- 可以用来生成伪标签,提高学生模型准确率
- 中间层蒸馏在复杂网络下有效,需要添加新的损失项,最小化两个网络在某些语义相同的中间点的输出之间的差异
数据增强
标注数据与准确率呈对数关系。一段时间主要用于图像领域,方法包括:
- 标签不变转换:几何变换,包括平移、翻转、裁剪、旋转、扭曲、缩放、修剪等。
- 标签混合转换:Mixup,Sample Pairing
- 数据依赖转换:最大化损失,或欺骗分类器
- 合成采样:SMOTE,GANs
- 组合转换:多种方法组合
讨论
- NLP 领域:
- 回译
- WordDropout:随机设置一些词的 embedding 为 0
- SwitchOut:不允许数据增强和原始输入太不相同
- AutoAugment:增强策略通过 RL 基于搜索学习,搜索能应用的变换(复杂且昂贵)
- RandAugment:一些给定模型和数据上,减少搜索空间到 2 个超参能达到相近的结果
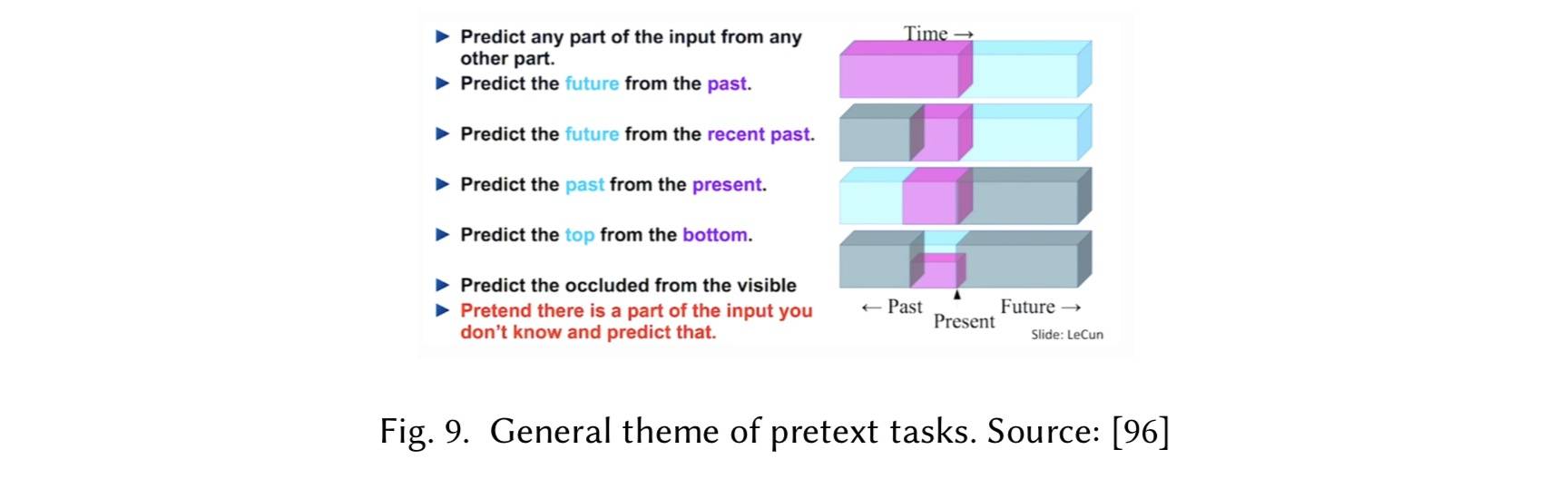
自监督学习
聚焦在学习样例自身的表征上,通过解决 pretext 任务(模型假装一部分输入丢失然后去预测)实现:
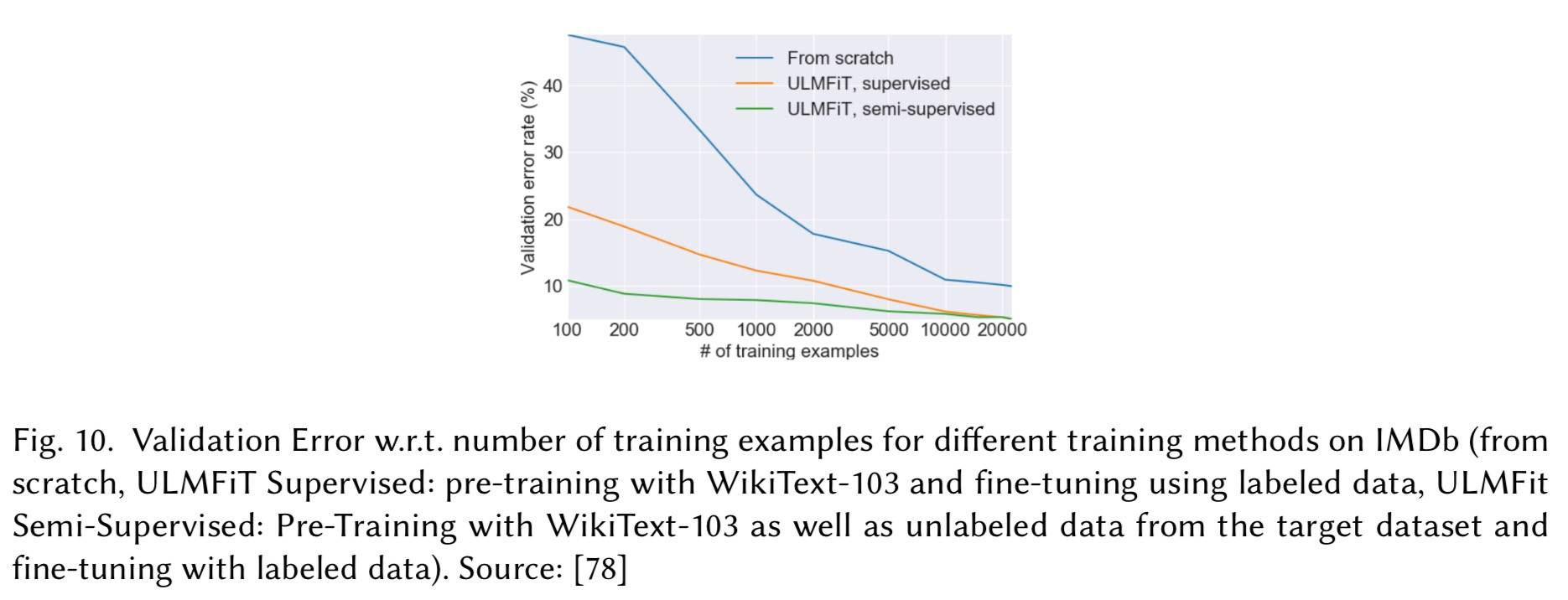
从预训练模型开始微调训练是数据高效的(同等数量标注数据收敛更快、效果更好):
另一个常见主题是对比学习,模型用来训练区分相似和不相似的输入,比如 SimCLR。
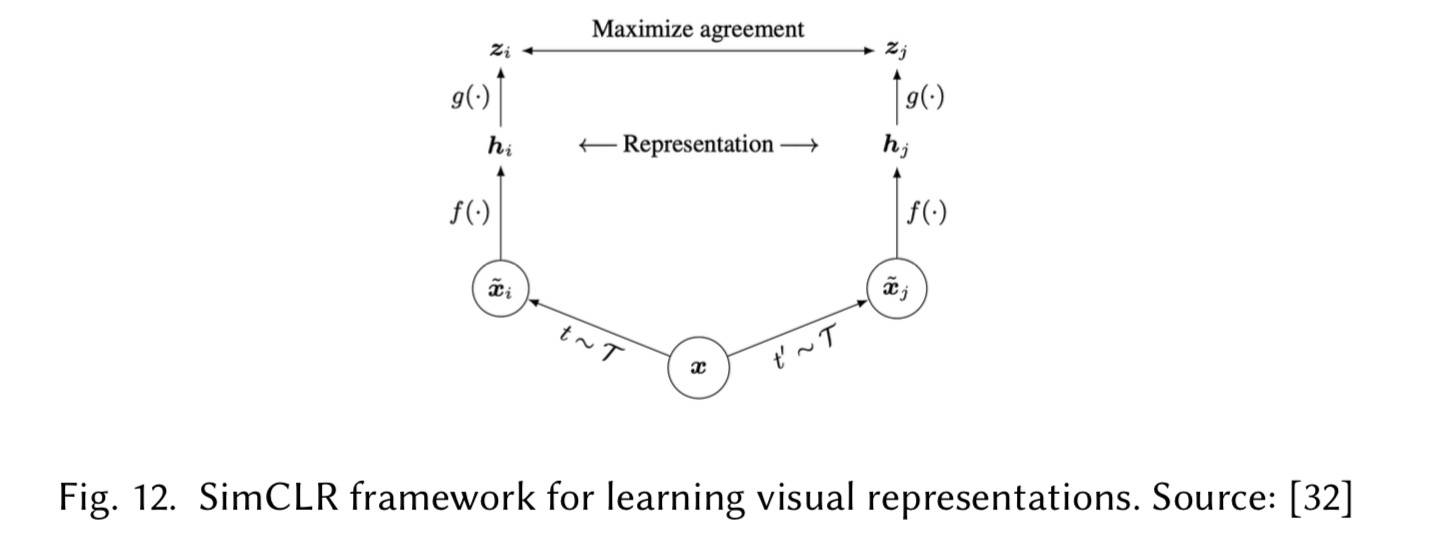
SSL 效果明显,甚至超越了之前最好的监督方案,已经成为行业标准和里程碑。
自动化
自动寻找训练更有效模型的方法,不仅能减少工作,而且能降低人工决策的偏好,不过就是太耗费资源了。
HPO
Hyper-Parameter Optimization,主要是调整超参数。由于所有可能的组合太多,所以一般会选择一个有限的尝试集合,这个集合的构建需要人工先验经验。
HPO 有三种方法:
- Grid Search:搜索所有离散有效的组合,会面临维度诅咒,组合数量随着参数的增加会暴增
- Random Search:随即从搜索空间采样,好处包括:
- 相比网格搜索,搜索策略可以随时更改
- 随着尝试次数增加,相比网格搜索找到最优参数的概率越大
- 在搜索空间有效维数较低的情况下,随机搜索的性能优于网格搜索
- Bayesian Optimization
- 目标函数的估计是使用从先验估计开始的代理函数来完成的
- 基于模型、顺序
- 引导而不是随机
一种节省训练资源的策略是:提前停止不靠谱的试验。比如 Google 使用 Median Stopping Rule,如果一个试验在 t 步还没达到其他试验该步的中位表现,则停止试验。
其他 HPO 相关算法包括:
- PBT:Population Based Training,类似进化算法,包括 exploitation 和 exploration。Exploitation 阶段,固定数量的试验从一组随机超参开始,训练提前设置好的步数,然后用此时效果最好的参数和权重替换其他所有的参数和权重;Exploration 阶段,这些超参数从它们的原始值被扰动。 这个过程重复直到收敛。。关于 Exploitation 和 Exploration 可以参考:Bandit。
- 多臂老虎机算法:类似 Successive Halving 和 Hyper-Band 方法与随机搜索类似,但是它们对表现好的试验分配更多的资源。
相关工具:
- Google Vizier:Vizier 概览 | AI Platform Vizier | Google Cloud
- Amazon Sagemaker:Amazon SageMaker 机器学习_机器学习模型构建训练部署 - AWS 云服务
- Microsoft NNI:microsoft/nni: An open source AutoML toolkit for automate machine learning lifecycle, including feature engineering, neural architecture search, model compression and hyper-parameter tuning.
- Ray Tune:Tune: Scalable Hyperparameter Tuning — Ray v2.0.0.dev0
- Microsoft Advisor:Optimization advisor overview - Finance & Operations | Dynamics 365 | Microsoft Docs
还有参考至《机器学习实战》中提及到优化超参数的库(及部分其他补充):
- hyperopt/hyperopt: Distributed Asynchronous Hyperparameter Optimization in Python
- maxpumperla/hyperas: Keras + Hyperopt: A very simple wrapper for convenient hyperparameter optimization (已存档)
- Avsecz/kopt: Hyper-parameter optimization for Keras(一阵没更新了)
- autonomio/talos: Hyperparameter Optimization for TensorFlow, Keras and PyTorch
- Introduction to the Keras Tuner | TensorFlow Core
- rsteca/sklearn-deap: Use evolutionary algorithms instead of gridsearch in scikit-learn(一阵没更新了)
- HIPS/Spearmint: Spearmint Bayesian optimization codebase(一阵没更新了)
- [1603.06560] Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization
- scikit-optimize: sequential model-based optimization in Python — scikit-optimize 0.8.1 documentation
- fmfn/BayesianOptimization: A Python implementation of global optimization with gaussian processes.
这里的都整理到工具箱了:hscspring/AIToolBox: My AI Basic Tool Box
NAS
Neural Architecture Search,可以看成 HPO 的扩展,从搜索参数到搜索架构本身。NAS 包括以下部分:
- 搜索空间:包括网络及他们之间的连接操作
- 搜索算法&状态:HPO 的标准算法也可以用到这里,不过比较流行使用 Reinforcement Learning 和 Gradient Descent
- 评估策略:常规的 validation loss,accuracy 或者混合的
基本范式:
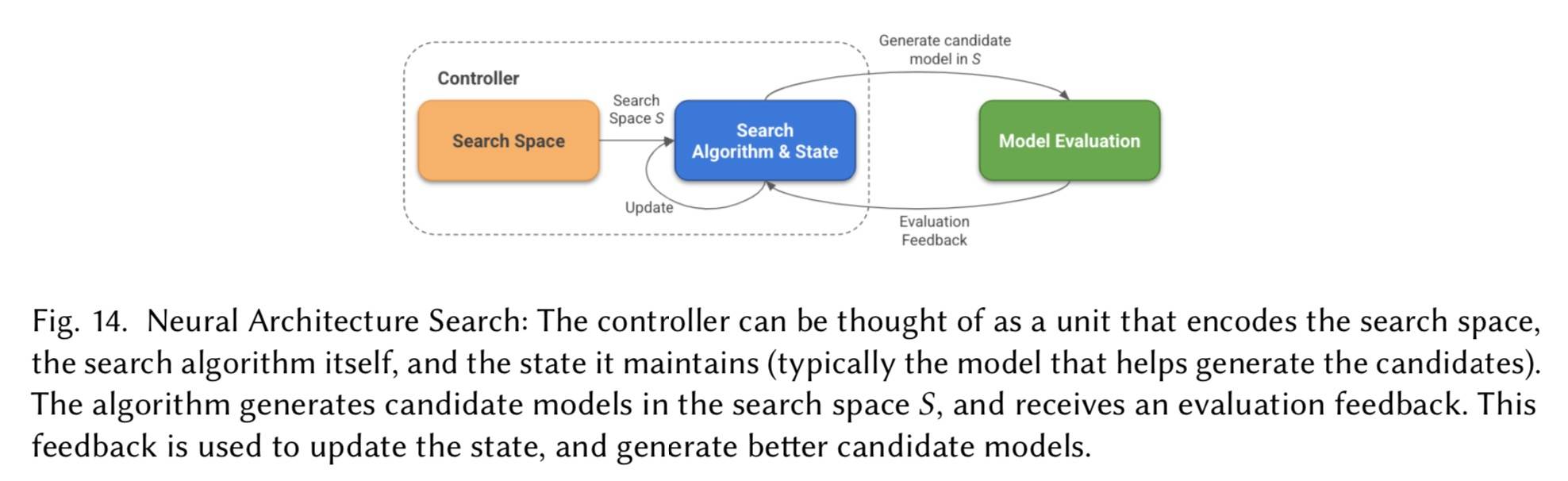
一些进展
-
使用 RL 进行端到端的网络架构生成:Controller 是一个 RNN,每次生成一层前馈网络架构的超参
-
精细的搜索空间,不搜索架构,而是搜索 Cell。比如一个普通 Cell,输出与输入相同的空间维度,而一个缩小 Cell 则输出缩放后的维度。
-
其他减少搜索架构消耗的方法:进化技术、可微架构搜索、渐进式搜索、参数共享等
-
同时关注质量和效率的 Architecture Search
-
MNasNet 在目标函数中直接包含了在目标设备上的延时
其中,T 是目标延时,LAT 是给定模型在设备上的延时,m 是候选模型,w 推荐设为 -0.07
-
FBNet 使用类似方法,使用综合奖励函数,包括验证集上的 loss value 和延时的加权组合。他们没有评估模型在设备上的延时,而是使用了一个预先计算好的 lookup table 来近似延时,进而加速搜索过程
-
MONAS 使用强化学习,将功耗与模型中 MAC 操作数量的硬约束结合到奖励函数中,并在给定的约束下发现帕累托边界
-
讨论
HPO 目前是一个很自然的步骤,消耗大时也可以使用提前停止技术,而且 HPO 的工具也很成熟。类似的,NAS 最新进展也使得以学习的方式构建架构变得可行,同时对质量和占用空间有限制。
高效架构
另一个思路是设计高效的架构。
视觉
卷积
在 FC 基础上的改进。FC 的两个主要问题:
- 忽略了输入中的空间信息
- 容易导致参数爆炸
卷积层通过学习「filter」来避免类似问题:
- 每个过滤器都对输入进行卷积以生成该给定过滤器的特征图
- 较低层的特征简单,后面层会变得复杂,因为后面的特征生成依赖前面的
- 高效的关键点是:同样的 filter 在不断复用
- 经常和 Pooling 层一起,通过对输入二次抽样(max avg)进一步降低维度
深度可分离卷积
主要有两步:
- depth-wise 卷积:一个通道只被一个 filter 卷
- point-wise 卷积:使用 output_channels 个 1×1 的 filter
对一个输入为 100×100×3 的图片,不同架构的参数数量:
| Convolutional | Depth-Separable | |
|---|---|---|
| 输入尺寸 | 100×100×3 | 100×100×3 |
| 输出通道 | 32 | 32 |
| 卷积核尺寸 | 3×3 | 3×3 |
| 参数 | 3×3×3×32=864 | 3×3×3+1×1×3×32=123 |
还可以参考这几篇文章:
- A Basic Introduction to Separable Convolutions | by Chi-Feng Wang | Towards Data Science
- Depthwise separable convolutions for machine learning - Eli Bendersky’s website
- Depthwise 卷积与 Pointwise 卷积 - 知乎
NLU
Attention 机制和 Transformer 家族
Seq2Seq 将 encoder 压缩成一个 context 向量并用于 decoder 的每一步,decoder 经常需要从中推理出整个 encoder 序列,这成为一个瓶颈。
Bahdanau 的 Attention 可以为每一个输出的 token 创建一个个性化的 context,具体是基于输出 token 对齐到每一个输入 token 生成一个加权 context。
aij 是第 i 个 decoder hidden state 和第 j 个 encoder hidden state(hj)的 attention 权重。在 Seq2Seq 架构下,Q 是 decoder 的 hidden state,K=V 是 encoder 的 hidden state,K 和 Q 对应的是 attention 权重。
1 | # From: https://www.tensorflow.org/tutorials/text/nmt_with_attention |
两种不同的计算方式:
其中,s 表示 source,t 表示 target。更多关于 Attention,可以参阅:Luong Attention 论文 + 代码笔记 | Yam
2017 年 Transformer 引入 Self-Attention 机制,Q=K=V,可以并行,取代 RNN 成为新的特征提取器。随后,基于此的 GPT、BERT 系列至今延续着辉煌。关于高效 Transformer 可以参考 Google 之前的一篇 Paper:[2009.06732] Efficient Transformers: A Survey
随机投影层 & 模型
词向量是会随着词表增大存储空间线性增加的,基于 Random Projection 的方法就是对 Embedding Table 进行压缩,或围绕这个需求评估层和模型的方法。该方法通过将输入特征映射到较低纬度来替换 embedding table 和 lookup。每个随机投影操作使用 LSH(局部敏感哈希),主要的好处是空间复杂度降低,从O(V,d) 降到O(T),其中 T 表示 T 个散列函数,同时计算复杂度从原来的 O(1) 变为 O(T)。
一些基于投影的模型:
- PRADO:从投影输入生成 n-gram 特征,然后在顶部有一个多头注意层
- PQRNN:在投影特征之上额外使用了快速 RNN 实现
- Proformer:引入一个 LPA(局部投影注意力)层,将投影操作与局部注意力相结合
基础设施

Tensorflow 生态
低资源环境的 Tensorflow Lite,从高 Level 可以将 TFLite 分成两个主要部分:
- 解释器和操作内核:针对 ARM 处理器的推理进行了优化
- 转换器:将 TF 模型转为单个 flatbuffer 文件,以供解释器进行推理
其他用于设备端推理的工具
- TF Micro:由一个精简的解释器和一组较小的操作组成,用于在非常低资源的微控制器上进行推理。
- TF Model Optimization toolkit:一个 Tensorflow 库,用于应用常见的压缩技术,如量化、修剪、聚类等。
- TF.JS:用于在浏览器中或使用 Node.js 训练和运行神经网络。
用于服务端加速的 XLA
XLA 是一个图形编译器,它可以通过生成为图形定制的新内核来优化模型中的线性代数计算。 这些内核针对相关模型图进行了优化。
PyTorch 生态
设备上的用例
也有轻量级的框架,以及优化工具。
具体可以看这里:Ecosystem | PyTorch,比 TF 不逞多让。
一般模型优化
PyTorch 还提供即时 (JIT) 编译工具 ,它可能看起来类似于 Tensorflow 的 XLA,但实际上是一种从 TorchScript 中的代码生成模型的可序列化中间表示的机制,它是 Python 的一个子集。 TorchScript 对它可以转换的代码添加了限制,例如类型检查,这使它能够避开典型 Python 编程的一些陷阱,同时与 Python 兼容。它允许在用于研究和开发的灵活 PyTorch 代码与可部署用于生产推理的表示之间建立桥梁。这种表示类似于 TensorFlow 生成的静态推理模式图。
PyTorch 提供了一个模型调优指南,核心思想包括:
- 使用 NVIDIA GPUs 时打开混合精度训练
- 使用 PyTorch JIT 融合 pointwise-operation
- 启用缓冲区检查点允许仅将某些层的输出保留在内存中,并在向后传递期间计算其余层
- 启用特定于设备的优化
- 分布式数据并行训练,每个 GPU 都有自己的模型和优化器副本,并对自己的数据子集进行操作。每个副本的梯度会定期累积,然后取平均值
硬件优化库
通过优化神经网络运行的硬件来进一步提高效率,主要的部署目标是 ARM 的 Cortex 系列处理器。QNNPACK 和 XNNPACK 库针对移动和嵌入式设备的 ARM Neon 以及 x86 SSE2、AVX 架构等进行了优化。 QNNPACK 支持 PyTorch 量化推理模式下的几种常见操作。 XNNPACK 支持 32 位浮点模型和 TFLite 的 16 位浮点模型。Accelerate for iOS 和 NNAPI for Android 试图从更高级别的 ML 框架中抽象出硬件级加速决策。
硬件
GPU
- 最初是为加速计算机图形而设计的
- 2007 年 CUDA 库的可用性以及用于加速线性代数运算的库(如 cuBLAS)开始用于通用用例
- 2009 年 Raina 证明了 GPU 可用于加速深度学习模型
- 2012 年 AlexNet 在 ImageNet 上的改进进一步规范了 GPU 在深度学习模型中的使用
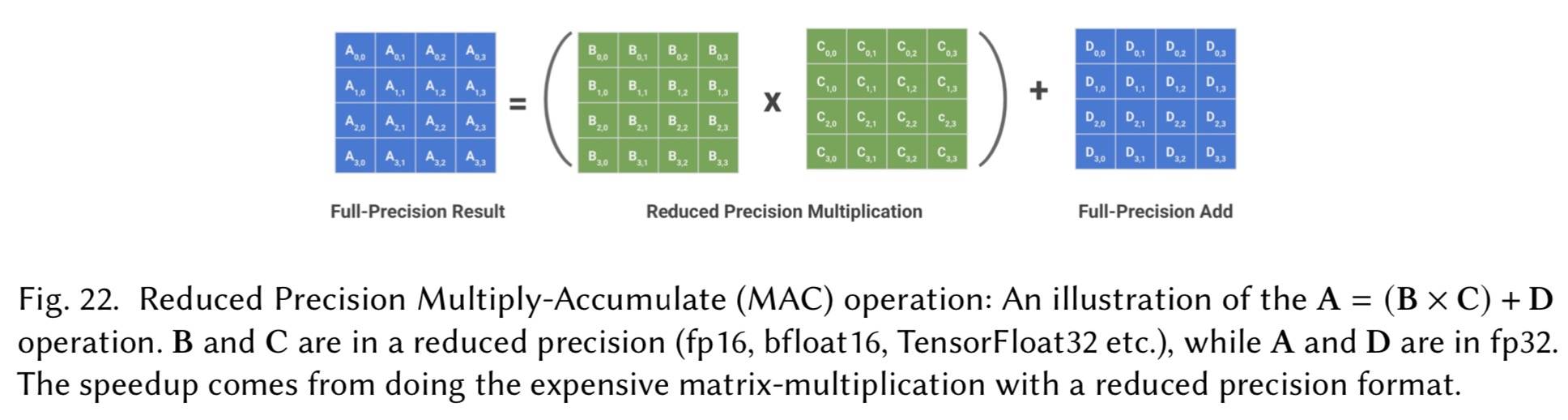
- 引入 TensorCores 专门用于深度学习应用程序, 支持一系列精度的训练和推理
Tensor Cores 优化了标准的乘法和累加 (MAC) 操作:
TPU
TPU 是专有的专用集成电路 (ASIC),谷歌旨在通过 Tensorflow 加速深度学习应用程序,它们被微调以并行化和加速线性代数运算。
TPU 芯片的核心架构利用了 Systolic Array 设计(见下图),其中将大量计算拆分为网格状拓扑,其中每个单元计算部分结果并将其按顺序(每个时钟步,以类似于心脏收缩节律的节奏方式)传递给下一个单元格。由于不需要访问中间结果的寄存器,一旦获取所需的数据,计算就不受内存限制。 每个 TPU 芯片都有两个 Tensor Cores(不是 NVidia 的那个),每个都有一个脉动阵列网格。 一块 TPU 板上有 4 个相互连接的 TPU 芯片。
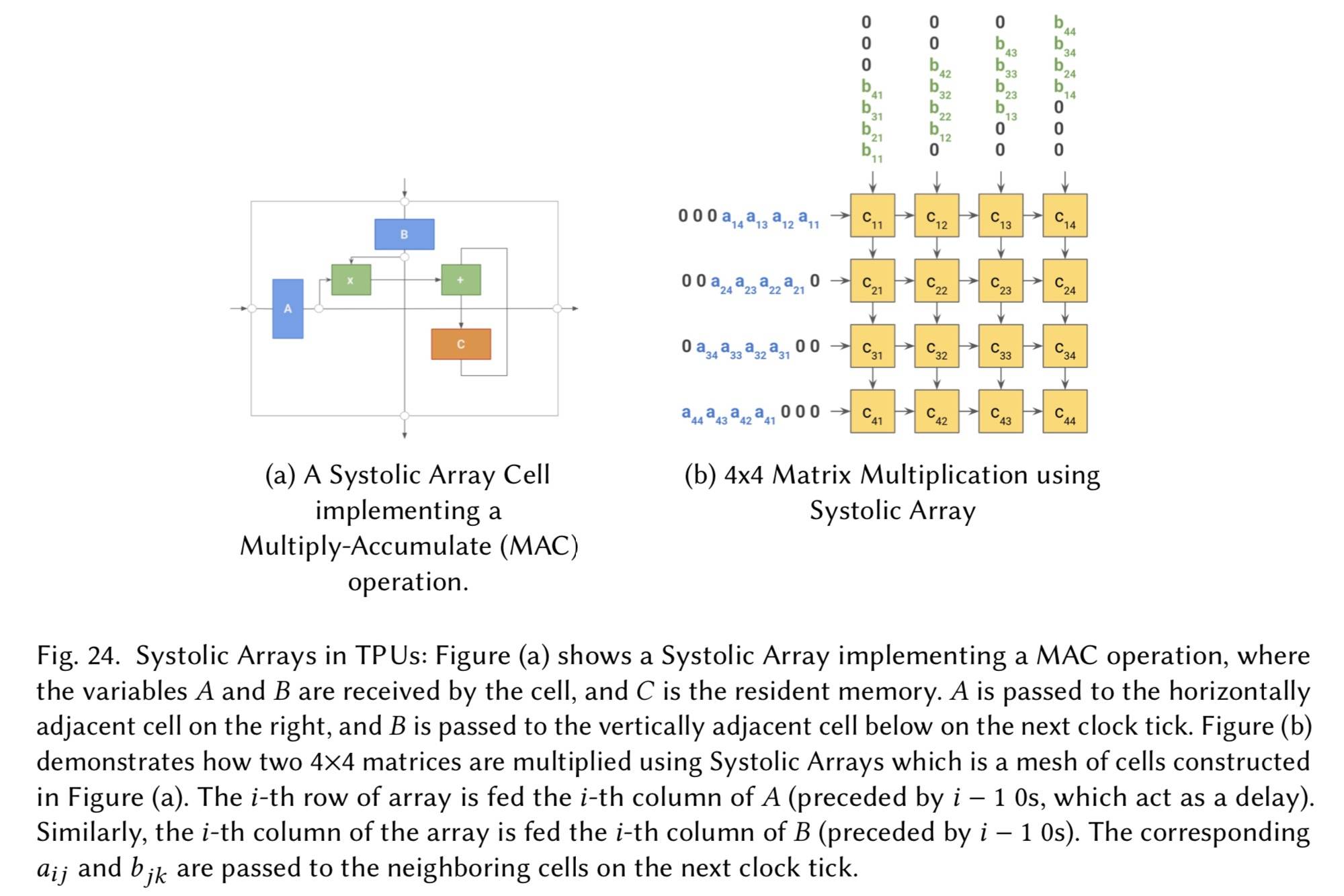
看的稀里糊涂,没有彻底搞懂……
EdgeTPU
EdgeTPU 是谷歌设计的定制 ASIC 芯片,用于在低功耗的边缘设备上运行推理。也是用于加速线性代数运算,但只用于推理。它仅限于部分操作,仅适用于 int8 量化的 TFLite 模型。EdgeTPU 芯片本身比 1 美分硬币还小,因此适合部署在多种物联网设备中。
Jetson
Jetson 是 Nvidia 的一系列加速器,用于为嵌入式和物联网设备启用深度学习应用程序。 它包括 Nano,这是一个为轻量级部署而设计的低功耗 “模块系统”(SoM),以及更强大的 Xavier 和 TX 变体,它们基于 NVidia Volta 和 Pascal GPU 架构。
实践指南

为从业者提供实用指南,以及这些工具和技术如何相互配合。如前所述,我们寻求的是帕累托最优模型,我们希望在一个维度上获得最佳结果,同时保持其他维度不变。 通常,这些维度之一是 Quality,另一个是 Footprint(下面翻译为资源占用)。 质量相关指标可以包括准确度、F1、精度、召回率、AUC 等。而 Footprint 相关指标可以包括模型大小、延迟、RAM 等。
两个策略:
- Shrink-and-Improve for Footprint-Sensitive Models:如果希望减少占用空间,同时保持质量不变,这可能是设备上部署和服务器端模型优化的有用策略。理想情况下,Shrink 应该在质量方面的损失最小(可以通过学习的压缩技术、架构搜索等实现),但在某些情况下,即使是 Naive 地减少容量也可以通过 Improve 阶段来补偿。 也可以在 Shrink 阶段之前进行 Impove 阶段。
- Grow-Improve-and-Shrink for Quality-Sensitive Models:如果想要部署质量更好的模型同时保持相同的资源占用时,遵循此策略可能是有意义的。 在这里,首先通过 Grow 模型来增加容量,如前面所示。然后使用学习技术、自动化等改进模型,然后 Naive 地或以学习的方式 Shrink。 或者,模型也可以在模型 Grow 后直接以学习的方式 Shrink。
实验
实验目标:
- 使用效率技术实现新的帕累托最优,证明这些技术可以单独使用或与其他技术结合使用。
- 通过效率技术和模型缩放的各种组合,展示用于发现和遍历帕累托边界的「Shrink-and-Improve」和「Grow-Improve-and-Shrink」策略的权衡。换句话说,提供经验证据证明可以减少模型容量以减少资源占用(Shrink)然后恢复他们权衡的模型质量(Improve);或者增加模型容量以提高质量(Grow) 然后进行模型压缩(Shrink)以改善模型资源占用。
实验的 code 在这里:efficient-dl-survey-paper/CIFAR_10_End_to_End.ipynb at main · reddragon/efficient-dl-survey-paper,我们直接看结果:
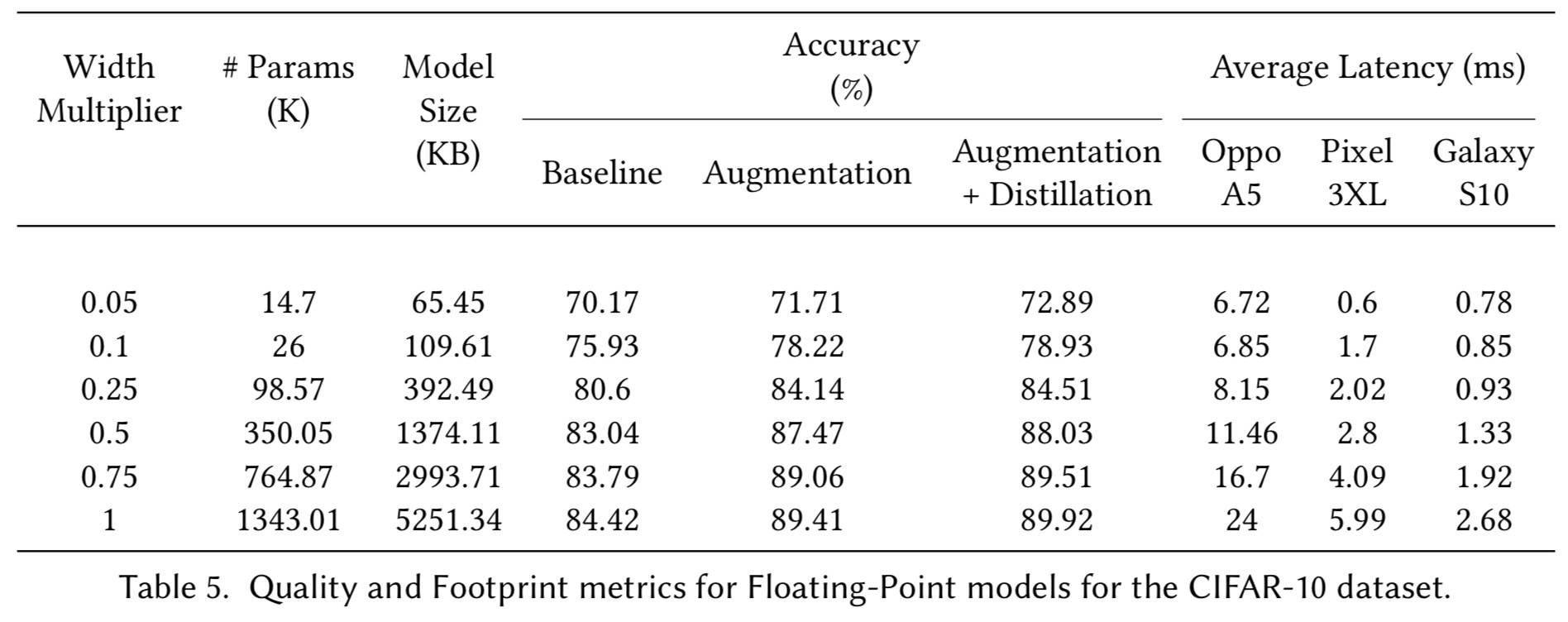
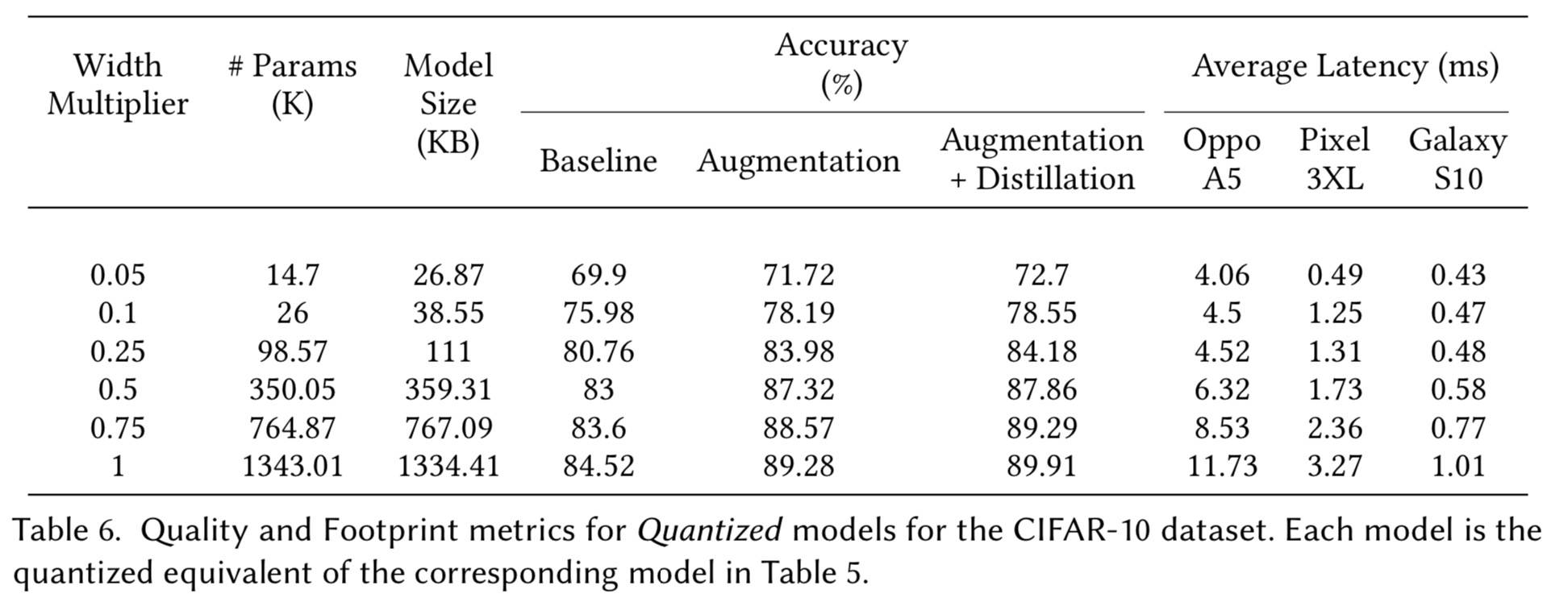
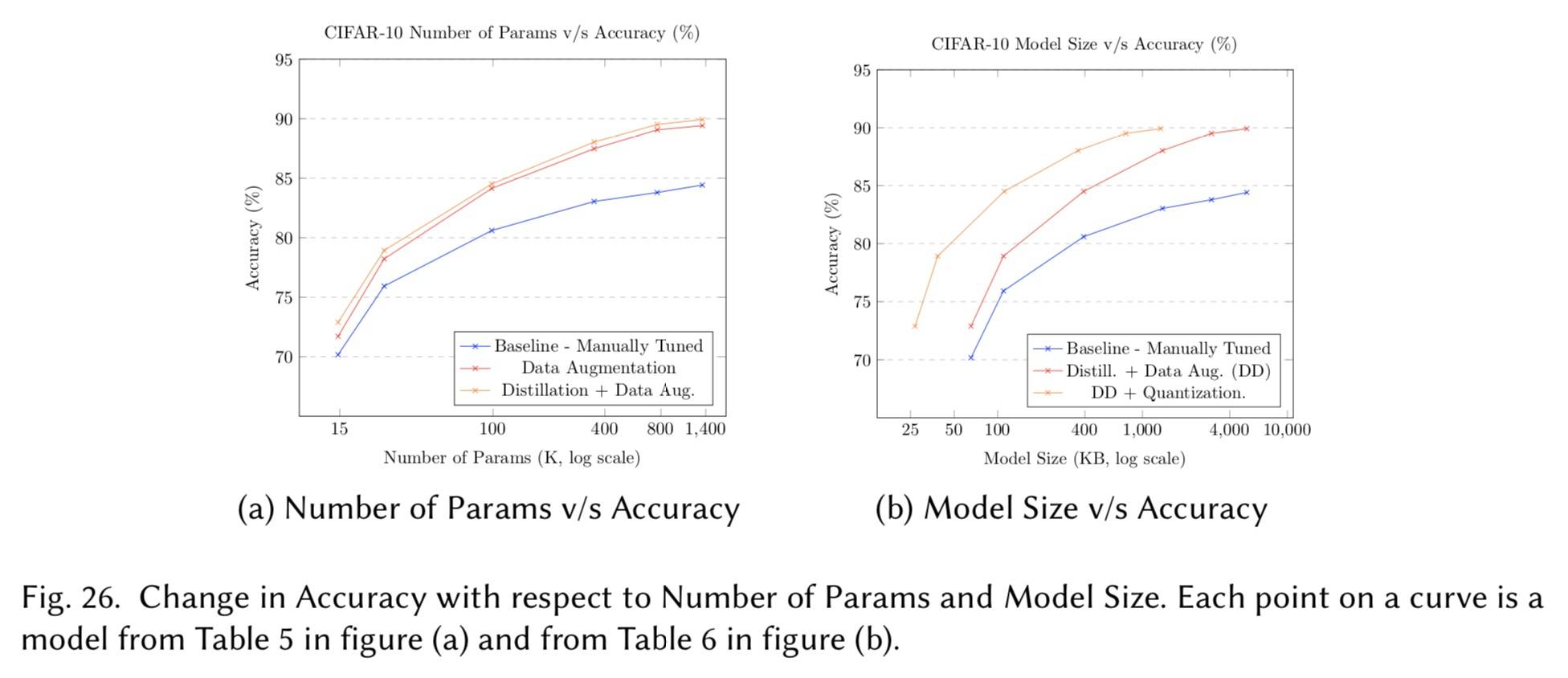
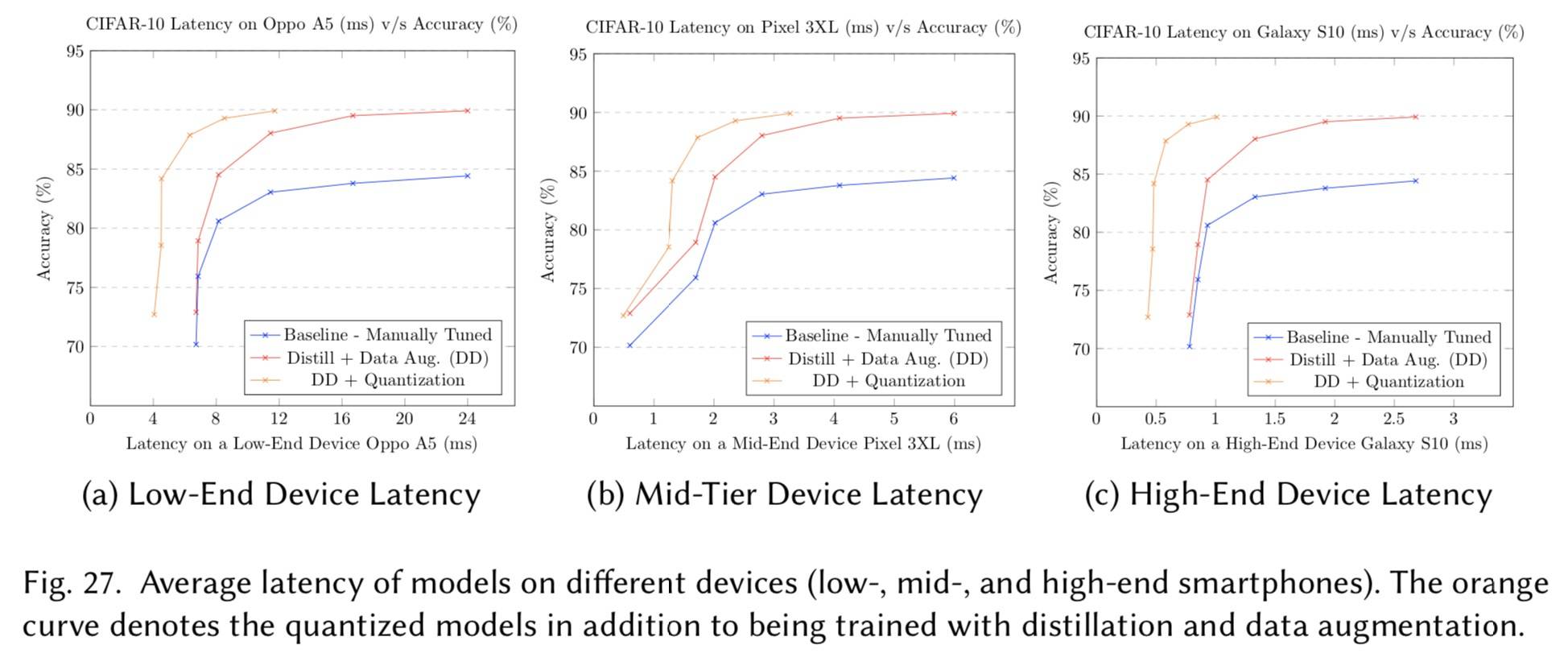
讨论
- Shrink-and-Improve for Footprint-Sensitive Models
- Grow-Improve-Shrink for Quality-Sensitive Models
无论目标是优化质量指标还是资源指标。我们还能够通过图 26 和 27 直观地检查效率技术可以在通过手动调整构建的帕累托边界上进行改进。
最后,还要强调对深度学习的性能的关注在代表性不足的类和分布外数据上建立模型(优化或未优化)以确保模型公平性,因为单独的质量指标可能不足以发现模型的更深层次问题。
结论
首先展示了深度学习模型的快速增长,并激发了当今训练和部署模型的人必须对效率做出隐式或显式决策的事实。为了解决这个问题,本文为读者设计了一个心智模型,让他们围绕模型效率和优化的多个重点领域进行思考。最后,展示了一部分明确且可操作的见解并辅以代码,供从业者用作该领域的指南,有望给出具体且可操作的要点,以及在优化用于训练和部署的模型时要考虑的权衡。
感想
又是两天时间,硬件那块有一点点地方看的不是太懂,不过依然不影响整体的印象。这是一篇非常实用的优化指南,告诉我们如何保证模型质量的同时尽可能减少资源占用(包括降低延迟)。而且还有实验代码附赠,完全可以亲自复现实验结果。总之,推荐阅读、更推荐实验;)