Paper:[2011.05864] On the Sentence Embeddings from Pre-trained Language Models
核心思想:无监督方法将 Bert 产生的非平滑各向异性的句子语义空间分布转换为各向同性的高斯分布。
What
动机和核心问题
Bert 取得的成功毋庸置疑,但在 Sentence Embedding 方面(比如句子相似度)表现却很差,甚至不如 Glove。针对这个情况,本文主要回答两个问题:
- 为什么 Bert 的 Sentence Embedding 在语义相似句子召回上效果不好?是没有学习到足够的语义信息,还是仅仅因为语义信息没有被正确利用?
- 如果 Bert 学习到足够的语义信息但是很难被直接使用,有没有什么不需要额外监督训练的方法能让它变得容易些?
本文首先证明了 Bert 的句子嵌入能够反映句子间的语义相似度,也就是说 Bert 已经学习到了句子的表示。但是之前有研究表明 Bert 的词嵌入存在各向异性(词嵌入被局限在一个狭窄的圆锥体空间),所以假定句子也有类似问题。进一步的实证研究发现,句子嵌入在语义空间上不平滑,并且在某些区域定义不佳,很难直接用来计算相似度。本文就是通过 Normalizing Flow(一个可逆网络)将 Bert 的句子嵌入分布转换为平滑的各向同性的高斯分布,具体而言,就是学习一个基于 Flow 的生成模型来最大化从一个标准高斯隐变量空间生成 Bert 句子嵌入的似然函数。训练时,只有 Flow 网络的参数被优化,Bert 的参数保持不变;学习完成后,该可逆网络就可以用来将 Bert 的句子嵌入映射到高斯空间。此为 Bert-Flow,其实质乃是一个优化 Bert 句子嵌入的方法。
需要注意的是,本文所指的 Sentence Embedding 是指直接从 Bert 预训练模型得到的,而不是 Fine-Tune 后的。
Sentence-Bert:Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence embeddings using siamese BERT-networks. InProceedings of EMNLP-IJCNLP.
Normalizing FLow:Laurent Dinh, David Krueger, and Yoshua Bengio.2015. NICE: Non-linear independent componentsestimation. InProceedings of ICLR.
模型和算法
Bert 的 Sentence Embedding
一般而言有两种方式:
- 直接用 CLS Token 的 Embedding 作为句子表征,Bert 下游句子级别的任务基本都是用这个作为标准方法;
- 最后几层上下文 Embedding 的平均值
之前(Sentence-Bert, Reimers and Curevych (2019))有实验表明,Bert 的句子 Embedding 在相似度方面表现还不如 Glove;另外,平均方法比直接取 CLS 效果要好。其实,这个是可以理解的, 之前正好写过一篇文章,其中探讨过这个问题。原因很简单,CLS 压缩了太多信息,而平均又会损失语义,尤其是对 Self-Attention 取平均,甚至会弱化本来得到的 “Attention”。如果非要提升效果,我觉得不如在最后一层基础上加一层 CNN(卷积+Max Pooling)。
语义相似度与 Bert
Sentence Embedding 相似度可以简化为 Context Embedding 的相似度,但因为 Bert 训练过程中并没有计算两个 Embedding 的点乘(或 Cosine 相似度),所以需要(想象、假设)替代的方案。
-
Co-Occurrence Statistics as the Proxy for Semantic Similarity
被用来代替计算 sim,而根据 Yang et al.(2018) 的研究,该式可以近似分解为下面的式子:
PMI(点间互信息)捕获两个事件共同发生比独立发生高的频率,log p(x) 是特定词项,λ 是特定上下文项。PMI 常用来近似度量词的语义相似,所以(马马虎虎地),计算 Context Embedding 和 Word Embedding 的点乘也具有语义意义。
-
Higher-Order Co-Occurrence Statistics as Context-Context Semantic Similarity
两个 Context 的关系可以通过他们与词的连接推断和加强。具体来说,两个不同的 Context 如果与同一个词共现,那这两个 Context 可能在语义上相似。Context 和词同时出现,Context 的 Embedding 和 Word Embedding 也应该接近。预训练时,以词表中的词为中心,Context Embedding 应该可以学习到彼此之间的语义关联。
这一步的分析主要是确定 Bert 的预训练过程其实已经在 “暗中” “鼓励” 语义上有意义的上下文嵌入。也就是说,Bert 预训练其实隐含了上下文语义的训练。
HcW 分解:Zhilin Yang, Zihang Dai, Ruslan Salakhutdinov, andWilliam W Cohen. 2018. Breaking the softmax bottleneck: A high-rank rnn language model. InPro-ceedings of ICLR
PMI 近似词语义相似度:
- Omer Levy and Yoav Goldberg. 2014. Neural wordembedding as implicit matrix factorization. InProceedings of NeurIPS.
- Kawin Ethayarajh, David Duvenaud, and Graeme Hirst.2019. Towards understanding linear word analogies. InProceedings of ACL.
各向异性嵌入空间导致语义相似度差
既然如此,那为啥 Sentence Embedding 的表现会一般呢?本文用 Word Embedding 来分析(因为它和 Context Embedding 在同一空间)。
-
词频导致嵌入空间有偏
期望 Embedding 的相似度和语义相似度一致,如果 Embedding 根据频率不同分布在不同区域,那 Embedding 的相似度其实已经没有意义了。本文的计算结果表明 Word Embedding 受词频影响,因为词连接了上下文,所以 Context Embedding 可能被词频信息带歪,进而导致语义信息有损。
这里的分析感觉有点问题。Word Embedding 受词频影响不应该是很正常的现象吗,低频词和高频词为什么一定要分布一致?另外,Word Embedding 受词频影响,为什么就能推出上下文语义就会有损呢?这中间的推理基础是什么?
关于怎么计算距离写的很不清楚,看了依然没有特别清楚到底是怎么做的。Freq Rank 的标记有错误。
-
低频词稀疏
低频词与相邻词的距离要比高频词远,因此低频词会导致稀疏,进而导致 Embedding 空间有很多 “hole”,这些区域的语义表示就不佳(因为 Sentence Embedding 是相加的到的)。
这部分主要是讲词频会影响 Embedding,进一步影响 Context Embedding,并最终会影响 Sentence Embedding。
语言模型各向异性的 Word Embedding:
- Jun Gao, Di He, Xu Tan, Tao Qin, Liwei Wang, and Tie-Yan Liu. 2019. Representation degeneration problem in training natural language generation models.InProceedings of ICLR.
- Lingxiao Wang, Jing Huang, Kevin Huang, Ziniu Hu,Guangtao Wang, and Quanquan Gu. 2020. Improv-ing neural language generation with spectrum control. InProceedings of ICLR.
- Kawin Ethayarajh. 2019. How contextual are contextualized word representations? comparing the geometry of bert, elmo, and gpt-2 embeddings. InProceed-ings of EMNLP-IJCNLP.
hole 会侵害嵌入空间凸性:
- Danilo Jimenez Rezende and Fabio Viola. 2018. Taming VAEs.arXiv preprint arXiv:1810.00597
- Bohan Li, Junxian He, Graham Neubig, Taylor Berg-Kirkpatrick, and Yiming Yang. 2019. A surprisingly effective fix for deep latent variable modeling of text. InProceedings of EMNLP-IJCNLP.
- Partha Ghosh, Mehdi SM Sajjadi, Antonio Vergari,Michael Black, and Bernhard Scholkopf. 2020.From variational to deterministic autoencoders. InProceedings of ICLR.
BERT-Flow
标准的高斯分布满足各向同性,而且不存在 “hole” 的区域,所以上面两个问题都能得到缓解。建模如下:
z 的分布是先验分布,f 是从高斯空间到观测空间的映射。观测变量的概率密度函数为:
似然函数:
D 表示句子集合。
关于基于 Flow 的模型:Ivan Kobyzev, Simon Prince, and Marcus A Brubaker.2019. Normalizing flows: Introduction and ideas. arXiv preprint arXiv:1908.09257.
映射函数:Laurent Dinh, David Krueger, and Yoshua Bengio.2015. NICE: Non-linear independent componentsestimation. InProceedings of ICLR.
det 设计:
- Durk P Kingma and Prafulla Dhariwal. 2018. Glow:Generative flow with invertible 1x1 convolutions. InProceedings of NeurIPS.
- Laurent Dinh, David Krueger, and Yoshua Bengio.2015. NICE: Non-linear independent componentsestimation. InProceedings of ICLR.
How
主要是如何获取 Sentence Embedding 和如何训练。
Sentence Embedding
这个比较简单,基本就是对 Bert 的 output 做各种处理。最后的输出都是 [batch_size, hidden_size] 的大小。CLS 的最简单,直接从 Bert 那里拿到 Pooled out 即可。下面再介绍两个:
1 | # avg |
avg 就是对最后一层的输出按照序列取平均。
1 | # ave-last-X |
“avg-last-X” 是对最后 X 层做平均。
Flow
这里的代码基本是参考了 OpenAI 和 Google 的,相关论文:[1807.03039] Glow: Generative Flow with Invertible 1x1 Convolutions,Google 代码:tensor2tensor/tensor2tensor/models/research at master · tensorflow/tensor2tensor。具体细节就不在本文展开了。
1 | flow_model = Glow(flow_model_config) |
数据和实验
评估方法:Sentence Embedding 的 Cosine 相似度与标签相似度的 Spearman 相关系数。
两种实验设置:
- 无监督的 Flow
- 先在 SNLI+MNLI 上精调 Bert 然后再训练 Flow
语义相似度

NLI 表示在 NLI(SNLI+MNLI)上训练 Flow,target 表示在所有数据集上训练 Flow。
QA 任务
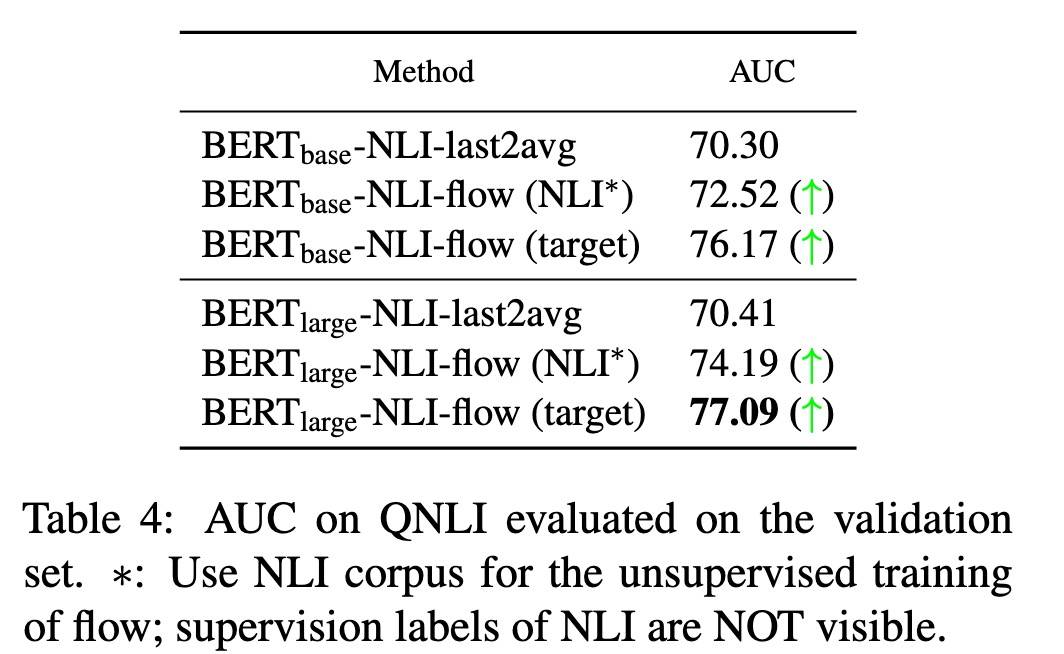
X-NLI 表示使用 NLI 监督,这个是 Sentence-Bert 里面的方法,对比需要。这个任务本来是判断 QA 对的 Label 是 “包含” 或 “不包含”,本文用问题和答案的相似度来表示 Label(1 表示包含,0 表示不包含)。
其他 Embedding

其中,SN 表示标准归一化,即对 Sentence Embedding Z 标准化。来自:Sanjeev Arora, Yingyu Liang, and Tengyu Ma. 2017.A simple but tough-to-beat baseline for sentence em-beddings. InProceedings of ICLR.
NATSV 表示 Nulling Away Top-k Singular Vectors,即通过使顶部的奇异向量无效,可以避免嵌入的各向异性,并可以实现更好的语义相似性。来自:Jiaqi Mu, Suma Bhat, and Pramod Viswanath. 2017.All-but-the-top: Simple and effective postprocessingfor word representations. InProceedings of ICLR.
词汇相似度

词汇相似度用编辑距离衡量,然后看两个相似度的相关性。标准相关性为 -24.61,Bert 的是 -50.49,Bert-Flow 的论文没说。论文觉得,很多时候改变一个字都有可能会完全影响语义,但是 Bert 因为相关性强,所以改变一个或少数几个(主要是编辑距离小于等于 4 的情况)字,语义可能改变很小。
Resource
- [1908.10084] Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
- [1908.09257] Normalizing Flows: An Introduction and Review of Current Methods
- openai/glow: Code for reproducing results in “Glow: Generative Flow with Invertible 1x1 Convolutions”
- tensor2tensor/tensor2tensor/models/research at master · tensorflow/tensor2tensor