在之前那篇 NLP 表征的历史与未来 | Yam 里,我们几乎从头到尾都在提及句子表征,也提出过一个很重要的概念:“句子” 才是语义理解的最小单位。不过当时并没有太过深入细节,直到做到文本相似度任务时才发现早已经有人将其 BERT 化了。这就是本文要提到的一篇很重要但又很顺其自然的一篇论文——Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks。其实说到相似度,大家多少都会想到大名鼎鼎的 Siamese Recurrent Networks,他们当时(2016 年)用的是 LSTM 对句子表征,那是因为那时候 LSTM 效果是最好的。Sentence-BERT 其实就是将 LSTM 替换为 BERT。
背景问题
- 针对句子对任务性能太差。这是因为原生 BERT 是通过将两个句子拼接后输出 Label 的,给定一组句子,要想找到相似度最高的句子对,需要二次方的复杂度。
- 使用 CLS Token 作为句子表征效果太差,甚至不如 Glove。
作为一个求知欲满满的好奇之人,自然很想知道——为神马。先按捺下自己躁动的心,看看本篇论文是怎么做的。对于第一个问题,其实就是 Siamese Network 的改版,专门用来做相似度计算。对于第二个问题,则尝试了三种不同的 Pooling 方法,分别是 CLS,MAX 和 AVERAGE。它之后的 Bert-Flow 又增加了 AVERAGE 后两层(Bert 后两个 block)的方法。
句子表征
先看看文章 Related Work 提到哪些关于句子表征的研究:
- Skip-Thought 通过预测上下文句子来做句子表征。这和 Skip-Gram 一样,只是把 Token 从词替换为句子。
- 对 Siamese Bi-LSTM 的结果做 MAX Pooling。
- Transformer
- Siamese DAN 和 Siamese Transformer。这个 DAN 就是对 Word Embedding 平均后再接一个 DNN。
这些方法基本都是我们熟悉的套路,可以说已经开发的淋漓尽致了。不过 BERT 的 CLS 却是另辟蹊径,突破了已有的范式,当然啦,这个想法其实是 Doc2Vec 用的方法,毕竟是同一个团队出品的。关于未来还有哪些可能的方向,开头提到的文章里有比较深入的思考。短期来看,知识图谱(长时记忆)和充分的上下文(短时记忆)依然是可以进一步优化的。不过这可能只适用于对话领域,对于长文本的理解,可能还需从段落和文章结构上提出新的表征方法。这里还提到一个比较有趣的点,SNLI 数据集适合用来训练句子表征,猜想可能是句子对能给任务带来一些 “指示”,比直接用单个句子学到的表征更加 “深刻”。之前只知道 “领域适配” 效果有提升,现在进一步证实,对文本的深入理解(相似句)同样可以提升效果。
模型算法
三种 Pooling 方法之前已经提到过,不再赘述。代码如下:
1 | # From https://github.com/UKPLab/sentence-transformers/ |
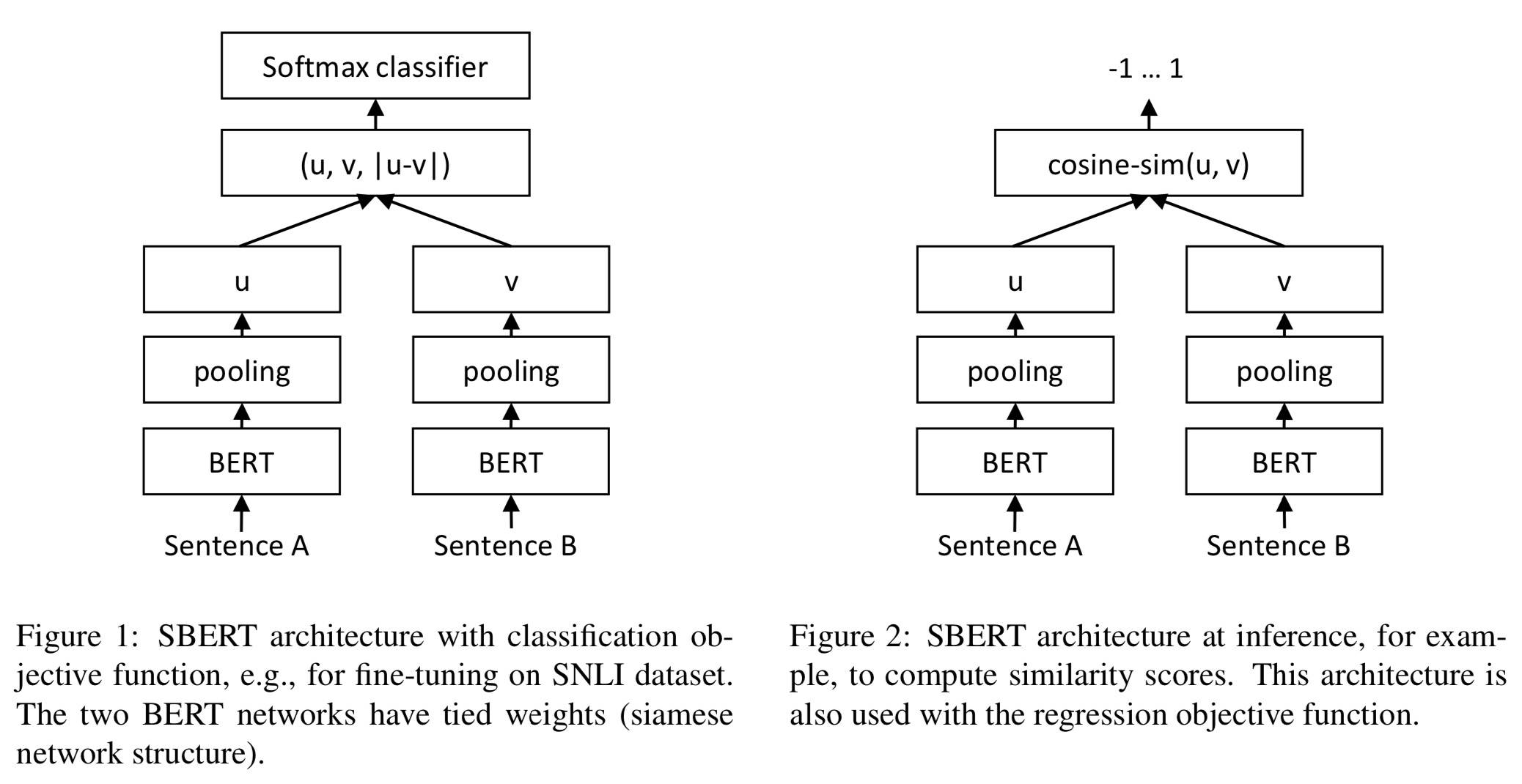
模型架构有两种,分别是:Siamese 和 Triplet,这主要是为了适配不同的任务,对句子对向量的输出做了不同处理。具体如下图(图片来自原论文)所示:
三类目标损失函数:
-
分类(u v 分别是两个句子的向量):
-
回归:使用均方误差损失(MSE Mean-Squared-Error Loss)
-
Triplet(给定句子 a,p 和 n 分别表示正向和反向句子):
距离评估采用 Euclidean distance,ε 表示 sp 至少比 sn 更接近 sa ε 那么多,文中设为 1。
代码如下(做了部分简化处理):
1 | # Code From https://github.com/UKPLab/sentence-transformers/ |
这些都比较直观,没啥需要特别说明的,稍微注意下,Triplet 损失其实就是 Relu 函数。
训练的一些配置:
- BatchSize 16
- Adam
- lr 2e-5
- lr warm-up 10% 训练数据
效果评估
首先看无监督任务,SBERT 训练数据:Wikipedia,NLI。注意,这里 NLI 数据是用来训练 SBERT 的,因为它是个相似度输出的模型(这点可能对其他模型略不公平,因为引入了新数据)。本任务评估的其实是预训练模型输出的句子向量表征的效果。结果如下图所示:
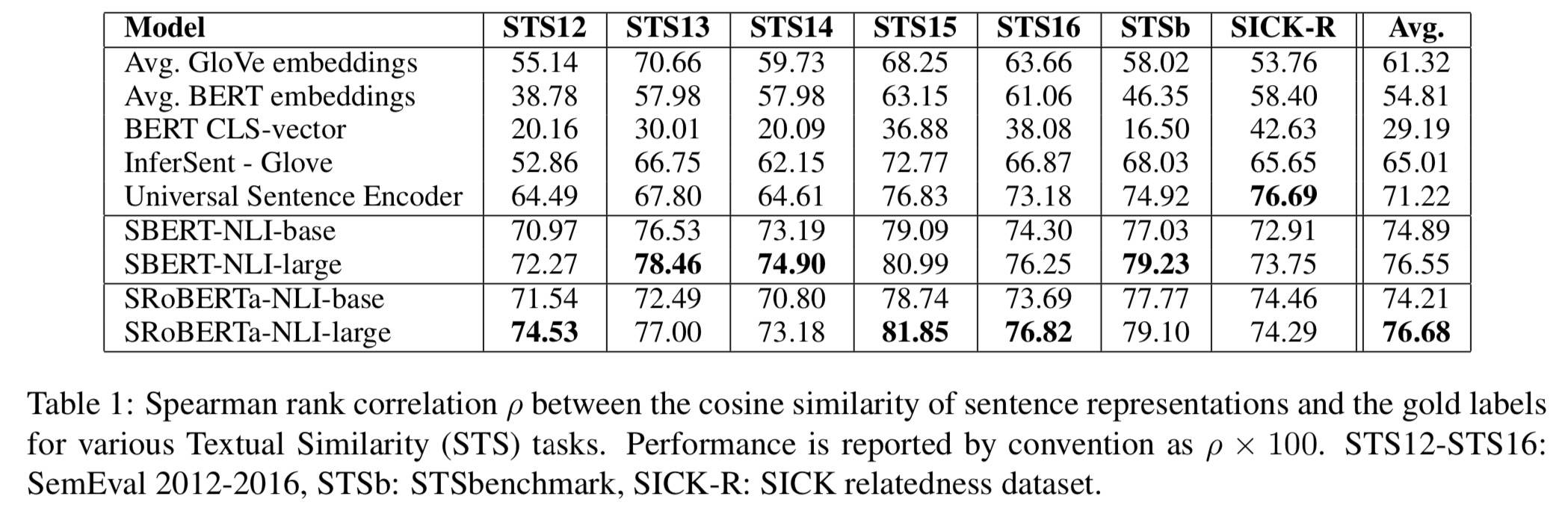
可以看出 CLS 和直接对 BERT 的隐向量取平均效果都不行。后面的几个实验也得出了类似的结论。不过这里有个现象还是值得注意:直接用 BERT 取平均的结果居然能比 SBERT 差那么多。这充分说明:不同任务使用的不同方法对预训练结果影响比较明显。
但这并不能说明 BERT 的句子表征能力弱。果然,接下来的有监督任务(相似度)就证明了这一点,如下图所示:
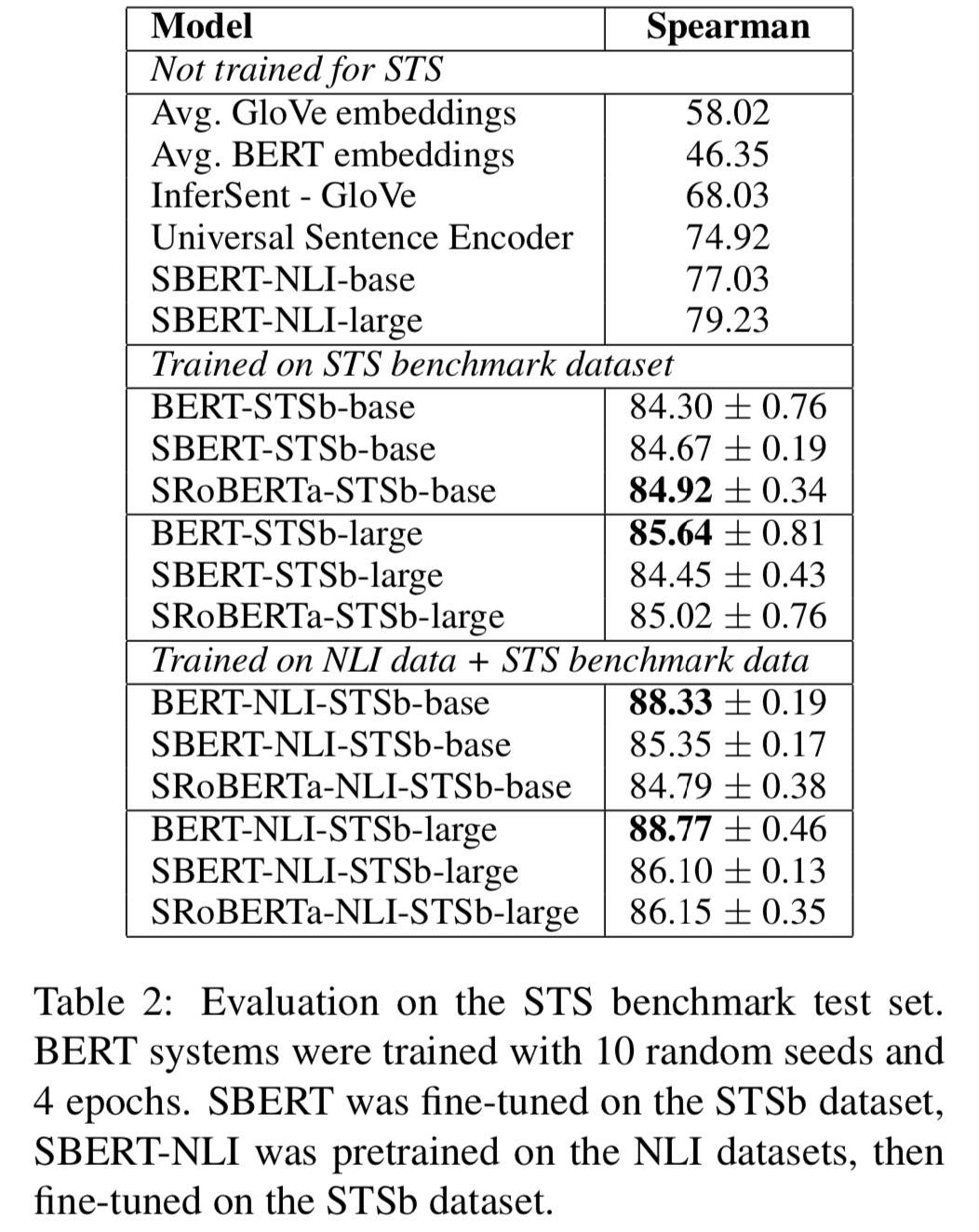
同样的配置下,BERT 表现比 SBERT 还要更好。这说明:下游任务精调效果显著。
而且后面在 SentEval 数据集上的实验(下游分类任务)同样也证明了这点,如下图所示:

对此,文章中也做了解释:这主要是因为不同任务的配置不同。STS 任务使用 Cosine-Similarity 对句子向量进行评估,Cosine-Similarity 对所有维度平等处理;而 SentEval 使用逻辑回归分类器对句子向量分类,这就允许某些维度对分类结果有更高或更低的影响。同时,也可以发现 SBERT 对句子表征本身也有一定的提升作用,这应该算是个额外收获。
结论就是:BERT 的 CLS 或输出向量无法和 “距离” 类的指标一起使用。这点也可以说是本文最大的价值所在,正如文章在 Related Work 中所言:还没有针对这些方法(CLS 和平均输出向量)是否能够带来有用句子表征的评估。
另外,还有一个有意思的发现:在交叉主题场景下,BERT 比 SBERT 表现的好很多。论文的解释是:BERT 能够使用 Attention 直接对比句子,而 SBERT 必须将单个句子从一个没见过的主题映射到一个向量空间,以使具有相似主张和原因的论点接近。其实,即便是单主题下,BERT 也要好于 SBERT。具体如下图所示:
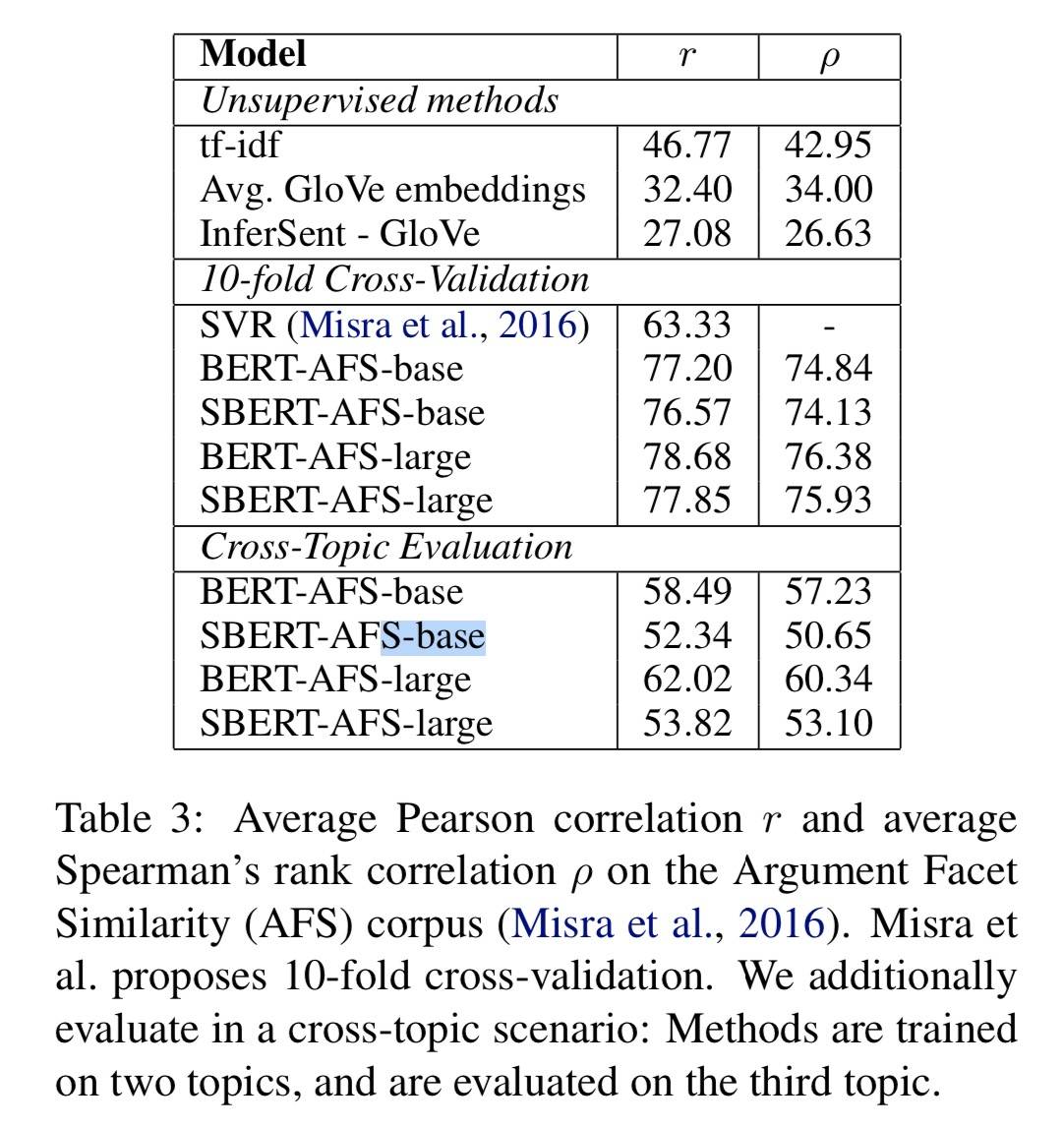
这几个实验个人感觉还挺有价值,整理一下能带给我们的启发:
- BERT 是个 “预训练” 的结果,直接使用一般不会有好效果,最好能在具体场景业务上精调一下。说到这里,其实我是不太赞同重新训练领域的 BERT 的,已经有很多实验证明提升有限。而且,预训练模型最主要的就是一个 “泛”,太 “专” 未必就好。不过倒是可以在领域数据上做增量训练。
- 不同任务使用的训练方法不同效果可能差异很大。这里指的主要是 “预训练方法”,原因自然是不同目标函数的 “导向” 不同,所以我们才会常常看到 BERT 会有个句子对的预训练模型。
- 不同数据集更适用的模型和任务不同。比如 SNLI 可能更适合训练句子表征(见下面两篇参考论文)。
参考论文:
- Alexis Conneau, Douwe Kiela, Holger Schwenk, Lo ̈ıc Barrault, and Antoine Bordes. 2017. Supervised Learning of Universal Sentence Representations from Natural Language Inference Data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 670–680, Copenhagen, Denmark. Association for Computational Linguistics.
- Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St. John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, Yun-Hsuan Sung, Brian Strope, and Ray Kurzweil. 2018. Universal Sentence Encoder. arXiv preprint arXiv:1803.11175.
使用指南
具体使用和 BERT 并无两样,因为模型架构本身其实还是 BERT,Similarity 无非是 BERT 输出之后的应用而已。作者已经将其发布为 pip 包,英文版直接安装后即可使用:
1 | # From https://www.sbert.net/index.html |
另外,这里面的功能也不止句子表征,还包括:相似度计算、文本聚类、语义搜索、信息检索、文本摘要、相似句挖掘、翻译句子挖掘、模型训练、模型蒸馏等。具体可参考文档:SentenceTransformers Documentation — Sentence-Transformers documentation。