Paper:[1912.08777] PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
Code:google-research/pegasus
核心思想:基于 GSG 的 Transformer 在文本摘要上的应用。
What
动机和核心问题
很少有关于系统评估文本摘要的不同方法和数据集
基于 Transformer 的 Seq2Seq 预训练在文本生成中的成功
本文的贡献如下:
提出新的文本摘要自监督预训练目标:gap-sentences generation(GSG)
在大量下游摘要任务中进行评估
在少量数据上精调取得很好的效果
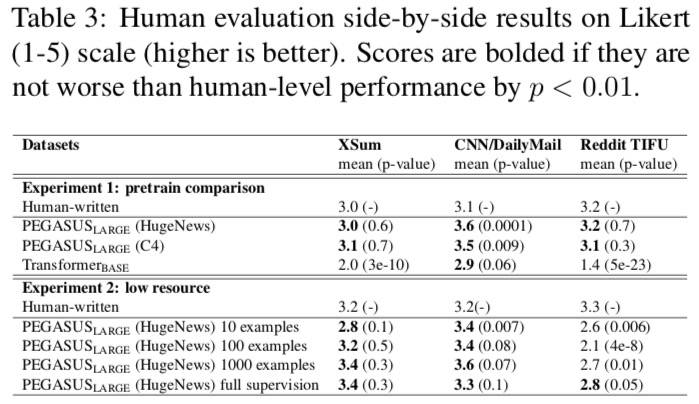
对结果进行了人工评估
模型和算法
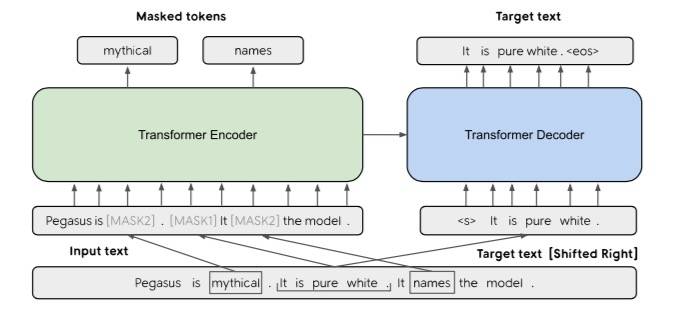
依然是基于 Transformer 的架构,不过在以下方面做了调整。
GSG
PEGASUS 选择了 mask 掉整个句子,然后将 mask 掉的句子重建为摘要。
因为是摘要任务,所以目标句子选择时基于重要性而不是随机选取。
三种选择句子的方式:
随机(纯粹做实验的)
前 m 个(也是做实验的)
基于重要性,评估方式:
Ind:独立的 ROUGE1-F1
Seq:连续选择后贪婪最大化的 ROUGE1-F1
计算 ROUGE1-F1 时,也采用了两种方式:
Orig:标准方式(double-counting identical n-grams)
Uniq:n-grams 集合
这里的代码是这样的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 float ComputeRougeFromCandidateCounts ( const RougeSentenceData& reference_data, const RougeSentenceData& candidate_data, const std::vector<double >& candidate_counts, MetricType rouge_type, RougeComputeOption option) double overlaps = 0 ; const auto & reference_ngrams = reference_data.ngrams (); for (int i = 0 ; i < reference_ngrams.size (); ++i) { double reference_count_conditional; if (option == ROUGE_OPTION_DEDUPLICATE) reference_count_conditional = std::min (reference_ngrams[i].second, 1 ); else if (option == ROUGE_OPTION_LOG) reference_count_conditional = std::log (1 + reference_ngrams[i].second); else reference_count_conditional = reference_ngrams[i].second; const double reference_count = reference_count_conditional; const double candidate_count = candidate_counts[i]; overlaps += std::min (reference_count, candidate_count); } float recall = 0 ; float precision = 0 ; float f1 = 0 ; if (option == ROUGE_OPTION_DEDUPLICATE) { recall = static_cast <float >( overlaps / std::max (1.0 , reference_data.num_unique_ngrams ())); precision = static_cast <float >( overlaps / std::max (1.0 , candidate_data.num_unique_ngrams ())); } else if (option == ROUGE_OPTION_LOG) { recall = static_cast <float >(overlaps / std::max (0.1 , reference_data.log_num_ngrams ())); precision = static_cast <float >( overlaps / std::max (0.1 , candidate_data.log_num_ngrams ())); } else { recall = static_cast <float >(overlaps / std::max (1.0 , reference_data.num_ngrams ())); precision = static_cast <float >(overlaps / std::max (1.0 , candidate_data.num_ngrams ())); } ... }
这里的 candidate_counts 是事先计算好的 overlap:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 static void AddCountsFromCandidate (const RougeSentenceData& candidate_data, const RougeSentenceData& reference_data, std::vector<double >* candidate_counts, RougeComputeOption option) const auto & reference_ngrams = reference_data.ngrams (); const auto & candidate_ngrams = candidate_data.ngrams (); int c_idx = 0 ; int r_idx = 0 ; while (c_idx < candidate_ngrams.size () && r_idx < reference_ngrams.size ()) { const auto & cand = candidate_ngrams[c_idx]; const auto & ref = reference_ngrams[r_idx]; if (cand.first == ref.first) { if (option == ROUGE_OPTION_DEDUPLICATE) (*candidate_counts)[r_idx] += std::min (cand.second, 1 ); else if (option == ROUGE_OPTION_LOG) (*candidate_counts)[r_idx] += std::log (1 + cand.second); else (*candidate_counts)[r_idx] += cand.second; ++c_idx; ++r_idx; } else if (cand.first < ref.first) { ++c_idx; } else { ++r_idx; } } }
ngrams 是已经按照 gram 的散列排序好的(这里采用了 queue 来生成 ngram):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 RougeSentenceData::RougeSentenceData ( const std::vector<std::string>& sentence_tokens, MetricType rouge_type, int ngram_size) : tokens_ (sentence_tokens), rouge_type_ (rouge_type) { if (NGramRougeType (rouge_type)) { num_ngrams_ = 0 ; std::string ngram; std::deque<std::string> ngram_token_queue; for (const std::string& token : sentence_tokens) { ngram_token_queue.push_back (token); if (ngram_token_queue.size () > ngram_size) { ngram_token_queue.pop_front (); } if (ngram_token_queue.size () == ngram_size) { std::string ngram = absl::StrJoin (ngram_token_queue, " " ); ngrams_map_[Fingerprint2011 (ngram)]++; num_ngrams_ += 1 ; } } ngrams_.assign (ngrams_map_.begin (), ngrams_map_.end ()); std::sort (ngrams_.begin (), ngrams_.end (), [](const std::pair<unsigned long long , int >& left, const std::pair<unsigned long long , int >& right) { return left.first < right.first; }); num_unique_ngrams_ = ngrams_.size (); for (auto & element : ngrams_) log_num_ngrams_ += std::log (1 + element.second); } }
关于评估方法的详细情况需要单独介绍,这里不再赘述。
MLM
两种不同的训练方式:
原始的 MLM 方式,此时在下游任务中 Decoder 和 Encoder 共享参数
原始的 MLM mask 和 GSG 一起
实验发现 MLM 在训练步数很大时并没能提升下游任务。
特点和创新
考虑到 Large 把 MLM 部分的 mask 给去了,那这跟 Bart 没啥区别啊,所不同的大概就是 Bart 做的是重建输入文本,PEGASUS 做的是重建摘要。其实从上面的贡献部分也可以看出,对模型最大的调整就是 GSG,这东西说白了和之前的 SpanBert 也没啥不同。再非要说有啥创新的地方,大概就是聚焦到 “文本摘要” 这个具体的任务吧,而且做了非常详尽的实验(可能这才是最有价值的地方)。
How
如何使用
训练可以参照官方文档(居然不是 TF2.0,真的是服气,不想说话),注意按照 GitHub 的 setup 安装依赖。推理部分可以使用 transformers,已经用 PyTorch 给实现好了,具体可以看这里 。
其实从中整体上看,模型就是输入一个文档,然后输出对应的摘要文本。因此推理的本质其实就是一个 “生成” 的过程,这里面用到的技术都是通用的,所以我们看 transformers 的源代码其实就是继承了 Bart 的生成:
1 2 3 4 5 6 7 8 9 class PegasusForConditionalGeneration (BartForConditionalGeneration ): config_class = PegasusConfig authorized_missing_keys = [ r"final_logits_bias" , r"encoder\.version" , r"decoder\.version" , r"model.encoder.embed_positions" , "model.decoder.embed_positions" , ]
数据和实验
这部分工作做的挺扎实的,内容非常详实。
数据
首先是预训练的数据集,使用了 C4 和 HugeNews,前者是 750G 的网页文本,后者是 3.8T 的1.5B 篇新闻类文章。这样的数据量真的让人叹为观止了。
下游任务的数据集达到了 12 个之多,基本覆盖了所有的文本摘要数据集,Tensorflow 官方有一份数据集的集合列表:TensorFlow Datasets 。
实验
模型参数:
Base:12 层,768 hidden size,3072 feed-forward layer size,12 self-attention heads,223 M 参数
Large:16 层,1024 hidden size,4096 feed-forward layer size,16 self-attention heads,568 M 参数
训练参数:
没有预训练的 Base 可以作为 TransformerBase。
在生成时使用了 greedy-decoding 和 beam-search 两种方式。
消融实验
预训练步数对下游任务影响显著:
主题相关的预训练模型对下游任务更加有效:
GSG 的 Ind-Orig 效果最好(证明按重要性选择是有效的),GSR(GSG 占 document 句子的比例)小于 50% 时表现好;单独使用 MLM 效果很差,MLM + Ind-Orig 和随机效果相近,另外实验也发现 MLM 在预训练早期(100k-200k 步)时能够提升下游任务,但当步数继续增加时反而会有抑制效果。所以 Large 就没有包括 MLM (是不是可以理解为——多此一举)。
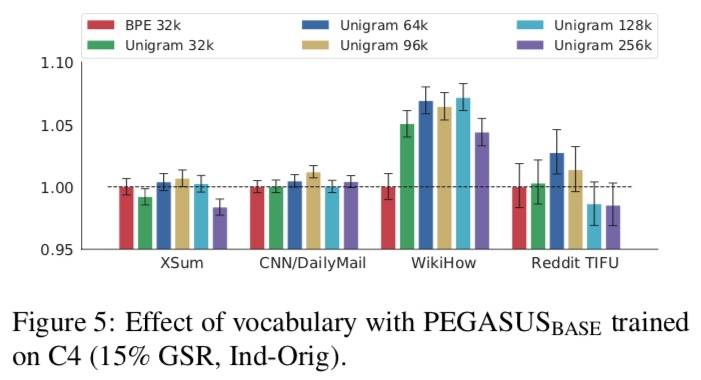
词表选择 Unigram 效果较好:
大模型
除了之前提到的参数外,其他方面也选用了消融实验的最佳配置:
GSG(Ind-Orig)
不使用 MLM
Unigram Vocabulary 96k
选中的句子 20% 不改变
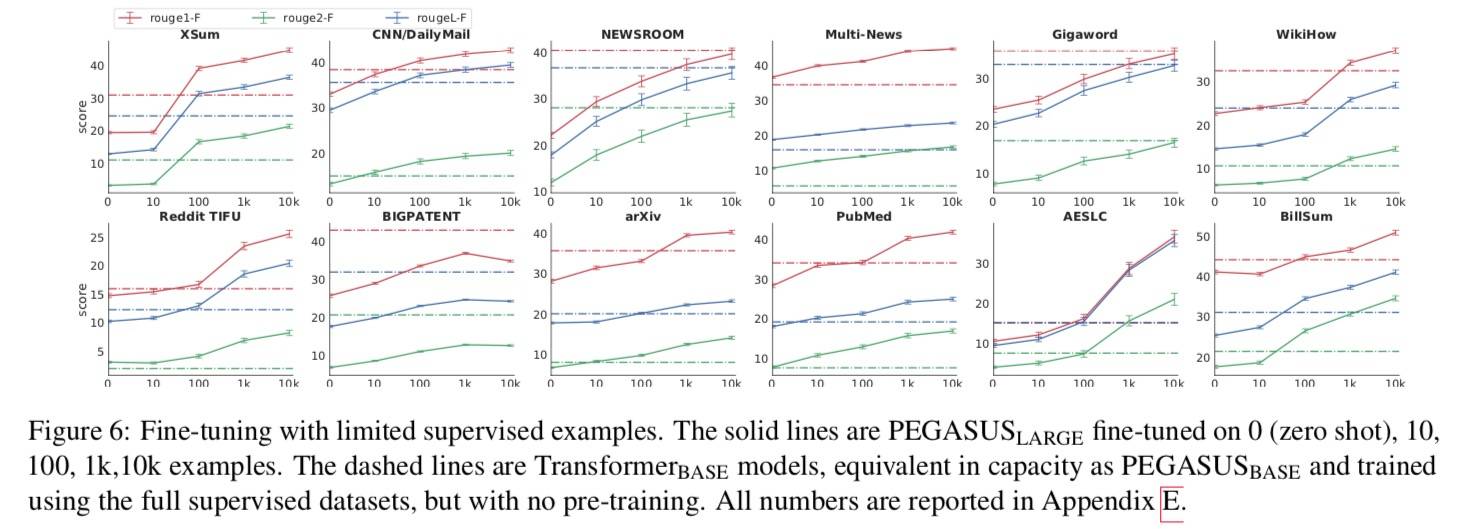
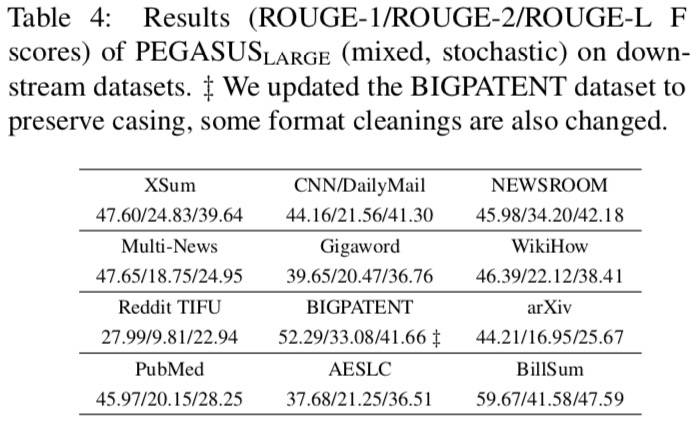
在不同下游任务上的结果:
结果也显示,小数据集更能从预训练中获益。
小样本
三根线分别是三种分数,折线上的五个点对应了不同数量的数据。
质量
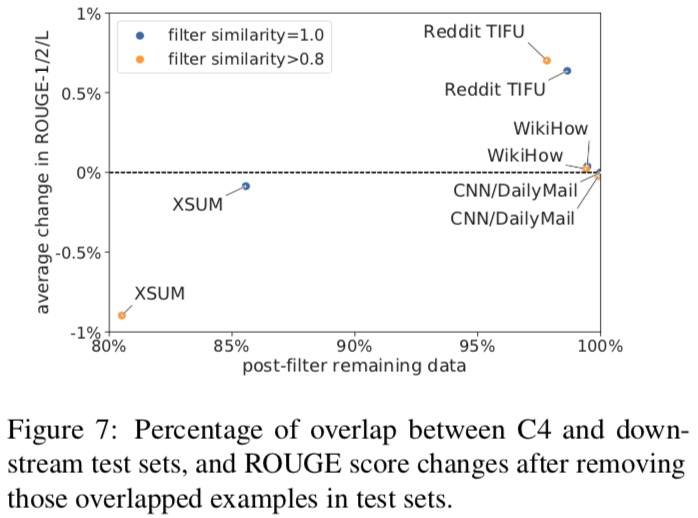
模型是记忆器还是具备生成能力
这里的 similarity 是计算下游任务测试集和预训练文档的,采用了 ROUGE-2 Recall,即:common 2-grams / 测试集 2-grams。
更进一步
在 C4 和 HugeNews 混合数据上做预训练,两者的权重是样本的数量
在 15%-45% 之间均匀地动态选择 gap sentences ratio(GSR)
加入 20% 均匀噪声随机采样重要的句子
由于 Perplexity 收敛过慢,预训练从 500k 调整到 1.5M 步
SentencePiece Tokenizer 编码换行符
Discussion
相关工作
MASS:根据剩余部分重建句子片段
UniLM:在三种语言模型(单向、双向 MLM,seq2seq)上进行联合训练
T5:不同 mask 比例和跨度的随机文本
BART:根据不同的噪声输入重建文本
打开脑洞
前面已经提到,本文对模型其实并没有创新,唯一的小调整是 GSG,但确实是一份不错的实验报告(貌似现在论文都是这个趋势),实验细节非常多,可以给要发 paper 的同学不少启发。纵观全文,依然是满满的 “大力出奇迹” 既视感,不过 GSG 的想法貌似还可以用来做关键词(短语)提取,不过这样倒是不需要 Decoder 部分了,应该用 Bert 的架构再加上一个按重要性 Mask 就可以实现了。